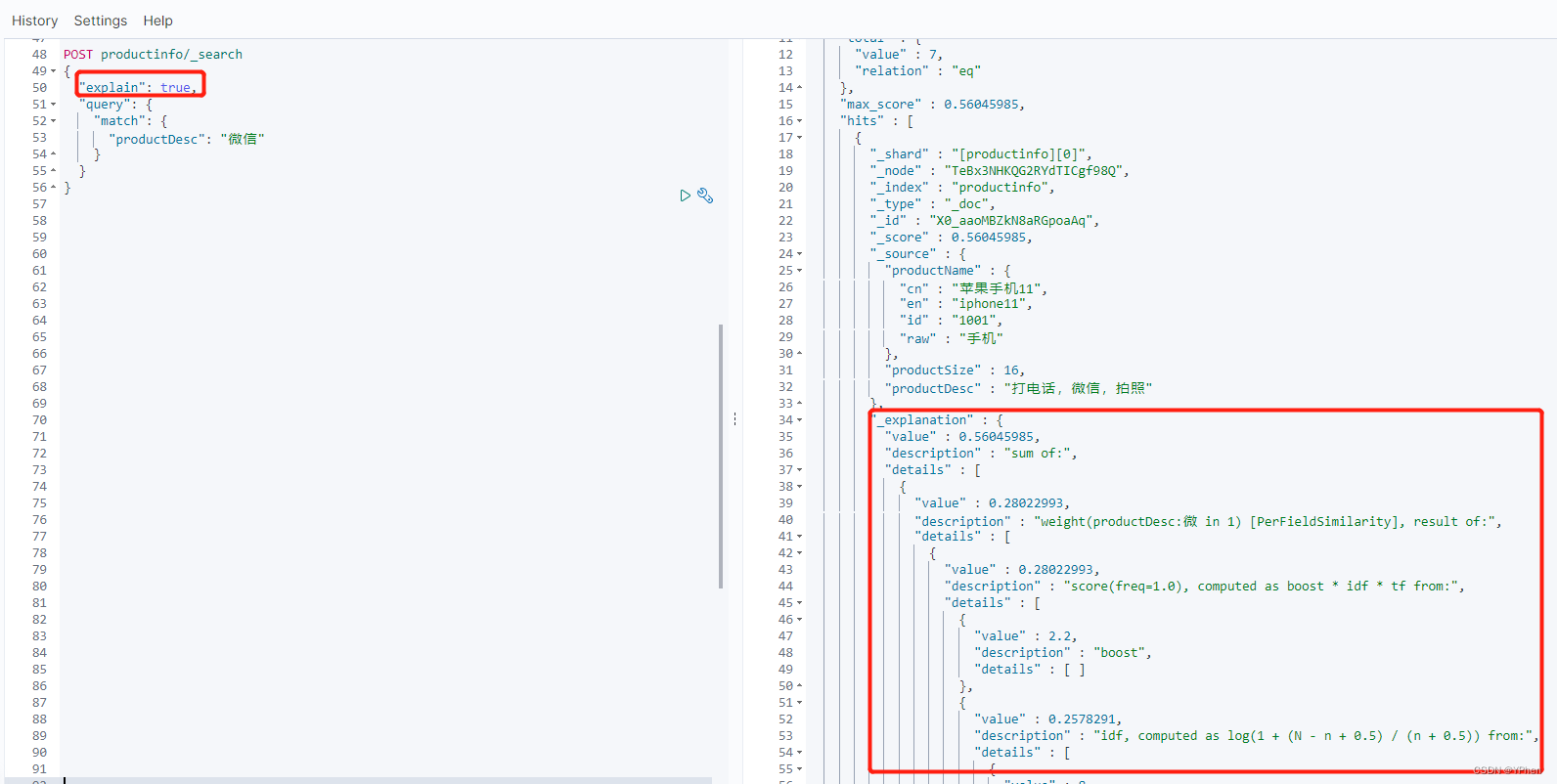
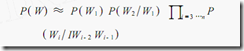概述
N-Gram 算法是一种单词级别的窗口取词算法,N-Gram(有时也称为N元模型)是自然语言处理中一个非常重要的概念,通常在NLP中,人们基于一定的语料库,可以利用N-Gram来预计或者评估一个句子是否合理。另外一方面,N-Gram的另外一个作用是用来评估两个字符串之间的差异程度。这是模糊匹配中常用的一种手段。
N-Gram 算法具体过程:
-
过滤掉文本数据中的标点符号和其他特殊字符;
-
对所有单词执行小写转换,并删除单词之间的空格、换行符等标志位;
-
使用长度为 N 的窗口对文本内容执行字符级滑动取词,将结果存入有序列表。
如下图所示

程序分为两步:文本过滤、滑动取词
文本过滤
def text_filter(text: str) -> str:"""文本过滤器:过滤掉文本数据中的标点符号和其他特殊字符:param text: 待过滤的文本:return: 过滤后的文本"""result = str()for t in text:if t.isalnum():if t.isalpha():t = t.lower()result += str(t)return result
滑动取词
def slide_word(text: str, l: int = 5) -> list:"""滑动取词器Input: text='abcd',l=2Output: ['ab','bc','cd']:param text: 过滤后的文本 (只包含小写数字/字母):param l: 滑动窗口长度,默认为 5:return:"""tf = text_filter(text)result = list()if len(tf) <= l:result.append(tf)return resultfor i in range(len(tf)):word = tf[i:i + l]if len(word) < l:breakresult.append(word)return result
测试
if __name__ == '__main__':banner = 'abcdefghigkLMN*^%$* \r\n)021'print(slide_word(banner))
输出
['abcde', 'bcdef', 'cdefg', 'defgh', 'efghi', 'fghig', 'ghigk', 'higkl', 'igklm', 'gklmn', 'klmn0', 'lmn02', 'mn021']