公司要求我采集网页中的某些数据,以下是我采集的步骤和思路,比较基础。
一.首先我是通过抓取网页源代码的方式,根据源代码,获取各种标签中的数据
public class GetData {//数据抓取核心类// 获取网页数据/** @param url:目标网址** @param encoding:编码*///url抓取数据(参数URL:就是你要抓数据的地址。如:http://www.cnev.cn/)public static String urlClimb(String url) throws Exception{URL getUrl =new URL(url); //创建URl连接HttpURLConnection connection = (HttpURLConnection) getUrl.openConnection(); //建立连接connection.connect(); //打开连接BufferedReader reader = new BufferedReader(new InputStreamReader(connection.getInputStream(), "utf-8")); //创建输入流并设置编码StringBuffer sb = new StringBuffer();String lines = null;while ((lines = reader.readLine()) != null) {lines = new String(lines.getBytes(), "utf-8"); //读取流的一行,设置编码sb = sb.append(lines + "\n");}reader.close(); //关闭流connection.disconnect(); //销毁连接return sb.toString(); //返回抓取的数据(注意,这里是抓取了访问的网站的全部数据)}
}
二.通过Jsoup获取标签体内容(以京东为例)
(1)抓取title
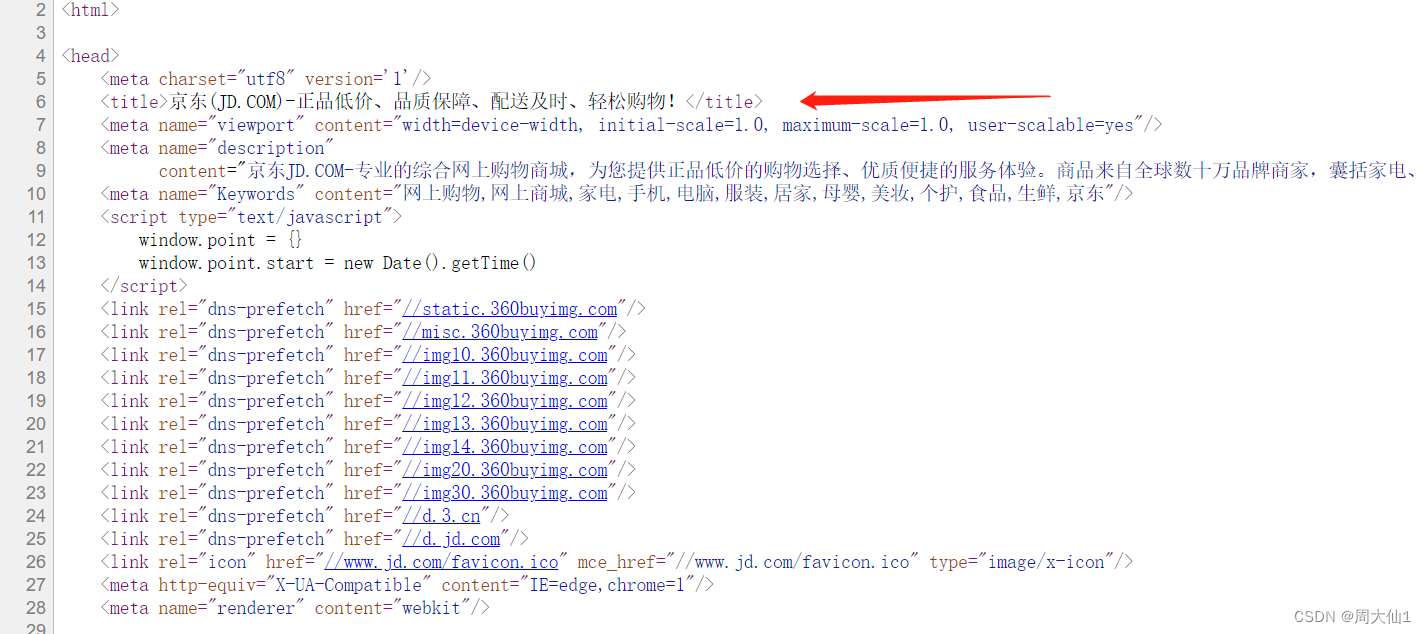
(2)抓取标签中文本内容

(3)抓取所有的a标签中内容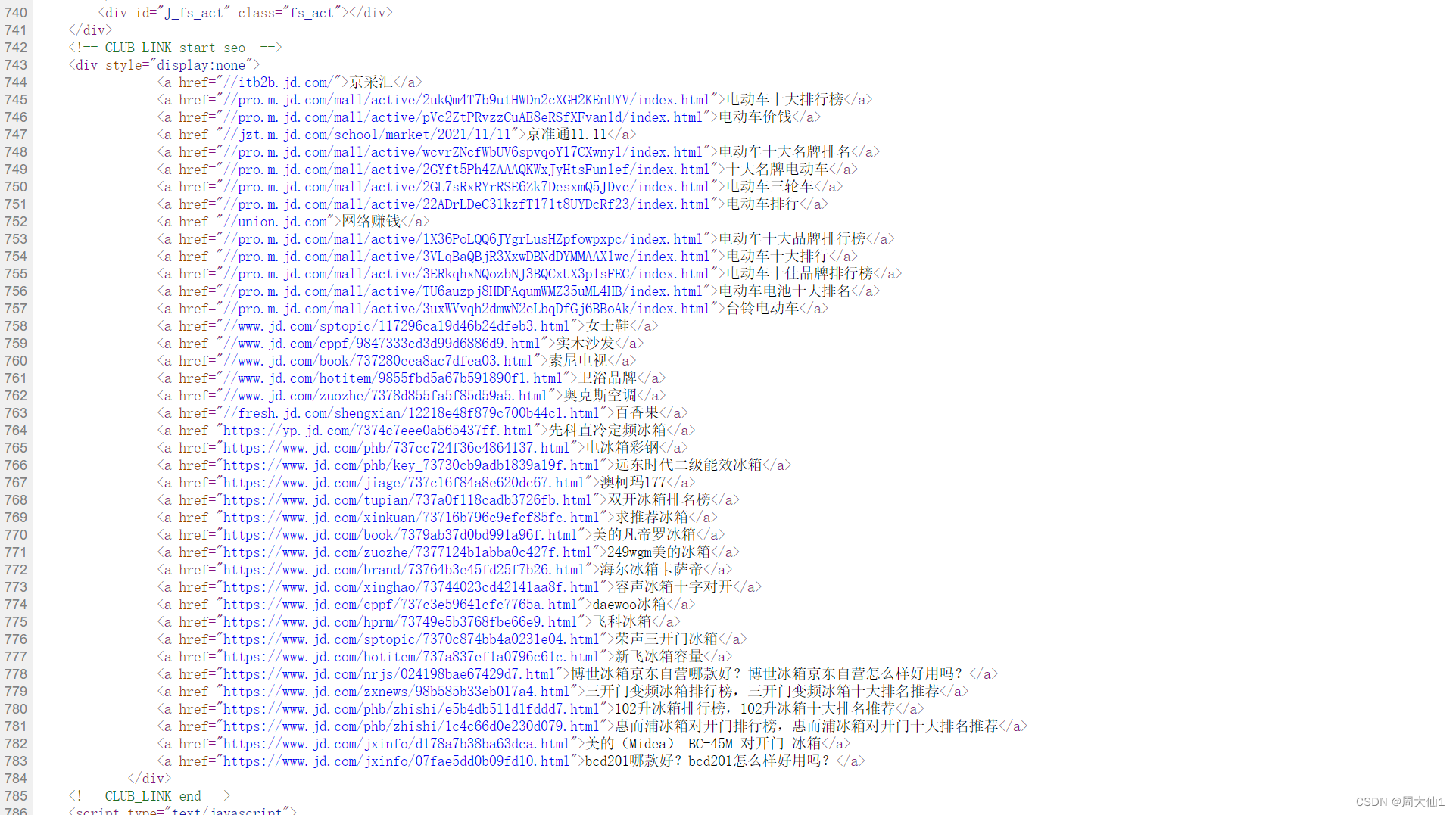
代码如下
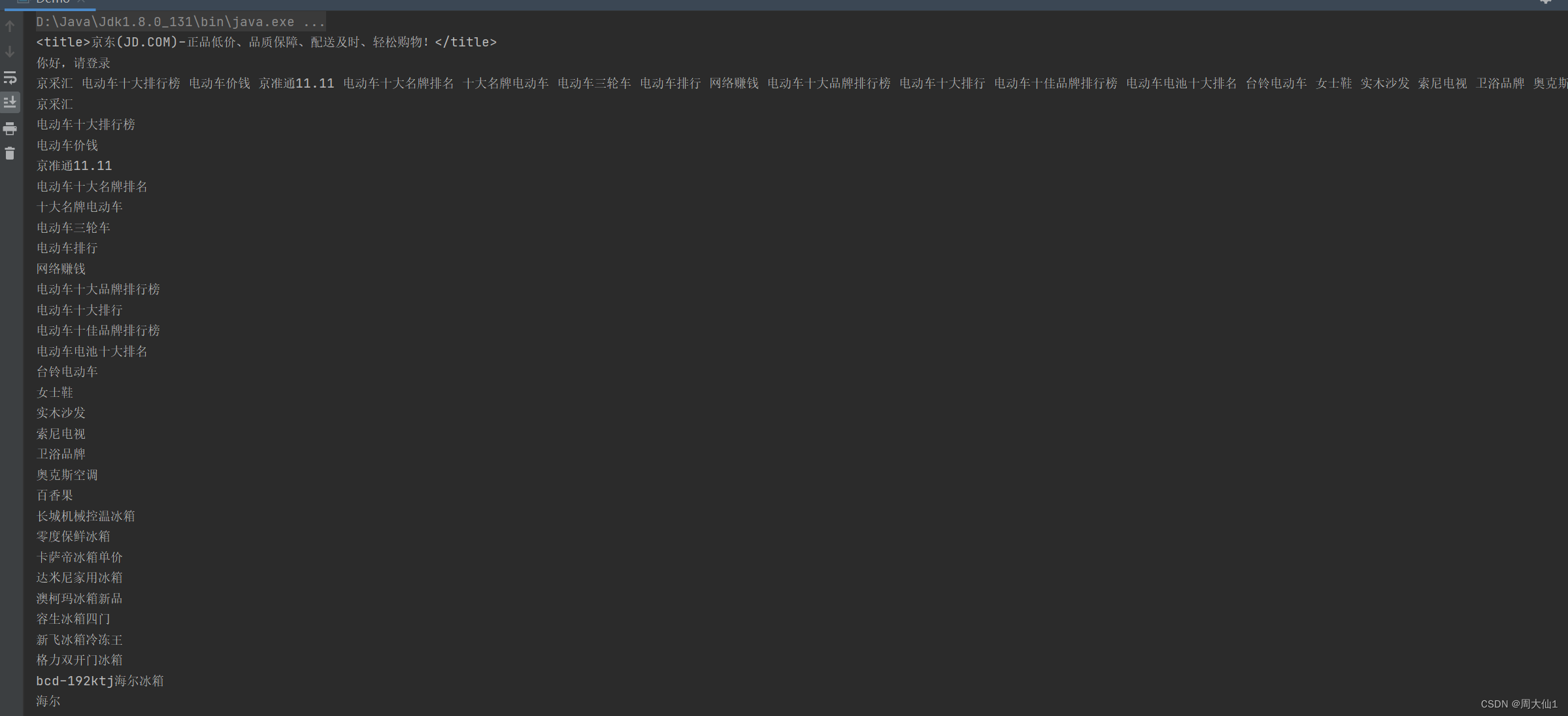
public class Demo {public static void main(String[] args) throws Exception {//第一条抓取title标签String result = GetData.urlClimb("https://www.jd.com/?cu=true&utm_source=baidu-pinzhuan&utm_medium=cpc&utm_campaign=t_288551095_baidupinzhuan&utm_term=0f3d30c8dba7459bb52f2eb5eba8ac7d_0_e931e367f5e34e07b1cb328f3bb899df");Document parse = Jsoup.parse(result);Elements title = parse.getElementsByTag("title");String Title = title.toString();System.out.println(Title);//抓“你好,请先登录”Elements login = parse.getElementsByClass("link-login");String Login = login.text();//.text()直接获取标签体中的内容System.out.println(Login);//抓取a标签所有内容Elements style = parse.getElementsByAttributeValue("style", "display:none");String data = style.text();System.out.println(data);//每个抓取到的中间都会有空格,所以直接用String中的split方法,全存入数组,遇到一个空格存一次String[] split = data.split(" ");for (int i=0;i<split.length;i++){System.out.println(split[i]);}}
}下面是结果
有帮助的兄弟们点个赞,一起多交流,我也是小菜鸡一枚,大家一起进步