数字信封是指发送方使用接收方的公钥来加密对称密钥后所得的数据,其目的是用来确保对称密钥传输的安全性。采用数字信封时,接收方需要使用自己的私钥才能打开数字信封得到对称密钥。
数字信封的加/解密过程如图所示。甲也要事先获得乙的公钥,具体说明如下(对应图中的数字序号):
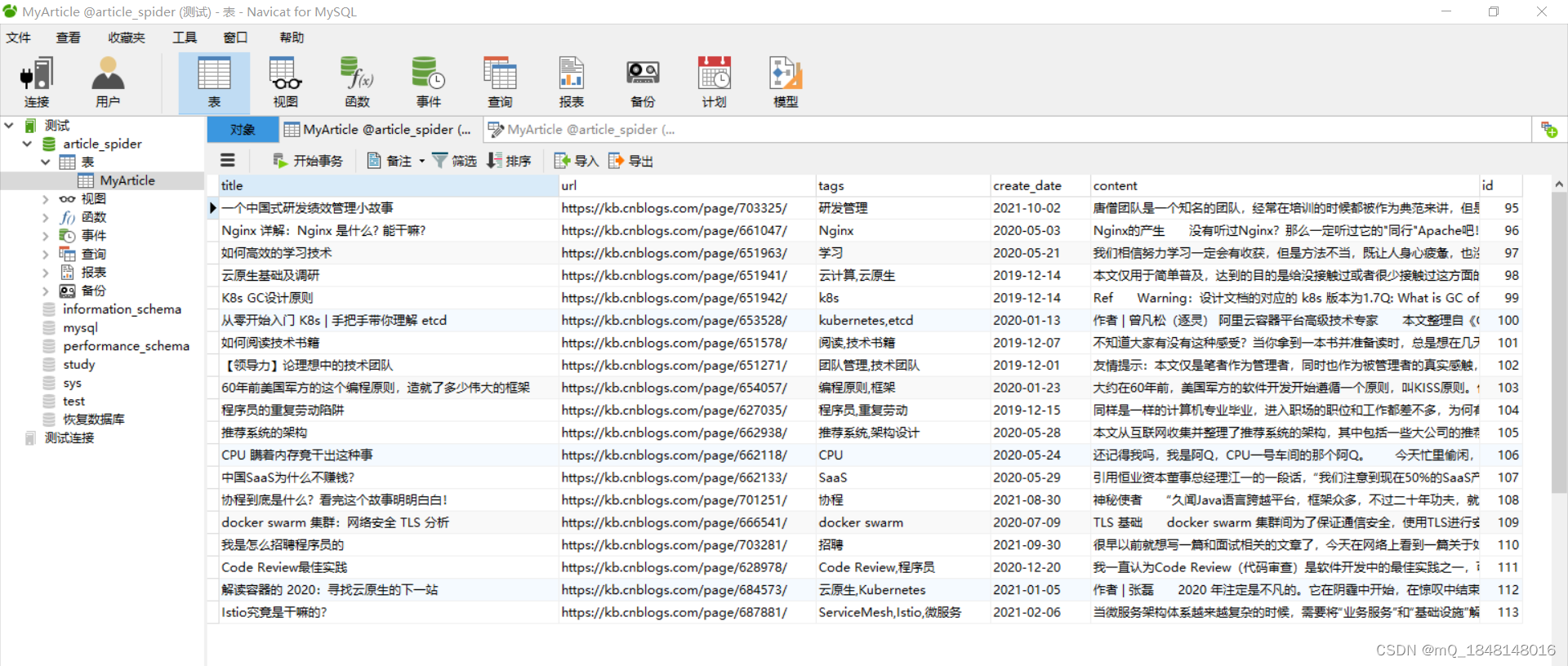
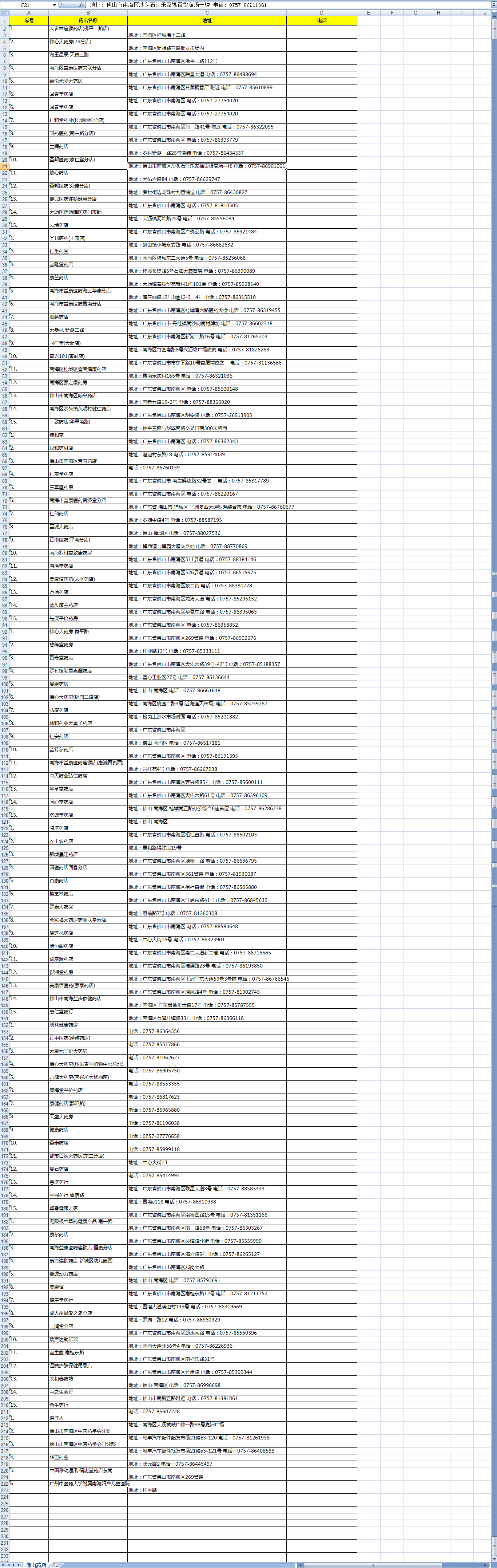
数字信封的加解密过程示意图

(1)甲使用对称密钥对明文进行加密,生成密文信息。
(2)甲使用乙的公钥加密对称密钥,生成数字信封。
(3)甲将数字信封和密文信息一起发送给乙。
(4)乙接收到甲的加密信息后,使用自己的私钥打开数字信封,得到对称密钥。
(5)乙使用对称密钥对密文信息进行解密,得到最初的明文。
从以上加/解密过程中,可以看出,数字信封技术结合了对称密钥加密和公钥加密的优点,解决了对称密钥的发布安全问题,和公钥加密速度慢问题,提高了安全性、扩展性和效率等。但是,数字信封技术还是有一个比较大的问题,那就是无法确保信息是来自真正的对方。
试想一下如果攻击者拦截甲发给乙的信息,用自己的对称密钥加密一份伪造的信息,并用乙的公钥(攻击者已获知了乙对外公开的公钥)加密攻击者自己的对称密钥,生成数字信封;然后把伪造的加密信息,以及伪造的数字信封一起发送给乙。乙收到加密信息后,用自己的私钥可以成功解密数字信封,再利用还原出的对称密钥(这个是攻击者的对称公钥)即可还原出加密的明文信息了,这样一来乙则始终认为这份本来是攻击者伪造的信息是甲发送的信息。这样的结局可能是损失惨重,如攻击者修改了甲发给乙的投标书的标的。
---------------------
转:https://blog.csdn.net/lycb_gz/article/details/78058747