DeepLab是谷歌为了语义分割又做的一系列工作,在多个开源数据集中都取得了不错的成果,DeepLabv1发表于2014年,后于2016、2017、2018分别提出了V2,V3以及V3+的版本,在mmsegmentation里面主要集成了V3以及V3+的版本,应该也是DeepLab这一家里面效果最好的两个了。
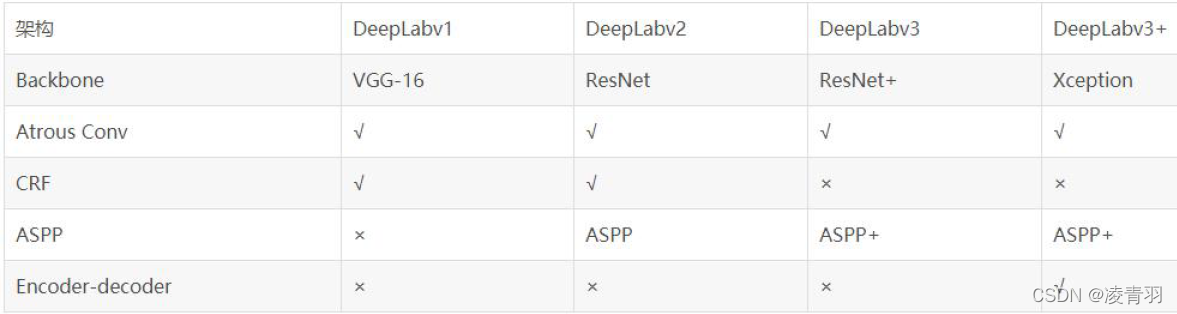
作为当前工业以及学术上都用的比较广泛的模型,DeepLab这一家究竟优势在哪里呢,参考mmLab官方的讲解视频链接【通用视觉框架 OpenMMLab 字幕版】第五讲 语义分割 —刘子纬教授_哔哩哔哩_bilibili,可以发现DeepLab有三宝,分别是:
1、使用空洞卷积解决网络下采样的问题

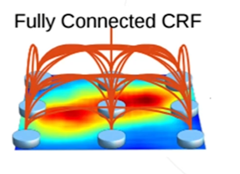
2、使用条件随机场CRF作为后处理手段,精细化分割图
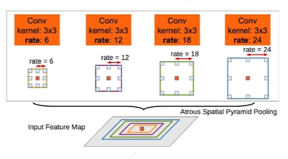
3、使用多尺度的空洞卷积(ASPP模块)捕捉上下文信息
接下来我将对于这三个方面根据视频内容进行个人理解总结,如有错误请批评指正。
首先是空洞卷积,在之前的Resnet等模型中,为了获取更大感受野更多信息特征,往往采用池化下采样的方式,但是这就会导致一个问题,图片尺寸会变小,由于语义分割是对于逐像素进行预测,因此还要再上采样恢复到原图大小,但是在上采样的过程中虽然像FCN以及Unet融合下采样之前的语义信息,但是还是肯定会有精度损失,扩大卷积核同样能够扩大感受野,但是参数就会成倍增加,那么能不能在获取更大感受野的同时尽可能减少精度损失以及控制参数数量呢呢,让图片不要继续变小,这就引入了我们的空洞卷积,如下图所示:

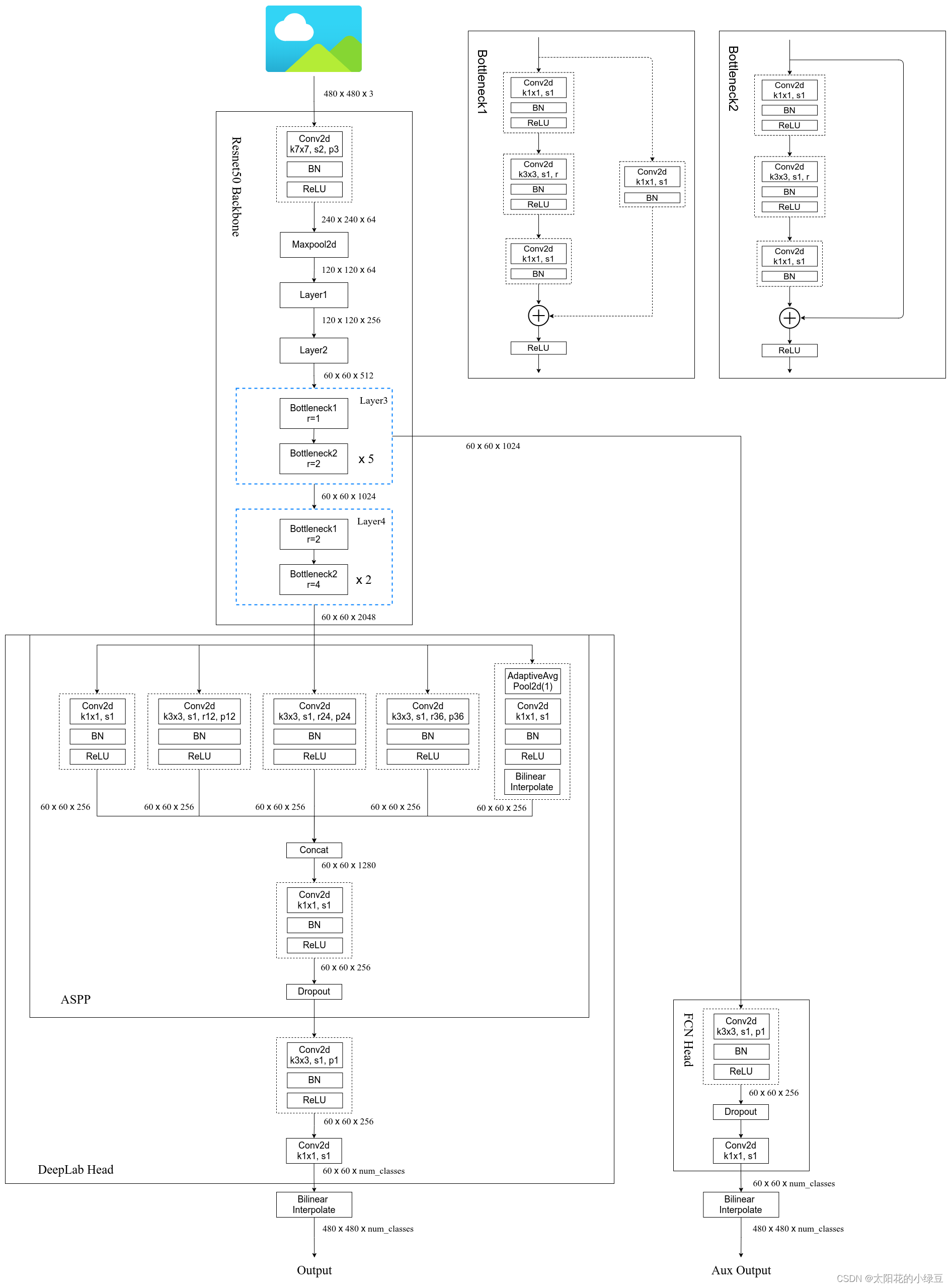
空洞卷积相当于对于卷积核进行了一个膨胀化,在里面填充0,就能在扩大感受野的同时不会产生额外参数,在卷积的过程中也不对导致图片缩小,可以说是一举三得,因此在现在很多模型中空洞卷积都代替了池化层,在mmsegmentation里面如图

我们可以看到他使用了resnet作为主干结构,但是用dilation即卷积核的膨胀率记性空洞卷积,在dilation为2和4的部分,我们看到对应的池化strides变成了1和1,即不进行池化了,也就是本来decode结构里面resnet最后生成的特征图可能是1/32但是变成了1/8,扩大感受野的同时保留了图片的细节信息。同样在下图中我们也能比较清晰了解到空洞卷积相对于下采样的优势。

第二个就是条件随机场(CRF),这个我最开始看的时候非常懵,后面听完讲解就慢慢理解了,
首先我们先介绍一下什么是条件随机场

也就是这个能量应该就是判断结果的优劣性,而如何判断优劣性呢,通过该像素以及结合该像素周围像素的信息进行判断,下面是能量函数的定义:

而通过条件随机场,模型在边界信息分割会更精确

第三部分是空间金字塔池化模块(ASPP)
这里的池化不是真的池化,而是通过不同尺度的空洞卷积的方式代替池化,更大的空洞卷积可以获得更大的感受野,从而获取更多上下文信息,然后在对不同尺度空洞卷积的特征图进行concat获取多尺度信息。

下面是deeplab的整体模型

可以看到在模型Encoder结构中,通过ASPP融合了多个空洞卷积生成的高层次语义信息,同时在decoder机构里面融合了之前低层次的特征信息最后生成分割图。

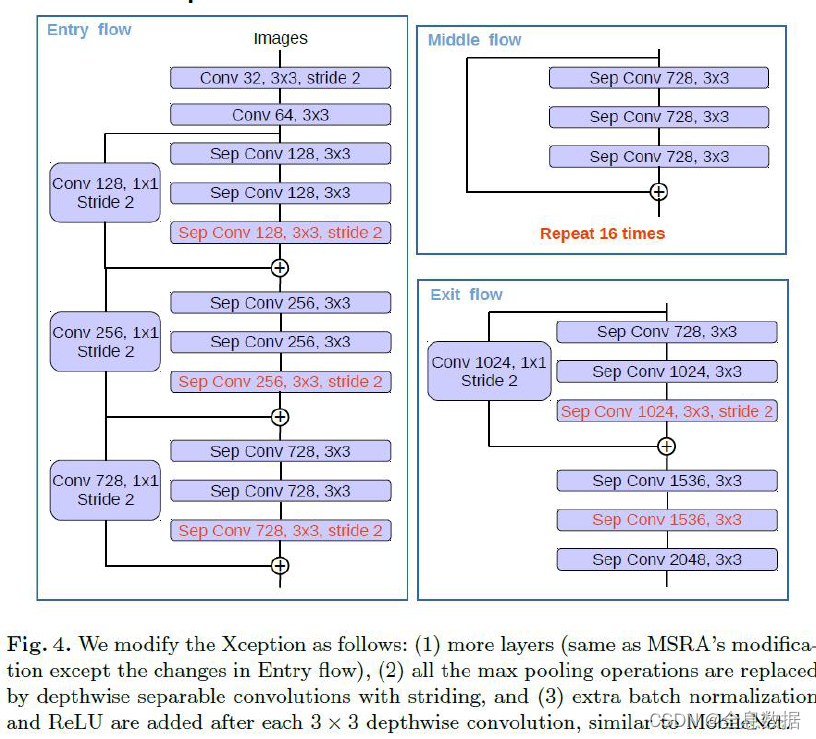
从图中可以明显看出V3+作为最新的DeepLab家族一员,在v2v3的基础上,不仅仅对于空间金字塔生成的特征图进行上采样,而是结合Unet的思想,融合下采样之前的特征信息一步一步进行上采样,但是为什么2倍上采样而是4倍上采样我也不是很懂,可能是因为2倍上采样对于空间金字塔生成的特征图信息丢失太严重。
![深度学习论文精读[13]:Deeplab v3+](https://img-blog.csdnimg.cn/img_convert/4a881284941cdcc5d276731f62152f9c.png)