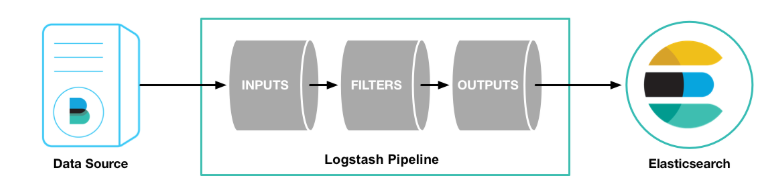
ELK
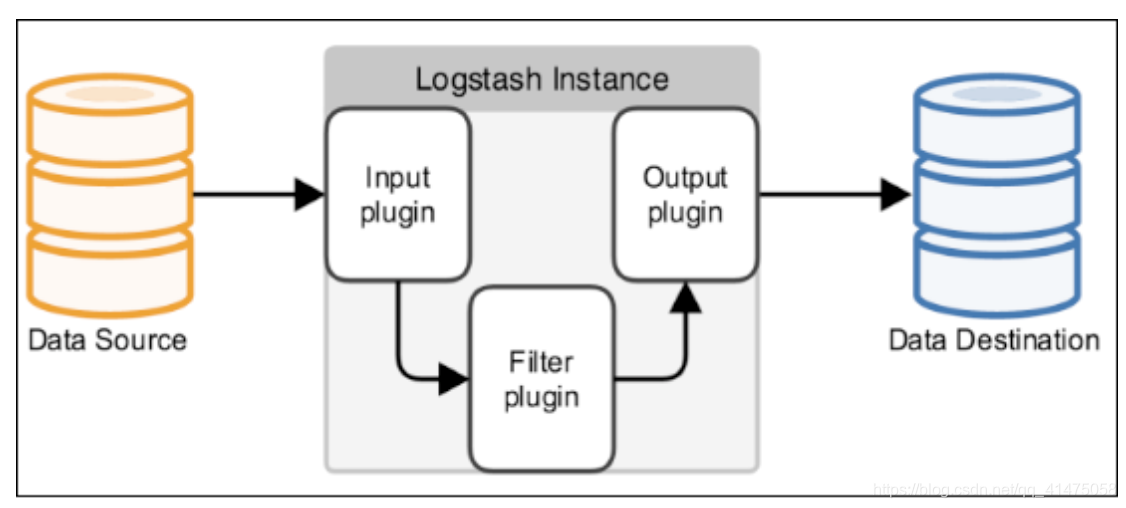
ELK 其实是Elasticsearch、Logstash和Kibana三个产品的首字母缩写,这三款都是开源产品。
- ElasticSearch (简称 ES),是一个实时的分布式搜索和分析引擎,它可以用于全文搜索,结构化搜索以及分析;
- Logstash 是一个数据收集引擎,主要用于进行数据收集、解析,并将数据发送给 ES。支持的数据源包括本地文件、ElasticSearch、MySQL、Kafka 等等;
- Kibana 则是作为
Elasticsearch分析数据的页面展示,可以进行对日志的分析、汇总、监控和搜索日志用。
搭建版本:
- elasticsearch-7.16.2
- kibana-7.16.2
- logstash-7.16.2
准备环境
1.安装 java 环境
# 创建目录
mkdir /usr/local/java/# 解压
tar -zxvf jdk-8u333-linux-x64.tar.gz -C /usr/local/java/# 配置环境变量
vim /etc/profileexport export JAVA_HOME=/usr/local/java/jdk1.8.0_211
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH# 环境变量生效
source /etc/profile# 添加软连接
ln -sf /usr/local/java/jdk1.8.0_211/bin/java /usr/bin/java# 检查java版本
java -version
2.创建用户组及用户
由于 elasticsearch 不允许使用 root 启动,创建以下用户及用户组以备用。
创建用户组名
groupadd elsearch #【添加组】【用户组名】
创建用户
useradd elsearch -g elsearch -p elsearch #【添加用户】【用户名】-g【用户组名】-p【密码值】
安装 Elasticsearch
1.安装
# 下载
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.16.2-linux-x86_64.tar.gz# 解压
tar -zxvf elasticsearch-7.16.2-linux-x86_64.tar.gz# 设置权限到elsearch用户
chown -R elsearch:elsearch /usr/local/elasticsearch-7.16.2
2.修改配置
修改配置文件 elasticsearch.yml
cd /usr/local/elasticsearch-7.16.2/configvim elasticsearch.yml# ========== 修改内容如下 ==================# 集群名称(按实际需要配置名称)
cluster.name: my-elasticsearch
# 节点名称
node.name: node-1
# 数据路径(按实际需要配置日志地址)
path.data: /usr/local/elasticsearch-7.16.2/data
# 日志路径(按实际需要配置日志地址)
path.logs: /usr/local/elasticsearch-7.16.2/logs
# 地址(通常使用内网进行配置)
network.host: 0.0.0.0
# 端口号
http.port: 19200
# 节点地址
discovery.seed_hosts: ["127.0.0.1", "[::1]"]
# 集群master
cluster.initial_master_nodes: ["node-1"]
# 跨域(这两项配置手动添加一下)
http.cors.enabled: true
http.cors.allow-origin: "*"
3.修改 Elasticsearch 启动脚本
7.x 版本以上的 Elasticsearch 需要的 jdk11 及以上,我们的项目大多数都是使用的 jdk8 ,但是 7.x 版本以上的 Elasticsearch 自带了 jdk,此时我们需要把 Elasticsearch 的启动环境 jdk 进行配置。
修改 bin 目录下的elasticsearch文件
vim bin/elasticsearch# ========== 修改内容如下 ==================
# 配置jdk
export JAVA_HOME=JAVA_HOME=/usr/local/java/jdk1.8.0_211/
export PATH=$JAVA_HOME/bin:$PATH# 添加jdk判断
if [ -x "$JAVA_HOME/bin/java" ]; thenJAVA="/usr/local/java/jdk1.8.0_211/bin/java"
elseJAVA=`which java`
fi
4.启动
切换到 elsearch 用户,启动
su elsearch# 后台方式启动
./elasticsearch -d # 查看日志,是否启动成功
cd /usr/local/elasticsearch-7.16.2/logs
tail -fn 100 /usr/local/elasticsearch-7.16.2/logs/my-elasticsearch.log
5.启动报错
ERROR: [1] bootstrap checks failed. You must address the points described in the following [1] lines before starting Elasticsearch.
bootstrap check failure [1] of [1]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
ERROR: Elasticsearch did not exit normally - check the logs at /usr/local/elasticsearch-7.16.2/logs/my-application.log
原因:最大虚拟内存值设置过小,无法支持 ElasticSearch 的运行。
解决方法:将 vm.max_map_count 的值改为 262144,重新启动即可解决问题。
# 查看
cat /proc/sys/vm/max_map_count# 设置
sudo sysctl -w vm.max_map_count=262144
安装 Elasticsearch-head 插件
1.下载
# 下载
wget https://github.com/mobz/elasticsearch-head/archive/master.zip# 解压
unzip master.zip
2.安装 grunt
cd /usr/local/elasticsearch-headnpm install -g grunt-cli
修改所有域名访问,添加 hostname:“*”
# 进入elasticsearch-head目录
cd elasticsearch-head# 修改Gruntfile.js
vim Gruntfile.js# ========== 修改内容如下 ==================
connect: {server: {options: {hostname: '*',port: 9100,base: '.',keepalive: true}}
}
3.启动
# 下载依赖
npm install# 启动
cnpm run start# 后台启动
nohup ./grunt server >/dev/null 2>&1 &
浏览器访问:http://{IP}:9100
安装 Logstash
1.安装
# 下载
wget https://artifacts.elastic.co/downloads/logstash/logstash-7.16.2-linux-x86_64.tar.gz# 解压
tar -zxvf logstash-7.16.2-linux-x86_64.tar.gz
2.修改配置
# 修改配置文件logstash-sample.conf
cd /usr/local/logstash-7.16.2/config# 将logstash-sample.conf文件复制一份,并命名为logstash.conf
cp logstash-sample.conf logstash.conf# 修改配置
vim logstash.conf# ========== 修改内容如下 ==================
input {tcp{mode => "server"host => "0.0.0.0"port => 5701codec => json_lines}
}# 以下配置为创建用户索引及默认索引情况
output {elasticsearch {hosts => ["http://127.0.0.1:19200"]index => "tmk-log-%{+YYYY.MM.dd}"}
}
注意:为了方便解释含义,包含注释
‘#’的行请手动去除。
3.启动
cd /usr/local/logstash-7.16.2/bin# 启动命令
nohup ./logstash -f /usr/local/logstash-7.16.2/config/logstash.conf >../logs/logstash.log &# 使用jps命令查看运行的进程
jps
安装 Kibana
1.安装
# 下载
wget https://artifacts.elastic.co/downloads/kibana/kibana-7.16.2-linux-x86_64.tar.gz# 解压
tar -zxvf kibana-7.16.2-linux-x86_64.tar.gz# 权限
chown -R elsearch:elsearch /usr/local/kibana-7.16.2-linux-x86_64
2.修改配置
修改config目录下的kibana.yml文件
cd /usr/local/kibana-7.16.2-linux-x86_64/config
vim kibana.yml# ========== 修改内容如下 ==================# 服务端口(按实际需求)
server.port: 15601
# 服务主机(这里是服务器内网地址)
server.host: "0.0.0.0"
# 服务名(按实际需求)
server.name: "kibana"
# elasticsearch地址
elasticsearch.hosts: ["http://127.0.0.1:19200"]
# 设置简体中文
i18n.locale: "zh-CN"
3.启动
Kibana 和 Elasticsearch 一样,不能使用 root 用户启动
cd /usr/local/kibana-7.16.2-linux-x86_64/bin# 切换用户
su elsearch#非后台启动,关闭shell窗口即退出
./bin/kibana# 后台启动
nohup ./kibana &# 查看进程
netstat -tunlp | grep 15601
浏览器打开:http://{IP}:15601/app/home
项目测试(Springboot)
1.添加 logstash 依赖
<dependency><groupId>net.logstash.logback</groupId><artifactId>logstash-logback-encoder</artifactId><version>7.0.1</version>
</dependency>
2.添加 logback-spring.xml 配置
配置中destination标签是定义logstash传输日志的ip及端口,有两种方式:
- 直接写在标签里面;
- 从
spring配置中读取,再如下图中通过${**}方式引入。
<?xml version="1.0" encoding="UTF-8"?>
<configuration><include resource="org/springframework/boot/logging/logback/defaults.xml"/><springProperty scope="context" name="springAppName" source="spring.application.name"/><springProperty scope="context" name="logstashUrl" source="logstash.url"/><property name="LOG_FILE" value="/data/logs/${springAppName}/${springAppName}"/><property name="CONSOLE_LOG_PATTERN" value="%clr(%d{yyyy-MM-dd HH:mm:ss.SSS}){faint} %clr(${LOG_LEVEL_PATTERN:-%5p}) %clr([${springAppName:-},%X{X-B3-TraceId:-},%X{X-B3-SpanId:-},%X{X-B3-ParentSpanId:-},%X{X-Span-Export:-}]){yellow} %clr(${PID:- }){magenta} %clr(---){faint} %clr([%15.15t]){faint} %clr(%-40.40logger{39}){cyan} %clr(:){faint} %m%n${LOG_EXCEPTION_CONVERSION_WORD:-%wEx}"/><!-- console --><appender name="console" class="ch.qos.logback.core.ConsoleAppender"><filter class="ch.qos.logback.classic.filter.ThresholdFilter"><!-- Minimum logging level to be presented in the console logs --><level>DEBUG</level></filter><encoder><pattern>${CONSOLE_LOG_PATTERN}</pattern><charset>utf8</charset></encoder></appender><!-- logstash --><appender name="logstash" class="net.logstash.logback.appender.LogstashTcpSocketAppender"><!-- <destination>127.0.0.1:5701</destination> --><destination>${logstashUrl}</destination><!-- 日志输出编码 --><encoder charset="UTF-8" class="net.logstash.logback.encoder.LoggingEventCompositeJsonEncoder"><providers><timestamp><timeZone>UTC</timeZone></timestamp><pattern><pattern>{"logLevel": "%level","serviceName": "${springAppName:-}","pid": "${PID:-}","thread": "%thread","class": "%logger{40}","rest": "%message"}</pattern></pattern></providers></encoder></appender><root level="INFO"><appender-ref ref="console"/><appender-ref ref="logstash"/></root>
</configuration>
改进优化
上面只是用到了核心的三个组件简单搭建的 ELK,实际上是有缺陷的。
如果 Logstash 需要添加插件,那就全部服务器的 Logstash 都要添加插件,扩展性差。所以就有了 FileBeat,占用资源少,只负责采集日志,不做其他的事情,这样就轻量级,把 Logstash 抽出来,做一些滤处理之类的工作。
安装 Filebeat
1.安装
# 下载
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.9.3-linux-x86_64.tar.gz# 解压
tar -zxvf filebeat-7.9.3-linux-x86_64.tar.gz
2.修改配置
# 输入源
filebeat.inputs:
- type: logenabled: truepaths:- /app/demo/*.log # 配置项目日志路径# 输出:Logstash的服务器地址
output.logstash:hosts: ["127.0.0.1:5701"]# 输出:如果直接输出到ElasticSearch
#output.elasticsearch:#hosts: ["127.0.0.1:19200"]#protocol: "https"
3.修改Logstash配置
# 修改配置
vim logstash.conf# ========== 修改内容如下 ==================
input {beats {port => 5701codec => "json"}
}
4.启动
# 后台启动命令
nohup ./filebeat -e -c filebeat.yml >/dev/null 2>&1 &
5.重启Logstash
cd /usr/local/logstash-7.16.2/bin# 启动命令
nohup ./logstash -f /usr/local/logstash-7.16.2/config/logstash.conf >../logs/logstash.log &
6.修改 logback-spring.xml 配置
<?xml version="1.0" encoding="UTF-8"?>
<configuration><include resource="org/springframework/boot/logging/logback/defaults.xml"/><springProperty scope="context" name="springAppName" source="spring.application.name"/><springProperty scope="context" name="logstashUrl" source="logstash.url"/><property name="LOG_FILE" value="/data/logs/${springAppName}/${springAppName}"/><property name="CONSOLE_LOG_PATTERN" value="%clr(%d{yyyy-MM-dd HH:mm:ss.SSS}){faint} %clr(${LOG_LEVEL_PATTERN:-%5p}) %clr([${springAppName:-},%X{X-B3-TraceId:-},%X{X-B3-SpanId:-},%X{X-B3-ParentSpanId:-},%X{X-Span-Export:-}]){yellow} %clr(${PID:- }){magenta} %clr(---){faint} %clr([%15.15t]){faint} %clr(%-40.40logger{39}){cyan} %clr(:){faint} %m%n${LOG_EXCEPTION_CONVERSION_WORD:-%wEx}"/><!-- console --><appender name="console" class="ch.qos.logback.core.ConsoleAppender"><filter class="ch.qos.logback.classic.filter.ThresholdFilter"><!-- Minimum logging level to be presented in the console logs --><level>DEBUG</level></filter><encoder><pattern>${CONSOLE_LOG_PATTERN}</pattern><charset>utf8</charset></encoder></appender><appender name="flatfile" class="ch.qos.logback.core.rolling.RollingFileAppender"><file>${LOG_FILE}</file><rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"><fileNamePattern>${LOG_FILE}.%d{yyyy-MM-dd}.gz</fileNamePattern><maxHistory>7</maxHistory></rollingPolicy><encoder><pattern>${CONSOLE_LOG_PATTERN}</pattern><charset>utf8</charset></encoder></appender><!-- <appender name="logstash" class="net.logstash.logback.appender.LogstashTcpSocketAppender"><destination>${logstashUrl}</destination><encoder charset="UTF-8" class="net.logstash.logback.encoder.LoggingEventCompositeJsonEncoder"><providers><timestamp><timeZone>UTC</timeZone></timestamp><pattern><pattern>{"logLevel": "%level","serviceName": "${springAppName:-}","pid": "${PID:-}","thread": "%thread","class": "%logger{40}","rest": "%message"}</pattern></pattern></providers></encoder></appender> --><root level="INFO"><appender-ref ref="console"/><!-- <appender-ref ref="logstash"/> --><appender-ref ref="flatfile"/></root>
</configuration>ELK 基本搭建完成,能够满足正常的使用。因安全性 Elasticsearch 与 Kibana 默认是没有密码的。
Elasticsearch、Kibana、Logstash 配置密码
Elasticsearch 设置密码
1.x-pack插件
x-pack 是 Elasticsearch 的一个扩展包,将安全,警告,监视,图形和报告功能捆绑在一个易于安装的软件包中,可以轻松的启用或者关闭一些功能。
默认我们的 ELK 部署后,可以直接就进入 web 管理界面,这样会带来极大的安全隐患。
Elasticsearch 是借助 x-pack 插件的密码配置,6.3.0 之前的版本需要下载插件,6.3.0 以后都不需要下载。
6.3.0 版本需要下载:
# 在es的目录下进行下载
./elasticsearch-plugin install x-pack
2.修改配置
cd /usr/local/elasticsearch-7.16.2/configvim elasticsearch.yml# ========== 修改内容如下 ==================xpack.security.enabled: true
xpack.license.self_generated.type: basic
xpack.security.transport.ssl.enabled: true
3.重启
# 切换到 elsearch 用户
su elsearch# 后台方式启动
./elasticsearch -d
4.设置密码
设置六个账号的密码:elastic、apm_system、kibana、logstash_system、beats_system、remote_monitoring_user。
这里设置的密码为:123456,默认账号为:elastic
# 在bin目录下以交互的方式设置密码
./bin/elasticsearch-setup-passwords interactive# 以下步骤配置密码elasticsearch、kibana、logstash密码
warning: usage of JAVA_HOME is deprecated, use ES_JAVA_HOME
Future versions of Elasticsearch will require Java 11; your Java version from [/usr/local/java/jdk1.8.0_211/jre] does not meet this requirement. Consider switching to a distribution of Elasticsearch with a bundled JDK. If you are already using a distribution with a bundled JDK, ensure the JAVA_HOME environment variable is not set.
Initiating the setup of passwords for reserved users elastic,apm_system,kibana,kibana_system,logstash_system,beats_system,remote_monitoring_user.
You will be prompted to enter passwords as the process progresses.
Please confirm that you would like to continue [y/N]yEnter password for [elastic]:
Reenter password for [elastic]:
Enter password for [apm_system]:
Reenter password for [apm_system]:
Enter password for [kibana_system]:
Reenter password for [kibana_system]:
Enter password for [logstash_system]:
Reenter password for [logstash_system]:
Enter password for [beats_system]:
Reenter password for [beats_system]:
Enter password for [remote_monitoring_user]:
Reenter password for [remote_monitoring_user]:
Changed password for user [apm_system]
Changed password for user [kibana_system]
Changed password for user [kibana]
Changed password for user [logstash_system]
Changed password for user [beats_system]
Changed password for user [remote_monitoring_user]
Changed password for user [elastic]
5.修改Logstash配置
output {elasticsearch {hosts => ["http://127.0.0.1:19200"]index => "tmk-log-%{+YYYY.MM.dd}"user => elasticpassword => 123456}
}
Kibana 设置密码
由于 Elasticsearch 已经设置好了密码,此时如果 Kibana 想要从 Elasticsearch 中获取数据就必须进行账号密码配置,在 Kibana 配置账号密码即可。
cd /usr/local/kibana-7.16.2-linux-x86_64/config
vim kibana.yml# 默认用户为elastic
elasticsearch.username: "elastic"
elasticsearch.password: "123456"
Elasticsearch修改密码的命令
# 修改es密码
curl -H "Content-Type:application/json" -XPOST -u elastic 'http://127.0.0.1:19200/_xpack/security/user/elastic/_password' -d '{ "password" : "123456" }'
修改成功后需重启 Elasticsearch、Kibana、Logstash。