原标题:协同过滤的python简易实现
了解推荐算法的人对协同过滤都不陌生,协同过滤就寻找和被推荐客户品味相似的客户,找出利用这些相似客户的偏好特征为用户推荐产品。下面就通过一个简单的示例将协同过滤加以实现。
关注我们公众号的粉丝都知道,在前几期的文章里,我们给大家介绍过推荐算法中的关联规则算法在实际项目中应用和实现,本期我们打算给大家介绍推荐算法中的协同过滤算法。协同过滤算法,在我们进行网购的时候比较常见。比如,最近想买一本书,比如是机器学习类,在亚马逊网络书店上搜索“机器学习”,会出现很多机器学习相关的书目,我们在进行筛选喜欢的图书的时候,往往通过网页左下角的“CustomerWho Bought This Item Also Bought”指引我找到了我的潜在需求,这个功能就是协同过滤算法的一个应用场景。
相信大家在网上购物、阅读、浏览视频时都会有类似的体验,这即是协同过滤推荐算法在起作用。该算法的好处是能起到意想不到的推荐效果, 经常能推荐出来一些惊喜结果。
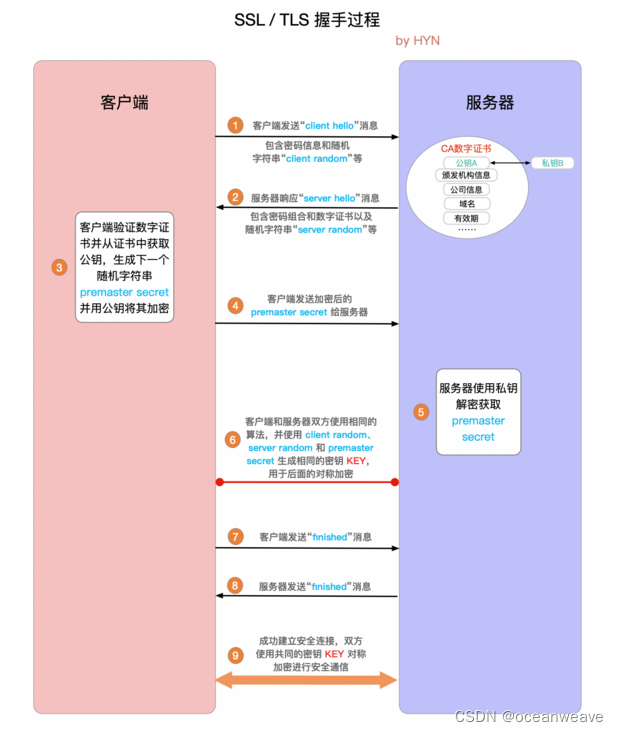
协同过滤算法简单的说先寻找和被推荐客户品味相似的客户,找出利用这些相似客户的偏好特征为用户推荐产品。协同过滤的基本流程如下图所示:

下面就通过一个简单的示例将协同过滤加以实现。这个例子是通过生成10个用户的喜欢的电影名称的清单,然后在这10个用户中,找出和被推荐客户相似的客群,计算该相似客群的电影偏好,进而为被推荐用户推荐电影。
STEP 1产生建模数据
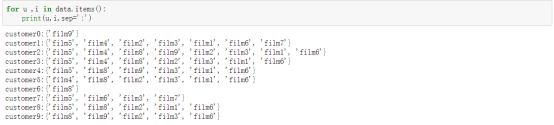
首先,随机产生了10个用户喜欢的每个用户喜欢的电影名称的集合。比如customer0 喜欢film9等。将字典打印出的结果如下:
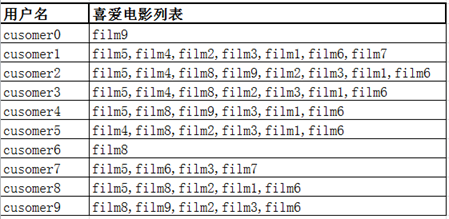
然后,将上面随机生成的用户的喜爱电影列表通过图表的形式进行展现,第一列为用户名称,第二列为每个客户喜欢电影的列表:
STEP 2设定被推荐用户以及喜欢的电影
接着,设定被推荐用户以及喜欢的电影,这里假设customer喜欢film1、film2、film3 。
STEP 3找出和被推荐用户的相似的用户
通过集合交集的方式寻找10个用户中和被推荐客户最相似的用户,也就是和customer一样同样喜欢film1、film2、film3的用户,然后存放在similar_user_list用户的列表中。结果如下,找出了customer1、customer2、 customer3、customer5这4个用户和customer最为相似。

STEP 4
按照这些相似用户喜好的电影清单为被推荐用户推荐电影,通过Counter统计推荐电影的频数,最后将推荐的电影存放在recommend列表中,并按照喜好电影出现的频次进行降序排列推荐。因此推荐的电影依次为film4、film6、film5、film8、film7、film9。

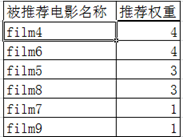
将上面的电影推荐结果通过数据表表格的形式进行展现,为customer推荐的film4的权重为4、film6的权重为4、film5的权重为3、film8的权重为3、film7的权重为1、film9的权重为1 。
以上几个步骤,实现了协同过滤的基本算法,但是还有一些可以进行改进的空间,比如增加用户对喜好电影的打分,这样可以更加准确的寻找相似用户以及给相似用户推荐电影,所以有兴趣的小伙伴可以继续改进和探索。
团队介绍:我们是毕马威旗下的专业数据挖掘团队,微信公众号(kpmgbigdata)每周末晚上推送一篇原创数据科学文章。我们的作品都由项目经验丰富的博士或资深顾问精心准备,分享结合实际业务的理论应用和心得体会。欢迎大家关注我们的微信公众号,关注原创数据挖掘精品文章;您也可以在公众号中直接发送想说的话,与我们联系交流。返回搜狐,查看更多
责任编辑: