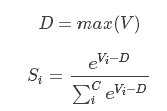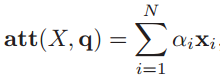注意力最近几年在深度学习各个领域被广泛使用,无论是图像分割、语音识别还是自然语言处理的各种不同类型的任务中,注意力机制都在其中大放异彩
介绍
注意力(attention)机制最初应用于机器翻译任务,现在已被广泛地应用于深度学习的各个领域,无论是图像分割、语音处理,还是在计算机视觉和自然语言处理的各种不同类型的任务,注意力机制都在其中大放异彩。
在认知科学中,由于信息处理的瓶颈,人类会选择性地关注所有信息的一部分,同时忽略其他信息。同理,当神经网络处理大量的信息输入时,快速聚焦其中一些关键信息来进行处理,这便是注意力机制。
决定需要关注输入的哪部分
分配有限的信息处理资源给重要的部分
注意力机制一般分为两种
聚焦式(Focus)注意力:自上而下的有意识的注意力
这种注意力是需要设计或是经过学习才能产生的,所以称为自上而下的,或称为有意识的。在这一节我们主要对这种自上而下的注意力进行了解。
显著性(Saliency-Based)注意力:自下而上的无意识的注意力
在很常见的卷积神经网络和循环神经网络中,可以将 池化(max pooling)、门控(Gating) 近似看作是自下而上的基于显著性的注意力机制。自下而上的意思是,这种注意力不需要策略和判断,也不需要经过学习,所以是无意识的。
举个简单的例子,你和朋友走在大街上,在嘈杂的街道中你仍能听清你朋友的声音,这就是聚焦式注意力;这时你突然听到有人从后面喊你名字,这就是显著式注意力。
基础知识
数学上,注意力机制是加权求和
形式上,注意力机制是键值查询
应用上,注意力机制是相似性度量
简单注意力的计算
NLP中,主要分为两步:
- 在所有输入信息上计算注意力分布
- 根据注意力分布计算输入信息的加权和,以此选择关键信息
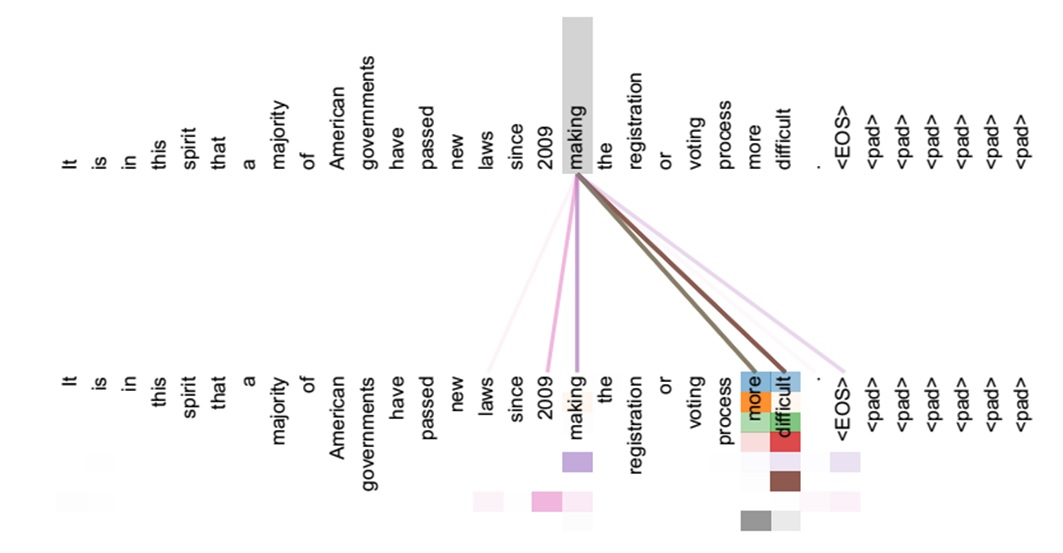
查询向量和打分函数
为了实现选择关键的信息来进行处理,我们引入了一个与任务相关的查询向量 q q q,并且使用一个打分函数 s s s来计算不同信息向量与查询向量的相关性。
查询向量通过线性变换得到
Q = W Q X Q=W_QX Q=WQX
对于键值对模型
K = W K X V = W V X K=W_KX\\ V=W_VX K=WKXV=WVX
常见的打分函数有
- 加性模型: v T tanh ( W x i + U q ) v^T\tanh(Wx_i+Uq) vTtanh(Wxi+Uq)
- 点积模型: x i T q x_i^Tq xiTq
- 缩放点积模型: x i T q d \frac{x_i^Tq}{\sqrt d} dxiTq
- 双线性模型: x i T W q x_i^TWq xiTWq
其中 W , U , v W,U,v W,U,v为可训练的参数,d为输入向量的维度。
点积模型相较于加性模型效率更高,但是当输入向量维度过高,点积模型通常有较大的方差,从而导致softmax函数梯度较小,而缩放点积模型可以很好地解决这个问题。
双线性模型可以看作一种更泛化的点积模型,引入了非对称性。
注意力分布
α i \alpha_i αi为在给定 q i 、 x i q_i、x_i qi、xi时 x i x_i xi被选择的概率。
以最简单的softmax模型为例,
KaTeX parse error: No such environment: align at position 8: \begin{̲a̲l̲i̲g̲n̲}̲ \alpha_i&=p(z=…
加权和
a t t e n t i o n ( X , Q ) = ∑ i = 1 N α i x i attention(X,Q)=\sum_{i=1}^N\alpha_ix_i attention(X,Q)=i=1∑Nαixi
即为输入向量与其注意力分布点积之和。以上都是向量哦
加权和有两种模式:
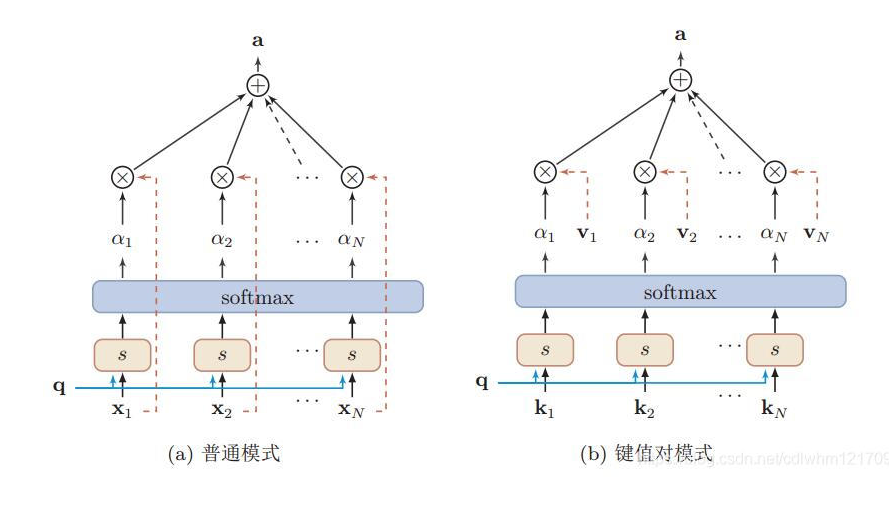
对于键值对模式,计算可分为三个部分:
-
依据q和k计算二者的相似度
S i = F ( Q , k i ) S_i=F(Q,k_i) Si=F(Q,ki) -
使用softmax函数得到注意力分布
α i = s o f t m a x ( s i ) \alpha_i=softmax(s_i) αi=softmax(si) -
加权和
a t t e n t i o n ( ( K , V ) , Q ) = ∑ i = 1 N α i v i attention((K,V),Q)=\sum_{i=1}^N\alpha_iv_i attention((K,V),Q)=i=1∑Nαivi
即将输入向量以键值对的形式表达,K用来计算注意力分布,V用来聚合信息。
其他注意力模型
硬注意力机制
上述通过加权和计算是一种软注意力
硬注意力机制只关注某一个输入向量,通常两种方法实现:
- 直接选取概率最高的向量
- 在注意力分布上随即采样选取某个向量
然而使用最大或随机采样,损失函数与注意力分布之间的函数不可导,无法进行反向传播,这也是硬注意力机制的一大特征。
多头注意力机制
通过多个查询向量 [ q 1 , ⋯ , q m ] [q_1,\cdots,q_m] [q1,⋯,qm]来并行地从输入中选取多组信息,每个注意力关注不同的部分。
a t t e n t i o n ( ( K , V ) , Q ) = a t t e n t i o n ( ( K , V ) , q 1 ) ⊕ ⋯ ⊕ a t t e n t i o n ( ( K , V ) , q m ) attention((K,V),Q)=attention((K,V),q_1)\oplus\cdots\oplus attention((K,V),q_m) attention((K,V),Q)=attention((K,V),q1)⊕⋯⊕attention((K,V),qm)
自注意力机制
减少对外部信息的依赖,尽可能地利用特征内部固有的信息进行注意力的交互。
上述的普通模式和键值对模式都是一种自注意力模型
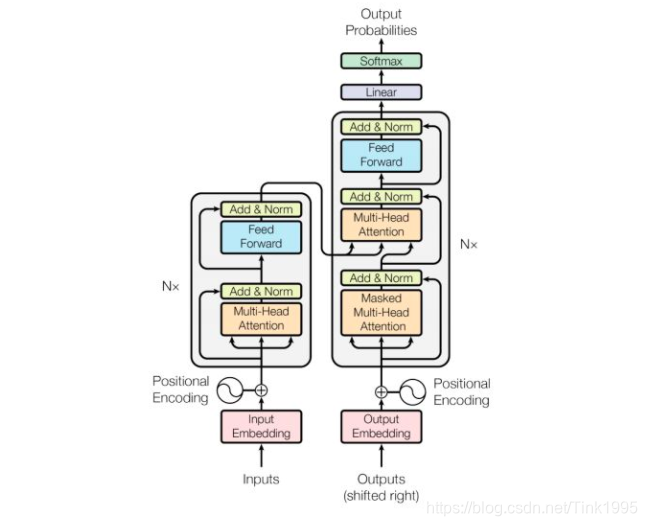
另一方面,自注意力机制可以捕获长距离关系,nlp中,每个词与其他所有词都要进行计算。(具体表现在Softmax上)
最为著名的模型即transformer,具体可见此
注意力机制在计算机视觉中的应用
注意力机制没有严格的的数学定义,例如传统的局部图像特征提取、滑动窗口方法等都可以看做一种注意力机制。在神经网络中,注意力机制通常是一个额外的神经网络,能够硬性的选择输入某些部分,或者给输入的不同部分分配不同的权重。
只要是能够从大量信息中筛选出有用的信息,就能够称为注意力机制。
首先让我们关注硬注意力,它是一个0/1问题,上文已经提到,不可微是硬注意力的一个特点,其更关注每一个点,哪些点被关注是一目了然的。
接下来关注应用更广的软注意力,通过域的划分可以分为以下几点
空间域
顾名思义,就是在图像的空间上进行筛选信息。
Spatial Transformer Networks
我们希望我们的神经网络能具有空间不变性,即在目标进行平移、旋转、放大等操作后,网络仍然能够得到正确的结果,然而我们的CNN在这方面的能力是不够的,因此提出了STN(空间转换网络),其将原始图片变换到另一个空间
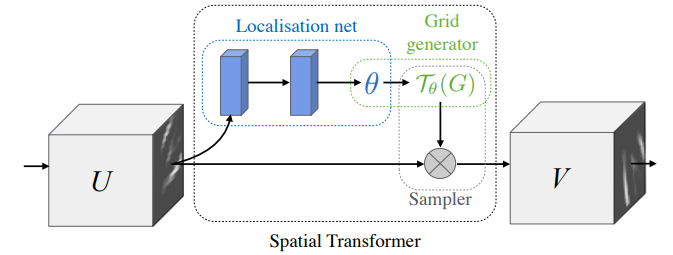
Spatial Transformer主要分为三个部分:
- Localisation net:得到参数 θ \theta θ,用于第二步使用
- Grid generator:通过参数 θ \theta θ得到目标坐标点
- Sampler:填充
具体可看论文。
Reverse Attention-Based Residual Network
RAS-net是显著性目标检测方向的一个网络,它添加了一种注意边缘的反向注意力模块来提升分割精度。
其网络结构在主干网络之后分为几个侧输出,R为注意力模块,并由最后的输出向上开始反向实现注意力。
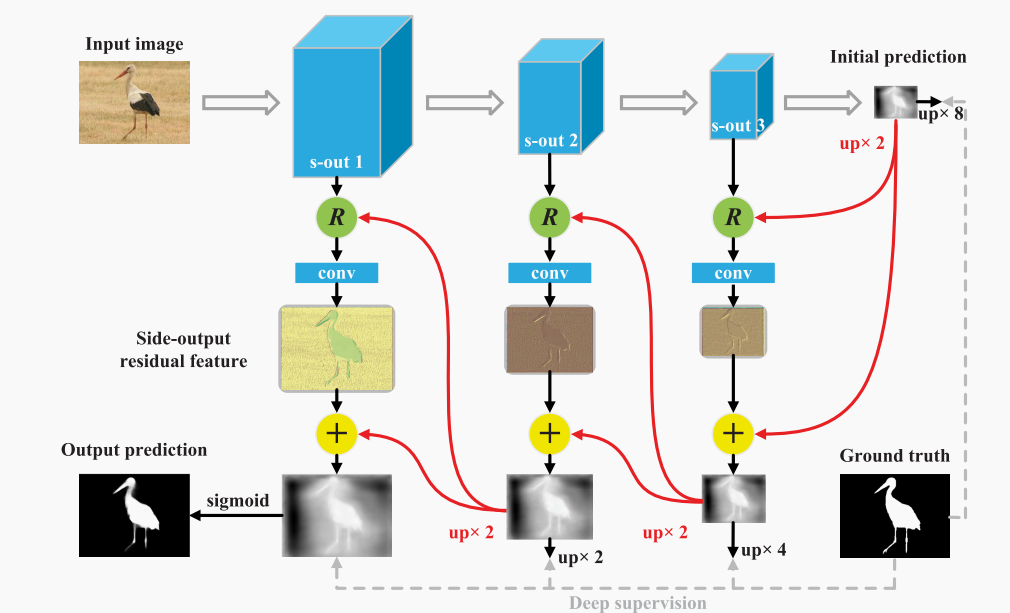
其中注意力模块的结构为:
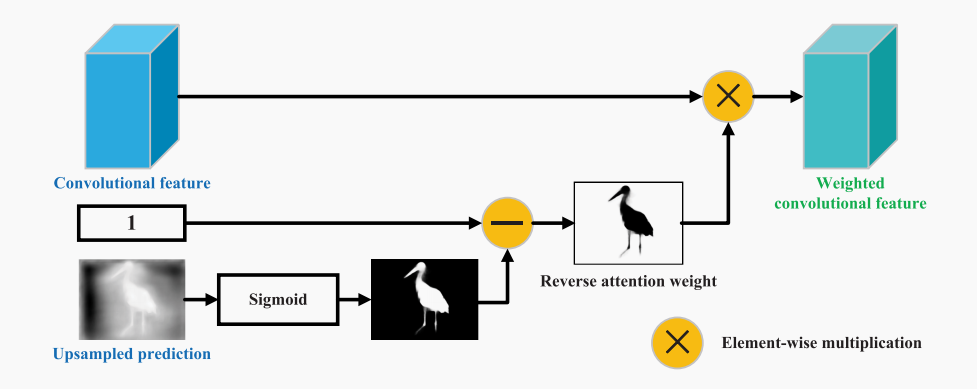
可以看到,对于某一层:
- 其下一层的输出首先会做一个上采样,并使用一个Sigmoid函数生成一个0-1之间的权重图
- 使用1减去权重图得到最终的注意力图,代码实现中我们使用
torch.sigmoid(-x)来获得同样的效果 ,这里使用1减可能是为了获得对边缘的注意。 - 与该层输入进行乘加操作
Double Attention Networks
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tFicFpe3-1632536178439)(/home/czh/.config/Typora/typora-user-images/image-20210601200552199.png)]
主要分为一下几个部分:
- Feature Gathering:
空间域的缺点便是忽略了通道信息。
通道域
首先让我们从信号变换的角度理解通道中到底储存着什么信息
推荐阅读:傅立叶变换
池化《深度学习》一书中解释道:“卷积等效于使用傅里叶变化将输入与核都转换到频域、执行两个信号的逐点相乘,再使用傅里叶逆变换转换回时域。”,即通过卷积可将特征图的信息分解成n个不同卷积核上的信号分量。另外,这些信息分量的频率不同,低频特征主要表示轮廓,高频特征主要表示细节。考虑到特征图过多的通道数对于关键信息的贡献不同,我们可以给每个通道上的信号都添加一个权重,用来表示通道信息的重要程度。
Squeeze-and-Excitation Networks
SEnet通过全连接层的隐式学习来得到不同通道的重要程度
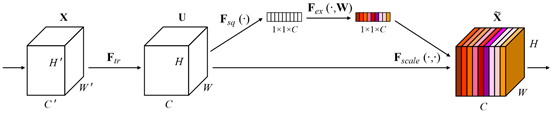
SEnet主要分为两个部分:
- Squeeze:对输入特征图进行全局平均池化
- Excitation:使用一个Bottleneck结构与Sigmoid激活函数来获得权重

最后直接与输入相乘就行了
SK(select kernel)net:
灵感来源是,我们在看不同尺寸不同远近的物体时,视觉皮层神经元接受域大小是会根据刺激来进行调节的。那么对应于CNN网络,一般来说对于特定任务特定模型,卷积核大小是确定的,那么是否可以构建一种模型,使网络可以根据输入信息的多个尺度自适应的调节接受域大小呢?
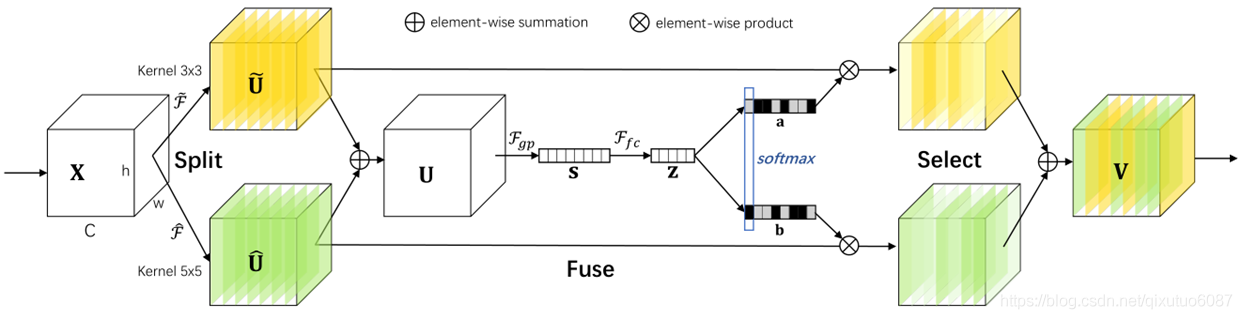
SKnet分别使用3X3和5X5的卷积核(也可以使用更多不同大小的卷积核)来得到在不同感受野下的特征图,相加之后使用与SEnet相同的结构,但是在最后添加了一个softmax来获得两个特征图上通道的权重。
Efficient Channel Attention for Deep Convolutional Neural Networks
来自于CVPR2020,类似于SE模块的结构,拥有更小的计算量和参数量
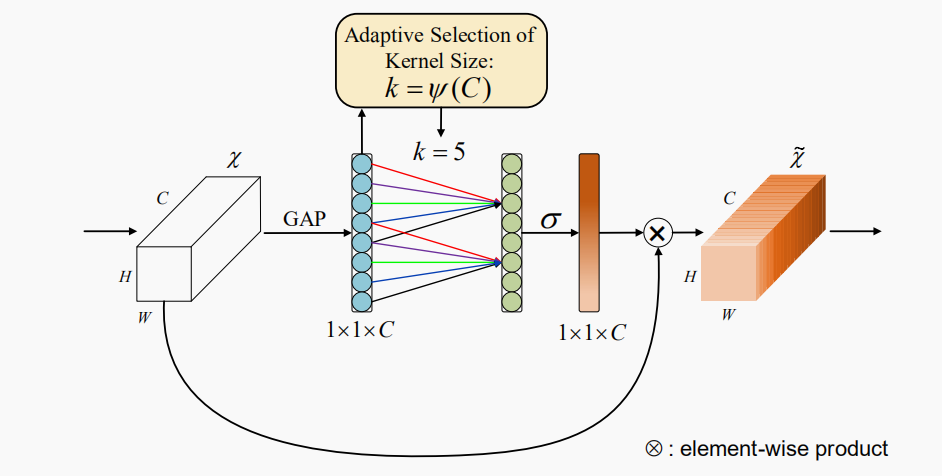
不同于SEnet使用两层全连接层来得到通道权重,ECAnet直接使用一维卷积,其中卷积核的大小k通过通道数C来确定
其中k的公式为:
K = ψ ( C ) = o d d ( log 2 ( C ) γ + b γ ) K= \psi(C)=odd(\frac{ \log_2(C)}{\gamma}+\frac{b}{\gamma}) K=ψ(C)=odd(γlog2(C)+γb)
这里的odd表示最近的奇数
使用卷积的好处有两点:
-
避免降维
适当降维在一定程度上可以减缓信息冗余的情况(比如低维流形的研究),但是过度的降维会造成关键信息损失,从而导致精度降低
-
局部跨通道交互
每一个通道权重都由相邻的几个通道嵌入信息通过卷积操作得来
相似可见此
Gated Channel Transformation for Visual Recognition
来自CVPR2020的一篇论文,通过全局上下文嵌入、通道归一化、自适应门控三个部分来显式地建模通道之间的关系,促进其竞争或者合作。
详细解读见此
Global Second-Order Pooling Convolutional Networks
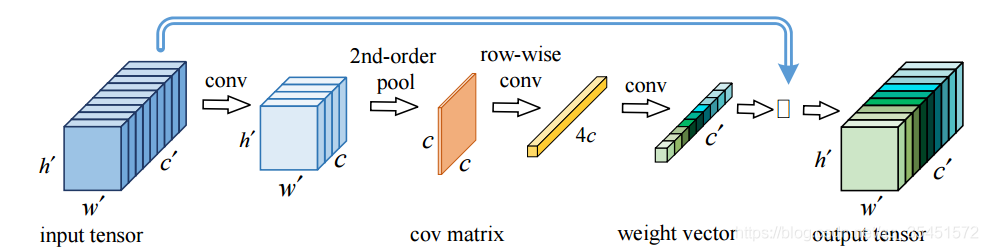
协方差矩阵:我们知道数据的标准差和方差可以描述数据的离散程度,但是这仅仅对于单个变量适用,对于多元变量,我们使用协方差矩阵,详细公式请自行百度或查阅书籍
GPoS Block主要分为一下几个部分:
- 对输入维度进行降维,以减小计算量
- 首先进行协方差矩阵计算
- 使用卷积和激活函数
- 逐行卷积进行放缩
- 降维得到最终的权重张量
Frequency Channel Attention Networks
来自CVPR2020,主要思想是DCT(离散余弦变换)(有点难,等我有时间看论文)
详细见此
自注意力
Non-Local
Non-Local旨在建立长距离依赖,著名的transformer可以看作Non-Local的一个实例;自Non-Local以后,越來越多的工作在长距离关系建模上做出贡献,具体可见此
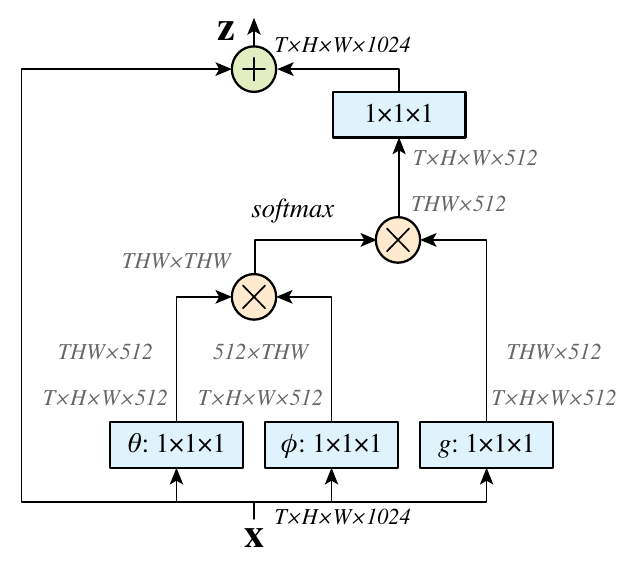
Global Context Networks
针对Non-Local的不足——其对于每一个位置学习不受位置关系依赖的注意力,这造成大量浪费;经过实验证明,Non-Local模块学习的的全局上下文信息在不同位置几乎是相同的,如下图:

因此,提出了简化版的Global Context Block
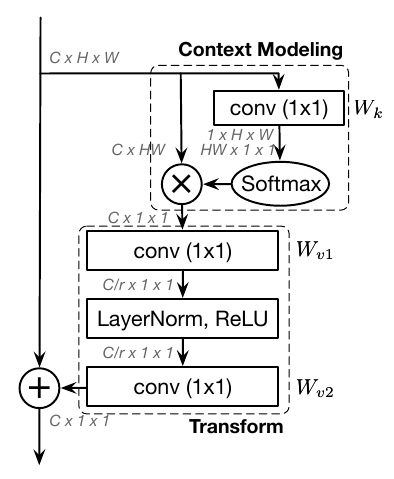
并且提出了一种Global Context Modeling Framework用于指导以后的工作,其示意图如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JTzmOLxc-1632536178448)(https://ml.akasaki.space/assets/img/image-20210713161721108.f07c4820.png)]
详细解读可见此
Disentangled Non-Local
本文认为像素之间除了存在成对(pair-wise)关系之外,其还具有一种一元(Unary)的显著信息,因此提出对Non-Local模块进行解耦,详细见此
Criss-Cross Attention
2018年的工作,提出使用连续的稀疏连接来代替密集连接,在保证极低计算复杂度的同时,实现了对全局上下文信息的聚合。具体见此
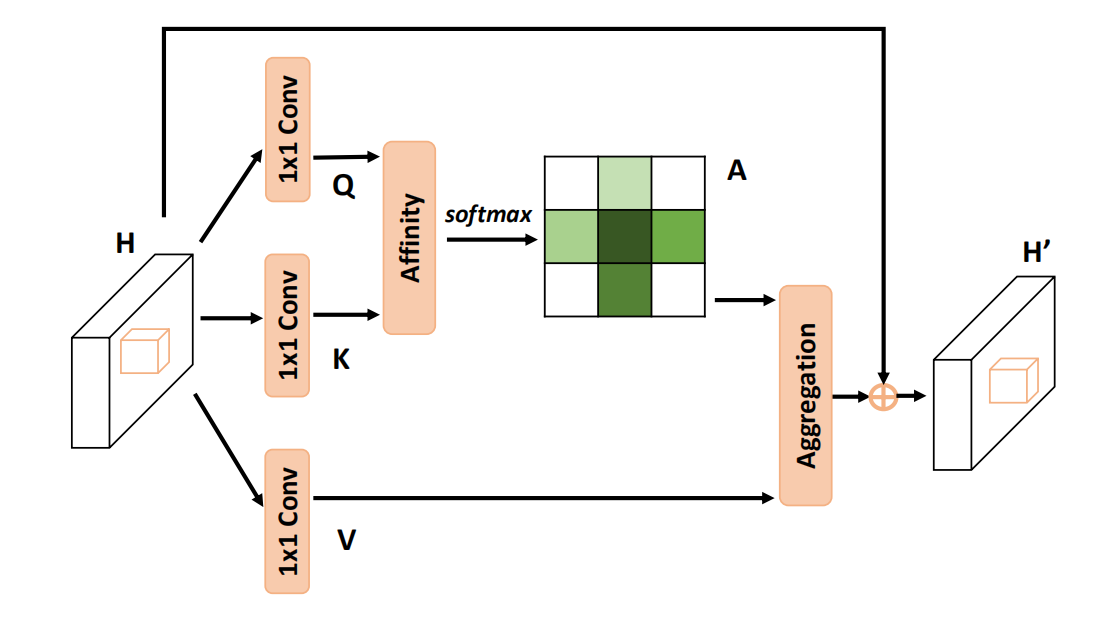
Polarized Self-Attention
极化自注意力针对语义分割等密集预测任务,探索了在保持高分辨率的同时,如何高效的进行自注意力的计算
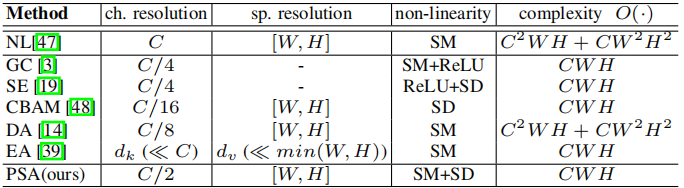
具体见此
OutLook Attention
VOLO
本文认为Transformer在中等数据集上表现差强人意的原因是因为其细粒度特征编码效率低下,不同于全局上的粗略关系建模,提出OutLook Attention,在像素领域上进行更加精细化的关系建模。
OutLooker的提出主要基于以下两点:
- 每个空间位置的特征都具有足够的代表性,可以生成聚集了局部邻近信息的注意力权重;
- 密集的局部空间聚合信息可以有效地编码精细层次的信息。
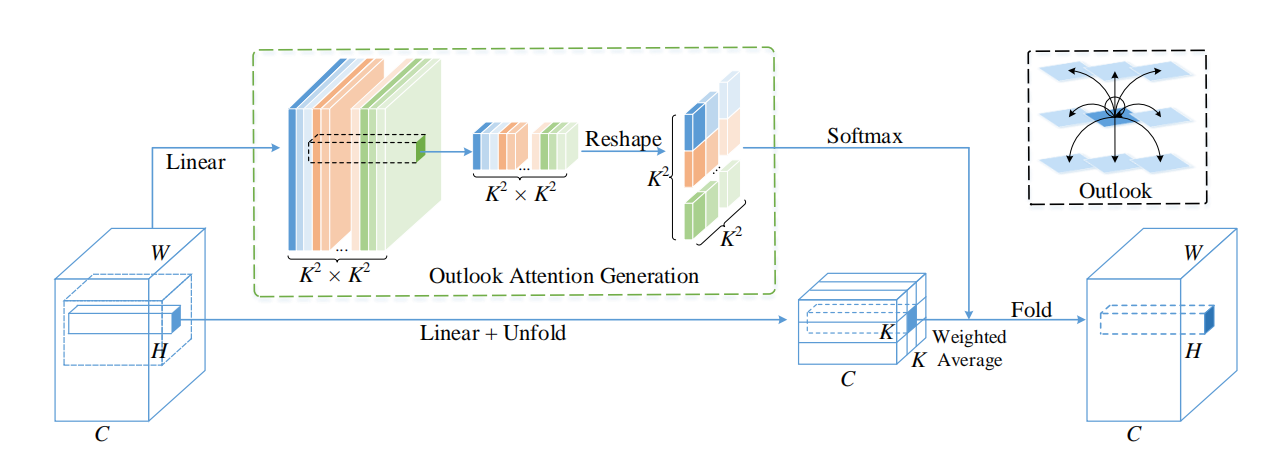
具体可见此
注意力结构
Bilateral Segmentation Network
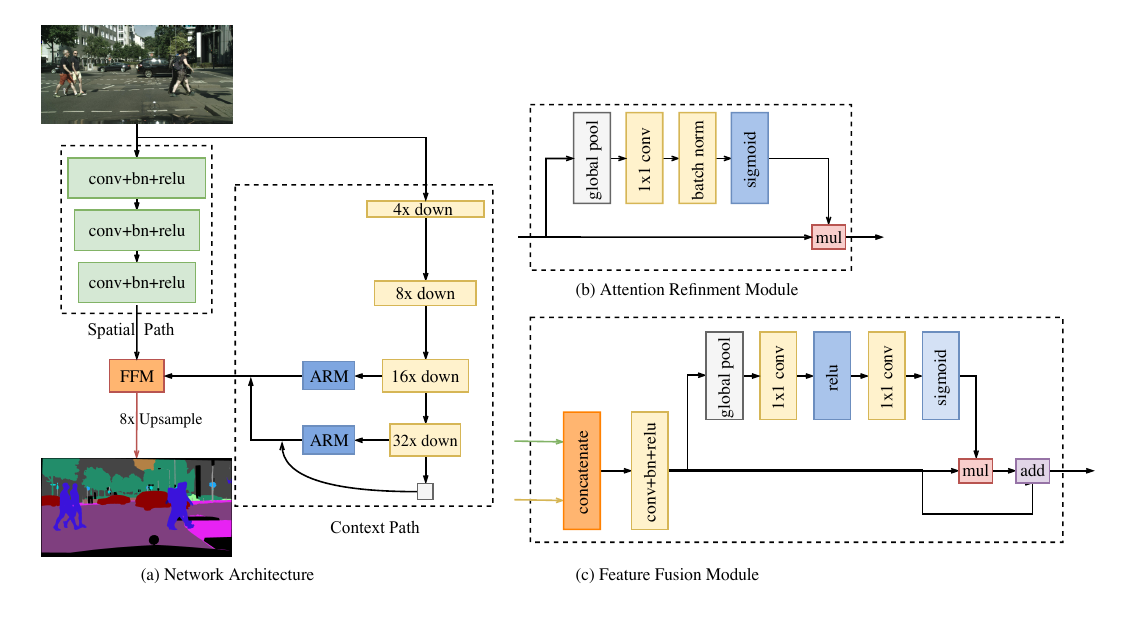
网络分为两个分支,Spatial Path只下采样到1/8保留大量的空间信息,Context Path进行快速下采样,实现对高级语义信息的编码,使用ARM提取语义信息,FFM模块融合语义信息与空间信息,从而达到快速语义分割。具体见此
Short-Term Dense Concatenate network
对BiseNet的改进,其认为Spatial Path非常耗时,因此将两个分支合二为一,并且使用了辅助训练模块来直到对空间信息的提取,从而实现了更加高效精准的快速语义分割。具体见此
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6Eelsqd1-1632536178455)(https://ml.akasaki.space/assets/img/image-20210719100139212.672ebcac.png)]
混合域(结合空间域与通道域)
Residual attentionnetwork for image classification
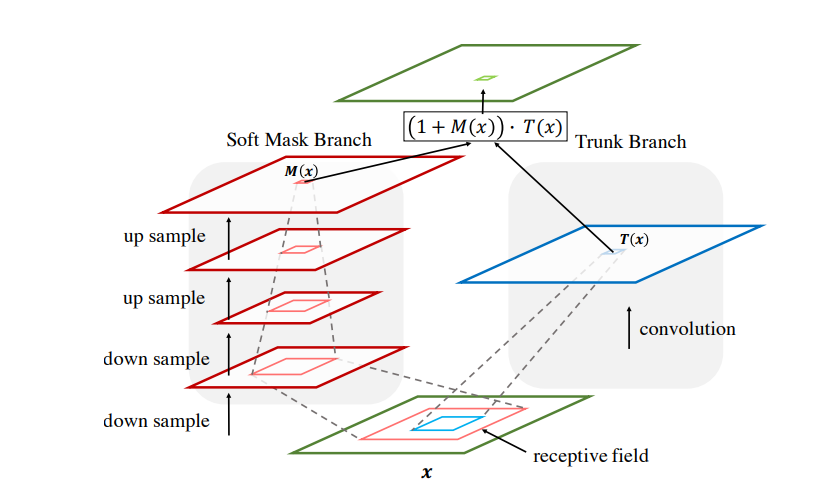
大意为在原来网络的基础上添加一个attention分支,并且进行残差连接。
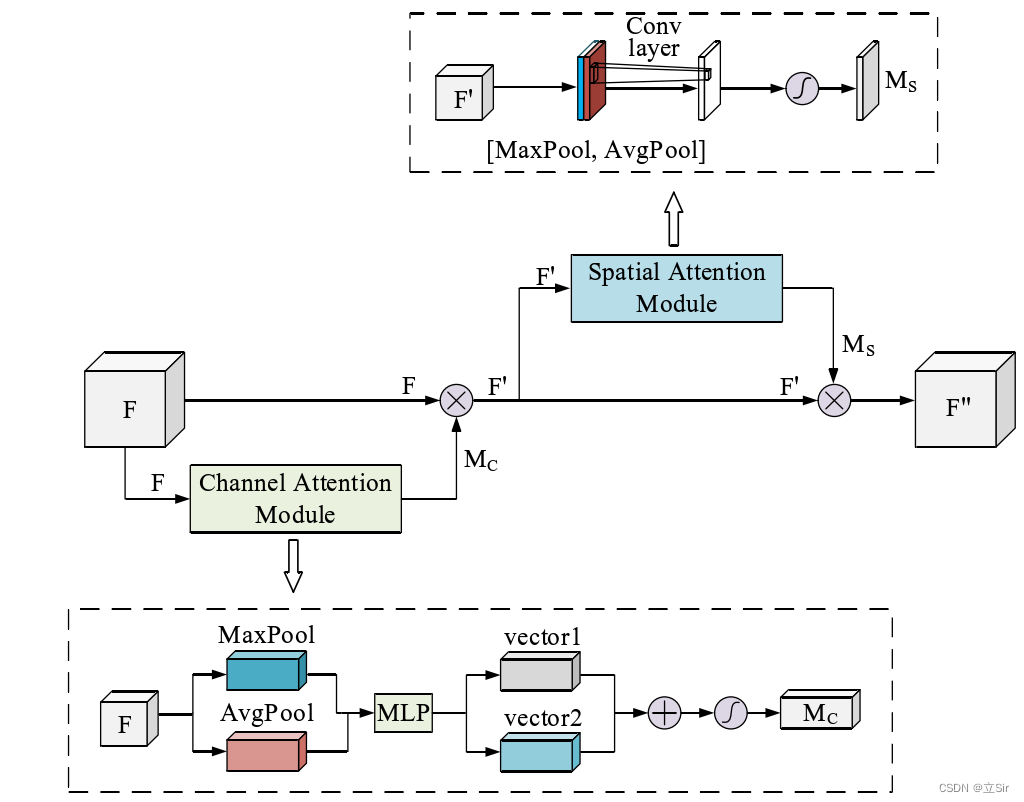
Convolutional Block Attention Module
CBAM是一种即插即用的、结合了空间(spatial)和通道(channel)的注意力机制模块。相比于SENet只关注通道(channel)的注意力机制可以取得更好的效果。
详细解读见此
SimAM
本文提出了一种简单有效的3D注意力模块,基于著名的神经科学理论,提出了一种能量函数,并且推导出其快速解析解,能够为每一个神经元分配权重。详细见此
时间域
对于时间