之前写过一篇关于Trie树的介绍:Trie树——在一个字符串集合中快速查找某个字符串。今天就用Trie树来实现敏感词过滤算法。
首先简单介绍一下Trie树的数据结构:
1.根节点不存储字符。
2.Trie树中除了根节点外其余节点都需要存储一个字符,另外还需要一个标记来确定当前节点是否为敏感词中的最后一个字符。
3.每个节点的所有子节点包含的字符都不相同。
了解了Trie树的基本结构,就可以开始思考如何构造我们的敏感词树。我又把这张图搬出来了:
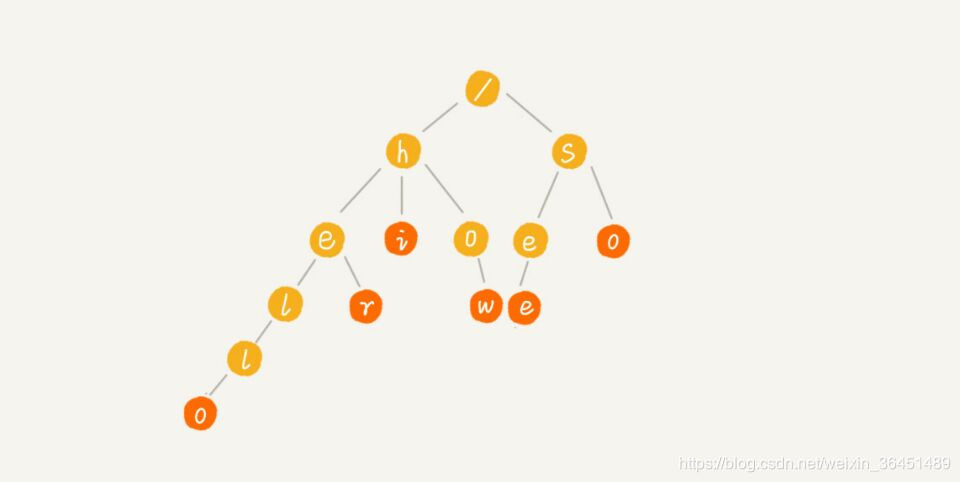
假设我们的敏感词是[hello,her,how,see,so],那么我们的敏感词树就长成上图那样。Trie树的节点数据结构设计:
class TrieNode{//key为子节点字符,value为字节点的子节点Map<Character,TrieNode> subnodes = new HashMap<Character, TrieNode>();//isend标记该节点中的字符是否为为敏感词中的最后一个字符boolean isend = false;//添加子节点void addSubNode(Character key,TrieNode subnode){subnodes.put(key,subnode);}//获取下一个节点TrieNode getSubNode(Character key){return subnodes.get(key);}//判断是否为最后一个节点boolean isEnd(){return isend;}//设置标记void setEnd(boolean end){this.isend = end;}//获取子节点个数int getSubNodesCount(){return subnodes.size();}}
敏感词过滤算法思想:
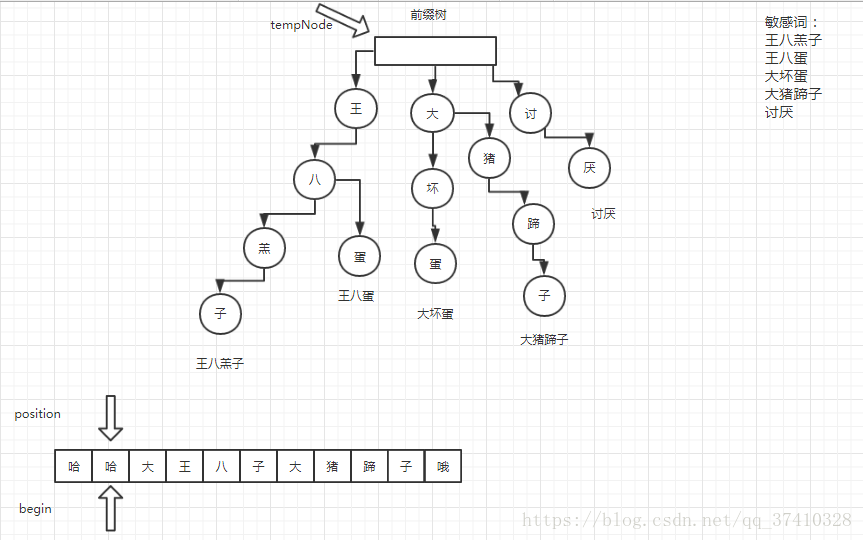
假设有一串字符串“abhelhiwhowab”,根据上面构造好的敏感词树过滤敏感词,则过滤后的字符串为abhel***w***ab。具体的思路就是——
先定义三个指针:
int begin : 指向字符串中已匹配串的后一位。
int position :指向字符串中当前匹配到的位置。
TrieNode tempNode :指向字典树中与position匹配到的节点位置。初始时,指向字典树的根节点位置。

判断position指向的字符x是否存在与tempNode的子节点中(tempNode = tempNode.getSubNode(x))
- 若不存在,则将当前字符append到结果字符串中(结果字符串为StringBuilder类型变量,初始值为空)。并将begin指针都后移一位,position指针指向begin所指的位置,tempNode指向字典树的树根,准备进行下一次判断。
- 若存在,判断节点标记是否为true
①若不是,position后移一步,准备进行下一次判断。

②若是,结果字符串中append("***"),position指向下一个位置,begin指向position所指的位置,tempNode指向字典树的根节点,准备进行下一次判断。

详细代码:
package com.example.demo.service;import org.apache.commons.lang3.CharUtils;
import org.springframework.stereotype.Service;import java.util.HashMap;
import java.util.Map;@Service
public class SensitiveService{private class TrieNode{//key为子节点字符,value为字节点的子节点Map<Character,TrieNode> subnodes = new HashMap<Character, TrieNode>();//isend标记该节点中的字符是否为为敏感词中的最后一个字符,true代表是boolean isend = false;//添加子节点void addSubNode(Character key,TrieNode subnode){subnodes.put(key,subnode);}//获取下一个节点TrieNode getSubNode(Character key){return subnodes.get(key);}//判断是否为最后一个节点boolean isEnd(){return isend;}//设置标记void setEnd(boolean end){this.isend = end;}//获取子节点个数int getSubNodesCount(){return subnodes.size();}}//创建一个根结点private TrieNode root = new TrieNode();//添加敏感词private void addWord(String word){TrieNode tempNode = root;for(int i=0;i<word.length();++i){char c = word.charAt(i);//过滤掉敏感词中的特殊字符if(isSymbol(c)){continue;}//如果root的子节点中没有当前字符,则添加, (否则,跳过该字符)TrieNode node = tempNode.getSubNode(c);if(node == null){node = new TrieNode();tempNode.addSubNode(c,node);}tempNode = node;//设置关键词标志if(i==word.length()-1){tempNode.setEnd(true);}}}//跳过特殊字符private boolean isSymbol(char c) {int ic = (int) c;// 0x2E80-0x9FFF 东亚文字范围return !CharUtils.isAsciiAlphanumeric(c) && (ic < 0x2E80 || ic > 0x9FFF);}//过滤敏感词public String filtSensitiveWord(String str){if(str==null)return str;//结果字符串StringBuilder sb = new StringBuilder();int begin = 0;int position = 0;TrieNode tempNode = root;while(position<str.length()){char c = str.charAt(position);//过滤掉符号字符if(isSymbol(c)){if(tempNode==root){begin++;}position++;continue;}tempNode = tempNode.getSubNode(c);//当前字符不在敏感词树中if(tempNode == null){sb.append(c);begin++;position = begin;tempNode = root;}else{if(tempNode.isEnd()){sb.append("***");position++;begin = position;}else{position++;}}}//append最后一个子串sb.append(str.substring(begin));return sb.toString();}public static void main(String[] args){SensitiveService service = new SensitiveService();service.addWord("敏感词");service.addWord("要过滤");System.out.println(service.filtSensitiveWord("这个敏 感*词haha要 过 滤呀哎呀!"));}
}


![[转*摘要*总结]敏感词过滤的算法原理之DFA算法](https://img-blog.csdnimg.cn/20200612123501562.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2RvY3RvcnZpYW4=,size_16,color_FFFFFF,t_70)