论文:https://arxiv.org/pdf/1911.11929.pdf
CSPNet全称是Cross Stage Partial Network,主要从一个比较特殊的角度切入,能够在降低20%计算量的情况下保持甚至提高CNN的能力。
跨阶段局部网络(CSPNet)是 Wang 等人于 2019 年提出的新型骨干网络,主要用于增强 CNN 的学习能力。CSPNet 结构通过将浅层的特征图在通道维度一分为二,一部分经由特征提取模块(比如残差块)向后传播,另一部分则经过跨阶段层次结构直接与特征提取模块的输出进行合并,实现了更加丰富的梯度组合,并且在准确性不变或者提高的基础上可以减少了 10%~20%的网络参数量。CSPNet 结构可以轻松应用于 ResNet、ResNeXt和 DenseNet等常用 CNN模型,在同样的测试条件(分类或检测)下可以稍微提高模型的学习能力。CSPNet结构应用于 ResNe(X)t 之后的网络结构如图。
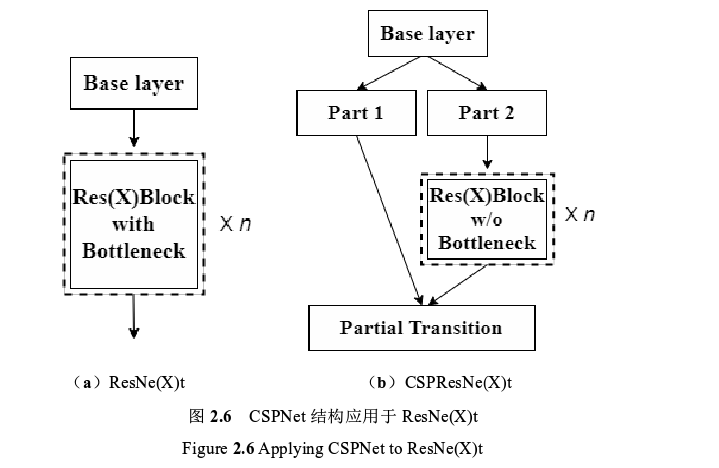
图 2.6 可以看到, 在 ResNe(X)t 结构中,输入特征图经过多个残差块层层向后传递,由于堆叠在一起的各个残差块结构大同小异,导致反向传播的梯度信息重复率比较高,容易出现过多的冗余计算量;而在 CSPResNe(X)t 结构中,输入特征图在通道维度被分为两个部分,第一部分被保留下来,第二部分则经过多个残差块向后传递,最后将两者在 CSPNet 结构的末端进行合并,这样跨阶段拆分与合并的网络构造有效降低了梯度信息重复的可能性,增加了梯度组合的多样性,有利于提高模型的学习能力,并且降低了网络中的数据传递量与计算量。
YOLOv5 中的 CSPNet代码:
import torch
import torch.nn as nndef autopad(k, p=None): # kernel, padding# Pad to 'same'if p is None:p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-padreturn pclass Conv(nn.Module):# Standard convolutiondef __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groupssuper(Conv, self).__init__()self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)self.bn = nn.BatchNorm2d(c2)self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())def forward(self, x):return self.act(self.bn(self.conv(x)))def fuseforward(self, x):return self.act(self.conv(x))class Bottleneck(nn.Module):# Standard bottleneckdef __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansionsuper(Bottleneck, self).__init__()c_ = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, c_, 1, 1)self.cv2 = Conv(c_, c2, 3, 1, g=g)self.add = shortcut and c1 == c2def forward(self, x):return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))class BottleneckCSP(nn.Module):# CSP Bottleneck https://github.com/WongKinYiu/CrossStagePartialNetworksdef __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansionsuper(BottleneckCSP, self).__init__()c_ = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, c_, 1, 1)self.cv2 = nn.Conv2d(c1, c_, 1, 1, bias=False)self.cv3 = nn.Conv2d(c_, c_, 1, 1, bias=False)self.cv4 = Conv(2 * c_, c2, 1, 1)self.bn = nn.BatchNorm2d(2 * c_) # applied to cat(cv2, cv3)self.act = nn.LeakyReLU(0.1, inplace=True)self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])def forward(self, x):y1 = self.cv3(self.m(self.cv1(x)))y2 = self.cv2(x)return self.cv4(self.act(self.bn(torch.cat((y1, y2), dim=1))))bcsp = BottleneckCSP(1,2)
print(bcsp)class Bottleneck(nn.Module):

class BottleneckCSP(nn.Module):

output
BottleneckCSP((cv1): Conv((conv): Conv2d(1, 1, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn): BatchNorm2d(1, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act): SiLU())(cv2): Conv2d(1, 1, kernel_size=(1, 1), stride=(1, 1), bias=False)(cv3): Conv2d(1, 1, kernel_size=(1, 1), stride=(1, 1), bias=False)(cv4): Conv((conv): Conv2d(2, 2, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn): BatchNorm2d(2, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act): SiLU())(bn): BatchNorm2d(2, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act): LeakyReLU(negative_slope=0.1, inplace=True)(m): Sequential((0): Bottleneck((cv1): Conv((conv): Conv2d(1, 1, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn): BatchNorm2d(1, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act): SiLU())(cv2): Conv((conv): Conv2d(1, 1, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn): BatchNorm2d(1, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act): SiLU())))
)
reference:
[1]朱杰. 基于YOLOv4-tiny改进的口罩检测算法[D].中国科学院大学(中国科学院长春光学精密机械与物理研究所),2021.DOI:10.27522/d.cnki.gkcgs.2021.000058.
[2]https://github.com/WongKinYiu/CrossStagePartialNetworks
[3]https://zhuanlan.zhihu.com/p/116611721
[4]https://www.cnblogs.com/dan-baishucaizi/p/14267602.html#4bottleneckcsp-csp%E7%93%B6%E9%A2%88%E5%B1%82