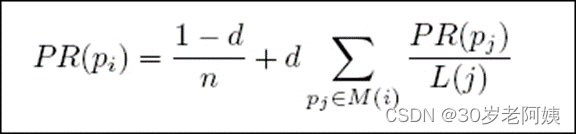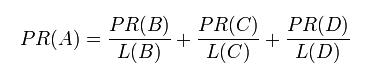大数据管理与分析实验报告
实验一 大数据系统基本实验
实验二 文档倒排索引算法实现
实验三 PageRank 算法实现
实验目的
PageRank 网页排名的算法,曾是Google 发家致富的法宝。用于衡量特定网页相对于搜索引擎索引中的其他网页而言的重要程度。通过对PageRank 的编程在Hadoop 和Spark 上的实现,熟练掌握MapReduce 程序与Spark 程序在集群上的提交与执行过程,加深对MapReduce 与Spark 的理解。
实验平台
- 操作系统:Ubuntu Kylin
- Hadoop 版本:2.10.1
- JDK 版本:1.8
- Java IDE:Eclipse 3.8
实验内容
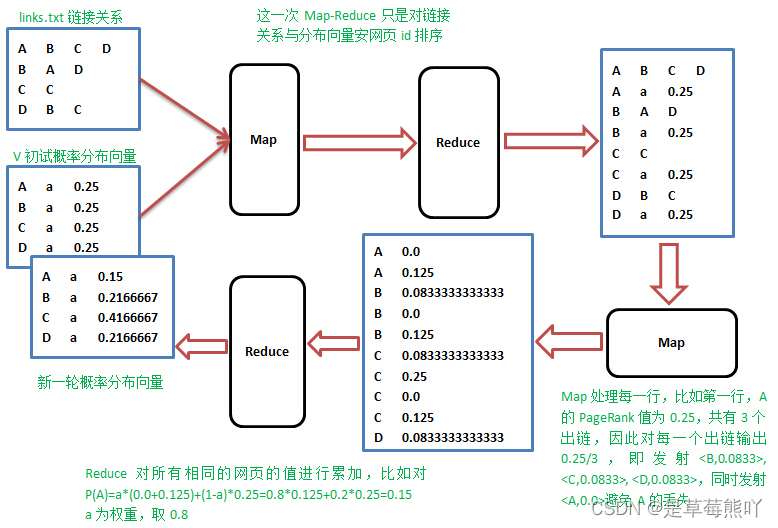
在本地eclipse 上分别使用MapReduce 和Spark 实现PageRank 算法,Spark程序可采用Java、Python、Scala 等语言进行编程。数据集中每一行内容的格式:网页+\t+该网页链接到的网页的集合(相互之间用英文逗号分开)。例如,下图为其中一行的数据,因为一行显示不出来所以使用多行显示。

要求能够利用PageRank 算法的思想计算出每个网页的PR 值(迭代10 次即可),在伪分布式环境下完成程序的编写和测试。
实验要求
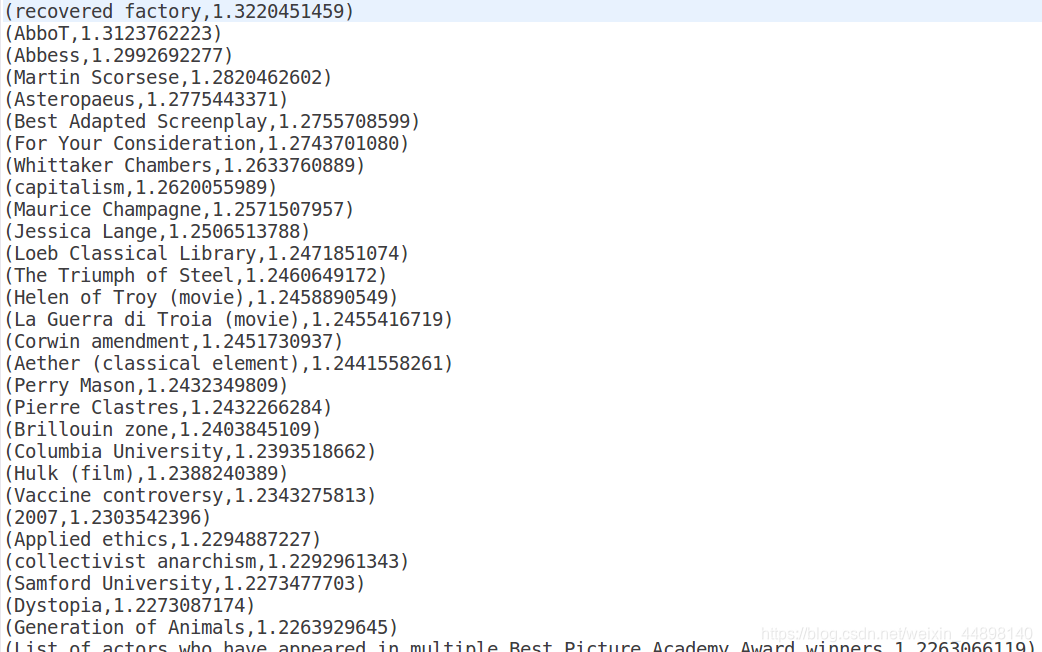
实验结果为连续迭代10 次后的输出结果
两个程序输出的结果格式均为(网页,PR 值),其中PR 值保留10 位小数,
部分结果如下所示:

标准输出存放在hdfs 上/output/PageRank 目录,使用diff 命令判断自己的输出结果与标准输出的差异
diff <(hdfs dfs -cat /output/FinalRank/part-r-00000) <(cat /home/hadoop/Desktop/part-r-00000)
实验思路
PageRank算法不再介绍。
代码中主要有3个类:GraphBuilder,PageRankIter,PageRankViewer,分别完成构建网页之间的超链接图,迭代计算各个网页的PageRank值,按PageRank值从大到小输出,通过PageRankDriver实现多趟MapReduce的处理。
代码中有一些注释说明,不算很难,按照课上和PPT思路完成即可。
实现代码
package org.apache.hadoop.examples;import java.io.IOException;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;public class exp3 {// 建立网页之间的超链接图public static class GraphBuilder {public static class GraphBuilderMapper extends Mapper<LongWritable, Text, Text, Text> {@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {// map:逐行分析原始数据,输出<URL, (PR_init, link_list)>String pr = "1.0"; // PR值初始化为1.0String[] tmp = value.toString().split("\t");context.write(new Text(tmp[0]), new Text(pr + "\t" + tmp[1]));}}public static void main(String[] args) throws Exception {Configuration conf = new Configuration();Job job = Job.getInstance(conf, "GraphBuilder");job.setJarByClass(GraphBuilder.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(Text.class);job.setMapperClass(GraphBuilderMapper.class);FileInputFormat.addInputPath(job, new Path(args[0]));FileOutputFormat.setOutputPath(job, new Path(args[1]));job.waitForCompletion(true);}}// 迭代计算各个网页的PageRank值public static class PageRankIter {private static final double d = 0.85; // damping阻尼系数public static class PRIterMapper extends Mapper<LongWritable, Text, Text, Text> {@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {String[] tmp = value.toString().split("\t");// tmp[0]:当前网页 tmp[1]:pr tmp[2]:指向网页String url = tmp[0];double cur_rank = Double.parseDouble(tmp[1]);if (tmp.length > 2) {String[] link_list = tmp[2].split(",");for (String linkPage : link_list) {context.write(new Text(linkPage), new Text(String.valueOf(cur_rank / link_list.length)));}}context.write(new Text(url), new Text("|" + tmp[2])); // 做个标记"|"}}public static class PRIterReducer extends Reducer<Text, Text, Text, Text> {@Overrideprotected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {double new_rank = 0;String url_list = "";for (Text value : values) {String tmp = value.toString();if (tmp.startsWith("|")) { // 标志着链出信息url_list = tmp.substring(1);} else {new_rank += Double.parseDouble(tmp);}}new_rank = d * new_rank + (1 - d); // 不是 (1-d)/Ncontext.write(key, new Text(String.valueOf(new_rank)+"\t"+url_list));}}public static void main(String[] args) throws Exception {Configuration conf = new Configuration();Job job = Job.getInstance(conf, "PageRankIter");job.setJarByClass(PageRankIter.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(Text.class);job.setMapperClass(PRIterMapper.class);job.setReducerClass(PRIterReducer.class);FileInputFormat.addInputPath(job, new Path(args[0]));FileOutputFormat.setOutputPath(job, new Path(args[1]));job.waitForCompletion(true);}}// 将PageRank值从大到小输出public static class PageRankViewer {public static class PRViewerMapper extends Mapper<LongWritable, Text, DoubleWritable, Text> {@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {String[] tmp = value.toString().split("\t");context.write(new DoubleWritable(Double.parseDouble(tmp[1])), new Text(tmp[0]));}}public static class DescDoubleComparator extends DoubleWritable.Comparator {public float compare(WritableComparator a, WritableComparable<DoubleWritable> b) {return -super.compare(a, b);}public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) {return -super.compare(b1, s1, l1, b2, s2, l2);}}
// public static class DecDoubleWritable extends DoubleWritable {
//
// @Override
// public int compareTo(DoubleWritable o) {
// return -super.compareTo(o);
// }
// }public static class PRViewerReducer extends Reducer<DoubleWritable, Text, Text, Text> {@Overrideprotected void reduce(DoubleWritable key, Iterable<Text> values, Context context) throws IOException, InterruptedException {for (Text value : values) {context.write(new Text("(" + value + "," + String.format("%.10f", key.get()) + ")"), null);}}}public static void main(String[] args) throws Exception {Configuration conf = new Configuration();Job job = Job.getInstance(conf, "PageRankViewer");job.setJarByClass(PageRankViewer.class);job.setOutputKeyClass(DoubleWritable.class);job.setOutputValueClass(Text.class);job.setMapperClass(PRViewerMapper.class);job.setSortComparatorClass(DescDoubleComparator.class);job.setReducerClass(PRViewerReducer.class);FileInputFormat.addInputPath(job, new Path(args[0]));FileOutputFormat.setOutputPath(job, new Path(args[1]));job.waitForCompletion(true);}}public static class PageRankDriver {private static int times = 10;public static void main(String[] args) throws Exception {String[] forGB = {"", args[1] + "/Data0"}; // GraphBuilderforGB[0] = args[0];GraphBuilder.main(forGB);String[] forItr = {"", ""}; // PageRankIterfor (int i = 0; i < times; i++) {forItr[0] = args[1] + "/Data" + i;forItr[1] = args[1] + "/Data" + (i + 1);PageRankIter.main(forItr);}String[] forRV = {args[1] + "/Data" + times, args[1] + "/FinalRank"}; // PageRankViewerPageRankViewer.main(forRV);}}// 主函数入口public static void main(String[] args) throws Exception {PageRankDriver.main(args);}
}
实验结果

反思总结
其实课上包括PPT已经讲了很多用MapReduce实现PageRank的算法介绍和具体细节,如果对于Java编程和Hadoop的API已经足够了解,那么根据这个思路和伪代码实现应该是不算难的,如果有问题,参考一些其他博客也能实现。
对我而言,更多接触的是C++和Python,Java编程菜鸟,顶多读懂,写这次实验还是需要不停地查一些资料,一些地方的报错不能理解,比如注释掉的DecDoubleWritable类,用它实现的代码不能得到最后的结果(理论上可以,但菜鸟不会调试Java),换成DescDoubleComparator再设置job.setSortComparatorClass(DescDoubleComparator.class)就能跑出结果。
Hadoop编写的代码,PageRank迭代时需要从文件读,再写到文件里,所以map和reduce的输入输出类型需要特别注意,最初写代码时就困惑于此,以为reduce的输出应该就是下一轮的输入了,但其实还要经过文件读写。
另外,Hadoop的API真的是一言难尽,官网上API的介绍也没有那么友好,写代码的时候我就没搞懂job.setOutputKeyClass和job.setOutputValueClass这两个常常用到的函数究竟是指谁的(具体可见这里)。