目录
一、新建项目
二、程序的编写
三、数据的爬取
一、新建项目
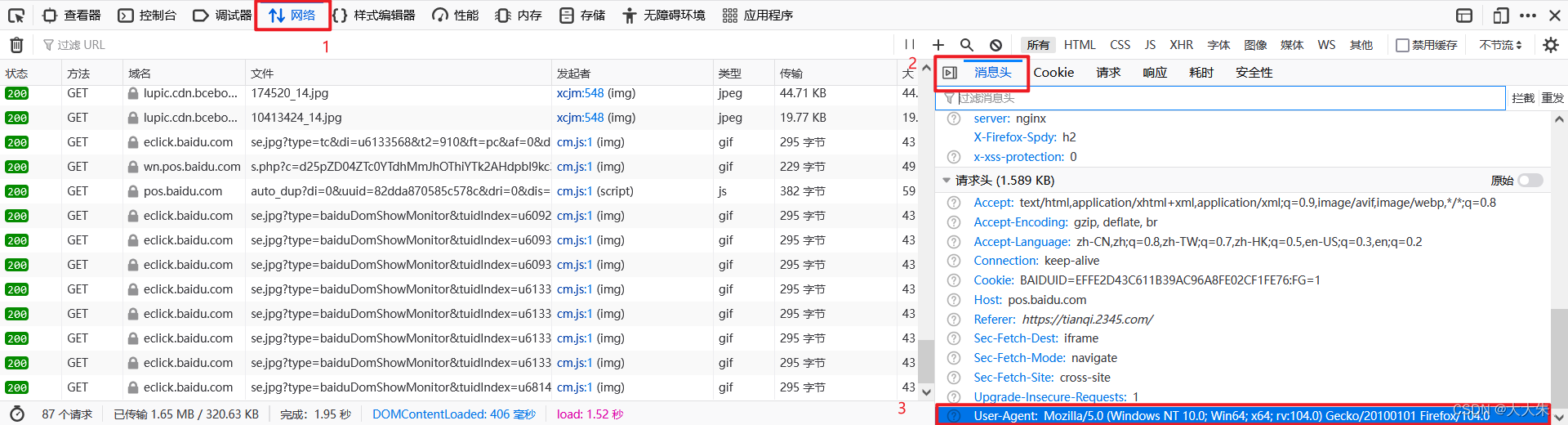
1.在cmd窗口输入scrapy startproject [项目名称] 创建爬虫项目
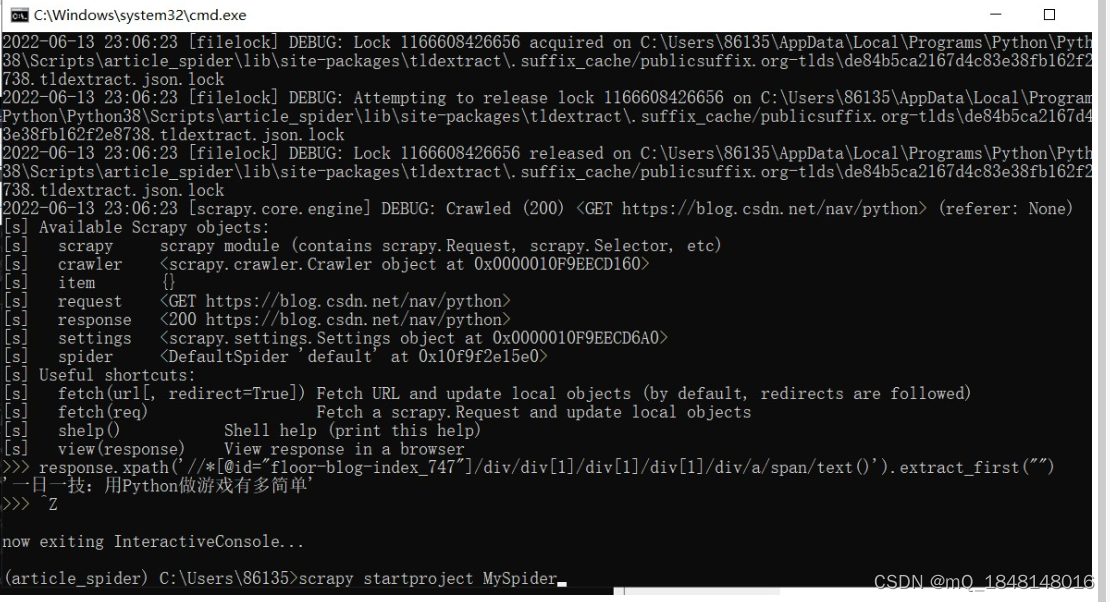
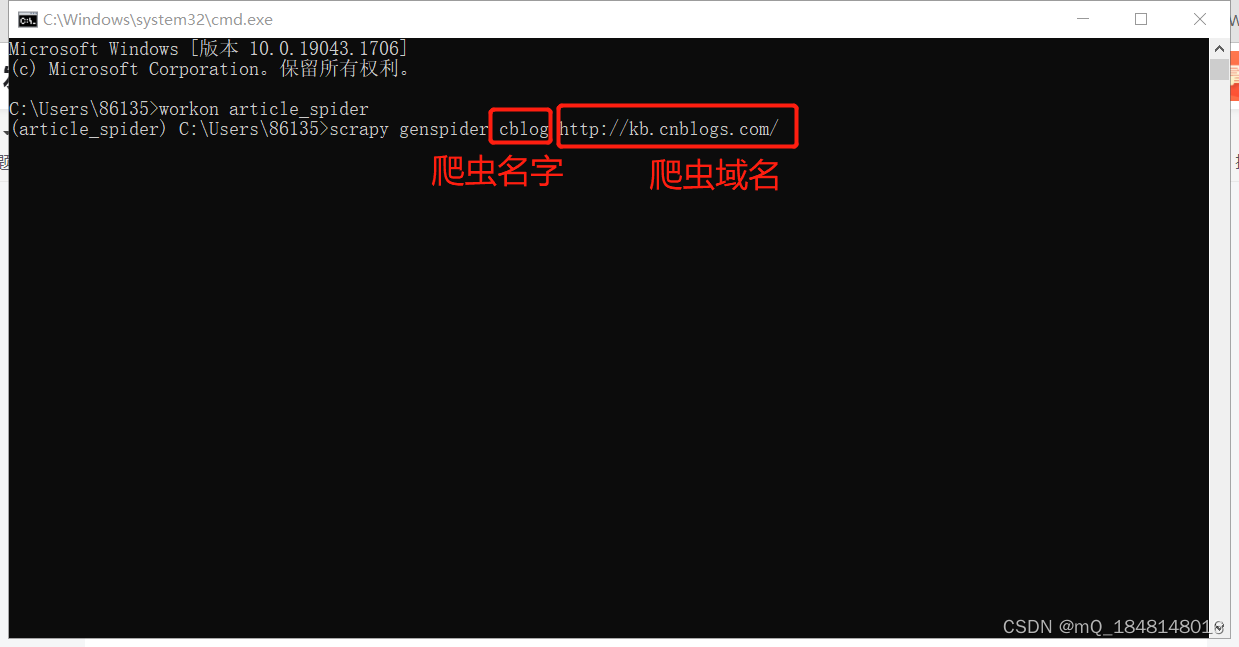
接着创建爬虫文件,scrapy genspider [爬虫名字] [爬虫域名]
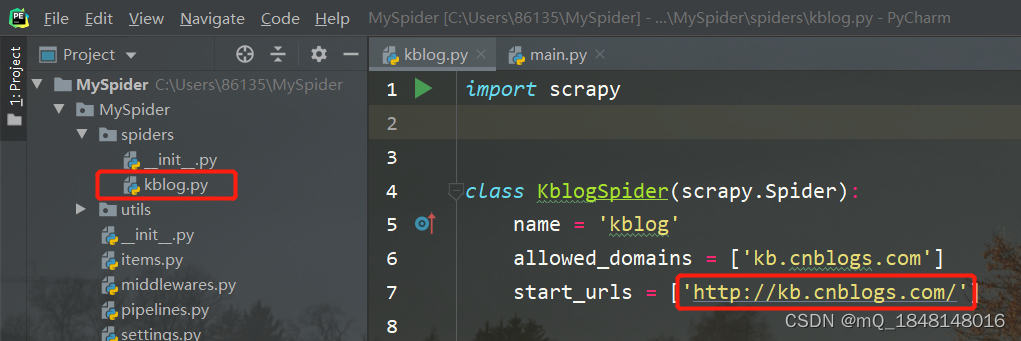
打开pycharm项目,就可以看到生成的cblog.py文件
二、程序的编写
1.在项目下新建main.py,写入以下代码,方便后续项目调试
main.py
from scrapy.cmdline import executeimport sys
import ossys.path.append(os.path.dirname(os.path.abspath(__file__)))execute(["scrapy", "crawl", "kblog"])
2.编写爬虫程序
kblog.py
import scrapy
from urllib import parse
import re
import json
import scrapy
import requests
from scrapy import Request
from scrapy import Selectorfrom urllib import parse
from scrapy import Request
from MySpider.utils import common
from MySpider.items import KBlogArticleItemclass KblogSpider(scrapy.Spider):name = 'kblog'allowed_domains = ['kb.cnblogs.com']start_urls = ['http://kb.cnblogs.com/']# 解析每个网页的urldef parse(self, response):post_nodes = response.xpath('//*[@id="wrapper"]/div[4]/div/div[2]/div')[1:20] # 解析该网页的list_url[1:20]for post_node in post_nodes: # 遍历解析urlpost_url = post_node.xpath('./div/div[1]/p/a/@href').extract_first("")yield Request(url=parse.urljoin(response.url, post_url), # 通过yield把每个url保存到生成器,再通过callback方法,将每个url传入parse_detail()函数进行数据解析callback=self.parse_detail)# 解析每个url的详细数据def parse_detail(self, response):article_item = KBlogArticleItem() # 实例化items# 解析数据title = response.xpath('//*[@id="left_content_pages"]/h1/a/text()').extract_first("") # 标题a = response.xpath('//*[@id="left_content_pages"]/div[1]//text()').extract()a = "".join(a)a = re.findall(r"(\d+)-(\d+)-(\d+)", a)create_date = "-".join(a[0]) # 发布时间content = response.xpath('//*[@id="left_content_pages"]/div[2]//text()').extract() # 内容tag_list = response.xpath('//*[@id="panelTags"]/div//a/text()').extract()tags = ",".join(tag_list) # 标签# 存入item对象中article_item['title'] = titlearticle_item['create_date'] = create_datearticle_item['content'] = contentarticle_item['tags'] = tagsarticle_item['url'] = response.urlarticle_item['url_object_id'] = common.get_md5(article_item["url"])yield article_item
3.在items.py文件中创建items函数与爬取数据对应
items.py
import scrapyclass KBlogArticleItem(scrapy.Item):title = scrapy.Field()create_date = scrapy.Field()url = scrapy.Field()url_object_id = scrapy.Field()tags = scrapy.Field()content = scrapy.Field()pass
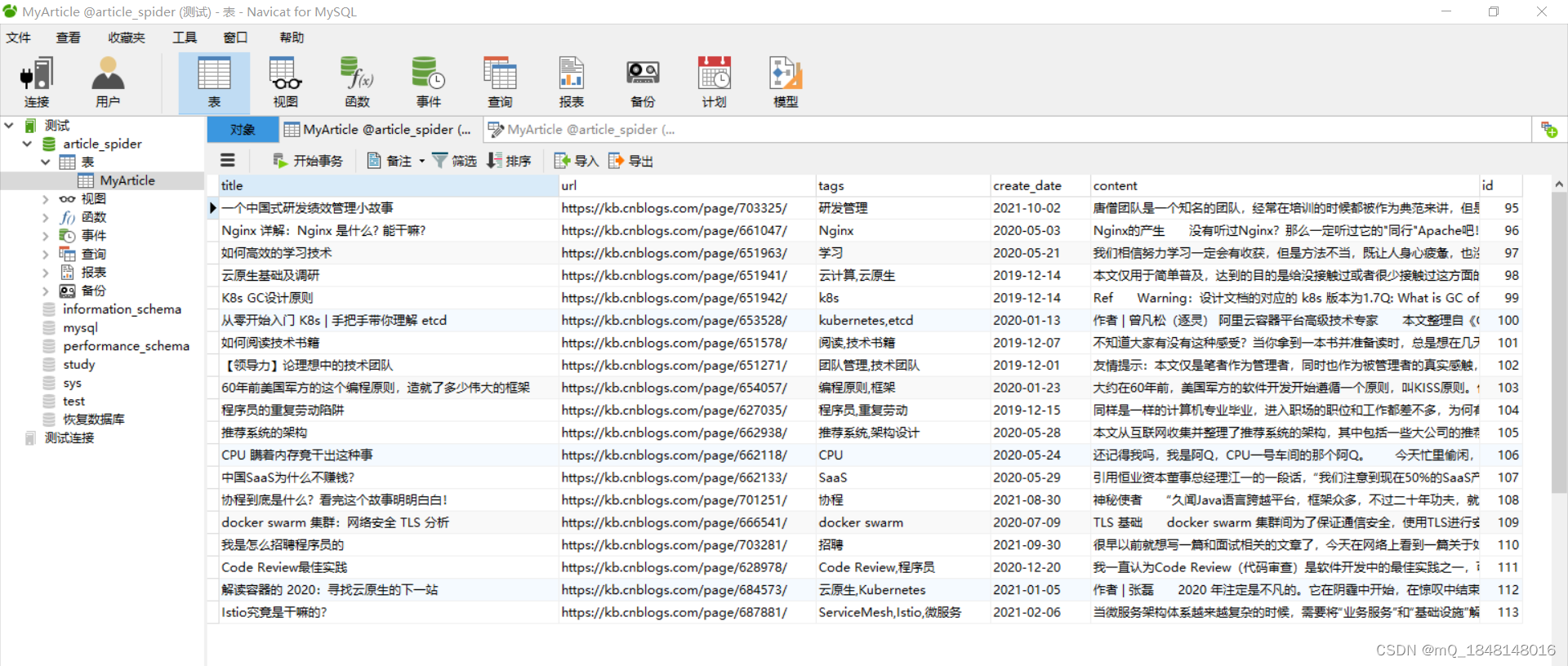
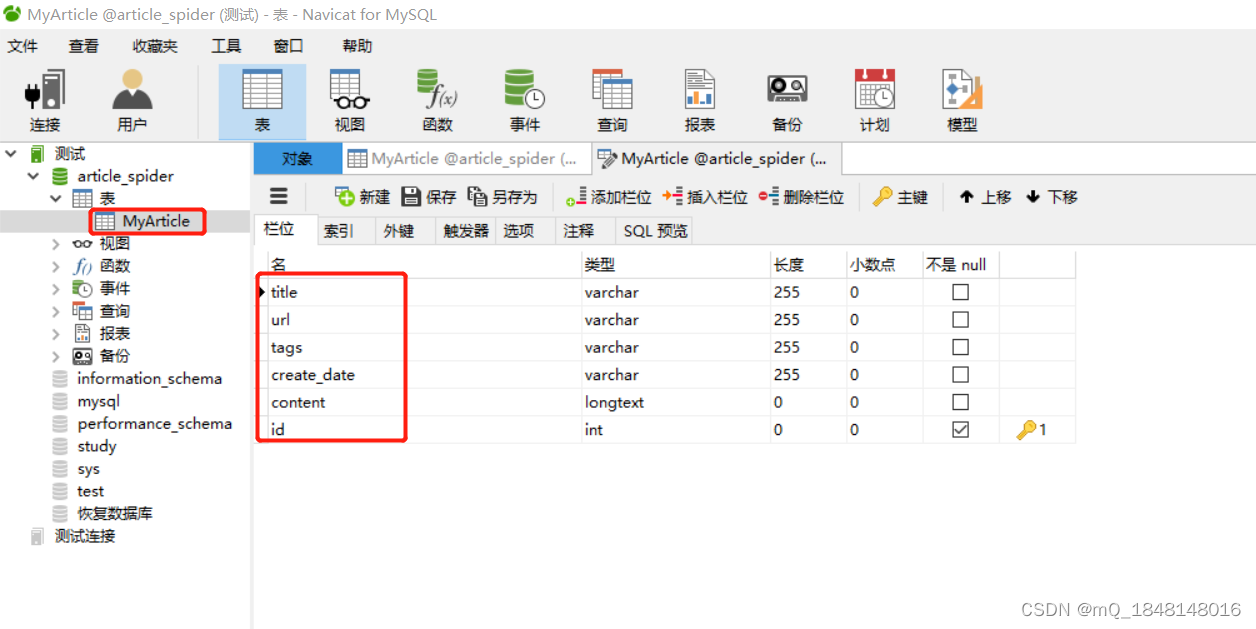
4.在数据库中新建数据表MyArticle,数据表列名属性与爬取的数据对应
MyArticle.sql
5.在pipelines.py中新建数据库函数,用于保存数据到数据库
pipelines.py
import MySQLdbclass MysqlPipeline(object):def __init__(self):# 连接数据库self.conn = MySQLdb.connect(host="192.168.186.130", user="root", password="123456", database="article_spider", charset='utf8', use_unicode=True)self.cursor = self.conn.cursor()def process_item(self, item, spider):# 数据库插入语句insert_sql = """insert into MyArticle(title,url,tags,create_date,content)values(%s,%s,%s,%s,%s)"""# 数据参数列表parms = list()parms.append(item.get('title', ""))parms.append(item.get('url', ""))# parms.append(item.get('url_object_id', ""))parms.append(item.get('tags', ""))parms.append(item.get('create_date', "1970-07-01"))content = "".join([str(x) for x in (item.get('content', ""))])parms.append(content.lstrip())# 执行数据库语句,将数据存入SQL数据库中self.cursor.execute(insert_sql, tuple(parms))self.conn.commit()return item6.在setting中添加pipelines中的数据库函数,并将robot协议关闭
setting.py
ROBOTSTXT_OBEY = FalseITEM_PIPELINES = {'MySpider.pipelines.MysqlPipeline': 1,'MySpider.pipelines.MyspiderPipeline': 300,
}
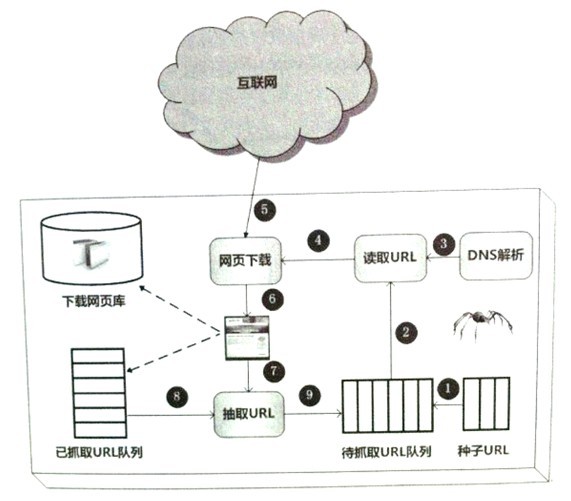
三、数据的爬取
在main函数运行该项目,最终爬取的数据将保存到SQL数据库上。