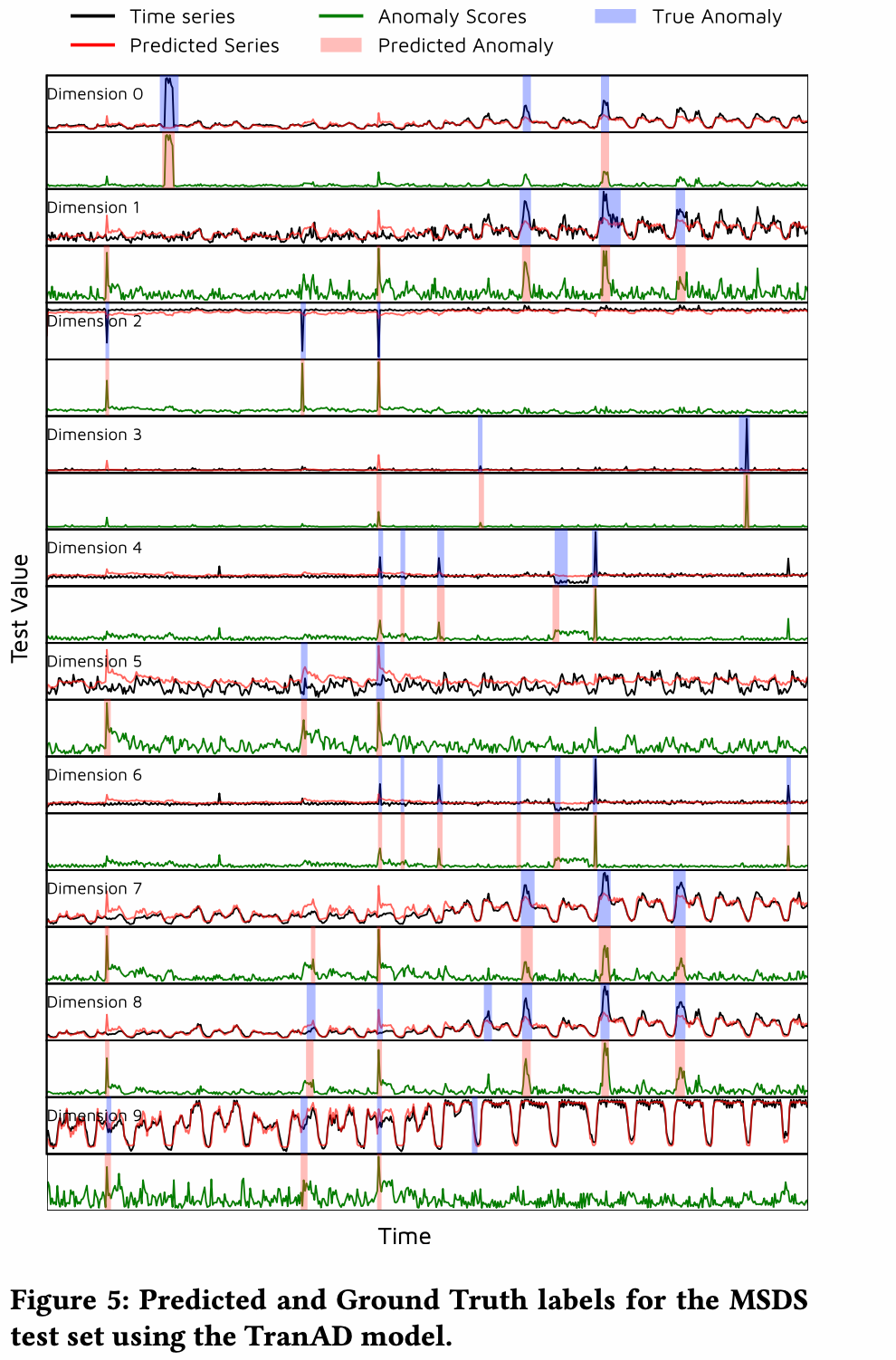
[论文]鲁棒的对抗性强化学习
- 摘要
- 1.简介
- 1.1RARL综述
- 2.背景
- 2.1 MDPs中的标准强化学习
- 2.2 两人零和折扣游戏
- 3.鲁棒的对抗式RL
- 3.1 对抗智能体的鲁棒控制
- 3.2 提出方法:RARL
- 结论
摘要
深度神经网络与快速模拟和改进的计算相结合,导致了最近在强化学习领域的成功。然而,目前大多数基于学习策略的方法不能推广,因为:(1)仿真和现实世界之间的差距太大,策略学习方法不能转移;(b)即使在现实世界中进行政策学习,数据稀缺也会导致从训练到测试场景的泛化失败(例如,由于不同的摩擦或物体质量)。受H∞控制方法的启发,我们注意到建模误差以及训练和测试场景中的差异都可以被视为系统中的额外力/干扰。本文提出了鲁棒对抗强化学习(RARL)的思想,在这种思想中,我们训练一个智能体在一个对系统施加干扰力的不稳定对手存在的情况下运行。联合训练的对手得到了强化——也就是说,它学会了一种最优的不稳定政策。我们将策略学习表述为零和极小极大目标函数。在多种环境下(倒立、半猎豹、游泳、跳跃、步行和蚂蚁)进行的大量实验最终证明,我们的方法(a)提高了训练稳定性;(b)对训练/测试条件的差异具有鲁棒性;和c)即使在没有对手的情况下也优于基线。
1.简介
诸如深度神经网络之类的大容量函数逼近器已经在强化学习领域取得了越来越大的成功。然而,这种策略学习方法的一个主要瓶颈是它们对数据的依赖:训练高容量模型需要大量的训练数据/轨迹。虽然这种训练数据可以很容易地从游戏等任务中获得(例如,末日,蒙特祖玛的复仇)(Mnih等人,2015),但真实世界物理任务的数据收集和策略学习具有重大挑战性。
对于现实世界的物理任务,有两种可能的方法来执行策略学习:
-
现实世界策略学习:第一种方法是在现实世界中学习智能体的策略。然而,现实世界中的培训过于昂贵、危险和耗时,导致数据稀缺。由于数据稀缺,训练往往被限制在有限的一组训练场景中,导致过度拟合。如果测试场景不同(例如,不同的摩擦系数),所学习的策略无法推广。因此,我们需要一种成熟的策略,这种策略能够在一系列场景中很好地推广。
-
在模拟中学习:逃避现实世界中数据稀缺的一种方法是将在模拟器中学习的策略转移到现实世界中。然而,模拟器的环境和物理与现实世界并不完全相同。如果学习的策略对建模错误不稳健,这种现实差距通常会导致不成功的转移(Christiano等人,2016;鲁苏等人,2016年)。
许多策略学习算法本质上是随机的,这一事实进一步加剧了测试泛化和模拟转移问题。对于许多艰苦的体力任务,如Walker2D (Erez等人,2011年),只有一小部分跑步会导致稳定的步行策略。这使得这些方法更加耗费时间和数据。我们需要的是一种方法,这种方法在不同的运行和初始化中学习策略时更加稳定/健壮,同时在培训期间需要更少的数据。
那么,我们如何对不确定性建模,并学习一种对所有不确定性都稳健的政策呢?我们如何模拟模拟和现实世界之间的差距?我们首先认识到,建模误差可以被视为系统中的额外力/干扰。
例如,测试时的高摩擦可能被模拟为接触点处抵抗运动方向的额外力。受这一观察的启发,本文提出了通过对抗代理对系统施加干扰力来建模不确定性的思想。此外,对手得到了强化——也就是说,它学会了一种最优策略来挫败原代理人的目标。我们提出的方法,鲁棒对抗强化学习(RARL),联合训练一对代理,一个主角和一个对手,主角学习完成最初的任务目标,同时对对手产生的干扰保持鲁棒性。
我们进行了广泛的实验来评估在多个开放的gym中的RARL。证明了方法是:(1)对模型初始化是鲁棒的:在给定不同的模型参数初始化和随机种子的情况下,学习的策略表现更好。这通过降低学习的敏感性缓解了数据稀缺问题。对建模误差和不确定性的稳健性:学习到的策略概括了不同的环境设置(例如,具有不同的质量和摩擦值)。
1.1RARL综述
我们的目标是学习一种策略,这种策略对于模拟中的建模错误或者训练和测试场景之间的不匹配是稳健的。例如,我们想学习Walker2D的策略,它不仅适用于carpet(训练场景),还适用于冰上行走(测试场景)。类似地,其他参数如助行器的质量在训练和测试期间可能会有所不同。一种可能性是列出所有这些参数(质量、摩擦力等)。)并学习针对不同可能变化的策略集合(Rajeswaran等人,2016)。但是,明确考虑模拟和真实世界之间的差异或训练/测试之间的参数变化的所有可能参数是不可行的。
我们的核心思想是通过系统中额外的力/干扰来模拟训练和测试场景中的差异。我们的假设是,如果我们能够学习一种对所有干扰都鲁棒的策略,那么这种策略将对训练/测试情况的变化鲁棒;因此可以很好地推广。但是有没有可能在所有可能的扰动下对轨迹进行采样?在不受约束的情况下,可能干扰的空间可能大于可能动作的空间,这使得采样轨迹在联合空间中更加稀疏。
为了解决这个问题,我们主张双管齐下:
-
模拟干扰的敌对智能体:我们不是对所有可能的干扰进行抽样,而是联合训练第二个智能体(称为对手),其目标是通过施加破坏稳定的力量来阻止最初的代理人(称为主角)。对手只因为主角的失败而得到奖励。因此,对手学会了抽样硬例子:干扰,这将使原来的智能体失败;主角学到了一个对对手制造的任何干扰都很稳健的策略。
-
结合领域知识的对手:开发对手的天真方法是简单地给它与主角相同的行动空间——就像驾驶学生和驾驶教练争夺双控汽车的控制权。然而,我们提出的方法要丰富得多,并且不限于对称的动作空间——我们可以利用领域知识来:将对手集中在主角的弱点上;由于对手处于模拟环境中,我们可以赋予对手“超能力”——以主角无法做到的方式影响机器人或环境的能力(例如,突然改变摩擦系数或质量等物理参数)。
2.背景
在深入研究RARL的细节之前,我们首先概述术语、标准强化学习设置和两人零和游戏,我们的论文就是从这些内容中受到启发的。
2.1 MDPs中的标准强化学习
在本文中,我们研究了由元组表示的连续空间MDPs, ( S , A , P , R , γ , s 0 ) (S, A, P, R, γ, s_0) (S,A,P,R,γ,s0),其中 S S S是一组连续状态, S S S是一组连续动作, P : S × A × S → R P : S × A × S → R P:S×A×S→R是转移概率, r : S × A → R r : S × A → R r:S×A→R是奖励函数, γ γ γ是折扣因子, s 0 s_0 s0是初始状态分布。
2.2 两人零和折扣游戏
对抗性设置可以表示为两人γ折扣零和马尔可夫博弈(Littman,1994;Perolat等人,2015年)。这个游戏MDP可以表示为元组: ( S , A 1 , A 2 , P , r , γ , s 0 ) (S,A_1,A_2,P,r,γ,s0) (S,A1,A2,P,r,γ,s0),其中 A 1 A_1 A1和 A 2 A_2 A2是玩家可以采取的连续动作集。 P : S × A 1 × A 2 × S → R P : S ×A_1×A_2×S → R P:S×A1×A2×S→R为跃迁概率密度, r : S × A 1 × A 2 → R r : S ×A_1×A_2→ R r:S×A1×A2→R为双方玩家的奖励。零和两人游戏可以看作是1号玩家最大化γ折扣奖励,而2号玩家最小化。
3.鲁棒的对抗式RL
3.1 对抗智能体的鲁棒控制
我们的目标是学习主角(由 μ \mu μ表示)的策略,使其更好(更高的回报)和健壮(更好地推广到测试设置的变化)。在标准强化学习设置中,对于给定的转移函数 P P P,我们可以学习策略参数 θ μ θ^{\mu} θμ,使得期望回报最大化,其中策略 μ \mu μ的期望回报从 s 0 s_0 s0开始是
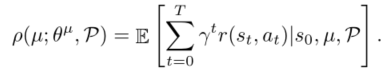
请注意,在这个公式中,预期的回报取决于转换函数,因为转换函数定义了状态的展开。在标准RL设置中,跃迁函数是固定的(因为物理引擎和质量、摩擦等参数是固定的)。然而,在我们的设置中,我们假设转换函数会有建模错误,并且在训练和测试条件之间会有差异。因此,在我们的一般设置中,我们应该估计策略参数θ,以便我们也在不同可能的转移函数上最大化预期回报。因此,
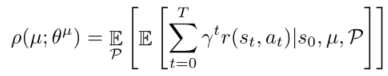
优化预期报酬总转移函数优化平均绩效,这是一个风险中性公式,假设模型参数分布已知。在这种模式下学习到的大部分策略很可能在不同的环境中失败。相反,受到鲁棒控制工作的启发(Tamar等人,2014年;Rajeswaran等人,2016),我们选择优化条件风险值(CV aR):
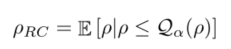
其中, Q α ( ρ ) Q_α(ρ) Qα(ρ)是 ρ ρ ρ值的 α α α分位数。直观地说,在鲁棒控制中,我们希望最差的 ρ ρ ρ值最大化。但是,如何对处于最差 α α α百分位的轨迹进行易处理的采样呢?像EP-Opt (Rajeswaran等人,2016)这样的方法通过改变摩擦、物体质量等参数来采样这些最差的百分位数轨迹。在推广期间。
相反,我们引入了一个敌对的智能体,它在预先定义的位置上施加力,并且这个智能体试图改变轨迹,使得主角的奖励最小化。请注意,由于对手试图最小化主角的奖励,它结束了从最差百分位数的采样轨迹,导致主角的鲁棒控制学习。如果对手保持不变,主角可以学会过度适应它的敌对行动。因此,我们主张使用一种习得的策略来产生对抗行为,而不是使用随机的或固定的对手。我们还想指出我们提出的方法和实例采矿实践之间的联系(宋和波吉欧,1994;Shrivastava等人,2016年)。RARL中的对手学会了为主角学习硬样本(最差轨迹)。最后,RARL不是使用α作为百分比参数,而是根据对手可用的力量大小来参数化。随着对手变得越来越强大,RARL针对较低的百分点进行优化。然而,非常大的力导致非常有偏差的采样,并使学习不稳定。在极端情况下,一个不合理的强大对手总是可以阻止主角完成任务。类似地,传统的RL基线相当于与无能(零力量)的对手一起训练。
3.2 提出方法:RARL
我们的算法(RARL)使用以下交替过程优化两个智能体。在第一阶段,我们学习主角的策略,同时保持对手的策略不变。接下来,主角的策略被保持不变,对手的策略被学习。这个序列重复进行,直到收敛。
算法1详细概述了我们的方法。两个玩家策略的初始参数都是从随机分布中采样的。在每一步操作中,我们执行两步(交替)优化程序。首先,对于N次迭代,对手的参数 θ ν θ_ν θν保持恒定,而主角的参数 θ − μ θ-{\mu} θ−μ被优化以最大化 R 1 R^1 R1。在给定环境定义 ξ \xi ξ和两个玩家的策略的情况下,滚动函数对 N t r a j N_{traj} Ntraj进行采样。请注意, ξ \xi ξ包含转换函数 P P P和奖励函数 R 1 R^1 R1和 R 2 R^2 R2以生成轨迹。它的轨迹的形式是 ( s t i , a t 1 i , a t 2 i , r t 1 i , r t 2 i ) (s^i_t,a^{1i}_ t,a^{2i}_ t,r^{1i}_ t,r^{2i}_ t) (sti,at1i,at2i,rt1i,rt2i)。然后,这些轨迹被分割,使得第 i t h i_{th} ith轨迹的轨迹是这样的形式 ( s t i , a t i = a t 1 i , r t i = r t 1 i ) (s^i_t,a^i_t= a^{1i}_ t,r^i_ t= r^{1i}_ t) (sti,ati=at1i,rti=rt1i)。主角的参数 θ μ θ^{\mu} θμ然后使用策略优化器进行优化。对于第二步,玩家1的参数θ在接下来的 N ν N_ν Nν迭代中保持不变。对 N t r a j N_{traj} Ntraj进行采样并分割成轨迹,使得轨迹的比例为 ( s t i , a t i = a t 2 i , r t i = r t 2 i ) (s^i _t,a^i_t= a^{2i}_ t,r^i_t= r^{2i}_ t) (sti,ati=at2i,rti=rt2i)。然后玩家2的参数 θ ν θ_ν θν被优化。这种交替的过程重复多次。
结论
介绍了一个新的对抗性强化学习框架,即:(1)对训练初始化具有鲁棒性;(b)能更好地概括和适应训练和测试条件之间的环境变化;©对测试环境中的干扰具有鲁棒性,这些干扰在训练期间很难建模。我们的核心思想是,建模误差应被视为系统中的额外力/干扰。受这一观点的启发,我们建议通过对手向系统施加干扰来建模不确定性。对手不是使用固定的策略,而是得到加强,并学习最佳策略,以最佳方式挫败主角。实验表明,对手有效地采样硬例子(回报最差的轨迹),导致更鲁棒的控制策略。