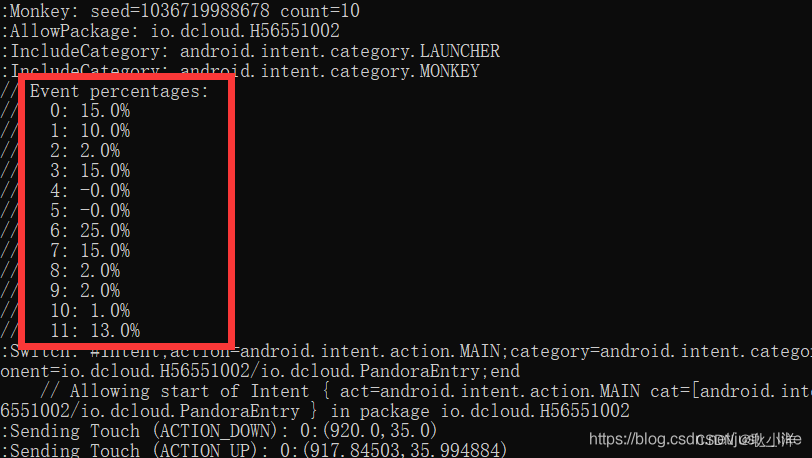
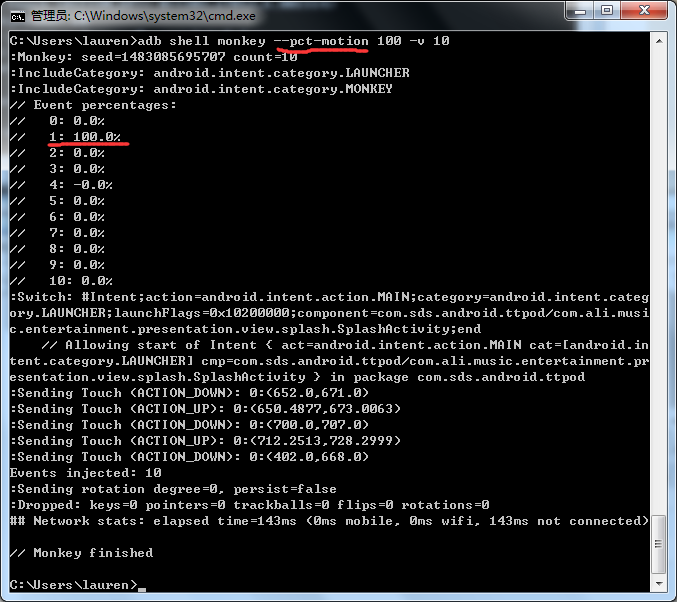
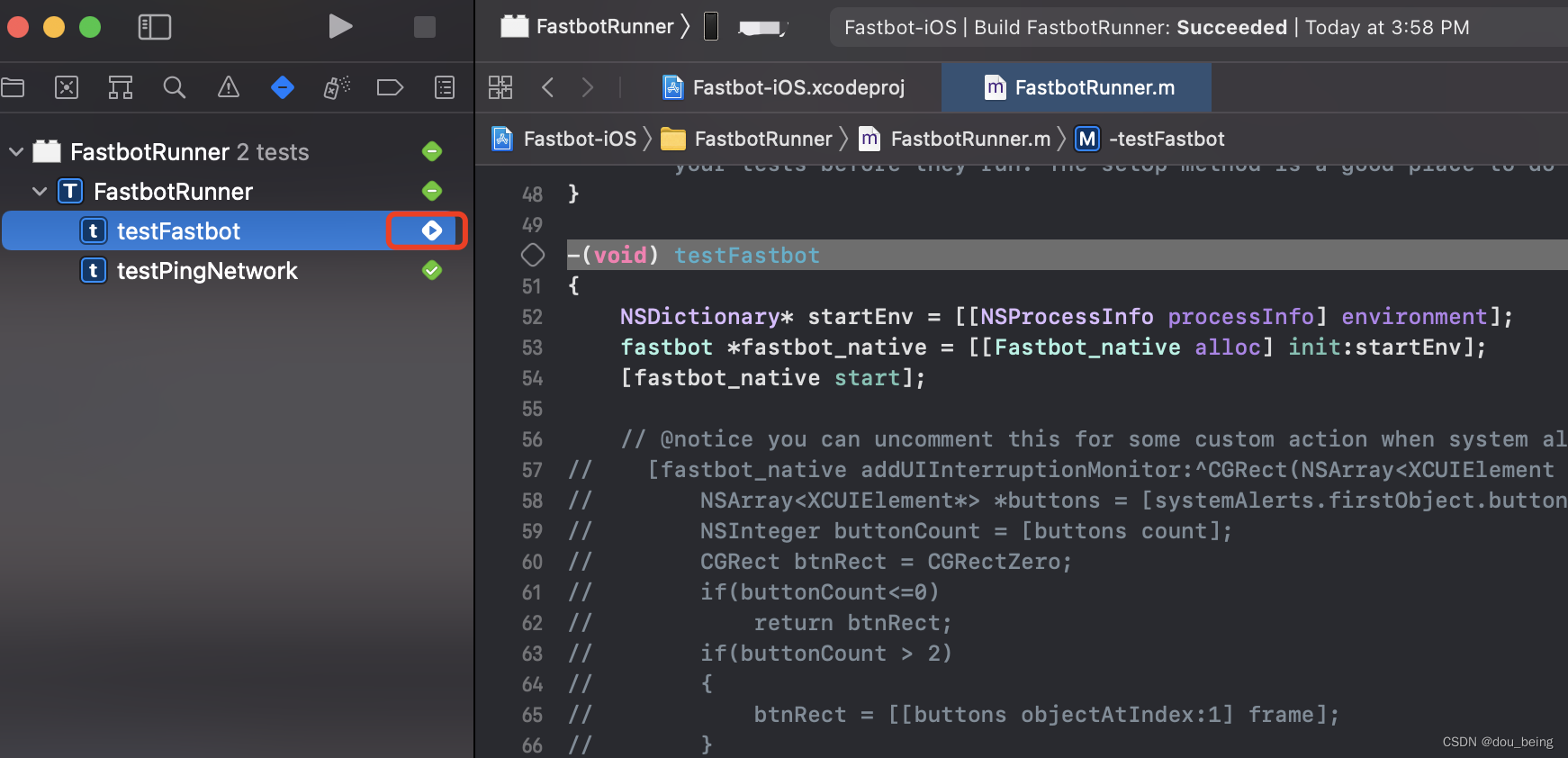
C#分词算法
分词算法的正向和逆向非常简单,设计思路可以参考这里:
中文分词入门之最大匹配法 我爱自然语言处理 http://www.52nlp.cn/maximum-matching-method-of-chinese-word-segmentation
正向最大匹配,简单来说,就是分词的时候,每次读取最大长度,比如7个字。然后去词典看,有没有这个词,没有,就减少一个字,再去词典找有没有这个词。
如此循环,直到找到为止。然后继续从字符串读取7个字,再去词典匹配,如此循环。直到整个字符串处理完毕。
逆向就是反过来,从右往左匹配,思路一样,不过分词之后,要反转排序,才是正常人的阅读顺序。
一般来说,逆向匹配,比正向匹配准确率高不少。
但是,在使用搜狗拼音的17万词库作为词典后,正向匹配的准确率,明显比逆向匹配高。
原因是,搜狗拼音的词库,为了处理生活中非常随意的文字输入,每次输入一个随意的短语或者错别字,就创建了一个新词。因此,这个词库有大量废词和错词。
比如:
<ns1:InputString>yao4 zhuang1</ns1:InputString> <ns1:OutputString>要装</ns1:OutputString> </ns1:DictionaryEntry> <ns1:DictionaryEntry> <ns1:InputString>yao4 zhuang1 qu1 dong4</ns1:InputString> <ns1:OutputString>要装驱动</ns1:OutputString> </ns1:DictionaryEntry> <ns1:DictionaryEntry> <ns1:InputString>yao4 zhuang4 tai4</ns1:InputString> <ns1:OutputString>要状态</ns1:OutputString> </ns1:DictionaryEntry> <ns1:DictionaryEntry> <ns1:InputString>yao4 zhui1 cha2</ns1:InputString> <ns1:OutputString>要追查</ns1:OutputString> </ns1:DictionaryEntry>
逆向分词的时候,无数的废词,会导致分词选择比较乱。但如果是刚装的搜狗拼音输入法,并导出词库,应该就没有这些问题了。
而双向匹配,就是进行正向 + 逆向匹配。
如果 正反向分词结果一样,说明没有歧义,就是分词成功。
如果 正反向结果不一样,说明有歧义,就要处理。
双向匹配,关键就在消除歧义的方法上。
常见的歧义消除方法,比如,从正反向的分词结果中:选择分词数量较少的那个 或者 选择单字较少的那个 或者 选择分词长度方差最小的那个。
还有个据说效果很好的方法是:罚分策略。
简单来说,就是有很多中文字,几乎是永远不会单独出现的,总是作为一个词出现。那么,就单独做个字典,把这些字加进去。
如果分词结果中,包含这样的单字,说明这个分词结果有问题,就要扣分。每出现一个,就扣一分。正反分词结果经过扣分之后,哪个扣分少,哪个就是最优结果。
这个策略听起来很凭感觉,很麻烦。但我发现这个思路可以用于解决一个很头痛的问题:多音字。
多音字,按道理,就不应该单独出现,不然鬼知道它应该读什么。
因此,通过检查分词结果中,是否存在单独的多音字,就知道分词结果是否优秀。
中文的多音字是如此之多,因此这个办法效果应该会相当不错。
而我自己,则小小创新了一下,做了个贪吃蛇法,来消除歧义。
思路是这样的:要进行分词的字符串,就是食物。有2个贪吃蛇,一个从左向右吃;另一个从右向左吃。只要左右分词结果有歧义,2条蛇就咬下一口。贪吃蛇吃下去的字符串,就变成分词。
如果左右分词一直有歧义,两条蛇就一直吃。两条蛇吃到字符串中间交汇时,就肯定不会有歧义了。
这时候,左边贪吃蛇肚子里的分词,中间没有歧义的分词,右边贪吃蛇肚子里的分词,3个一拼,就是最终的分词结果。
程序上,是这样的:
对字符串进行左右(正反)分词,如果有歧义,就截取字符串两头的第一个分词,作为最终分词结果的两头。
两头被各吃一口的字符串,就变短了。这个变短的字符串,重新分词,再次比较左右分词有没有歧义。
如果一直有歧义,就一直循环。直到没有歧义,或者字符串不断被从两头截短,最后什么也不剩下,也就不可能有歧义了。
这个方法,就是把正向分词结果的左边,和反向分词结果的右边,不断的向中间进行拼接,最终得到分词结果。
算法设计原因:
我发现,人在阅读中文的时候,并不完全是从左向右读的。
当一句话有重大歧义,大脑不能立马找到合理解释的时候,会本能的开始尝试从后往前去看这句话,试图找到一个合理的解释。
就像中学生做数学证明题时,正向推导很困难,就会尝试逆向推导。然后发现,正向推导的中间产物 和 逆向推导的中间产物,刚好一致,于是证明题完成。
这个贪吃蛇算法,就是基于这个原因而设计。
不过我暂时没法去验证这个算法是否真的优越。
因为我没有去优化词库。。。现在用的是我从搜狗拼音导出来的原生词库,里面有我多年上网形成的无数错别字词条。。。而且由于我个人的兴趣偏向,我导出的词库,缺少大量常用词。比如“名著”这个词。这辈子没用到过。。。
最后,贴上这个分词算法类的完整代码,直接就能用:
包含了 正反向最大匹配,双向匹配,以及贪吃蛇消除歧义法
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;namespace TextToPinyin.Helper
{/// <summary>/// 分词算法/// </summary>static class Segmentation{/// <summary>/// 用最大匹配算法进行分词,正反向均可。/// 为了节约内存,词典参数是引用传递/// </summary>/// <param name="inputStr">要进行分词的字符串</param>/// <param name="wordList">词典</param>/// <param name="leftToRight">true为从左到右分词,false为从右到左分词</param>/// <param name="maxLength">每个分词的最大长度</param>/// <returns>储存了分词结果的字符串数组</returns>public static List<string> SegMM(string inputStr, ref List<string> wordList, bool leftToRight, int maxLength){//指定词典不能为空if (wordList == null)return null;//指定要分词的字符串也不能为空if (string.IsNullOrEmpty(inputStr))return null;//取词的最大长度,必须大于0if (!(maxLength > 0))return null;//分词的方向,true=从左到右,false=从右到左//用于储存正向分词的字符串数组List<string> segWords = new List<string>();//用于储存逆向分词的字符串数组List<string> segWordsReverse = new List<string>();//用于尝试分词的取词字符串string word = "";//取词的当前长度int wordLength = maxLength;//分词操作中,处于字符串中的当前位置int position = 0;//分词操作中,已经处理的字符串总长度int segLength = 0;//开始分词,循环以下操作,直到全部完成while (segLength < inputStr.Length){//如果还没有进行分词的字符串长度,小于取词的最大长度,则只在字符串长度内处理if ((inputStr.Length - segLength) < maxLength)wordLength = inputStr.Length - segLength;//否则,按最大长度处理elsewordLength = maxLength;//从左到右 和 从右到左截取时,起始位置不同//刚开始,截取位置是字符串两头,随着不断循环分词,截取位置会不断推进if (leftToRight)position = segLength;elseposition = inputStr.Length - segLength - wordLength;//按照指定长度,从字符串截取一个词word = inputStr.Substring(position, wordLength);//在字典中查找,是否存在这样一个词//如果不包含,就减少一个字符,再次在字典中查找//如此循环,直到只剩下一个字为止while (!wordList.Contains(word)){//如果只剩下一个单字,就直接退出循环if (word.Length == 1)break;//把截取的字符串,最边上的一个字去掉//注意,从左到右 和 从右到左时,截掉的字符的位置不同if (leftToRight)word = word.Substring(0, word.Length - 1);elseword = word.Substring(1);}//将分出的词,加入到分词字符串数组中,正向和逆向不同if (leftToRight)segWords.Add(word);elsesegWordsReverse.Add(word);//已经完成分词的字符串长度,要相应增加segLength += word.Length;}//如果是逆向分词,还需要对分词结果反转排序if (!leftToRight){for (int i = 0; i < segWordsReverse.Count; i++){//将反转的结果,保存在正向分词数组中segWords.Add(segWordsReverse[segWordsReverse.Count - 1 - i]);}}//返回储存着正向分词的字符串数组return segWords;}/// <summary>/// 用最大匹配算法进行分词,正反向均可,每个分词最大长度是7。/// 为了节约内存,词典参数是引用传递/// </summary>/// <param name="inputStr">要进行分词的字符串</param>/// <param name="wordList">词典</param>/// <param name="leftToRight">true为从左到右分词,false为从右到左分词</param>/// <returns>储存了分词结果的字符串数组</returns>public static List<string> SegMM(string inputStr, ref List<string> wordList, bool leftToRight){return SegMM(inputStr, ref wordList, leftToRight, 7);}/// <summary>/// 用最大匹配算法进行分词,正向,每个分词最大长度是7。/// 为了节约内存,词典参数是引用传递/// </summary>/// <param name="inputStr">要进行分词的字符串</param>/// <param name="wordList">词典</param>/// <returns>储存了分词结果的字符串数组</returns>public static List<string> SegMMLeftToRight(string inputStr, ref List<string> wordList){return SegMM(inputStr, ref wordList, true, 7);}/// <summary>/// 用最大匹配算法进行分词,反向,每个分词最大长度是7。/// 为了节约内存,词典参数是引用传递/// </summary>/// <param name="inputStr">要进行分词的字符串</param>/// <param name="wordList">词典</param>/// <returns>储存了分词结果的字符串数组</returns>public static List<string> SegMMRightToLeft(string inputStr, ref List<string> wordList){return SegMM(inputStr, ref wordList, false, 7);}/// <summary>/// 比较两个字符串数组,是否所有内容完全相等。/// 为了节约内存,参数是引用传递/// </summary>/// <param name="strList1">待比较字符串数组01</param>/// <param name="strList2">待比较字符串数组02</param>/// <returns>完全相同返回true</returns>private static bool CompStringList(ref List<string> strList1, ref List<string> strList2){//待比较的字符串数组不能为空if (strList1 == null || strList2 == null)return false;//待比较的字符串数组长度不同,就说明不相等if (strList1.Count != strList2.Count)return false;else{//逐个比较数组中,每个字符串是否相同for (int i = 0; i < strList1.Count; i++){//只要有一个不同,就说明字符串不同if (strList1[i] != strList2[i])return false;}}return true;}/// <summary>/// 用最大匹配算法进行分词,双向,每个分词最大长度是7。/// 为了节约内存,字典参数是引用传递/// </summary>/// <param name="inputStr">要进行分词的字符串</param>/// <param name="wordList">词典</param>/// <returns>储存了分词结果的字符串数组</returns>public static List<string> SegMMDouble(string inputStr, ref List<string> wordList){//用于储存分词的字符串数组//正向List<string> segWordsLeftToRight = new List<string>();//逆向List<string> segWordsRightToLeft = new List<string>();//定义拼接后的分词数组List<string> segWordsFinal = new List<string>();//用于保存需要拼接的左、右、中间分词碎块List<string> wordsFromLeft = new List<string>();List<string> wordsFromRight = new List<string>();List<string> wordsAtMiddle = new List<string>();//通过循环,进行正反向分词,如果有歧义,就截短字符串两头,继续分词,直到消除歧义,才结束//整个思路就像贪吃蛇,从两头,一直吃到中间,把一个字符串吃完。////每次循环,得到正反向分词后,进行比较,判断是否有歧义//如果没有歧义,贪吃蛇就不用继续吃了,把分词结果保存,待会用于拼接//如果有歧义,就取正向分词的第一个词,和反向分词的最后一个词,拼接到最终分词结果的头尾//而输入字符串,则相应的揭短掉头尾,得到的子字符串,重新进行正反向分词//如此循环,直到完成整个输入字符串////循环结束之后,就是把上面"贪吃蛇"吃掉的左、右分词结果以及没有歧义的中间分词结果,拼接起来。//进行正反向分词//正向segWordsLeftToRight = SegMMLeftToRight(inputStr, ref wordList);//逆向segWordsRightToLeft = SegMMRightToLeft(inputStr, ref wordList);//判断两头的分词拼接,是否已经在输入字符串的中间交汇,只要没有交汇,就不停循环while ((segWordsLeftToRight[0].Length + segWordsRightToLeft[segWordsRightToLeft.Count-1].Length) < inputStr.Length){//如果正反向的分词结果相同,就说明没有歧义,可以退出循环了//正反向分词中,随便取一个,复制给middle的临时变量即可if (CompStringList(ref segWordsLeftToRight, ref segWordsRightToLeft)){wordsAtMiddle = segWordsLeftToRight.ToList<string>();break;}//如果正反向分词结果不同,则取分词数量较少的那个,不用再循环if (segWordsLeftToRight.Count < segWordsRightToLeft.Count){wordsAtMiddle = segWordsLeftToRight.ToList<string>();break;}else if (segWordsLeftToRight.Count > segWordsRightToLeft.Count){wordsAtMiddle = segWordsRightToLeft.ToList<string>();break;}//如果正反分词数量相同,则返回其中单字较少的那个,也不用再循环{//计算正向分词结果中,单字的个数int singleCharLeftToRight = 0;for (int i = 0; i < segWordsLeftToRight.Count; i++){if (segWordsLeftToRight[i].Length == 1)singleCharLeftToRight++;}//计算反向分词结果中,单字的个数int singleCharRightToLeft = 0;for (int j = 0; j < segWordsRightToLeft.Count; j++){if (segWordsRightToLeft[j].Length == 1)singleCharRightToLeft++;}//比较单字个数多少,返回单字较少的那个if (singleCharLeftToRight < singleCharRightToLeft){wordsAtMiddle = segWordsLeftToRight.ToList<string>();break;}else if (singleCharLeftToRight > singleCharRightToLeft){wordsAtMiddle = segWordsRightToLeft.ToList<string>();break;}}//如果以上措施都不能消除歧义,就需要继续循环//将正向"贪吃蛇"的第一个分词,放入临时变量中,用于结束循环后拼接wordsFromLeft.Add(segWordsLeftToRight[0]);//将逆向"贪吃蛇"的最后一个分词,放入临时变量,用于结束循环后拼接wordsFromRight.Add(segWordsRightToLeft[segWordsRightToLeft.Count-1]);//将要处理的字符串从两头去掉已经分好的词inputStr = inputStr.Substring(segWordsLeftToRight[0].Length);inputStr = inputStr.Substring(0, inputStr.Length - segWordsRightToLeft[segWordsRightToLeft.Count - 1].Length);//继续次循环分词//分词之前,清理保存正反分词的变量,防止出错segWordsLeftToRight.Clear();segWordsRightToLeft.Clear();//进行正反向分词//正向segWordsLeftToRight = SegMMLeftToRight(inputStr, ref wordList);//逆向segWordsRightToLeft = SegMMRightToLeft(inputStr, ref wordList);}//循环结束,说明要么分词没有歧义了,要么"贪吃蛇"从两头吃到中间交汇了//如果是在中间交汇,交汇时的分词结果,还要进行以下判断://如果中间交汇有重叠了:// 正向第一个分词的长度 + 反向最后一个分词的长度 > 输入字符串总长度,就直接取正向的// 因为剩下的字符串太短了,2个分词就超出长度了if ((segWordsLeftToRight[0].Length + segWordsRightToLeft[segWordsRightToLeft.Count-1].Length) > inputStr.Length){wordsAtMiddle = segWordsLeftToRight.ToList<string>();}//如果中间交汇,刚好吃完,没有重叠:// 正向第一个分词 + 反向最后一个分词的长度 = 输入字符串总长度,那么正反向一拼即可else if ((segWordsLeftToRight[0].Length + segWordsRightToLeft[segWordsRightToLeft.Count - 1].Length) == inputStr.Length){wordsAtMiddle.Add(segWordsLeftToRight[0]);wordsAtMiddle.Add(segWordsRightToLeft[segWordsRightToLeft.Count - 1]);}//将之前"贪吃蛇"正反向得到的分词,以及中间没有歧义的分词,进行合并。//将左边的贪吃蛇的分词,添加到最终分词词组foreach (string wordLeft in wordsFromLeft){segWordsFinal.Add(wordLeft);}//将中间没有歧义的分词,添加到最终分词词组foreach (string wordMiddle in wordsAtMiddle){segWordsFinal.Add(wordMiddle);}//将右边的贪吃蛇的分词,添加到最终分词词组,注意,右边的添加是逆向的for (int i = 0; i < wordsFromRight.Count; i++ ){segWordsFinal.Add(wordsFromRight[wordsFromRight.Count-1-i]);}//返回完成的最终分词return segWordsFinal;}}
}
出处:https://my.oschina.net/butaixianran/blog/164042
====================================================
本文用到的库下载:点此下载
词库下载:点此下载
将词库直接放到项目根目录
词库设置如下:
类库说明
词库查看程序:点此下载
可以在上面的程序中添加常用行业词库 还可以通过下面的类在程序中实现
完整的盘古release:点此下载
最新字典文件下载位置 http://pangusegment.codeplex.com/releases/view/47411 默认字典位置为 ..\Dictionaries 你可以通过设置PanGu.xml 文件来修改字典的位置 Demo.exe 分词演示程序 DictManage.exe 字典管理程序 PanGu.xml 分词配置文件 PanGu.HighLight.dll 高亮组件
Lucene.Net
Lucene.net是Lucene的.net移植版本,是一个开源的全文检索引擎开发包,即它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,是一个Library.你也可以把它理解为一个将索引,搜索功能封装的很好的一套简单易用的API(提供了完整的查询引擎和索引引擎)。利用这套API你可以做很多有关搜索的事情,而且很方便.。开发人员可以基于Lucene.net实现全文检索的功能。
注意:Lucene.Net只能对文本信息进行检索。如果不是文本信息,要转换为文本信息,比如要检索Excel文件,就要用NPOI把Excel读取成字符串,然后把字符串扔给Lucene.Net。Lucene.Net会把扔给它的文本切词保存,加快检索速度。
ok,接下来就细细详解下士怎样一步一步实现这个效果的。
Lucene.Net 核心——分词算法(Analyzer)
学习Lucune.Net,分词是核心。当然最理想状态下是能自己扩展分词,但这要很高的算法要求。Lucene.Net中不同的分词算法就是不同的类。所有分词算法类都从Analyzer类继承,不同的分词算法有不同的优缺点。
内置的StandardAnalyzer是将英文按照空格、标点符号等进行分词,将中文按照单个字进行分词,一个汉字算一个词
namespace EazyCMS.Common
{/// <summary>/// 分词类/// </summary>public class Participle{public List<string> list = new List<string>();public void get_participle(){Analyzer analyzer = new StandardAnalyzer(); TokenStream tokenStream = analyzer.TokenStream("",new StringReader("Hello Lucene.Net,我1爱1你China")); Lucene.Net.Analysis.Token token = null; while ((token = tokenStream.Next()) != null) {//Console.WriteLine(token.TermText()); string s = token.TermText();} }}
}
二元分词算法,每两个汉字算一个单词,“我爱你China”会分词为“我爱 爱你 china”,点击查看二元分词算法CJKAnalyzer。
namespace EazyCMS.Common
{/// <summary>/// 分词类/// </summary>public class Participle{public List<string> list = new List<string>();public void get_participle(){//ErAnalyzer analyzer = new CJKAnalyzer();TokenStream tokenStream = analyzer.TokenStream("", new StringReader("我爱你中国China中华人名共和国"));Lucene.Net.Analysis.Token token = null;while ((token = tokenStream.Next()) != null){Response.Write(token.TermText() + "<br/>");}}}
}
这时,你肯定在想,上面没有一个好用的,二元分词算法乱枪打鸟,很想自己扩展Analyzer,但并不是算法上的专业人士。怎么办?
天降圣器,盘古分词,
盘古分词的用法 首先引用以上的盘古dll 文件
将xml文件放在项目的根目录下
<?xml version="1.0" encoding="utf-8"?> <PanGuSettings xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:xsd="http://www.w3.org/2001/XMLSchema" xmlns="http://www.codeplex.com/pangusegment"><DictionaryPath>Dict</DictionaryPath><MatchOptions><ChineseNameIdentify>true</ChineseNameIdentify><FrequencyFirst>false</FrequencyFirst><MultiDimensionality>false</MultiDimensionality><EnglishMultiDimensionality>true</EnglishMultiDimensionality><FilterStopWords>true</FilterStopWords><IgnoreSpace>true</IgnoreSpace><ForceSingleWord>false</ForceSingleWord><TraditionalChineseEnabled>false</TraditionalChineseEnabled><OutputSimplifiedTraditional>false</OutputSimplifiedTraditional><UnknownWordIdentify>true</UnknownWordIdentify><FilterEnglish>false</FilterEnglish><FilterNumeric>false</FilterNumeric><IgnoreCapital>false</IgnoreCapital><EnglishSegment>false</EnglishSegment><SynonymOutput>false</SynonymOutput><WildcardOutput>false</WildcardOutput><WildcardSegment>false</WildcardSegment><CustomRule>false</CustomRule></MatchOptions><Parameters><UnknowRank>1</UnknowRank><BestRank>5</BestRank><SecRank>3</SecRank><ThirdRank>2</ThirdRank><SingleRank>1</SingleRank><NumericRank>1</NumericRank><EnglishRank>5</EnglishRank><EnglishLowerRank>3</EnglishLowerRank><EnglishStemRank>2</EnglishStemRank><SymbolRank>1</SymbolRank><SimplifiedTraditionalRank>1</SimplifiedTraditionalRank><SynonymRank>1</SynonymRank><WildcardRank>1</WildcardRank><FilterEnglishLength>0</FilterEnglishLength><FilterNumericLength>0</FilterNumericLength><CustomRuleAssemblyFileName>CustomRuleExample.dll</CustomRuleAssemblyFileName><CustomRuleFullClassName>CustomRuleExample.PickupVersion</CustomRuleFullClassName><Redundancy>0</Redundancy></Parameters> </PanGuSettings>
在全局文件中填入以下代码
protected void Application_Start(object sender, EventArgs e){//log4net.Config.XmlConfigurator.Configure();//logger.Debug("程序开始");Segment.Init(HttpContext.Current.Server.MapPath("~/PanGu.xml"));}
分词方法
Segment segment = new Segment();var ss = segment.DoSegment("海信的,家就看到");foreach (var s in ss){string sa = s.Word;}
设置过滤词(注意这里的过滤词不要放在第一个上)
出处:https://www.cnblogs.com/yabisi/p/6038299.html
如果,您希望更容易地发现我的新博客,不妨点击一下绿色通道的【关注我】。(●'◡'●)
如果你觉得本篇文章对你有所帮助,请给予我更多的鼓励,求打 付款后有任何问题请给我留言!!!
因为,我的写作热情也离不开您的肯定支持,感谢您的阅读,我是【Jack_孟】!