原文链接: https://blog.csdn.net/yuxuan20062007/article/details/88843690
【运动规划RRT*算法图解】 https://blog.csdn.net/weixin_43795921/article/details/88557317
尽管RRT算法是一个相对高效率,同时可以较好的处理带有非完整约束的路径规划问题的算法,并且在很多方面有很大的优势,但是RRT算法并不能保证所得出的可行路径是相对优化的。因此许多关于RRT算法的改进也致力于解决路径优化的问题,RRT*算法就是其中一个。RRT*算法的主要特征是能快速的找出初始路径,之后随着采样点的增加,不断地进行优化直到找到目标点或者达到设定的最大循环次数。RRT*算法是渐进优化的,也就是随着迭代次数的增加,得出的路径是越来越优化的,而且永远不可能在有限的时间中得出最优的路径。因此换句话说,要想得出相对满意的优化路径,是需要一定的运算时间的。所以RRT*算法的收敛时间是一个比较突出的研究问题。但不可否认的是,RRT*算法计算出的路径的代价相比RRT来说减小了不少。RRT*算法与RRT算法的区别主要在于两个针对新节点 的重计算过程,分别为:
- 重新为
选择父节点的过程, 比起RRT多了一个rewire的过程。
- 重布线随机树的过程
重新选择父节点过程

在新产生的节点 附近以定义的半径范围内寻找“近邻”,作为替换
父节点的备选。依次计算“近邻”节点到起点的路径代价加上
到每个“近邻”的路径代价,具体过程见图3。
图 a)中表现的是随机树扩展过程中的一个时刻,节点标号表示产生该节点的顺序,0节点是初始节点,9节点是新产生的节点 ,4节点是产生9节点的
(抱歉这里6节点是9节点的
,图中标错了),节点与节点之间连接的边上数字代表两个节点之间的欧氏距离(这里我们用欧氏距离来表示路径代价)。
在重新找父节点的过程中,以9节点 为圆心,以事先规定好的半径,找到在这个圆的范围内
的近邻,也就是4,5,8节点。
原来的路径0 - 4 - 6 - 9代价为10 + 5 + 1 = 16,备选的三个节点与 组成的路径0 - 1 - 5 - 9,0 - 4 - 9和0 - 1 - 5 - 8 - 9代价分别为3 + 5 + 3 = 11,10 + 4 = 14和3 + 5 + 1 + 3 = 12,因此如果5节点作为9节点的新父节点,则路径代价相对是最小的,因此我们把9节点的父节点由原来的节点4变为节点5,则重新生成的随机树如图 b)所示。
重布线随机树过程

在为 重新选择父节点之后,为进一步使得随机树节点间连接的代价尽量小,为随机树进行重新布线。过程示意如图4重布线的过程也可以被表述成:如果近邻节点的父节点改为
可以减小路径代价,则进行更改。
如图4 a),9节点为新生成的节点 ,近邻节点分别为节点4 , 6 , 8 。它们父节点分别为节点0 , 4 , 5。路径分别为0 - 4,0 - 4 - 6,0 - 1 - 5 - 8,代价分别为10,10 + 5 = 15 和3 + 5 + 1 = 9。
如果将4节点的父节点改为9节点 ,则到达节点4的路径变为0 - 1 - 5 - 9 - 4,代价为3 + 5 + 3 + 4 = 15 大于原来的路径代价10,因此不改变4节点的父节点。
同理,改变了8节点的父节点,路径代价将由原来的9变为14,也不改变8节点的父节点。如果改变6节点的父节点为 则路径变为0 - 1 - 5 - 9 - 6,代价为3 + 5 + 3 + 1 = 12小于原来的路径代价15,因此将6的父节点改为节点9,生成的新随机树如图4 b)。
重布线过程的意义在于每当生成了新的节点后,是否可以通过重新布线,使得某些节点的路径代价减少。如果以整体的眼光看,并不是每一个重新布线的节点都会出现在最终生成的路径中,但在生成随机树的过程中,每一次的重布线都尽可能的为最终路径代价减小创造机会。
RRT*算法的核心在于上述的两个过程:重新选择父节点和重布线。这两个过程相辅相成,重新选择父节点使新生成的节点路径代价尽可能小,重布线使得生成新节点后的随机树减少冗余通路,减小路径代价。

其中部分函数与RRT算法中的定义和作用相同。
calculate(dist(,
)+cost(
,
)) 中dist函数计算两点之间的距离,cost函数计算从给定点沿着随机树的各个边直到起点的路径代价。在这里路径代价是从给定点沿着随机树的各个边直到起点的欧氏距离之和。
min(dist( ,
)+cost(
,
)) 表示选出使路径代价最小的
。
同理min(dist(,
)+cost(
,
)) 表示选出使路径代价最小的
。
避障策略
为了简化问题,路径规划的障碍物取较为规则的几何形,如圆,多边形等。对于圆形障碍物来说,圆形边界的判断属于非线性问题,通常将圆形进行线性化处理(转化为多边形)。只需要判断 的横纵坐标是否在圆内,这里我们规定如果
位于圆形障碍物的外接正方形内,就视为碰撞。如果圆形障碍物的圆心坐标为
,半径为
,考虑移动机器人的尺寸,对障碍物进行膨化处理,膨胀尺寸inf,所以碰撞条件为:
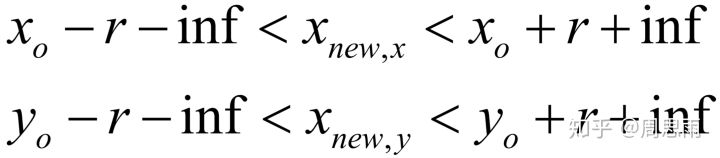
因为圆形障碍物的避障策略相对简单,在仿真中并未设置圆形障碍物。
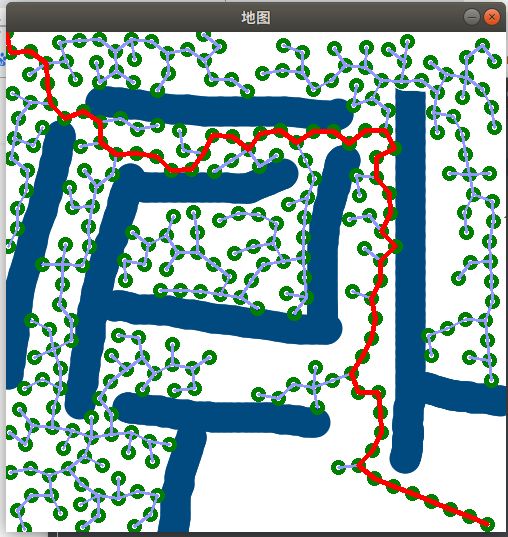
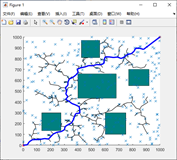
仿真环境中搭建的迷宫,主要选取长方形障碍物。长方形的碰撞机制研究相对复杂一些,具体碰撞机制阐述如下:在扩展随机树的过程中,由 到
连接的边不能与长方形障碍物的任何一边相交,即将长方形障碍物碰撞检测问题转化为直线与矩形相交问题。直线与矩形相交的判断主要分为两步:
第一步,判断 与
是否在矩形某一条边的一侧。如果
与
在矩形任意一条边的同侧,则不用进行后续判断,
与
连线必定不与矩形相交。这里不存在两点位于矩形内部的情况,因为
由
产生,而
必位于矩形外侧,如果
与
位于某一条边的两侧,则进行第二步判断。
第二步, 与
在矩形任意一边的不同侧时,分为两种情况:
- 第一种情况是
与
- 第二种情况是两点均在矩形外部。在这种情况下并不能保证两点连线不与矩形相交,图6情况所示,两点位于矩形外侧且位于矩形上边的两侧,但两点连线与矩形相交。在这种情况下,利用直线与矩形的性质进行避碰计算。


如图7所示, 与
位于矩形障碍物AB 边的两侧且均位于矩形的外侧,两点连线与矩形相交,
与
是两个边界,即当
与
连线位于
与
两直线下方时,
与
连线必定与矩形相交。反之,若不在
与
两直线下方则表现为不与障碍物发生碰撞。对于AD边来说必发生碰撞的过程可以用如下式子表示,
![]()
k 表示直线的斜率。
整个碰撞检测过程的逻辑如下:
对于矩形的一条边设定一个布尔值 ,当
时,表示发生碰撞,当
时,表示不发生碰撞。
定义一个判断函数 ,其中:
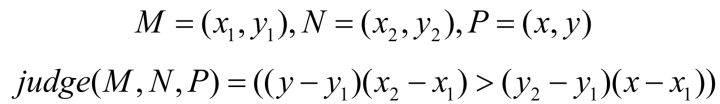
所以 函数是一个布尔函数,当等式右边为真时,
,反之
。则对于每一个边,判断逻辑可以写成
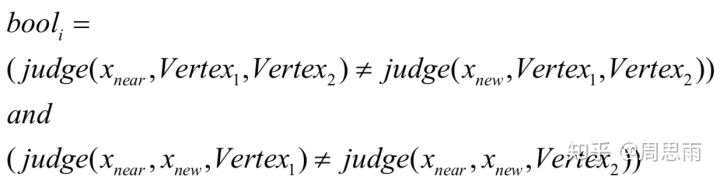
其中 表示矩形障碍物某一条边的两个定点。
针对图7中的具体情况:
布尔函数表示为:

首先判断且逻辑左半部分,
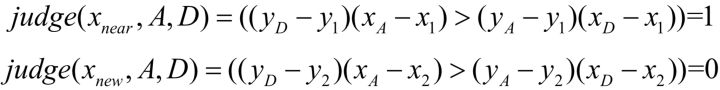
所以 ,意味着
与
位于AD边的两侧。
接着判断且逻辑的右半部分,
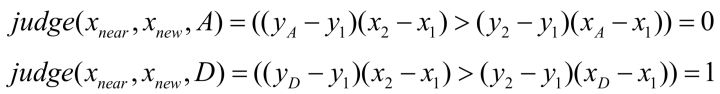
所以 ,意味着
与
连线位于
与
两直线下方。根据此判断条件发现,
与
属于同一种情况,不必再分情况讨论。
因此 ,
与
连线与矩形这一条边相交,发生碰撞。
bool 函数且逻辑左半部分与 相同,对于
而言,因为且逻辑左半部分判断两点是否在一条边两侧。且逻辑右半部分
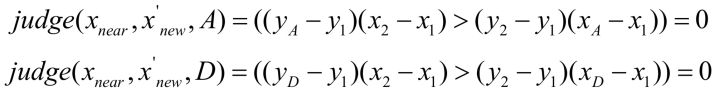
所以,故
。
因此 与
连线不会与矩形这一条边相交,不会发生碰撞。
其他边的判断方法是相同的,当且仅当
![]()
才表明 与
连线不与矩形相交,不会发生碰撞,也将其视为有效点插入随机树中。
通过对每一个障碍物进行上述逻辑判断即可以使随机树的扩展避开障碍物,在 中搜索路径。
算法图解:
1. 产生一个随机点xrand。

2. 在树上找到与xrand最近的节点xnearest。

3. 连接xrand与xnearest。

4. 以xrand为中心,ri为半径,在树上搜索节点。

5. 找出潜在的父节点集合Xpotential_parent,其目的是要更新xrand,看看有没有比它更好的父节点。

6. 从某一个潜在的父节点xpotential_parent开始考虑。

7. 计算出xparent作为父节点时的代价。

8. 先不进行碰撞检测,而是将xpotential_parent与xchild(也就是xrand)连接起来。

9. 计算出这条路径的代价。

10. 将新的这条路径的代价与原路径的代价作比较,如果新的这条路径的代价更小则进行碰撞检测,如果新的这条路径代价更大则换为下一个潜在的父节点。

11. 碰撞检测失败,该潜在父节点不作为新的父节点。

12. 开始考虑下一个潜在父节点。

13. 将潜在父节点和xchild连接起来

14. 计算出这条路径的代价。

15. 将新的这条路径的代价与原路径的代价作比较,如果新的这条路径的代价更小则进行碰撞检测,如果新的这条路径代价更大则换为下一个潜在的父节点。

16. 碰撞检测通过。

17. 在树中将之前的边删掉。

18. 在树中将新的边添加进去,将xpotential_parent作为xparent。

19. 遍历所有的潜在父节点,得到更新后的树。

引用文章:
[1] 机器人运动规划RRT*算法图解
[2] 路径规划——改进RRT算法