学习基础知识
大多数机器学习工作流程都涉及处理数据、创建模型、优化模型参数和保存经过训练的模型。本教程向您介绍在 PyTorch 中实现的完整 ML 工作流,并提供链接以了解有关每个概念的更多信息。
我们将使用 Fashion MNIST 数据集来训练一个神经网络,该网络预测输入图像是否属于以下类别之一:T 恤/上衣、裤子、套头衫、连衣裙、外套、凉鞋、衬衫、运动鞋、包或脚踝开机。
Class 10 mnist 分类
本教程假定您基本熟悉 Python 和深度学习概念。
运行教程代码
您可以通过以下几种方式运行本教程:
- 在云端:这是最简单的入门方式!每个部分的顶部都有一个“在 Microsoft Learn 中运行”链接,该链接在 Microsoft Learn 中打开一个集成笔记本,其中包含完全托管环境中的代码。
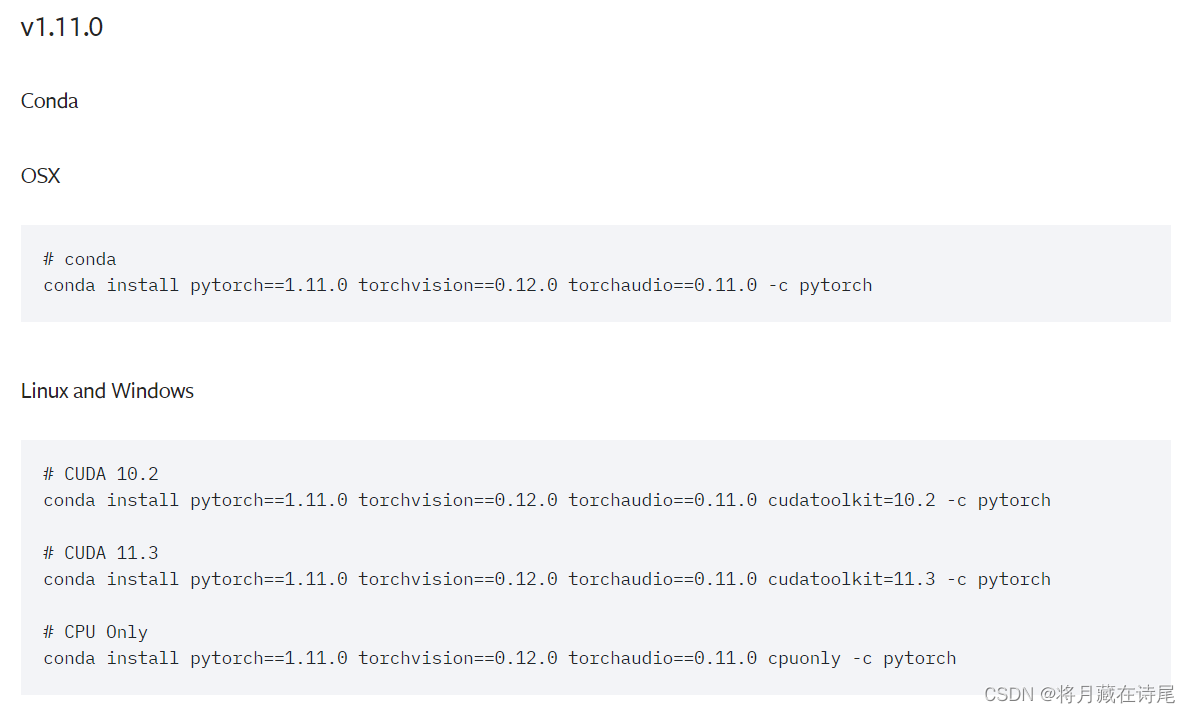
- 本地:此选项要求您首先在本地机器上设置 PyTorch 和 TorchVision(安装说明)。下载笔记本或将代码复制到您最喜欢的 IDE 中。
例子还是考虑用本地的方式
如何使用本指南
如果您熟悉其他深度学习框架,请先查看0. Quickstart,以快速熟悉 PyTorch 的 API。
如果您不熟悉深度学习框架,请直接进入我们分步指南的第一部分:1. 张量。
脚本总运行时间:(0分0.000秒)
快速开始
本节贯穿机器学习中常见任务的 API。请参阅每个部分中的链接以深入了解。
处理数据
PyTorch 有两个处理数据的原语: torch.utils.data.DataLoader和torch.utils.data.Dataset. Dataset存储样本及其对应的标签,并DataLoader在Dataset.
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensor
PyTorch 提供特定领域的库,例如TorchText、 TorchVision和TorchAudio,所有这些库都包含数据集。在本教程中,我们将使用 TorchVision 数据集。
该torchvision.datasets模块包含Dataset许多真实世界视觉数据的对象,如 CIFAR、COCO(此处为完整列表)。在本教程中,我们使用 FashionMNIST 数据集。每个 TorchVision 都Dataset包含两个参数:transform和 target_transform分别修改样本和标签。
# Download training data from open datasets.
training_data = datasets.FashionMNIST(root="data",train=True,download=True,transform=ToTensor(),
)# Download test data from open datasets.
test_data = datasets.FashionMNIST(root="data",train=False,download=True,transform=ToTensor(),
)
出去:
Downloading http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/train-images-idx3-ubyte.gz
Downloading http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/train-images-idx3-ubyte.gz to data/FashionMNIST/raw/train-images-idx3-ubyte.gz
Extracting data/FashionMNIST/raw/train-images-idx3-ubyte.gz to data/FashionMNIST/rawDownloading http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/train-labels-idx1-ubyte.gz
Downloading http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/train-labels-idx1-ubyte.gz to data/FashionMNIST/raw/train-labels-idx1-ubyte.gz
Extracting data/FashionMNIST/raw/train-labels-idx1-ubyte.gz to data/FashionMNIST/rawDownloading http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/t10k-images-idx3-ubyte.gz
Downloading http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/t10k-images-idx3-ubyte.gz to data/FashionMNIST/raw/t10k-images-idx3-ubyte.gz
Extracting data/FashionMNIST/raw/t10k-images-idx3-ubyte.gz to data/FashionMNIST/rawDownloading http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/t10k-labels-idx1-ubyte.gz
Downloading http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/t10k-labels-idx1-ubyte.gz to data/FashionMNIST/raw/t10k-labels-idx1-ubyte.gz
Extracting data/FashionMNIST/raw/t10k-labels-idx1-ubyte.gz to data/FashionMNIST/raw
我们将Dataset作为参数传递给DataLoader。这对我们的数据集进行了迭代,并支持自动批处理、采样、混洗和多进程数据加载。这里我们定义了一个64的batch size,即dataloader iterable中的每个元素都会返回一个batch 64个特征和标签。
batch_size = 64# Create data loaders.
train_dataloader = DataLoader(training_data, batch_size=batch_size)
test_dataloader = DataLoader(test_data, batch_size=batch_size)for X, y in test_dataloader:print(f"Shape of X [N, C, H, W]: {X.shape}")print(f"Shape of y: {y.shape} {y.dtype}")break
出去:
Shape of X [N, C, H, W]: torch.Size([64, 1, 28, 28])
Shape of y: torch.Size([64]) torch.int64 提示下载比较慢:国外网站
还是用国内的地址:清华镜像
python3 -m pip install --upgrade torch torchvision -i https://pypi.tuna.tsinghua.edu.cn/simple

python /Users/apple/PycharmProjects/flaskWeb/PyTorchSample.py
Downloading http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/train-images-idx3-ubyte.gz
Using downloaded and verified file: data/FashionMNIST/raw/train-images-idx3-ubyte.gz
Extracting data/FashionMNIST/raw/train-images-idx3-ubyte.gz to data/FashionMNIST/rawDownloading http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/train-labels-idx1-ubyte.gz
Using downloaded and verified file: data/FashionMNIST/raw/train-labels-idx1-ubyte.gz
Extracting data/FashionMNIST/raw/train-labels-idx1-ubyte.gz to data/FashionMNIST/rawDownloading http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/t10k-images-idx3-ubyte.gz
Downloading http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/t10k-images-idx3-ubyte.gz to data/FashionMNIST/raw/t10k-images-idx3-ubyte.gz
100.0%
Extracting data/FashionMNIST/raw/t10k-images-idx3-ubyte.gz to data/FashionMNIST/rawDownloading http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/t10k-labels-idx1-ubyte.gz
Downloading http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/t10k-labels-idx1-ubyte.gz to data/FashionMNIST/raw/t10k-labels-idx1-ubyte.gz
119.3%
Extracting data/FashionMNIST/raw/t10k-labels-idx1-ubyte.gz to data/FashionMNIST/rawShape of X [N, C, H, W]: torch.Size([64, 1, 28, 28])
Shape of y: torch.Size([64]) torch.int64
Using cpu device
NeuralNetwork((flatten): Flatten(start_dim=1, end_dim=-1)(linear_relu_stack): Sequential((0): Linear(in_features=784, out_features=512, bias=True)(1): ReLU()(2): Linear(in_features=512, out_features=512, bias=True)(3): ReLU()(4): Linear(in_features=512, out_features=10, bias=True))
)
Epoch 1
-------------------------------
loss: 2.308817 [ 0/60000]
loss: 2.298895 [ 6400/60000]
loss: 2.282714 [12800/60000]
loss: 2.272665 [19200/60000]
loss: 2.244191 [25600/60000]
loss: 2.228433 [32000/60000]
loss: 2.220300 [38400/60000]
loss: 2.193109 [44800/60000]
loss: 2.180864 [51200/60000]
loss: 2.153860 [57600/60000]
Test Error: Accuracy: 46.2%, Avg loss: 2.149433 Epoch 2
-------------------------------
loss: 2.157500 [ 0/60000]
loss: 2.154407 [ 6400/60000]
loss: 2.103146 [12800/60000]
loss: 2.118077 [19200/60000]
loss: 2.060432 [25600/60000]
loss: 2.008341 [32000/60000]
loss: 2.025860 [38400/60000]
loss: 1.949823 [44800/60000]
loss: 1.945079 [51200/60000]
loss: 1.882889 [57600/60000]
Test Error: Accuracy: 58.8%, Avg loss: 1.880382 Epoch 3
-------------------------------
loss: 1.910736 [ 0/60000]
loss: 1.890019 [ 6400/60000]
loss: 1.775693 [12800/60000]
loss: 1.812004 [19200/60000]
loss: 1.710484 [25600/60000]
loss: 1.661680 [32000/60000]
loss: 1.677290 [38400/60000]
loss: 1.576336 [44800/60000]
loss: 1.597025 [51200/60000]
loss: 1.496170 [57600/60000]
Test Error: Accuracy: 60.8%, Avg loss: 1.512554 Epoch 4
-------------------------------
loss: 1.578097 [ 0/60000]
loss: 1.551050 [ 6400/60000]
loss: 1.398014 [12800/60000]
loss: 1.469431 [19200/60000]
loss: 1.358654 [25600/60000]
loss: 1.352364 [32000/60000]
loss: 1.367244 [38400/60000]
loss: 1.287164 [44800/60000]
loss: 1.322717 [51200/60000]
loss: 1.223239 [57600/60000]
Test Error: Accuracy: 62.8%, Avg loss: 1.249063 Epoch 5
-------------------------------
loss: 1.323039 [ 0/60000]
loss: 1.313336 [ 6400/60000]
loss: 1.144988 [12800/60000]
loss: 1.248203 [19200/60000]
loss: 1.129645 [25600/60000]
loss: 1.156967 [32000/60000]
loss: 1.178468 [38400/60000]
loss: 1.111703 [44800/60000]
loss: 1.151673 [51200/60000]
loss: 1.064331 [57600/60000]
Test Error: Accuracy: 64.1%, Avg loss: 1.086445 Done!
Saved PyTorch Model State to model.pth
Predicted: "Ankle boot", Actual: "Ankle boot"Process finished with exit code 0
例子是全部正确的。即使跑的时候比较慢,注意是下载数据
全部代码
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensor# Download training data from open datasets.
training_data = datasets.FashionMNIST(root="data",train=True,download=True,transform=ToTensor(),
)# Download test data from open datasets.
test_data = datasets.FashionMNIST(root="data",train=False,download=True,transform=ToTensor(),
)batch_size = 64# Create data loaders.
train_dataloader = DataLoader(training_data, batch_size=batch_size)
test_dataloader = DataLoader(test_data, batch_size=batch_size)for X, y in test_dataloader:print(f"Shape of X [N, C, H, W]: {X.shape}")print(f"Shape of y: {y.shape} {y.dtype}")break# Get cpu or gpu device for training.
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"Using {device} device")# Define model
class NeuralNetwork(nn.Module):def __init__(self):super(NeuralNetwork, self).__init__()self.flatten = nn.Flatten()self.linear_relu_stack = nn.Sequential(nn.Linear(28*28, 512),nn.ReLU(),nn.Linear(512, 512),nn.ReLU(),nn.Linear(512, 10))def forward(self, x):x = self.flatten(x)logits = self.linear_relu_stack(x)return logitsmodel = NeuralNetwork().to(device)
print(model)loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=1e-3)def train(dataloader, model, loss_fn, optimizer):size = len(dataloader.dataset)model.train()for batch, (X, y) in enumerate(dataloader):X, y = X.to(device), y.to(device)# Compute prediction errorpred = model(X)loss = loss_fn(pred, y)# Backpropagationoptimizer.zero_grad()loss.backward()optimizer.step()if batch % 100 == 0:loss, current = loss.item(), batch * len(X)print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]")def test(dataloader, model, loss_fn):size = len(dataloader.dataset)num_batches = len(dataloader)model.eval()test_loss, correct = 0, 0with torch.no_grad():for X, y in dataloader:X, y = X.to(device), y.to(device)pred = model(X)test_loss += loss_fn(pred, y).item()correct += (pred.argmax(1) == y).type(torch.float).sum().item()test_loss /= num_batchescorrect /= sizeprint(f"Test Error: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")epochs = 5
for t in range(epochs):print(f"Epoch {t+1}\n-------------------------------")train(train_dataloader, model, loss_fn, optimizer)test(test_dataloader, model, loss_fn)
print("Done!")torch.save(model.state_dict(), "model.pth")
print("Saved PyTorch Model State to model.pth")model = NeuralNetwork()
model.load_state_dict(torch.load("model.pth"))classes = ["T-shirt/top","Trouser","Pullover","Dress","Coat","Sandal","Shirt","Sneaker","Bag","Ankle boot",
]model.eval()
x, y = test_data[0][0], test_data[0][1]
with torch.no_grad():pred = model(x)predicted, actual = classes[pred[0].argmax(0)], classes[y]print(f'Predicted: "{predicted}", Actual: "{actual}"')喜欢的同学可以自己编译一下
张量
张量是一种特殊的数据结构,与数组和矩阵非常相似。在 PyTorch 中,我们使用张量对模型的输入和输出以及模型的参数进行编码。
会引用
import numpy as np
张量类似于NumPy 的ndarray,除了张量可以在 GPU 或其他硬件加速器上运行。事实上,张量和 NumPy 数组通常可以共享相同的底层内存,从而无需复制数据。张量也针对自动微分进行了优化
初始化张量
张量可以以各种方式初始化。请看以下示例:
直接从数据
张量可以直接从数据中创建。数据类型是自动推断的。
data = [[1, 2],[3, 4],[5,6]]
x_data = torch.tensor(data) 来自 NumPy 数组
np_array = np.array(data)
x_np = torch.from_numpy(np_array)例子:
import torch
import numpy as np
data = [[1, 100],[3, 200], [5,300]]
x_data = torch.tensor(data)np_array = np.array(data)
x_np = torch.from_numpy(np_array)x_ones = torch.ones_like(x_data) # retains the properties of x_data
print(f"Ones Tensor: \n {x_ones} \n")x_rand = torch.rand_like(x_data, dtype=torch.float) # overrides the datatype of x_data
print(f"Random Tensor: \n {x_rand} \n")输出为
Ones Tensor: tensor([[1, 1],[1, 1],[1, 1]]) Random Tensor: tensor([[0.6287, 0.5308],[0.0132, 0.5593],[0.1074, 0.5575]]) 使用随机或恒定值:
shape是张量维度的元组。在下面的函数中,它决定了输出张量的维度。
shape = (3,3,)
rand_tensor = torch.rand(shape)
ones_tensor = torch.ones(shape)
zeros_tensor = torch.zeros(shape)print(f"Random Tensor: \n {rand_tensor} \n")
print(f"Ones Tensor: \n {ones_tensor} \n")
print(f"Zeros Tensor: \n {zeros_tensor}") Random Tensor: tensor([[0.2361, 0.5518, 0.3743],[0.5583, 0.8408, 0.0288],[0.2713, 0.4484, 0.1387]]) Ones Tensor: tensor([[1., 1., 1.],[1., 1., 1.],[1., 1., 1.]]) Zeros Tensor: tensor([[0., 0., 0.],[0., 0., 0.],[0., 0., 0.]])张量的属性
张量属性描述了它们的形状、数据类型和存储它们的设备。
tensor = torch.rand(3,4)print(f"Shape of tensor: {tensor.shape}")
print(f"Datatype of tensor: {tensor.dtype}")
print(f"Device tensor is stored on: {tensor.device}") Shape of tensor: torch.Size([3, 4])
Datatype of tensor: torch.float32
Device tensor is stored on: cpu张量运算
这里全面介绍了超过 100 种张量运算,包括算术、线性代数、矩阵操作(转置、索引、切片)、采样等。
这些操作中的每一个都可以在 GPU 上运行(通常以比 CPU 更高的速度)。如果您使用的是 Colab,请转到运行时 > 更改运行时类型 > GPU 来分配 GPU。
默认情况下,张量是在 CPU 上创建的。我们需要使用 .to方法明确地将张量移动到 GPU(在检查 GPU 可用性之后)。请记住,跨设备复制大张量在时间和内存方面可能会很昂贵!
# We move our tensor to the GPU if available
if torch.cuda.is_available():tensor = tensor.to("cuda")
尝试列表中的一些操作。如果您熟悉 NumPy API,您会发现 Tensor API 使用起来轻而易举。
标准的类似 numpy 的索引和切片:
tensor = torch.ones(4, 4)
print(f"First row: {tensor[0]}")
print(f"First column: {tensor[:, 0]}")
print(f"Last column: {tensor[..., -1]}")
tensor[:,1] = 0
print(tensor)
出去:
First row: tensor([1., 1., 1., 1.])
First column: tensor([1., 1., 1., 1.])
Last column: tensor([1., 1., 1., 1.])
tensor([[1., 0., 1., 1.],[1., 0., 1., 1.],[1., 0., 1., 1.],[1., 0., 1., 1.]])
连接张量您可以用来torch.cat沿给定维度连接一系列张量。另请参阅torch.stack,另一个与torch.cat.
t1 = torch.cat([tensor, tensor, tensor], dim=1)
print(t1)
出去:
tensor([[1., 0., 1., 1., 1., 0., 1., 1., 1., 0., 1., 1.],[1., 0., 1., 1., 1., 0., 1., 1., 1., 0., 1., 1.],[1., 0., 1., 1., 1., 0., 1., 1., 1., 0., 1., 1.],[1., 0., 1., 1., 1., 0., 1., 1., 1., 0., 1., 1.]])
算术运算
# This computes the matrix multiplication between two tensors. y1, y2, y3 will have the same value
y1 = tensor @ tensor.T
y2 = tensor.matmul(tensor.T)y3 = torch.rand_like(tensor)
torch.matmul(tensor, tensor.T, out=y3)# This computes the element-wise product. z1, z2, z3 will have the same value
z1 = tensor * tensor
z2 = tensor.mul(tensor)z3 = torch.rand_like(tensor)
torch.mul(tensor, tensor, out=z3)
单元素张量如果您有一个单元素张量,例如通过将张量的所有值聚合为一个值,您可以使用以下方法将其转换为 Python 数值item():
agg = tensor.sum()
agg_item = agg.item()
print(agg_item, type(agg_item))
出去:
12.0 <class 'float'>
就地操作 将结果存储到操作数中的操作称为就地操作。它们由_后缀表示。例如:x.copy_(y), x.t_(), 会变x。
print(f"{tensor} \n")
tensor.add_(5)
print(tensor)
出去:
tensor([[1., 0., 1., 1.],[1., 0., 1., 1.],[1., 0., 1., 1.],[1., 0., 1., 1.]])tensor([[6., 5., 6., 6.],[6., 5., 6., 6.],[6., 5., 6., 6.],[6., 5., 6., 6.]]) 与 NumPy 桥接
CPU 和 NumPy 数组上的张量可以共享它们的底层内存位置,改变一个会改变另一个。
张量到 NumPy 数组
t = torch.ones(5)
print(f"t: {t}")
n = t.numpy()
print(f"n: {n}")
出去:
t: tensor([1., 1., 1., 1., 1.])
n: [1. 1. 1. 1. 1.]
张量的变化反映在 NumPy 数组中。
t.add_(1)
print(f"t: {t}")
print(f"n: {n}")
出去:
t: tensor([2., 2., 2., 2., 2.])
n: [2. 2. 2. 2. 2.]
NumPy 数组到张量
n = np.ones(5)
t = torch.from_numpy(n)
NumPy 数组的变化反映在张量中。
np.add(n, 1, out=n)
print(f"t: {t}")
print(f"n: {n}")
出去:
t: tensor([2., 2., 2., 2., 2.], dtype=torch.float64)
n: [2. 2. 2. 2. 2.]
脚本总运行时间:(0分6.733秒)
数据集和数据加载器
处理数据样本的代码可能会变得混乱且难以维护;理想情况下,我们希望我们的数据集代码与我们的模型训练代码分离,以获得更好的可读性和模块化。PyTorch 提供了两个数据原语:torch.utils.data.DataLoader允许torch.utils.data.Dataset 您使用预加载的数据集以及您自己的数据。 Dataset存储样本及其对应的标签,并DataLoader在 周围包裹一个可迭代对象Dataset,以便轻松访问样本。
PyTorch 域库提供了许多预加载的数据集(例如 FashionMNIST),这些数据集子类torch.utils.data.Dataset化并实现了特定于特定数据的功能。它们可用于对您的模型进行原型设计和基准测试。你可以在这里找到它们:图像数据集、 文本数据集和 音频数据集
加载数据集
下面是如何从 TorchVision 加载Fashion-MNIST数据集的示例。Fashion-MNIST 是 Zalando 文章图像的数据集,由 60,000 个训练示例和 10,000 个测试示例组成。每个示例都包含 28×28 灰度图像和来自 10 个类别之一的相关标签。
我们使用以下参数加载FashionMNIST 数据集:
root是存储训练/测试数据的路径,train指定训练或测试数据集,download=True如果数据不可用,则从 Internet 下载数据root。transform并target_transform指定特征和标签转换
import torch
from torch.utils.data import Dataset
from torchvision import datasets
from torchvision.transforms import ToTensor
import matplotlib.pyplot as plttraining_data = datasets.FashionMNIST(root="data",train=True,download=True,transform=ToTensor()
)test_data = datasets.FashionMNIST(root="data",train=False,download=True,transform=ToTensor()
)
出去:
Downloading http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/train-images-idx3-ubyte.gz
Downloading http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/train-images-idx3-ubyte.gz to data/FashionMNIST/raw/train-images-idx3-ubyte.gz
Extracting data/FashionMNIST/raw/train-images-idx3-ubyte.gz to data/FashionMNIST/rawDownloading http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/train-labels-idx1-ubyte.gz
Downloading http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/train-labels-idx1-ubyte.gz to data/FashionMNIST/raw/train-labels-idx1-ubyte.gz
Extracting data/FashionMNIST/raw/train-labels-idx1-ubyte.gz to data/FashionMNIST/rawDownloading http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/t10k-images-idx3-ubyte.gz
Downloading http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/t10k-images-idx3-ubyte.gz to data/FashionMNIST/raw/t10k-images-idx3-ubyte.gz
Extracting data/FashionMNIST/raw/t10k-images-idx3-ubyte.gz to data/FashionMNIST/rawDownloading http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/t10k-labels-idx1-ubyte.gz
Downloading http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/t10k-labels-idx1-ubyte.gz to data/FashionMNIST/raw/t10k-labels-idx1-ubyte.gz
Extracting data/FashionMNIST/raw/t10k-labels-idx1-ubyte.gz to data/FashionMNIST/raw
迭代和可视化数据集
我们可以Datasets像列表一样手动索引:training_data[index]. 我们matplotlib用来可视化训练数据中的一些样本。
labels_map = {0: "T-Shirt",1: "Trouser",2: "Pullover",3: "Dress",4: "Coat",5: "Sandal",6: "Shirt",7: "Sneaker",8: "Bag",9: "Ankle Boot",
}
figure = plt.figure(figsize=(8, 8))
cols, rows = 3, 3
for i in range(1, cols * rows + 1):sample_idx = torch.randint(len(training_data), size=(1,)).item()img, label = training_data[sample_idx]figure.add_subplot(rows, cols, i)plt.title(labels_map[label])plt.axis("off")plt.imshow(img.squeeze(), cmap="gray")
plt.show()

为您的文件创建自定义数据集
自定义 Dataset 类必须实现三个函数:__init__、__len__和__getitem__。看看这个实现;FashionMNIST 图像存储在一个目录img_dir中,它们的标签分别存储在一个 CSV 文件annotations_file中。
在接下来的部分中,我们将分解每个函数中发生的事情。
import os
import pandas as pd
from torchvision.io import read_imageclass CustomImageDataset(Dataset):def __init__(self, annotations_file, img_dir, transform=None, target_transform=None):self.img_labels = pd.read_csv(annotations_file)self.img_dir = img_dirself.transform = transformself.target_transform = target_transformdef __len__(self):return len(self.img_labels)def __getitem__(self, idx):img_path = os.path.join(self.img_dir, self.img_labels.iloc[idx, 0])image = read_image(img_path)label = self.img_labels.iloc[idx, 1]if self.transform:image = self.transform(image)if self.target_transform:label = self.target_transform(label)return image, label
__在里面__
__init__ 函数在实例化 Dataset 对象时运行一次。我们初始化包含图像、注释文件和两种转换的目录(在下一节中更详细地介绍)。
labels.csv 文件如下所示:
tshirt1.jpg, 0
tshirt2.jpg, 0
......
ankleboot999.jpg, 9
def __init__(self, annotations_file, img_dir, transform=None, target_transform=None):self.img_labels = pd.read_csv(annotations_file)self.img_dir = img_dirself.transform = transformself.target_transform = target_transform
__len__
__len__ 函数返回我们数据集中的样本数。
例子:
def __len__(self):return len(self.img_labels)
__getitem__
__getitem__ 函数从给定索引处的数据集中加载并返回一个样本idx。基于索引,它识别图像在磁盘上的位置,使用 将其转换为张量read_image,从 csv 数据中检索相应的标签self.img_labels,调用它们的变换函数(如果适用),并返回张量图像和相应的标签一个元组。
def __getitem__(self, idx):img_path = os.path.join(self.img_dir, self.img_labels.iloc[idx, 0])image = read_image(img_path)label = self.img_labels.iloc[idx, 1]if self.transform:image = self.transform(image)if self.target_transform:label = self.target_transform(label)return image, label
使用 DataLoaders 为训练准备数据
检索我们数据集的Dataset特征并一次标记一个样本。在训练模型时,我们通常希望以“小批量”的形式传递样本,在每个 epoch 重新洗牌以减少模型过拟合,并使用 Python multiprocessing加速数据检索。
DataLoader是一个可迭代的,它在一个简单的 API 中为我们抽象了这种复杂性。
from torch.utils.data import DataLoadertrain_dataloader = DataLoader(training_data, batch_size=64, shuffle=True)
test_dataloader = DataLoader(test_data, batch_size=64, shuffle=True)
遍历 DataLoader
我们已将该数据集加载到 中,DataLoader并且可以根据需要遍历数据集。下面的每次迭代都会返回一批train_features和train_labels(分别包含batch_size=64特征和标签)。因为我们指定shuffle=True了 ,所以在我们遍历所有批次之后,数据被打乱(为了更细粒度地控制数据加载顺序,请查看Samplers)。
# Display image and label.
train_features, train_labels = next(iter(train_dataloader))
print(f"Feature batch shape: {train_features.size()}")
print(f"Labels batch shape: {train_labels.size()}")
img = train_features[0].squeeze()
label = train_labels[0]
plt.imshow(img, cmap="gray")
plt.show()
print(f"Label: {label}")
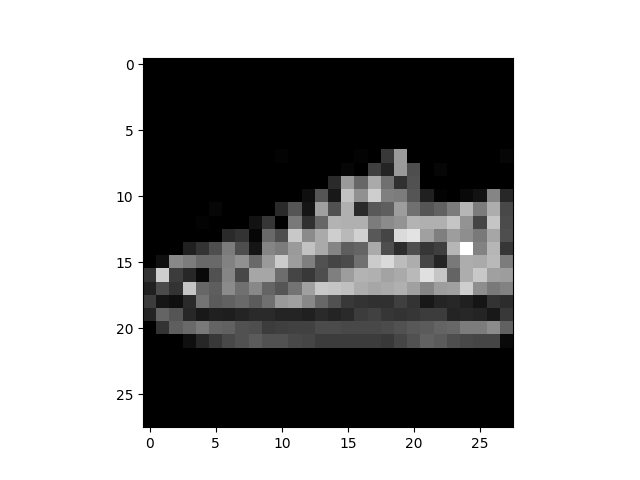
出去:
Feature batch shape: torch.Size([64, 1, 28, 28])
Labels batch shape: torch.Size([64])
Label: 7 CSDN![]() https://mp.csdn.net/mp_blog/creation/editor/106231608还可以看看我的其他链接
https://mp.csdn.net/mp_blog/creation/editor/106231608还可以看看我的其他链接
torch 安装
pip install torch
Installing collected packages: torch
Successfully installed torch-1.11.0
建立张量
import torcht = torch.Tensor([1, 2, 3])
print(t)tensor([1., 2., 3.])
tensor与ndarray的关系
t1 = np.array(torch.Tensor([[1, 2, 3],[1, 2, 3]]))
t2 = torch.Tensor(np.array([[1, 2, 3],[1, 2, 3]]))
print(t1)
print(t2)[[1. 2. 3.][1. 2. 3.]]
tensor([[1., 2., 3.],[1., 2., 3.]])还要查看type ,打印类型
t1 <class 'numpy.ndarray'>
[[1. 2. 3.][1. 2. 3.]]
t2 <class 'torch.Tensor'>
tensor([[1., 2., 3.],[1., 2., 3.]])torch 分别设置为空,0和1的张量
t3 = torch.empty(3, 4)
print("t3: ", t3)t3 = torch.ones(3, 4)
print("t3: ", t3)t3 = torch.zeros(3, 4)
print("t3: ",t3)可以看出来empty实际上不是0的值,而是内存的随机数据
t3: tensor([[ 1.4013e-45, 2.1250e+00, 1.2556e-29, 1.4013e-45],[-9.3015e-10, -2.0005e+00, -9.3012e-10, 2.5250e-29],[ 5.6052e-45, -0.0000e+00, -9.3008e-10, 3.6902e+19]])
t3: tensor([[1., 1., 1., 1.],[1., 1., 1., 1.],[1., 1., 1., 1.]])
t3: tensor([[0., 0., 0., 0.],[0., 0., 0., 0.],[0., 0., 0., 0.]])还可以看:
CSDN![]() https://mp.csdn.net/mp_blog/creation/editor/105785106
https://mp.csdn.net/mp_blog/creation/editor/105785106