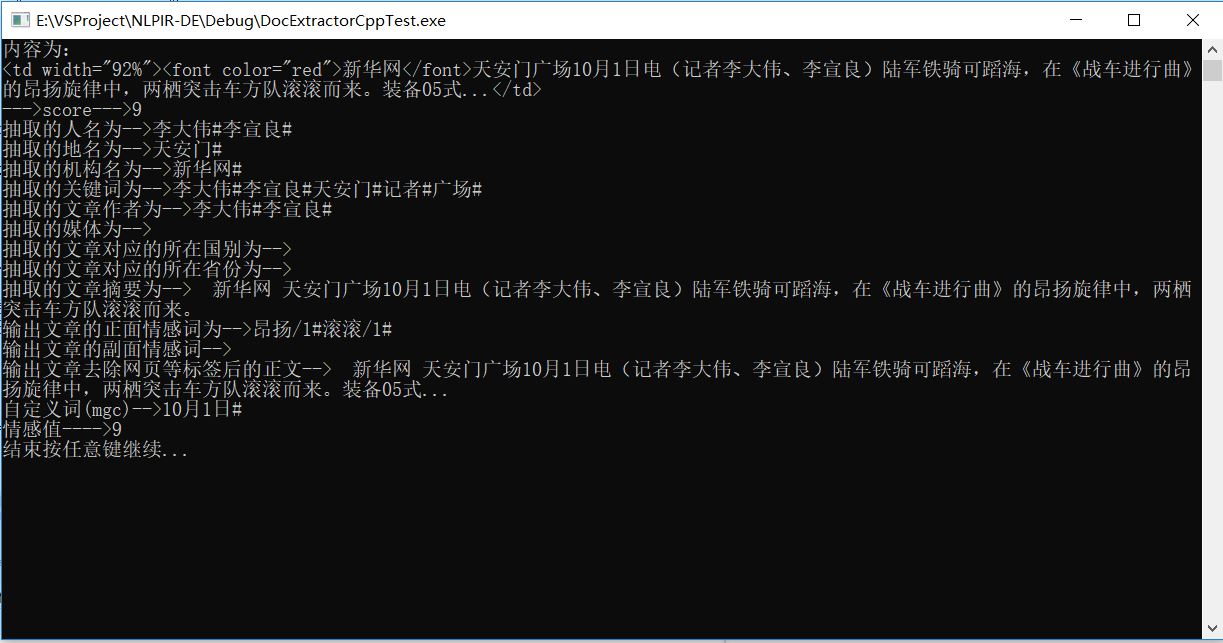
beta分布
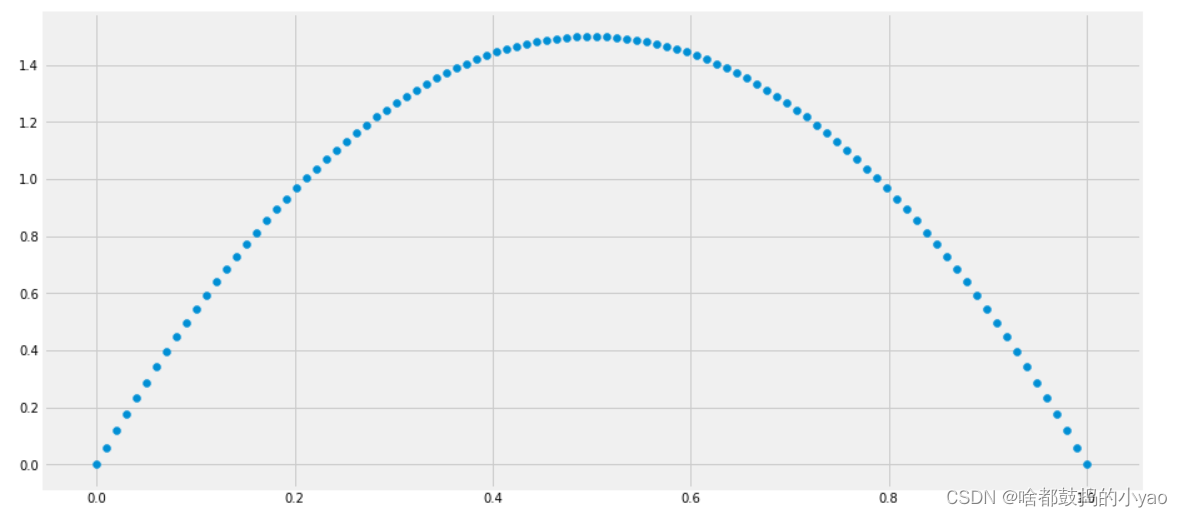
贝塔分布( Beta Distribution ) 是一个作为伯努利分布和二项式分布的共轭先验分布的密度函数,在机器学习和数理统计学中有重要应用。在概率论中,贝塔分布,是指一组定义在(0,1)区间的连续概率分布。其概率密度函数为:
beta 分布的期望为:
下面我们通过一个问题来具体的分析 beta 分布的使用。假设一个概率实验只有两种结果,一个是成功,概率是X;另一个是失败,概率为(1−X)。其中,X的值我们是不知道的,但是它所有可能的情况也是等概率的。如果我们对X的不确定性用一种方式描述,那么,可以认为X是个来自于[0,1]区间的均匀分布的样本。
这是很合理的,因为X只可能是[0,1]之间的某个值。同时,我们对X也一无所知,认为它是[0,1]之间任何一个可能的值。这些都与[0,1]均匀分布的性质契合。
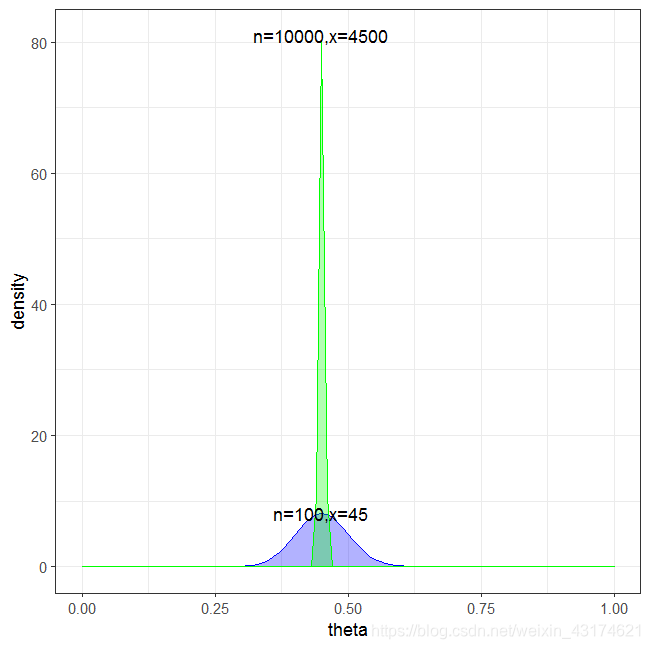
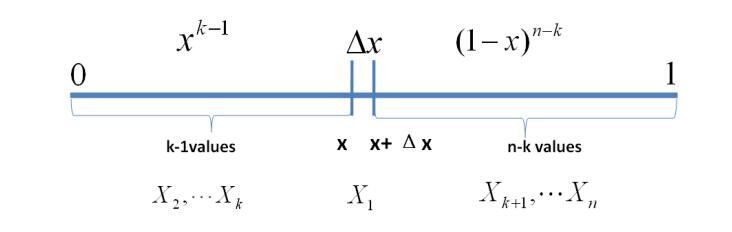
现在,假设我们做了n次独立重复的实验,我们观察到k次成功,n−k次失败。这时候我们就可以使用这些实验结果来修订之前的假设了。换句话说,我们就要计算X的条件概率,其条件是我们观察到的成功次数和失败次数。这里计算的结果就是 beta 分布了。
在这里,在总共n次实验,k次成功的条件下,X的条件概率是一个 beta 分布,其参数是k+1和n−k+1。
示例:beta分布用于评价旧货商服务质量
假设亚马逊上有三家旧货商,其评价结果分别如下:
商家一:85193个评论,94%的正向
商家二:20785个评论,98%的正向
商家三:840个评论,99%的正向
那么这三个商家中,哪一家的服务质量最好呢?假设我们对三家旧货商的信息一无所知,那么这些参数的先验可以认为是一个均匀分布,也可以等同于 beta(1,1) 。根据之前的知识,我们知道,最终这三家旧货商的服务质量应当服从三个不同参数的 beta 分布,即 beta(80082,5113)、beta(20370,417)和beta(833,9)。
注意,当 beta 分布的参数很大的时候,我们可以使用相同均值和方差的正态分布代替这个 beta 分布。
因此,最终这三家供货商,商家3的服务质量的标准差是0.003,是最大的。其他两家的标准差比这个还小。因此,我们可以认为这三家供货商的服务质量都高度聚焦于他们的均值。因此,从第一个或第二个分布中抽取的样本不太可能比第三个样本的值高。也就是说前两个服务商不太可能质量比第三个高。
scipy 的 beta 分布计算
Python 的scipy中含有 beta 分布函数。下面给出该函数的用法: beta.pdf(x,a,b) 其中x是给定的取值范围,a为α值,b为β值。它的返回值就是指定输入的概率值。
例如,在旧货商的正向评论率问题中,我们使用 scipy 的 beta 函数就可以得到三家供货商的服务质量函数。在本问题中,x∈[0,1]表示正向评论率,三个旧货商的 beta 函数为beta.pdf(x,80082,5113),beta.pdf(x,20370,417),beta.pdf(x,833,9)。 使用 beta 函数后得到的值就是正向评论率的概率。
编程示例
我们现在考虑这么个问题:
问题1. 在一个收费站,收费站一段时间(比如每隔1小时)会经过一些车(n辆)。假设经过的车只分两种,大车和小车。我们希望通过观察收费站一长段时间的车辆经过情况,估计小车占所有车的比例 p 。
首先我们使用这样的策略:每隔一个小时统计一次,那么在每个小时内,小车的数量应该服从(n,p)二项分布。但是有个问题,就是每个小时的 n (车辆总数)是不同的, p 也不同,那么十个小时的观测到的小车数目,就是十个不同的二项分布的期望,所以不好假设是二项分布了。
估计小车的比例 p 显然仅能出现于0到1之间。任何时刻的小车的比例具有随机性,这些提示我们一段时间的小车比例的分布可能符合贝塔分布。
记每小时的小车数为α ,大车数β,则小车的比例为。而这个比例就服从B(α,β)。也就是说,计算每小时观测到的小车比例,可以认为小车车流量服从 beta 分布,并进行求解。因此,小车的占比p的可能性为
0 ~ 1,作为beta分布的输入x,α 和β为函数的参数。
from scipy.stats import beta
import numpy as npa = input() #贝塔分布的alpha值
b = input() #贝塔分布的beta值
a = float(a)
b = float(b)
x=np.arange(0.1,1,0.1) #给定的输入数据
print(beta.pdf(x,a,b))测试输入:
0.50.5
预期输出:
[1.06103295 0.79577472 0.69460912 0.64974733 0.63661977 0.649747330.69460912 0.79577472 1.06103295]