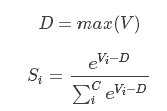学习《动手学习深度学习》注意力机制 之后,简单做个总结。
注意力提示
假设坐在一个物品很多的房间里,我们容易受到比较显眼的物品的吸引,进而将注意力倾注在那个物品上,这样我们就忽略了周围物品;换一种情形,如果你想读一本书,那么你进入房间将注意力放在书上,如果情况很急,甚至不论物品有多显眼,也无法博得你的注意力。
前者是一种非自主性注意力,后者是自主性注意力。在注意力的背景下,将自主性提示称为查询(query),给定任何查询,注意力机制通过注意力汇聚(attention pooling),将选择引导至感官输入(sensory inputs, 例如中间特征表示)。在注意力机制中,感官输入称为值(value)。每个值都和一个键(key)配对,可以想象为感官输入的非自主提示。如下图所示(图来自原文),我们通过设计注意力汇聚,将查询(自主性提示)和键(非自主性输入)结合在一起,实现对值(感官输入)的选择倾向。

注意力汇聚
非参数注意力汇聚
Nadaraya-Watson核回归:
f ( x ) = ∑ i = 1 n K ( x − x i ) ∑ j = 1 n K ( x − x i ) y i f(x)=\sum_{i=1}^n{\frac{K(x-x_i)}{\sum_{j=1}^n{K(x-x_i)}}y_i} f(x)=i=1∑n∑j=1nK(x−xi)K(x−xi)yi
其中,K是核。受到Nadaraya-Watson的启发,我们可以归纳出来一个更加通用的注意力汇聚公式:
f ( x ) = ∑ α ( x , x i ) y i f(x)=\sum{\alpha(x, x_i)y_i} f(x)=∑α(x,xi)yi
其中x是查询(自主性提示), ( x i , y i ) (x_i,y_i) (xi,yi)是键值对(非意志线索与感觉输入)。注意力汇聚是 y i y_i yi的加权平均,将查询 x和键 x i x_i xi之间的关系建模为注意力权重(attention weight) α ( x , x i ) \alpha(x,x_i) α(x,xi),这个权重将被分配给每一个对应值 y i y_i yi。对于任何查询,模型在所有键值对注意力权重都是一个有效的概率分布: 它们是非负的,并且总和为1。
如果我们将Nadaraya-Watson核回归中的核换成一个高斯核,其定义如下:
K ( u ) = 1 2 π exp ( − u 2 2 ) K(u)=\frac{1}{\sqrt{2 \pi}} \exp \left(-\frac{u^{2}}{2}\right) K(u)=2π1exp(−2u2)
将高斯核代入就可以得到如下公式:
f ( x ) = ∑ i = 1 n α ( x , x i ) y i = ∑ i = 1 n exp ( − 1 2 ( x − x i ) 2 ) ∑ j = 1 n exp ( − 1 2 ( x − x j ) 2 ) y i = ∑ i = 1 n softmax ( − 1 2 ( x − x i ) 2 ) y i \begin{aligned} f(x) &=\sum_{i=1}^{n} \alpha\left(x, x_{i}\right) y_{i} \\ &=\sum_{i=1}^{n} \frac{\exp \left(-\frac{1}{2}\left(x-x_{i}\right)^{2}\right)}{\sum_{j=1}^{n} \exp \left(-\frac{1}{2}\left(x-x_{j}\right)^{2}\right)} y_{i} \\ &=\sum_{i=1}^{n} \operatorname{softmax}\left(-\frac{1}{2}\left(x-x_{i}\right)^{2}\right) y_{i} \end{aligned} f(x)=i=1∑nα(x,xi)yi=i=1∑n∑j=1nexp(−21(x−xj)2)exp(−21(x−xi)2)yi=i=1∑nsoftmax(−21(x−xi)2)yi
在上式的结果中,我们会发现如果一个键 x i x_i xi的值越接近与给定的查询x,那么分配给这个键对应值 y i y_i yi的注意力权重就越大,也就获得越多的注意力。下面用一个示例来将上述概念串联起来:
# 目标函数
def f(x):return 2 * torch.sin(x) + x ** 0.8"""生成训练集"""
n_train = 50
# 使用随机数来生成x而不是直接0-5的数,可以得到随机度更高的样本
#
# 通过乘以5来控制样本区间的范围
x_train, _ = torch.sort(torch.rand(n_train) * 5)
# 噪声服从均值为0和标准差为0.5的正态分布。
y_train = f(x_train) + torch.normal(0.0, 0.5, (n_train,))"""生成测试集"""
x_test = torch.arange(0, 5, 0.1)
y_truth = f(x_test)
n_test = len(x_test)
上面代码生成了长度为n_train的训练集、长度为n_test的测试集,接下来,我们将x_test构造为查询(意志线索),将x_train作为为键(非意志线索),y_train作为值(感官输入),并将查询 x和键 x i x_i xi之间的关系建模为注意力权重:
# 每一行都包含相同的测试输入(相同的查询)
x_repeat = x_test.repeat_interleave(n_train).reshape((-1, n_train)) # (n_test, n_train)
# x_train 包含键,attention.shape=(n_test, n_train)
#
# 每一行都包含要在给定的每一个查询的值(y_train)之间的分配的注意力权重。
attension_weights = nn.functional.softmax(-(x_repeat - x_train)**2 / 2, dim=1)# y_hat的每个元素都是值的加权平均值,其中的权重是注意力权重
y_hat = torch.matmul(attention_weights, y_train)
plot_kernel_reg(y_hat)
为什么选择x_test作为查询(意志线索)呢?因为我们想要得到的是y_hat,输入是x_test,假设我们时刻都保持着有意识的状态,那么我们就根据自己的意志(x_test)结合环境的特征(x_train),处理接收到的感觉输入(y_train)最终找到自己想到的物品(y_hat)。可能会疑惑为什么y_truth不作为感觉输入?因为y_truth是用来衡量我们的输入x_test所得到的结果如何,也就是将其和y_hat进行比对的过程。
将上述矩阵操作过程使用图来表示如下:

那么在表达式中, s o f t m a x ( − 1 2 ( x − x i ) 2 ) softmax(-\frac{1}{2}(x-x_i)^2) softmax(−21(x−xi)2)体现在哪里呢? 我们在得到上图的两个矩阵之后,将两个矩阵相减,对于x_repeat矩阵,每一行中的元素都相等,不同行的元素不等,对应的是不同的 查询,而右边经过广播机制得到的矩阵中,每一列的元素相等的,不同行的元素表示不同的 键,两个矩阵相减之后就实现:给定一个查询 x x x,计算所有的键 x i x_i xi和查询之间的差距。

看上去有点像x_train对x_test进行加权得到attention_weights,但是实际上这也仅仅是矩阵运算,单从矩阵运算来看,将谁看作谁的加权都行,但是结合我们的实际问题背景来看,将x_test看作x_train的加权更加合理,因为我们将x_test作为意志线索,而x_train作为非意志线索。非意志线索-感官输入 对于我们的感官来讲都是时刻存在的,如果加上我们的意识的话可以帮助我们更好的从外界注意到我们想要获得的东西,所以理解为x_test对x_train进行加权更合理。当然这个加权操作之后得到的是attention_weights,这个矩阵又可以作为y_train的加权,最终可以得到y_hat。
那么这种非参数注意力汇聚的操作预测效果如何呢?上述代码的运行结果如下:

上面说到,如果一个键 x i x_i xi的值越接近于给定的查询x,那么分配给这个键对应值 y i y_i yi的注意力权重就越大,即注意力汇聚的注意力权重越大,也就获得越多的注意力,将attention_weights可视化得到如下结果,从结果上来看,矩阵的对角线权值更高,即键和查询相等的部分权值更高,表明所使用的方法达到了一定的效果:

**这个注意力权重满足每一行的所有值之和为1,**其实是代码内部将每一行的所有元素一起执行softmax函数运算的结果。
但是效果不是很好,是否和数据量有关呢?将数据量改成500和1000分别测试,得到的结果如下:
数据量为500:

数据量为1000:
发现拟合效果并没有很大的变化,说明与数据量无关。其实也好理解,如果仅仅增加数据量的话,变化的仅仅是权重矩阵的规模,而权重矩阵仅仅是由训练数据和测试数据的差值经过一层线性变换得到,其表达能力不够(欠拟合)。
参数注意力汇聚
和非参数注意力汇聚不同的是,我们在查询 x x x和键 x i x_i xi之间的距离乘以可学习参数 w w w就可以得到如下的公式:
f ( x ) = ∑ i = 1 n α ( x , x i ) y i = ∑ i = 1 n exp ( − 1 2 ( ( x − x i ) w ) 2 ) ∑ j = 1 n exp ( − 1 2 ( ( x − x j ) w ) 2 ) y i = ∑ i = 1 n softmax ( − 1 2 ( ( x − x i ) w ) 2 ) y i \begin{aligned} f(x) &=\sum_{i=1}^{n} \alpha\left(x, x_{i}\right) y_{i} \\ &=\sum_{i=1}^{n} \frac{\exp \left(-\frac{1}{2}(\left(x-x_{i})w\right)^{2}\right)}{\sum_{j=1}^{n} \exp \left(-\frac{1}{2}(\left(x-x_{j})w\right)^{2}\right)} y_{i} \\ &=\sum_{i=1}^{n} \operatorname{softmax}\left(-\frac{1}{2}(\left(x-x_{i})w\right)^{2}\right) y_{i} \end{aligned} f(x)=i=1∑nα(x,xi)yi=i=1∑n∑j=1nexp(−21((x−xj)w)2)exp(−21((x−xi)w)2)yi=i=1∑nsoftmax(−21((x−xi)w)2)yi
有了可学习参数,我们接下来的目标就是学习注意力汇聚的参数。
剩余的内容请移步原文查看~