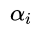前言:
{
之前的神经网络实践还卡在硬件上,不过目前已经打算先使用云设备,下次应该就会继续进行多目标识别的调试。这次就先写一点零散知识。
在专利[1]中我遇到了新的观点——字典学习(Dictionary Learning)。
}
正文:
{
资料[2]让我想起了之前学习的线性代数知识,当时学线性组成和线性相关时我也是想到了人对事物的理解(或者说我对事物的理解):首先通过之前的经验形成一组基,之后通过这组基来线性组成(理解)新旧事物。我认为这和今天说的字典学习很像。
回到正题,设X代表源数据,D代表字典,Z代表稀疏编码矩阵,即得图1。

可以看到,字典就像一个编码解码器一样,Z的数据量比X的小。
字典的学习公式在[1]中如式1。

可见此式即考虑了解码数据与原数据的距离,又考虑了生成的编码的大小。
在[2]中,字典里的原子如图2。

其中每个原子都是训练得到的。值得注意的是,[2]中的原数据被划分成了与字典原子维度一致的pitch(块),也就是说上述X和Z实际上都是小块,并且这些原子都是基于pitch得到的(在资料[3]中原子就是部分pitch,更新也就是使用某个pitch来更换某个原子);相应地,解码输出也是对应的pitch。
图2是一种方法的结果,其中image的左边是原数据,image的右边是解码数据,difference是image与原数据的差别。

可以看到,编码解码后还是会损失部分细节。
}
结语:
{
本来这次想记录对专利[1]的理解,但其中数学公式太多,也需要很多时间。所以这次就先简单记录一下字典学习的概念,现在的时间和精力还不能分配到这上面。
这次就先用点零散知识充数,我也尽量保持3天1更。
参考资料:
{
[1]《基于原子拉普拉斯图正则化的半监督字典学习的样本类别归类方法》(CN 108564107)http://so.lotut.com/patent/search/article.html?patent_id=5bbffae4d827b71f1b11b780
[2]https://www.cnblogs.com/hdu-zsk/p/5954658.html
[3]https://www.jianshu.com/p/f6e5d1cd21b9
}
}