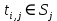TextRank算法理解
TextRank算法
TextRank算法基于PageRank,用于为文本生成关键字和摘要。其论文是:
Mihalcea R, Tarau P. TextRank: Bringing order into texts[C]. Association for Computational Linguistics, 2004.
先从PageRank讲起
在浅入浅出:PageRank算法这篇博客中我做过简要的介绍,这里再补充一下。
PageRank最开始用来计算网页的重要性。整个www可以看作一张有向图图,节点是网页。如果网页A存在到网页B的链接,那么有一条从网页A指向网页B的有向边。
构造完图后,使用下面的公式:

S(Vi)是网页i的中重要性(PR值)。d是阻尼系数,一般设置为0.85。In(Vi)是存在指向网页i的链接的网页集合。Out(Vj)是网页j中的链接存在的链接指向的网页的集合。|Out(Vj)|是集合中元素的个数。
也就是说:
对于一篇网页来说,可以这么理解:它的重要性,取决于到他的每个链接页面的重要性之和来决定的。每个链接到该页面的页面的重要性 S(Vj) 还需要对所有它所出去的页面所评分。所以除以了OUT(Vj)。同时,该页面 S(Vj) 的重要性不能单单由其他的链接页面决定,还包含一定的概率来决定要不要接受由其他页面来决定,这也就是d的作用。
PageRank需要使用上面的公式多次迭代才能得到结果。初始时,可以设置每个网页的重要性为1。上面公式等号左边计算的结果是迭代后网页i的PR值,等号右边用到的PR值全是迭代前的。
举个例子:

上图表示了三张网页之间的链接关系,直觉上网页A最重要。
依然能判断出A、B、C的重要性。
使用TextRank提取关键字
将原文本拆分为句子,在每个句子中过滤掉停用词(可选),并只保留指定词性的单词(可选)。由此可以得到句子的集合和单词的集合。
每个单词作为pagerank中的一个节点。设定窗口大小为k,假设一个句子依次由下面的单词组成:
w1,w2,w3,w4,w5,…,wn
[w1,w2,…,wk]、[w2,w3,…,wk+1]、[w3,w4,…,wk+2]等都是一个窗口。在一个窗口中的任两个单词对应的节点之间存在一个无向无权的边。
基于上面构成图,可以计算出每个单词节点的重要性。最重要的若干单词可以作为关键词。
使用TextRank提取关键短语
参照“使用TextRank提取关键词”提取出若干关键词。若原文本中存在若干个关键词相邻的情况,那么这些关键词可以构成一个关键短语。
例如,在一篇介绍“支持向量机”的文章中,可以找到三个关键词支持、向量、机,通过关键短语提取,可以得到支持向量机。 使用TextRank提取摘要
将每个句子看成图中的一个节点,若两个句子之间有相似性,认为对应的两个节点之间有一个无向有权边,权值是相似度。
通过pagerank算法计算得到的重要性最高的若干句子可以当作摘要。
论文中使用下面的公式计算两个句子Si和Sj的相似度:

分子是在两个句子中都出现的单词的数量。|Si|是句子i的单词数。
由于是有权图,PageRank公式略做修改:

但是很明显我只想计算关键字,如果把一个单词视为一个句子的话,那么所有句子(单词)构成的边的权重都是0(没有交集,没有相似性),所以分子分母的权值w约掉了,算法退化为PageRank。所以说,这里称关键字提取算法为PageRank也不为过。
TextRank代码
使用textrank源代码可以抽取摘要,也可以抽取关键词。
以snownlp的源代码为例,抽取摘要:
def solve(self): #针对抽关键句for cnt, doc in enumerate(self.docs):scores = self.bm25.simall(doc) #在本实现中,使用的不是前面提到的公式,而是使用的BM25算法,之前会有一个预处理(self.bm25 = BM25(docs)),然后求doc跟其他所有预料的相似程度。self.weight.append(scores)self.weight_sum.append(sum(scores)-scores[cnt])#需要减掉本身的权重。self.vertex.append(1.0)for _ in range(self.max_iter):m = []max_diff = 0for i in range(self.D):#每个文本都要计算与其他所有文档的链接,然后计算出重要程度。m.append(1-self.d)for j in range(self.D):if j == i or self.weight_sum[j] == 0:continuem[-1] += (self.d*self.weight[j][i]/ self.weight_sum[j]*self.vertex[j])#利用前面的公式求解if abs(m[-1] - self.vertex[i]) > max_diff:#找到该次迭代中,变化最大的一次情况。max_diff = abs(m[-1] - self.vertex[i])self.vertex = mif max_diff <= self.min_diff:#当变化最大的一次,仍然小于某个阈值时认为可以满足跳出条件,不用再循环指定的次数。breakself.top = list(enumerate(self.vertex))self.top = sorted(self.top, key=lambda x: x[1], reverse=True)def solve(self):#针对抽关键词for doc in self.docs:que = []for word in doc:if word not in self.words:self.words[word] = set()self.vertex[word] = 1.0que.append(word)if len(que) > 5:que.pop(0)for w1 in que:for w2 in que:if w1 == w2:continueself.words[w1].add(w2)self.words[w2].add(w1)for _ in range(self.max_iter):m = {}max_diff = 0tmp = filter(lambda x: len(self.words[x[0]]) > 0,self.vertex.items())tmp = sorted(tmp, key=lambda x: x[1] / len(self.words[x[0]]))for k, v in tmp:for j in self.words[k]:if k == j:continueif j not in m:m[j] = 1 - self.dm[j] += (self.d / len(self.words[k]) * self.vertex[k]) #利用之前提到的公式,简化的结果。for k in self.vertex:if k in m and k in self.vertex:if abs(m[k] - self.vertex[k]) > max_diff:max_diff = abs(m[k] - self.vertex[k])self.vertex = mif max_diff <= self.min_diff:breakself.top = list(self.vertex.items())self.top = sorted(self.top, key=lambda x: x[1], reverse=True)