SQL常用语句(基础篇)
-
说明:创建数据库
CREATE DATABASE database-name -
说明:删除数据库
drop database dbname -
说明:备份sql server
—创建备份数据的device
USE master
EXEC sp_addumpdevice ‘disk’,‘testBack’,‘c:\mssql7backup\MyNwind_1.dat’
–开始备份
BACKUP DATABASE pubs TO testBack -
说明:创建新表
create table tabname(col1 type1[not null][primary key],col2 type2 [not null],…)根据已有的表创建新表A:create table tab_new like tab_old(使用旧表创建新表)
B:create table tab_new as select col1,col2…from table_old definition only -
说明:删除新表
drop table tabname -
说明:增加一个列
Alter table tabname add column col type
注: 列增加后将不能删除 -
说明:添加主键
Alter table tabname add primary key(col) -
删除主键
Alter table tabname drop primary key(col) -
说明:创建索引
create [unique] index 索引名称 on tabname(col,col…)索引被创建于已有的表中,他可使对行的地位更加快速有效,可是在表格的一个或者多个列上传建索引,每一个索引都会被起一个名字,用户无法看见索引,他们只能被用来快速查询,but 更新一个包含索引的表需要比更新一个没有索引的表花费更多的时间,这是由于索引本身也需要更新。因此理想的做法是仅仅在常用于搜索的列上面创建索引。
删除索引: drop index 索引名称
注:索引是不可更改的,想要更改必须删除重新建 -
说明:创建视图
create view 视图名称 as select 语句
删除视图: drop view 视图名称通俗的讲:视图就是一条select语句执行后的返回的结果集,它是一张虚拟的表,视图中的数据是依赖于真实表中的数据的。一旦真实表中的数据发生改变,显示在视图中的数据也会发生改变。
-
说明:几个简单的基本的sql语句
选择: select * from table1 where 范围
插入: insert into 表名(field1,field2)values(value1,value2)
删除: delete from table1 where 范围
更新: update table1set field1=value1,field2=value2 where 范围
查找: select * from table where field like ‘%value1%’
排序: select * from table1 order by field1,field2 [DESC/ASC]
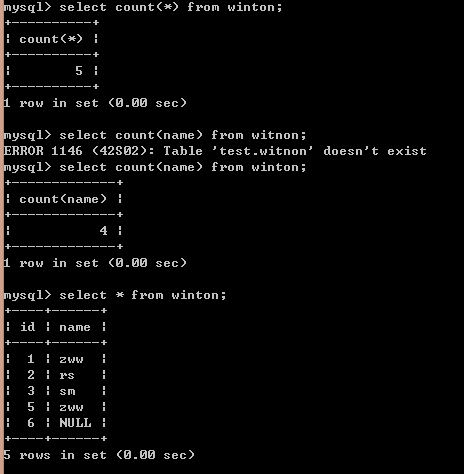
总数: select count as totalcount from table1
平均: select avg(field1) as sumvalue from table1
求和: select sum(field1) as sumvalue from table1
最大: select max(field1) as minvalue from table1
最小: select min(field1) as minvalue from table1 -
说明:几个高级查询运算词
A:UNION运算符
UNION操作符用于合并两个或多个select语句的结果集
union内部的select语句必须拥有相同数量的列,列也必须拥有相似的数据类型,同事,每条select语句中的列的顺序必须相同


union:对两个结果集进行并集操作,不包括重复行,相当于distinct 会对获取的结果进行排序操作。
union all:对两个结果集进行并集操作,包括重复行,不会对获取的结果进行排序操作。
所以在仅仅想要合并查询结果,不会进行去重和排序操作的话,使用union all的执行效率高一些
-
并集 :union: select × from table1 union (all) select × from table2
交集: intersect: select × from table1 intersect select × from table2
差集: minus: select × from table1 minus select × from table2

-
说明:使用外连接
A. left (outer) join on 左(外)连接
语句:select * from a_table a left join b_table b on a.a_id = b.b_id;
左表(a_table)的记录会全部表示出来,而右表(b_table)只会显示符合条件的记录,右表记录不足的地方均为NULL。
B. right (outer) join on 右外连接
语句:select * from a_table a right outer join b_table b on a.a_id = b.b_id;
与左连接相反,右连接,左表只会显示符合条件的记录,而右表记录将会全部表示出来,左表记录不足的地方均为NULL。
C. inner join on 内连接
语句:select * from a_table a inner join b_table b on a.a_id = b.b_id;
组合两个表中的记录,返回关联字段相符的记录,也就是返回两个表的交集部分 -
分组:group by
GROUP BY 语句根据一个或多个列对结果集进行分组。
在分组的列上我们可以使用 COUNT, SUM, AVG,等函数。
语法:
SELECT column_name, function(column_name)
FROM table_name
WHERE column_name operator value
GROUP BY column_name;

配合 WITH ROLLUP使用
WITH ROLLUP 可以实现在分组统计数据基础上再进行相同的统计(SUM,AVG,COUNT…)