Trie(字典树),正如它的名字一样,其主要的作用就是来存储字符串的,用它来实现字符串的查找效率比较高,查找的时间复杂度主要和它的元素(字符串的长度)O(W)相关,但是消耗的内存也比较大。
字典树主要应用于:
- 字符串的检索
- 词频统计
- 字符串的排序
利用Trie实现敏感词过滤器主要有下面三个步骤:
- 定义前缀树
- 根据敏感词,初始化前缀树
- 编写过滤敏感词的算法
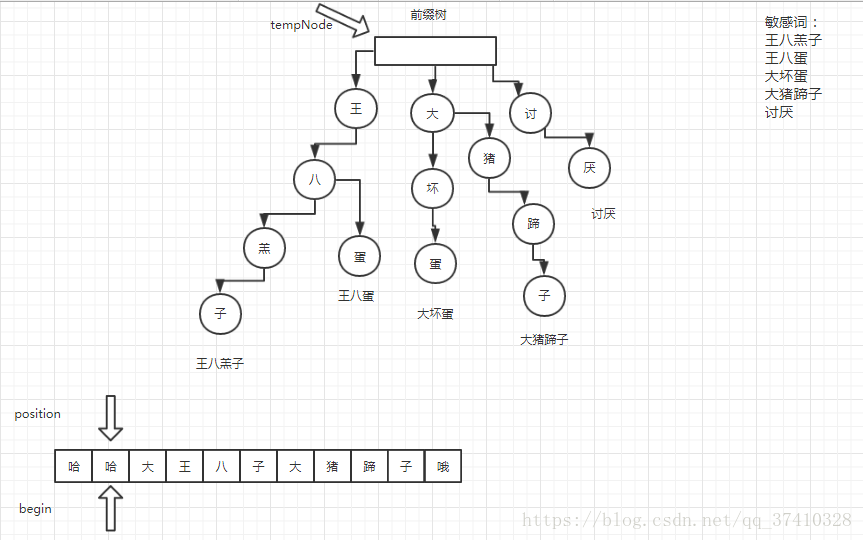
定义和初始化前缀树
- 根节点没有字符
- 除了根节点每个节点都只有一个字符
- 每个节点所有的子节点的字符都不相同
字符串的每个字符作为一个Node节点,Node’节点主要有两部分组成
1.是否为单词(boolean isKeyWordEnd)
2.节点所有的子节点,用map来保存 key是字符,value 是子节点
//定义前缀树private class TrieNode {//表示是否为关键词的结尾private boolean isKeyWordEnd = false;//子节点private Map<Character, TrieNode> subNodes = new HashMap<>();//判断是否是关键词的结尾public boolean isKeyWordEnd() {return isKeyWordEnd;}//设置关键词的结尾为truepublic void setKeyWordEnd(boolean isKeyWordEnd) {this.isKeyWordEnd = isKeyWordEnd;}//添加子节点public void addSubNode(Character c, TrieNode node) {subNodes.put(c, node);}//获取子节点public TrieNode getSubNode(Character c) {return subNodes.get(c);}}
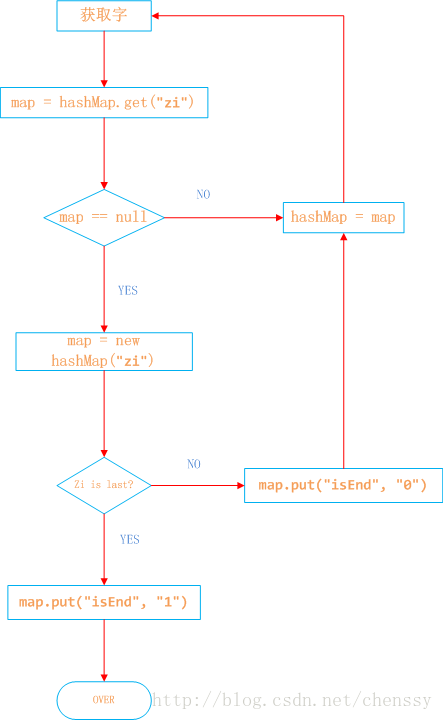
根据敏感词,初始化前缀树
//将一个敏感词添加到前缀树中private void addKeyWord(String keyword) {TrieNode temp = rootNode;for (int i = 0; i < keyword.length(); i++) {char c = keyword.charAt(i);TrieNode subNode = temp.getSubNode(c);//如果子节点中不存在该字符节点if (subNode == null) {subNode = new TrieNode();temp.addSubNode(c, subNode);}//指向下一个节点,进行下一个循环temp = subNode;//如果遍历到字符结束的位置,就要设置节点的字符结束标志位为trueif (i == keyword.length() - 1) {temp.setKeyWordEnd(true);}}}
例如把单词abc插入到前缀树中,如果用户输入ab,尽管abc包含了ab,但是trie中仍然不包含ab这个单词,所以插入到单词的最后一个位置时,需要设置当前最后一个节点的结束标志位为true,代表这是一个完整的敏感词。

敏感词过滤算法的实现
设置三个指针
指针1:初始时指向前缀树的root根节点
指针2:初始时指向待过滤字符的头结点,表示敏感词的开头
指针3:初始时指向待过滤字符的头结点,表示敏感词的末尾
利用StringBuilder接收返回值

在指针1所指向节点的子节点中寻找是否出现指针3所指向的字符,如果没有指针2和指针3进入下一个位置,并将滑过的值添加到stringbuilder中。

当指针1之指向的节点的子节点中能找到指针3指向的值时,指针1指向对应的子节点,指针2在原位置不动(疑似敏感词的开头位置)

指针3继续步进,此时在指针1对应的子节点中找不动指针3的值f!=c,指针3就要回到指针2的下一个节点,指针1需要回到根节点,继续寻找以b开头的字符是不是敏感词。


指针3继续步进,并与指针1指向的节点的自己点的值比对,当两者都指向字符’f’的时候,判断节点f的敏感词标志位是否为true,如果为true表示找到一个敏感词,并将其替换为‘***’添加到stringbuilder中,随后指针2指向指针3的下一个位置即a,指针1重回root,继续进行过滤。


//敏感词过滤算法的实现public String filter(String text){if(StringUtils.isBlank(text)){return null;}//指针1TrieNode tempNode=rootNode;//指针2 指向字符的开头int begin=0;//指针3 指向疑似敏感字符的结尾int position=0;//结果StringBuilder sb=new StringBuilder();while(begin<text.length()) {char c = text.charAt(position);//跳过符号if (isSymbol(c)) {//如果指针1处于根节点,将此符号计入结果,让指针2向下走一步if (tempNode==rootNode) {sb.append(c);begin++;}//无论符号在开头还是中间,指针3都向下走一步position++;continue;}//检查下级节点tempNode=tempNode.getSubNode(c);if (tempNode==null){//以begin开头的字符串不是敏感词sb.append(text.charAt(begin));//进入下一个位置position=++begin;//重新指向根节点tempNode=rootNode;}else if (tempNode.isKeyWordEnd()){//发现敏感词,将begin-position字符串替换点sb.append(REPLACEMENT);//进入下一个位置begin=++position;//重新指向根节点tempNode=rootNode;}else{//检查下一个字符if (position<text.length()-1){position++;}}}sb.append(text.substring(begin));return sb.toString();}
测试:
@Testpublic void testSensitiveFilter(){String text="这里可以赌博,可以嫖娼,可以吸毒,可以开票";text=sensitiveFilter.filter(text);System.out.println(text);text="这里可以🀁赌博,可以🀂嫖娼,可以🀂🀂🀂吸毒,可以开🀃🀃🀃票";text=sensitiveFilter.filter(text);System.out.println(text);}
结果:




![[转*摘要*总结]敏感词过滤的算法原理之DFA算法](https://img-blog.csdnimg.cn/20200612123501562.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2RvY3RvcnZpYW4=,size_16,color_FFFFFF,t_70)