第七届“泰迪杯”数据挖掘挑战赛——C 题:运输车辆安全驾驶行为的分析
- 一、问题背景
- 二、研究问题
- 三、分析问题
- excel的批量处理
- 时间、速度、方向角的处理
- 经纬度的处理
- 大数据处理的优化
一、问题背景
车联网是指借助装载在车辆上的电子标签通过无线射频等识别技术,实现在信息网络平
台上对所有车辆的属性信息和静、动态信息进行提取和有效利用,并根据不同的功能需求对
所有车辆的运行状态进行有效的监管和提供综合服务的系统。当前道路运输行业等相关部门
利用车联网等系统数据,开展道路运输过程安全管理的数据分析,以提高运输安全管理水平
和运输效率。
某运输企业所辖各车辆均存在常规运输路线与驾驶人员。在驾驶员每次运输过程中,车
辆均可自动采集当前驾驶行为下的行车状态信息并上传至车联网系统。驾驶行为可能随气
象、路况等因素的变化而变化,进一步影响行车安全、运输效率与节能水平。
请根据该运输企业所采集的数据(见附件 1、附件 2),分析车辆行驶过程中的驾驶行为
对行车安全、运输效率与节能情况的影响,运用数据挖掘的方法,建立有效的数学模型进行
评价。
二、研究问题
(1) 利用附件 1 所给数据,提取并分析车辆的运输路线以及其在运输过程中的速度、加
速度等行车状态。提交附表中 10 辆车每辆车每条线路在经纬度坐标系下的运输线路图及对
应的行车里程、平均行车速度、急加速急减速情况。
(2) 利用附件 1 所给数据,挖掘每辆运输车辆的不良驾驶行为,建立行车安全的评价模
型,并给出评价结果。
(3) 综合考虑运输车辆的安全、效率和节能,并结合自然气象条件与道路状况等情况,
为运输车辆管理部门建立行车安全的综合评价指标体系与综合评价模型。
在车辆运输过程中,不良驾驶行为主要包括疲劳驾驶、急加速、急减速、怠速预
热、超长怠速、熄火滑行、超速、急变道等。
三、分析问题
首先,题目给了有十三维数据,总共450个excel,以及一个天气汇总表。
我们观察到,450个excel数据格式都是一样的,平均每个excel有七八万条数据,如果手动计算挖掘的话,肯定会很麻烦。
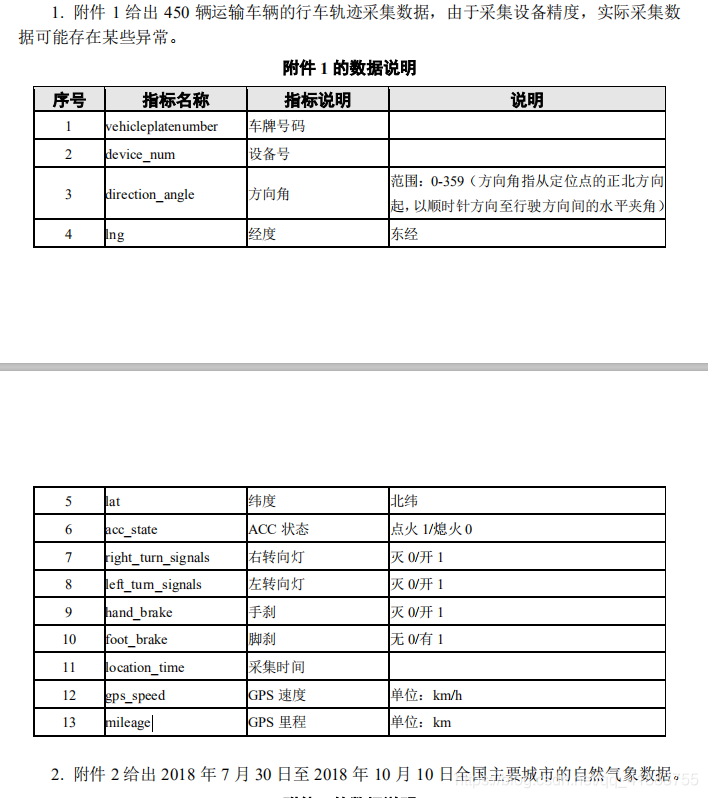
excel的批量处理
首先,我们来进行批量excel的处理。
import numpy as np #che su wending xing
import pandas as pd
import osdef file_name( user_dir):file_list = list()for root, dirs, files in os.walk(user_dir):for file in files:# if os.path.splitext(file)[1] == '.txt':if file.split('.')[-1]=='csv':file_list.append(os.path.join(root, file))return file_list
path="d:\\car" #此处的路径为存放excel的根目录
csv=file_name(path) #得到一个列表,里面为450个excel的存放地址
for j in range(len(csv)): #遍历这个列表data=pd.read_csv(csv[j]) #遍历每个excelfunction(data) #对每辆车的数据进行相应的处理
通过打印输出csv列表,得到如下:
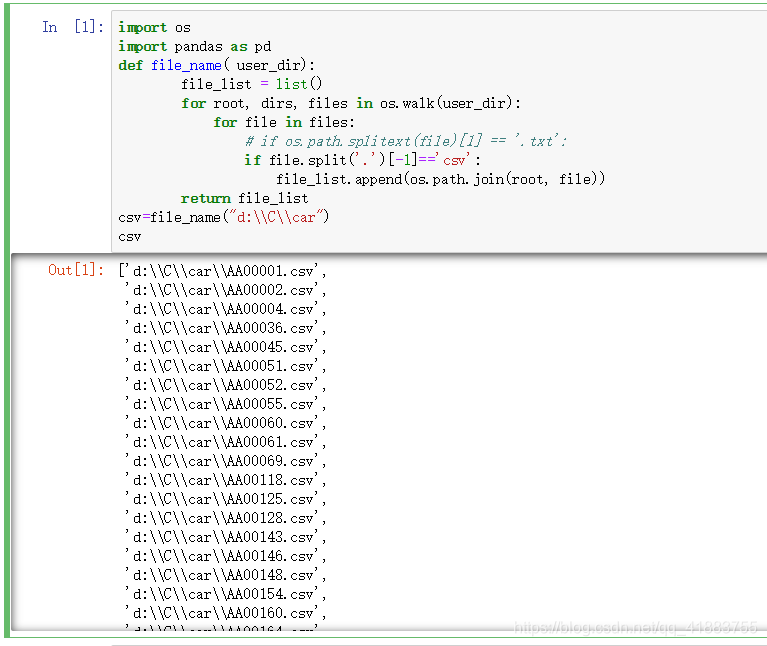
我们的第一步,批量操作excel这一步完成了。
接下来就是对单个excel进行数据处理了。
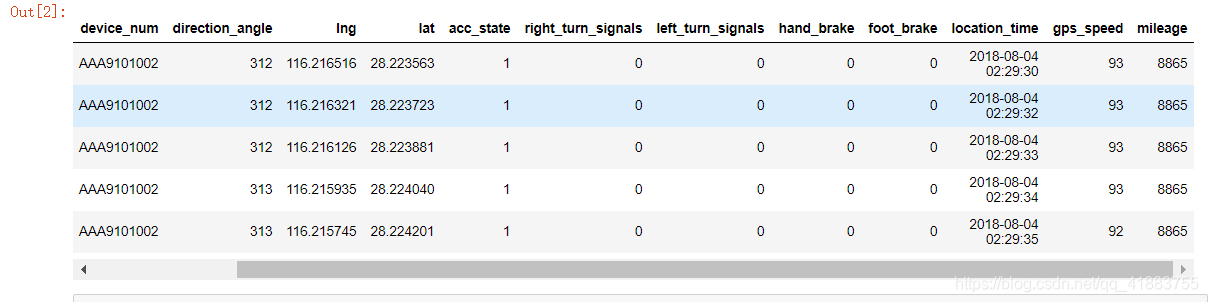
时间、速度、方向角的处理
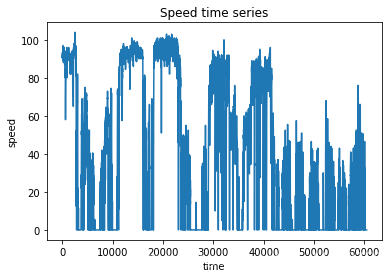
我们能够发现,方向角,经纬度,以及时间轴,acc状态,还有速度里程这几个变量可以为我们所利用。
很显然,我们可以知道这是一个基于时间序列的操作。
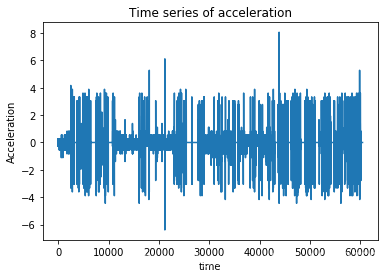
我们可以观察到时间轴的数据格式,转换为我们需要的格式,比如第二条时间减去第一条时间就是△t啦,这样我们就可以通过a=△v/△t,来计算加速度啦。
如何利用时间轴的数据呢?
下面这一个时间格式转换函数,相信对你一点有帮助。
import time
import datetime
import mathdef composeTime(time1):time2 = datetime.datetime.strptime(time1, "%Y-%m-%d %H:%M:%S")time3 = time.mktime(time2.timetuple())time4 = int(time3)return time4
t=[]
v=[]
for i in range(len(data["location_time"])):t1=data["location_time"][i]t2=data["location_time"][i+1]v1=data["gps_speed"][i]v2=data["gps_speed"][i+1]t0=t2-t1v0=v2-v1t.append(t0)v.append(v0)这里面的△t和△v在列表t和列表v里面,相应的,我们还可以得到角变化量,进一步得到角加速度,可以用来判断急转弯,通过±a可以来判断急加速急减速。
经纬度的处理
经纬度的处理有很多方法,这里我们用python第三方库中最好用的一个库folium,自带地图。
当然,也有plotly,google earth呀,很多画地图的软件,这里,我们挑一个最简单的库。
import numpy as np
import pandas as pd
import seaborn as sns
import folium
import webbrowser
from folium.plugins import HeatMap
import osposi=pd.read_csv("D:\\C\\first\\AB00006.csv")lat = np.array(posi["lat"]) # 获取维度之维度值
lon = np.array(posi["lng"]) # 获取经度值
pop = np.array(posi["gps_speed"]) # 获取人口数,转化为numpy浮点型data1 = [[lat[i],lon[i],pop[i]] for i in range(len(lat))] #将数据制作成[lats,lons,weights]的形式
m = folium.Map([ 33., 113.], tiles='stamentoner', zoom_start=5)route = folium.PolyLine( #polyline方法为将坐标用线段形式连接起来data1, #将坐标点连接起来weight=3, #线的大小为3color='orange', #线的颜色为橙色opacity=0.8 #线的透明度
).add_to(m) #将这条线添加到刚才的区域m内m.save(os.path.join(r'd:\\C\\car', 'AA000002.html'))
m
我们得到如下路线图,观察到了存在一些漂移点。
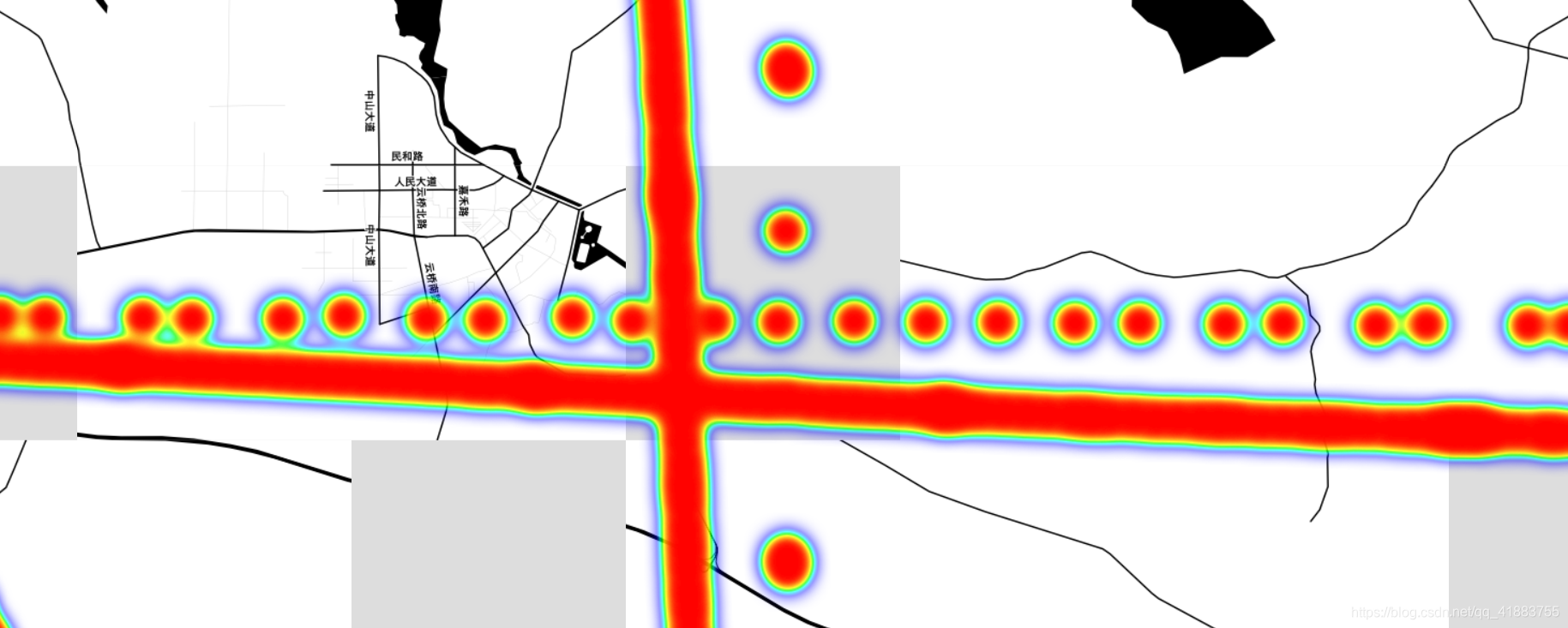
这时,我们可能不知道怎么去处理这些异常点,或者说是漂移点。
我们应该通过计算速度与实际距离的关联性来判断是否为异常点。这时,我们需要用到下面这个经纬度与实际距离转换的函数来作进一步的优化:
def hypot(x,y):return math.sqrt(x**2+y**2)def distance(lat1, lon1, lat2, lon2):PI = 3.1415926535898R = 6.371229 * 1e6x = (lon2 - lon1) * PI * R * math.cos( ( (lat1 + lat2) / 2) * PI / 180) / 180y = (lat2 - lat1) * PI * R / 180out = hypot(x, y)return out
我们可以通过实际的 经纬度转换距离d 是否在 gps_speed *△t 理论距离这个正常区间范围内 。
大数据处理的优化
当我们把所有的分析代码写完之后,你会很开心地开始运行,你会发现速度会特别的慢,450个excel大约需要等待两个半小时,你可以打三把英雄联盟。
这里,我们需要用到一个第三方库numba,pip install numba 即可安装完毕。
@nb.jit 这个函数修饰器加速效果特别明显,也还有其他相关的库,有兴趣的同学可以自己去找找。
以下为计算车速稳定性的加速版完整excel处理代码:
import numpy as np #che su wending xing
import pandas as pd
import seaborn as sns
import folium
import webbrowser
from folium.plugins import HeatMap
import os
import time
import datetime
import matplotlib.pyplot as plt
import math
import numba as nbdef composeTime(time1):time2 = datetime.datetime.strptime(time1, "%Y-%m-%d %H:%M:%S")time3 = time.mktime(time2.timetuple())time4 = int(time3)return time4def hypot(x,y):return math.sqrt(x**2+y**2)@nb.jit
def distance(lat1, lon1, lat2, lon2):PI = 3.1415926535898R = 6.371229 * 1e6x = (lon2 - lon1) * PI * R * math.cos( ( (lat1 + lat2) / 2) * PI / 180) / 180y = (lat2 - lat1) * PI * R / 180out = hypot(x, y)return outdef file_name( user_dir):file_list = list()for root, dirs, files in os.walk(user_dir):for file in files:# if os.path.splitext(file)[1] == '.txt':if file.split('.')[-1]=='csv':file_list.append(os.path.join(root, file))return file_list@nb.jit
def ji_wending_jit():for j in range(3):data=pd.read_csv(csv[j])v=[]count=0t=0for i in range(len(data["gps_speed"])-1):t1 = composeTime(data["location_time"][i])t2 = composeTime(data["location_time"][i+1])v1 = data["gps_speed"][i]if t2-t1<=100 and v1>0:count=count+1v.append(v1)t=t+(t2-t1)arr_std_v = np.std(v,ddof=1)arr_std_v_list.append(arr_std_v)T.append(t/(60*60))print("第"+str(j)+"个车分析完成")print("finish")csv=file_name("d:\\C\\car")T=[]
arr_std_v_list=[]
ji_wending_jit()Data=[]
Data.append(arr_std_v_list)print(Data)print(T)
#columns=["arr_std_v_list" ]# list转dataframe
#x=np.array(Data)
#print("finish the while")
#y=np.transpose(x)
#print("finish the transpose")
#df = pd.DataFrame(y, columns=columns)# 保存到本地excel
#df.to_excel("d:\\car_wendingxing.xlsx", index=False)
#print("save the excel")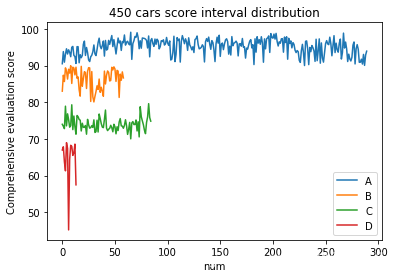
得到了以下450辆车的排名和分布等级阶段。
这就是我对以上数据处理的过程。
由于笔者能力有限,如有不正确的地方,还请各位点名批评,互相交流学习。





![[数据挖掘案例]逻辑回归LR模型实现电商商品个性化推荐](https://img-blog.csdn.net/20180704175028369?watermark/2/text/aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dvbml1MjAxNDEx/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70)







