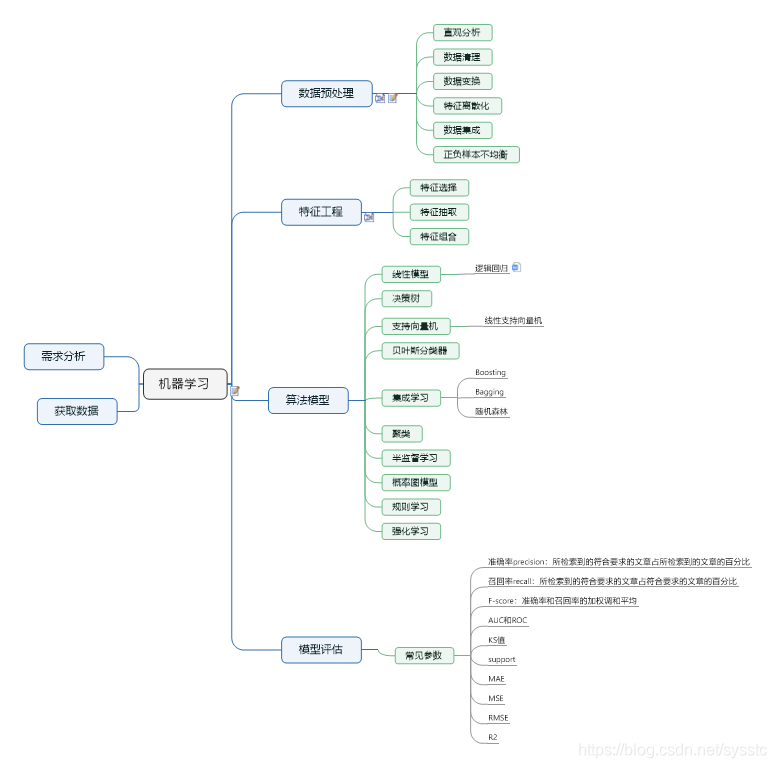
一 定义
机器学习(Machine Learning, ML)是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。
严格的定义:机器学习是一门研究机器获取新知识和新技能,并识别现有知识的学问。这里所说的“机器”,指的就是计算机,电子计算机,中子计算机、光子计算机或神经计算机等等。
二 分类:
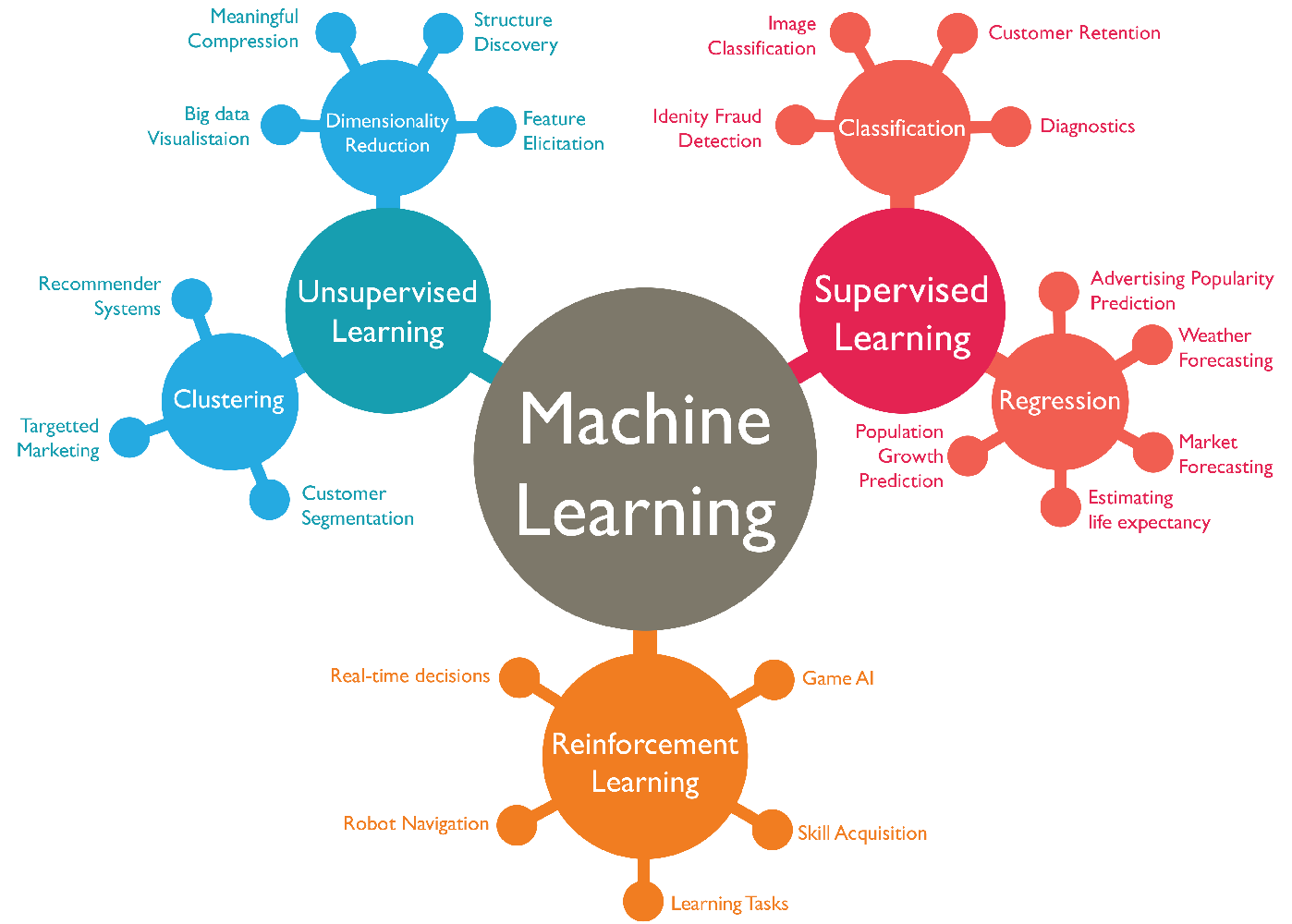
机器学习分为四大块: classification (分类), clustering (聚类), regression (回归), dimensionality reduction (降维)。

1、监督学习
1)监督学习
从给定的训练数据集中学习出一个函数,当新的数据到来时,可以根据这个函数预测结果。监督学习的训练集需要包括输入和输出,也可以说是特征和目标。训练集中的目标是由人标注的。常见的监督式学习算法包括回归分析和统计分类。
监督学习就是训练数据有标签的学习。比如说,我有10万条数据,每个数据有100个特征,还有一个标签。标签的内容取决于学习的问题,如果数据是病人进行癌症诊断做的各项检查的结果,标签就是病人是否得癌症。是为1,不是为0.
监督学习就是要从这10万条数据中学习到根据检查结果诊断病人是否得癌症的知识。由于学习的范围限定在这10万条数据中,也就是说,学习的知识必须是从这10万条数据中提炼出来。形象地理解,就是在这10万条带标签数据的“监督”下进行学习。因此称为监督学习。
2)监督学习的成果
监督学习学习到的知识如何表示,又是如何被我们人类使用呢?简单讲,学习到的知识用一个模型来表示,我们人类就用这个模型来使用学习到的知识。
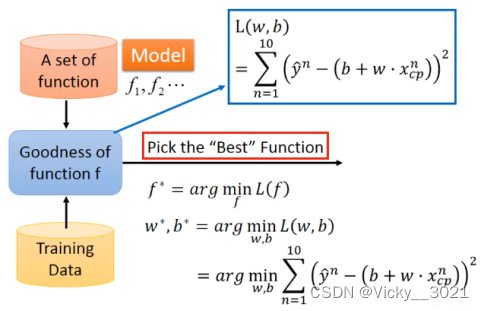
那么,模型是什么东西?
模型就是一个数学表达式。最简单的一个模型就是线性模型,它长这个样子:y^i=∑_j θ_j*x_ij。用我们上面的例子讲,x_i就是我们10万条数据中的第i条,x_ij就是第i条数据中的第j个检查结果。yi就是模型对这条数据的预测结果,这个值越大,表明病人得癌症的概率也大。通常,我们还需将yi处理成0到1的值,以更清晰地表明这是一个概率预测,处理的方法一般是用sigmoid函数,不熟悉的朋友可参考其他资料。θ_j就是第j个检查结果对病人是否得癌症的“贡献度”,它是我们模型的参数,也就是我们从10万条数据中学习到的知识。
可见,所谓监督学习,就是两步,一是定出模型确定参数,二是根据训练数据找出最佳的参数值,所谓最佳,从应用角度看,就是最大程度地吸收了10万条训练数据中的知识,但从我们寻找参数的过程来看,却有另一番解释,下文会详细解释,找到最佳参数后,我们就得出一个参数都是已知的模型,此时,知识就在其中,我们可以自由使用。
3)如何找出最佳参数
以上面的线性模型为例,病人有100个检查结果,那么就有100个参数θ_j(j从1到100)。每个参数可取值都是实数,100个参数的组合显然有无穷多个,我们怎么评判一组参数是不是最佳的呢?
此时,我们需要另外一个函数来帮助我们来确定参数是否是最佳的,这就是目标函数(object function)。
目标函数如何确定呢?用我们上面的例子来讲,我们要判断病人是否得癌症,假设我们对上面的线性模型的值y^i进行了处理,将它规约到了0到1之间。我们的10万条训练数据中,得癌症的病人标签为1,没得的标签为0.那么显然,最佳的参数一定就是能够将得癌症的病人全预测为1,没得癌症的病人全部预测为0的参数。这几乎就是完美的参数!
因此,我们的目标函数可以设为MSE函数:obj = ∑_i (sigmoid(∑_jθ_j*x_ij) - y_i)^2
上面的函数的意思就是对第i条数据,将模型预测的值规约到0到1,然后与该条数据的真是标签值(0和1)做差,再求平方。这个平方值越大,表明预测的越不准,就是模型的预测误差,最后,我们将模型对10万条数据的预测误差求和。就得出了一组具体的参数的预测好坏的度量值。
果真这样就完美了吗?
不是的。上面的目标函数仅仅评测了参数对训练数据来说的好坏,并没有评测我们使用模型做预测时,这组参数表现好坏。也就是说,对训练数据来说是好的参数,未必在预测时就是好的。为什么?
一是10万条数据中有错误存在
二是10万条数据未必涵盖了所有种类的样本,举个极端的例子,假如10万条数据全是60岁以上老人的检查结果,我们用学习到的模型取预测一个10岁的小孩,很可能是不准的。
那么,怎么评测一组参数对预测是好是坏呢?
答案是测了才知道!
这不是废话吗。
事实就是这样。真实的预测是最权威的评判。但我们还是可以有所作为的,那就是正则化。
所谓正则化就是对参数施加一定的控制,防止参数走向极端。以上面的例子来说,假如10万条数据中,得癌症的病人都是60岁以上老人,没得癌症的病人都是30岁以下年轻人,检查结果中有一项是骨质密度,通常,老人骨质密度低,年轻人骨质密度高。那么我们学习到的模型很可能是这样的,对骨质密度这项对应的参数θ_j设的非常大,其他的参数都非常小,简单讲,模型倾向于就用这一项检查结果去判断病人是否得癌症,因为这样会让目标函数最小。
明眼人一看便知,这样的参数做预测肯定是不好的。
正则化可以帮助我们规避这样的问题。
常用的正则化就是L2正则,也就是所有参数的平方和。我们希望这个和尽可能小的同时,模型对训练数据有尽可能好的预测。
最后,我们将L2正则项加到最初的目标函数上,就得出了最终的目标函数:
obj = ∑_i(sigmoid(∑_j θ_j*x_ij) - y_i)^2 + ∑_j(θ_j^2)
能使这个函数值最小的那组参数就是我们要找的最佳参数。这个obj包含的两项分别称为损失函数和正则项。
这里的正则项,本质上是用来控制模型的复杂度。
上面,我们为了尽可能简单地说明问题,有意忽略了一些重要的方面。比如,我们的例子是分类,但使用的损失函数却是MSE,通常是不这样用的。
对于回归问题,我们常用的损失函数是MSE,即:
对于分类问题,我们常用的损失函数是对数损失函数:
乍一看,这个损失函数怪怪的,我们不免要问,为什么这个函数就是能评判一组参数对训练数据的好坏呢?
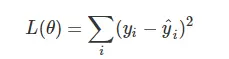
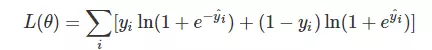
我们用上面的例子来说明,假如有一条样本,它的标签是1,也就是y_i = 1,那么关于这条样本的损失函数中就只剩下了左边那一部分,由于y_i = 1,最终的形式就是这样的:
头上带一个小尖帽的yi就是我们模型的预测值,显然这个值越大,则上面的函数越倾向于0,yi趋向于无穷大时,损失值为0。这符合我们的要求。
同理,对于yi=0的样本也可以做出类似的分析。
至于这个损失函数是怎么推导出来的,有两个办法,一个是用LR,一个是用最大熵。具体的推导过程请参阅其他资料。
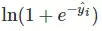
2、无监督学习
与监督学习相比,训练集没有人为标注的结果。常见的非监督式学习算法有聚类。
3、半监督学习
输入数据部分被标识,部分没有被标识,介于监督式学习与非监督式学习之间。常见的半监督式学习算法有支持向量机。
4、强化学习
- 强化学习:在这种学习模式下,输入数据作为对模型的反馈,不像监督模型那样,输入数据仅仅是作为一个检查模型对错的方式,在强化学习下,输入数据直接反馈到模型,模型必须对此立刻作出调整。常见的强化学习算法有时间差学习。