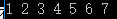注:PageRank原理另行查询
在介绍TextRank前,我想先给大家介绍下PageRank,实质上个人认为可以把TextRank当做PageRank2.0。
谷歌的两位创始人的佩奇和布林,借鉴了学术界评判学术论文重要性的通用方法,“那就是看论文的引用次数”。由此想到网页的重要性也可以根据这种方法来评价。于是PageRank的核心思想就诞生了:
- 如果个网页被很多其他网页链接到的话说明这个网页比较重要,也就是PageRank值会相对较高
- 如果一个PageRank值很高的网页链接到一个其他的网页,那么被链接到的网页的PageRank值会相应地因此而提高
TextRank算法
TextRank 算法是一种用于文本的基于图的排序算法。其基本思想来源于谷歌的 PageRank算法, 通过把文本分割成若干组成单元(单词、句子)并建立图模型, 利用投票机制对文本中的重要成分进行排序, 仅利用单篇文档本身的信息即可实现关键词提取、文摘。和 LDA、HMM 等模型不同, TextRank不需要事先对多篇文档进行学习训练, 因其简洁有效而得到广泛应用。
TextRank 一般模型可以表示为一个有向有权图 G =(V, E), 由点集合 V和边集合 E 组成, E 是V ×V的子集。图中任两点 Vi , Vj 之间边的权重为 wji , 对于一个给定的点 Vi, In(Vi) 为 指 向 该 点 的 点 集 合 , Out(Vi) 为点 Vi 指向的点集合。点 Vi 的得分定义如下:
用TextRank提取来提取关键词,用PageRank的思想来解释它:
- 如果一个单词出现在很多单词后面的话,那么说明这个单词比较重要
- 一个TextRank值很高的单词后面跟着的一个单词,那么这个单词的TextRank值会相应地因此而提高
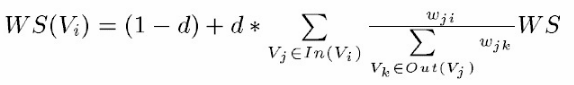
公式的意思:TextRank中一个单词\large i的权重取决于与在\large i前面的各个点\large j组成的\large (j,i)这条边的权重,以及\large j这个点到其他其他边的权重之和
其中, d 为阻尼系数, 取值范围为 0 到 1, 代表从图中某一特定点指向其他任意点的概率, 一般取值为 0.85。使用TextRank 算法计算图中各点的得分时, 需要给图中的点指定任意的初值, 并递归计算直到收敛, 即图中任意一点的误差率小于给定的极限值时就可以达到收敛, 一般该极限值取 0.0001。(个人觉得算法领域很多公式的可解释性不强,大多是为了解决某些限定条件,而人为选择的比较好的优化方式,比如阻尼系数d,(这个d通常取0.85实践出来的,好像没什么数学解释),实质上是为了给数据做一个平滑处理,实质是为了替代为零项)
关键词抽取的任务就是从一段给定的文本中自动抽取出若干有意义的词语或词组。TextRank算法是利用局部词汇之间关系(共现窗口)对后续关键词进行排序,直接从文本本身抽取。其主要步骤如下:
(1)把给定的文本T按照完整句子进行分割,即
(2)对于每个句子,进行分词和词性标注处理,并过滤掉停用词,只保留指定词性的单词,如名词、动词、形容词,即
,其中
是保留后的候选关键词。
(3)构建候选关键词图G = (V,E),其中V为节点集,由(2)生成的候选关键词组成,然后采用共现关系(co-occurrence)构造任两点之间的边,两个节点之间存在边仅当它们对应的词汇在长度为K的窗口中共现,K表示窗口大小,即最多共现K个单词。
(4)根据上面公式,迭代传播各节点的权重,直至收敛。
(5)对节点权重进行倒序排序,从而得到最重要的T个单词,作为候选关键词。
(6)由(5)得到最重要的T个单词,在原始文本中进行标记,若形成相邻词组,则组合成多词关键词。例如,文本中有句子“Matlab code for plotting ambiguity function”,如果“Matlab”和“code”均属于候选关键词,则组合成“Matlab code”加入关键词序列。
python编程实现
因为在了解textrank的时候,参考了jieba分词和TextRank4zh这2个开源库的写法。但是两者无论写法和运算规则都有很大出入,结合公式来说本人觉得jieba做的更符合公式,TextRank4zh更具有准确性,因为TextRank4zh在公式上面做了一定的优化。
Jieba分词TextRank:
- 对每个句子进行分词和词性标注处理
- 过滤掉除指定词性外的其他单词,过滤掉出现在停用词表的单词,过滤掉长度小于2的单词
- 将剩下的单词中循环选择一个单词,将其与其后面4个单词分别组合成4条边。
例如: [‘有’,‘媒体’, ‘曝光’,‘高圆圆’, ‘和’, ‘赵又廷’,‘现身’, ‘台北’, ‘桃园’,‘机场’,‘的’, ‘照片’]
对于‘媒体‘这个单词,就有(‘媒体’, ‘曝光’)、(‘媒体’, ‘圆’)、(‘媒体’, ‘和’)、(‘媒体’, ‘赵又廷’)4条边,且每条边权值为1,当这条边在之后再次出现时,权值再在基础上加1.
- 有了这些数据后,我们就可以构建出候选关键词图G=(V,E),图的概念有基础的人可能会很好理解,不理解其实也没关系,按上面例子,你只用知道这一步我们把2个单词组成的边,和其权值记录了下来。
- 这样我们就可以套用TextRank的公式,迭代传播各节点的权值,直至收敛。
- 对结果中的Rank值进行倒序排序,筛选出前面的几个单词,就是我们需要的关键词了。
<span style="color:#000000"><code>def textrank(self, sentence, topK=20, withWeight=False, allowPOS=('ns', 'n', 'vn', 'v'), withFlag=False):self.pos_filt = frozenset(allowPOS)# 定义无向有权图g = UndirectWeightedGraph()# 定义共现词典cm = defaultdict(int)# 分词words = tuple(self.tokenizer.cut(sentence))# 依次遍历每个词for i, wp in enumerate(words):# 词i 满足过滤条件if self.pairfilter(wp):# 依次遍历词i 之后窗口范围内的词for j in xrange(i + 1, i + self.span):# 词j 不能超出整个句子if j >= len(words):break# 词j不满足过滤条件,则跳过if not self.pairfilter(words[j]):continue# 将词i和词j作为key,出现的次数作为value,添加到共现词典中if allowPOS and withFlag:cm[(wp, words[j])] += 1else:cm[(wp.word, words[j].word)] += 1# 依次遍历共现词典的每个元素,将词i,词j作为一条边起始点和终止点,共现的次数作为边的权重for terms, w in cm.items():g.addEdge(terms[0], terms[1], w)# 运行textrank算法nodes_rank = g.rank()# 根据指标值进行排序if withWeight:tags = sorted(nodes_rank.items(), key=itemgetter(1), reverse=True)else:tags = sorted(nodes_rank, key=nodes_rank.__getitem__, reverse=True)# 输出topK个词作为关键词if topK:return tags[:topK]else:return tags
</code></span>关于有向图的数据结构:
<span style="color:#000000"><code>def addEdge(self, start, end, weight):# use a tuple (start, end, weight) instead of a Edge objectself.graph[start].append((start, end, weight))self.graph[end].append((end, start, weight))
</code></span>关于TextRank的手写:
<span style="color:#000000"><code>def rank(self):ws = defaultdict(float)outSum = defaultdict(float)wsdef = 1.0 / (len(self.graph) or 1.0)# 初始化各个结点的权值# 统计各个结点的出度的次数之和for n, out in self.graph.items():ws[n] = wsdefoutSum[n] = sum((e[2] for e in out), 0.0)# this line for build stable iterationsorted_keys = sorted(self.graph.keys())# 遍历若干次for x in xrange(10): # 10 iters# 遍历各个结点for n in sorted_keys:s = 0# 遍历结点的入度结点for e in self.graph[n]:# 将这些入度结点贡献后的权值相加# 贡献率 = 入度结点与结点n的共现次数 / 入度结点的所有出度的次数s += e[2] / outSum[e[1]] * ws[e[1]]# 更新结点n的权值ws[n] = (1 - self.d) + self.d * s(min_rank, max_rank) = (sys.float_info[0], sys.float_info[3])# 获取权值的最大值和最小值for w in itervalues(ws):if w < min_rank:min_rank = wif w > max_rank:max_rank = w# 对权值进行归一化for n, w in ws.items():# to unify the weights, don't *100.ws[n] = (w - min_rank / 10.0) / (max_rank - min_rank / 10.0)return ws
</code></span>jieba.analyse.textrank完整源码如下:
<span style="color:#000000"><code>#!/usr/bin/env python
# -*- coding: utf-8 -*-from __future__ import absolute_import, unicode_literals
import sys
from operator import itemgetter
from collections import defaultdict
import jieba.posseg
from .tfidf import KeywordExtractor
from .._compat import *class UndirectWeightedGraph:d = 0.85def __init__(self):self.graph = defaultdict(list)def addEdge(self, start, end, weight):# use a tuple (start, end, weight) instead of a Edge objectself.graph[start].append((start, end, weight))self.graph[end].append((end, start, weight))def rank(self):ws = defaultdict(float)outSum = defaultdict(float)wsdef = 1.0 / (len(self.graph) or 1.0)for n, out in self.graph.items():ws[n] = wsdefoutSum[n] = sum((e[2] for e in out), 0.0)# this line for build stable iterationsorted_keys = sorted(self.graph.keys())for x in xrange(10): # 10 itersfor n in sorted_keys:s = 0for e in self.graph[n]:s += e[2] / outSum[e[1]] * ws[e[1]]ws[n] = (1 - self.d) + self.d * s(min_rank, max_rank) = (sys.float_info[0], sys.float_info[3])for w in itervalues(ws):if w < min_rank:min_rank = wif w > max_rank:max_rank = wfor n, w in ws.items():# to unify the weights, don't *100.ws[n] = (w - min_rank / 10.0) / (max_rank - min_rank / 10.0)return wsclass TextRank(KeywordExtractor):def __init__(self):self.tokenizer = self.postokenizer = jieba.posseg.dtself.stop_words = self.STOP_WORDS.copy()self.pos_filt = frozenset(('ns', 'n', 'vn', 'v'))self.span = 5def pairfilter(self, wp):return (wp.flag in self.pos_filt and len(wp.word.strip()) >= 2and wp.word.lower() not in self.stop_words)def textrank(self, sentence, topK=20, withWeight=False, allowPOS=('ns', 'n', 'vn', 'v'), withFlag=False):"""Extract keywords from sentence using TextRank algorithm.Parameter:- topK: return how many top keywords. `None` for all possible words.- withWeight: if True, return a list of (word, weight);if False, return a list of words.- allowPOS: the allowed POS list eg. ['ns', 'n', 'vn', 'v'].if the POS of w is not in this list, it will be filtered.- withFlag: if True, return a list of pair(word, weight) like posseg.cutif False, return a list of words"""self.pos_filt = frozenset(allowPOS)g = UndirectWeightedGraph()cm = defaultdict(int)words = tuple(self.tokenizer.cut(sentence))for i, wp in enumerate(words):if self.pairfilter(wp):for j in xrange(i + 1, i + self.span):if j >= len(words):breakif not self.pairfilter(words[j]):continueif allowPOS and withFlag:cm[(wp, words[j])] += 1else:cm[(wp.word, words[j].word)] += 1for terms, w in cm.items():g.addEdge(terms[0], terms[1], w)nodes_rank = g.rank()if withWeight:tags = sorted(nodes_rank.items(), key=itemgetter(1), reverse=True)else:tags = sorted(nodes_rank, key=nodes_rank.__getitem__, reverse=True)if topK:return tags[:topK]else:return tagsextract_tags = textrank</code></span>