一、本文内容简介
- 关于中文分词的基本概念
- 关于NLPIR(北理工张华平版中文分词系统)的基本情况
- 具体SDK模块(C++版)的组装方法
二、具体内容
1. 中文分词的基本概念
中文分词是自然语言处理的一个分支,自然语言即人们在日常生活中使用的语言,包含书面语,口语,例如报纸上的一篇通讯,博客里面的一篇文章。之所以称其为自然语言,是因为它区别于计算机语言,计算机语言的文法与组织方式较为规范,自然语言则贴近人们生活。自然语言处理作为一项技术,在搜索引擎,机器语义理解和对话系统中有着基础和决定性的作用和价值,这方面比较知名的例如微软的cortana(微软小娜),以及国内各个互联网公司发布的智能音箱等。
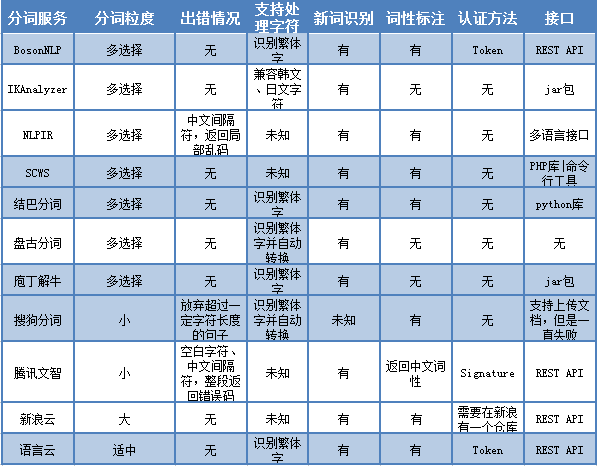
2.关于NLPIR(北理工张华平版中文分词系统)的基本情况
北理工张华平版中文分词系统(NLPIR),又名中科院分词系统,是国内高校院所中开源力度相当大的一家(下文将简称北理工分词系统),另一家是哈工大中文分词系统(LTP)。北理工分词系统功能丰富,目前已经包含了以下功能:
- 全文检索
- 新词发现
- 分词标注
- 统计分析与术语翻译大数据聚类与热点分析
- 大数据文本过滤
- 自动摘要
- 关键词提取
- 文档去重
- HTML正文提取
- 编码自动识别与转换
-
NLPIR提供的组件包中含有13种SDK组件包:
- Classify规则组件
- Cluster聚类组件
- DeepClassifier训练分类组件
- DocExtractor实体抽取组件
- HTMLPaser网站正文提取组件
- NLPIR-ICTCLAS分词组件
- JZsearch精准搜索组件
- JZSearch精准搜索客户端组件
- KeyExtract关键词提取组件
- RedupRemover文档去重组件
- Sentiment情感组件
- SentimentAnalysis情感分析组件
- Summary摘要组件
每个组件包内容介绍
- doc:使用说明文档和API文档
- include:头文件
- lib:linux32,linux64,win32,win64等不同版本的库
- projects:开发工程包
- sample:C#,C++,java等不同语言的案例
- Data:数据库
3.具体SDK模块(C++)的组装方式
注:以下组装方式以实体抽取模块(DocExtractor)为例,平台为VS2012
①准备内容:
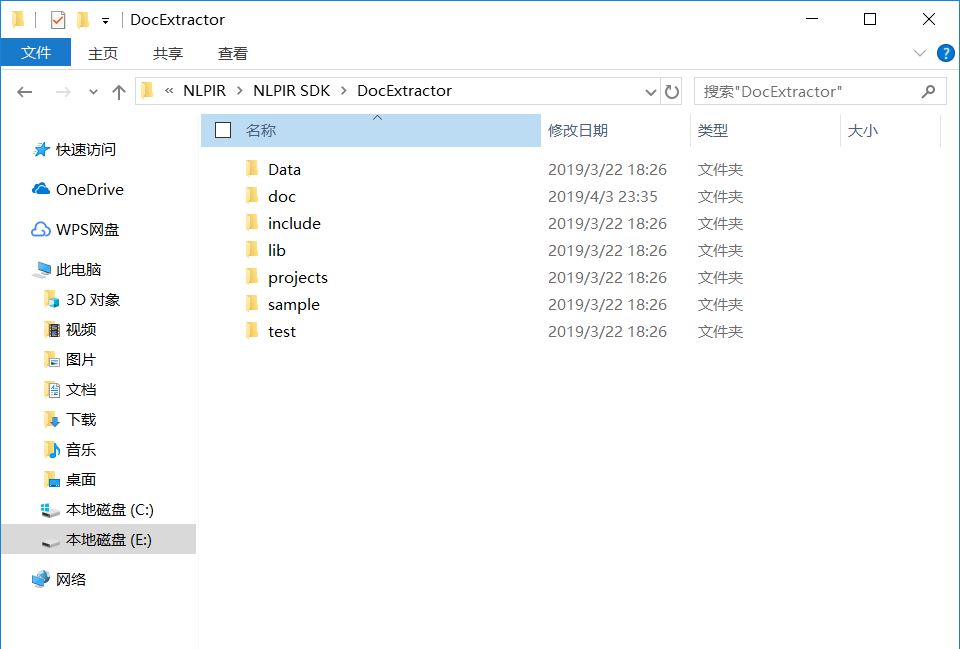
前往Github下载源码,源码的数据量在740MB左右,因为DNS被禁的原因,一般网络的下载速度比较慢,几十kb的样子。博主的解决方法是使用国内的代码托管平台,例如本人使用的是码云( https://gitee.com),可以与Github关联同一个账户,将Github中的项目fork到码云中再进行下载,速度可以上每秒0.5MB。解压之后,如下图所示
> 实体抽取组件的路径为:NLPIR\NLPIR SDK\DocExtractor,其中包含的文件如下图
②开始组装
emsp;1.点击新建—>项目—>其他语言—>Visual C++ —>空项目,名称为:DocExtractorCppTest,解决方案名称为:NLPIR-DE;如下图所示
2.将路径(NLPIR\NLPIR SDK\DocExtractor\projects\DocExtractor_c++)中的main.cpp文件拷贝到项目目录下(我的路径为NLPIR-DE\DocExtractorCppTest\)。
3.把路径(NLPIR\NLPIR SDK\DocExtractor\lib\win32)下的DocExtractor.dll以及DocExtractor.lib两个文件拷贝到项目目录下(我的路径为NLPIR-DE\DocExtractorCppTest\)。
4.将(NLPIR\License\license for a month\DocExtractor文档提取授权)下面的DocExtractor.user拷贝到路径NLPIR\NLPIR SDK\DocExtractor\Data下
5.将DATA文件夹拷贝到新建的解决方案目录下
6.将路径NLPIR\NLPIR SDK\DocExtractor\include下的文件DocExtractor.h拷贝到项目目录下,我的路径为NLPIR-DE\DocExtractorCppTest
7.经过以上操作,新建项目文件如下图
9.在VS中右键单击项目—>添加—>现有项,把项目目录下的四个文件 DocExtractor.dll,DocExtractor.h,DocExtractor.lib,main.cpp添加进去,点击运行,而后报错,如下图所示,正常现象,这是因为部分代码没有修改的缘故。
10.将如图所示的红色框中的代码去掉就可以,使dll文件及lib文件正确读取。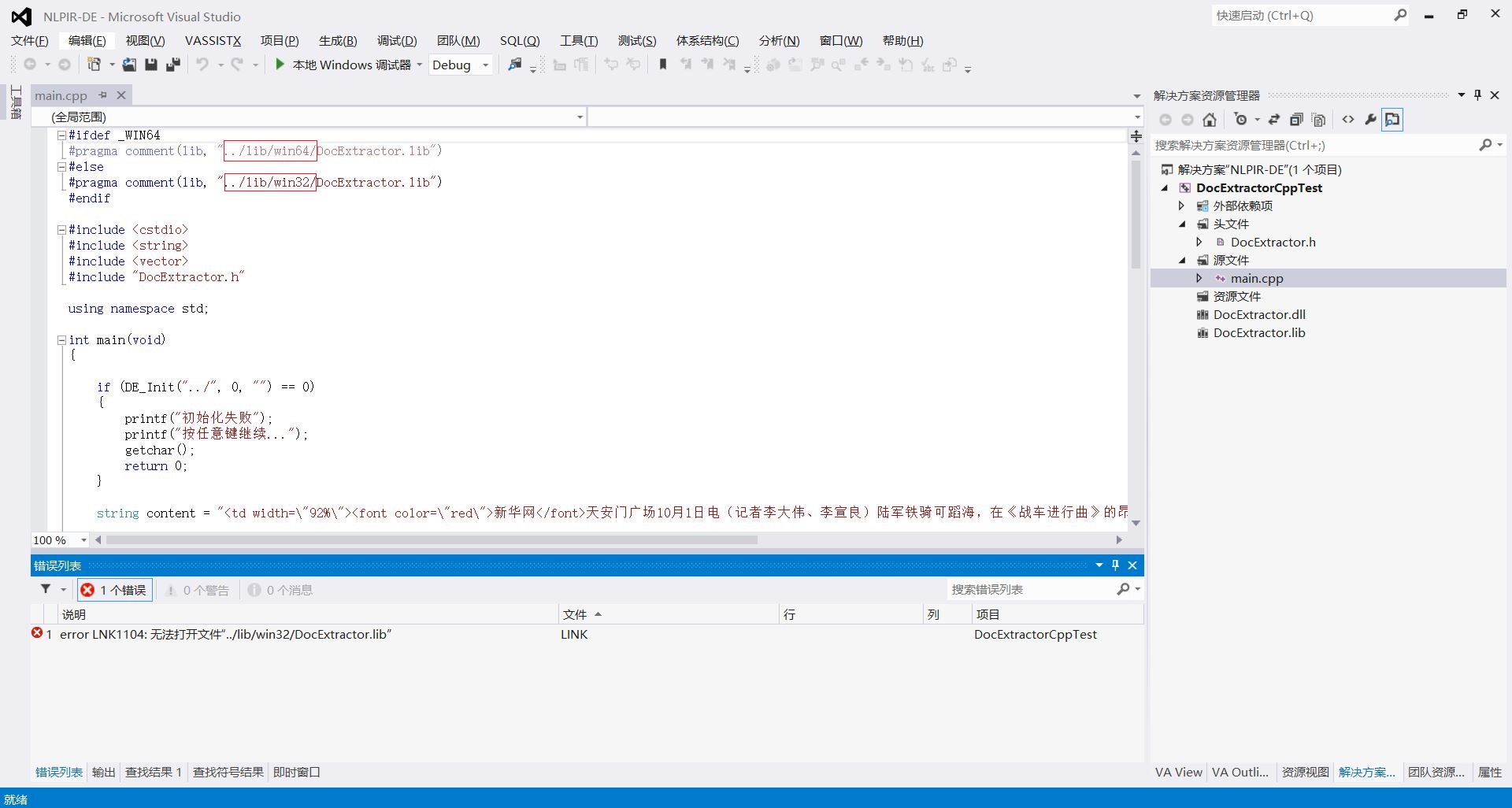
11.去掉之后再点击运行就可以正常运行了,效果如下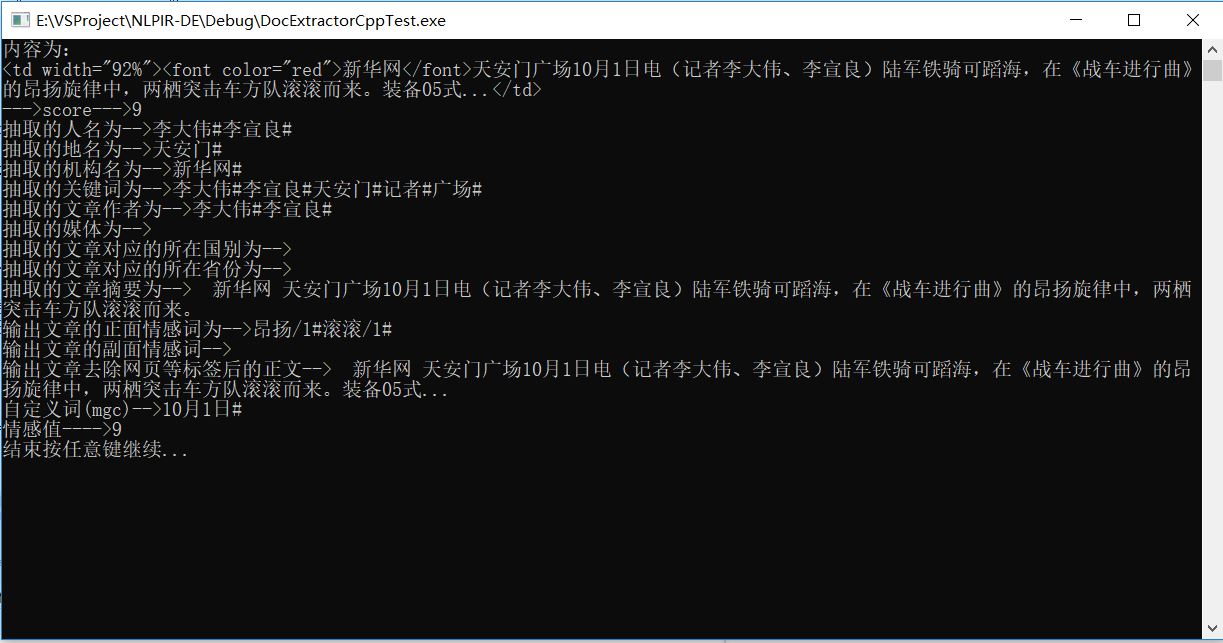 # 三.注意事项
# 三.注意事项
1. 之所以去掉红框中标注的代码是要把dll与lib的文件路径修改正确2. license授权文件每月更新一次,因此DATA文件夹下的授权文件DocExtractor.user要保持最新版本
2018.4.6