HashMap超详细探讨
- 总述
- 从集合出发探讨HashMap
- Collection接口继承树
- Map接口继承树
- 从Map接口来,一步一步深入其中
- Map接口概述
- Map接口:常用方法
- Map接口
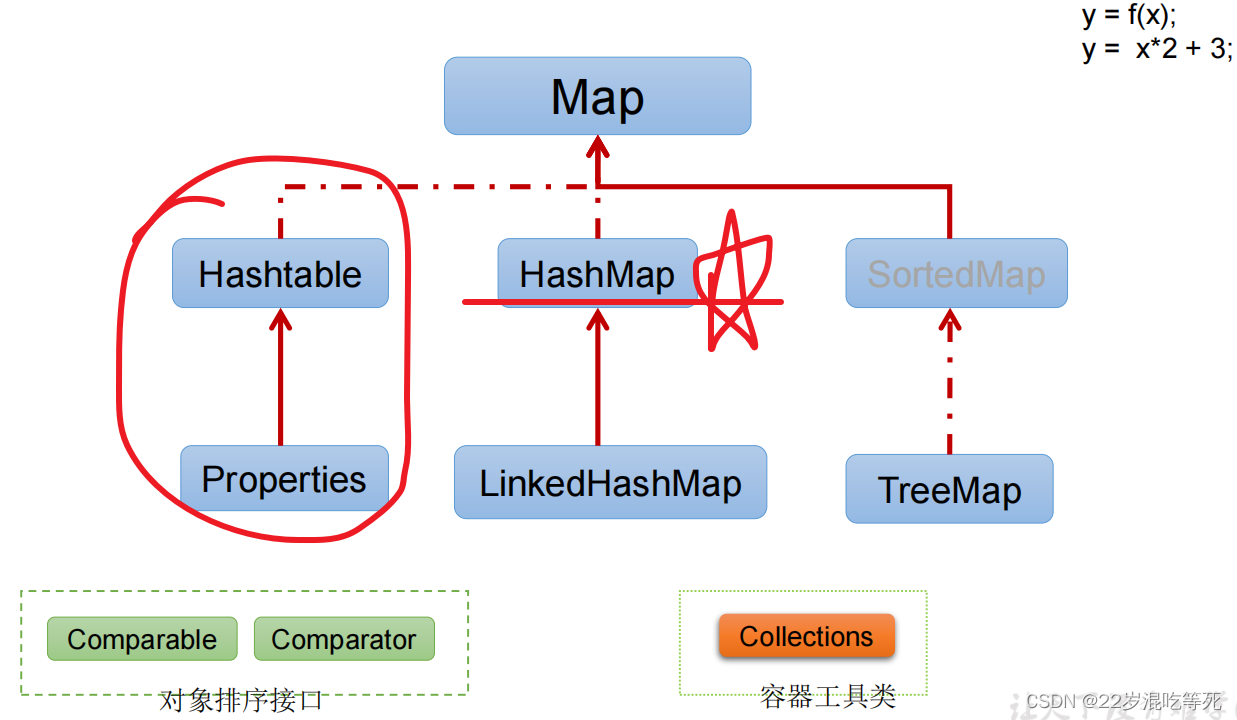
- Map实现类之一:HashMap
- HashMap的存储结构
- HashMap源码中的重要常量
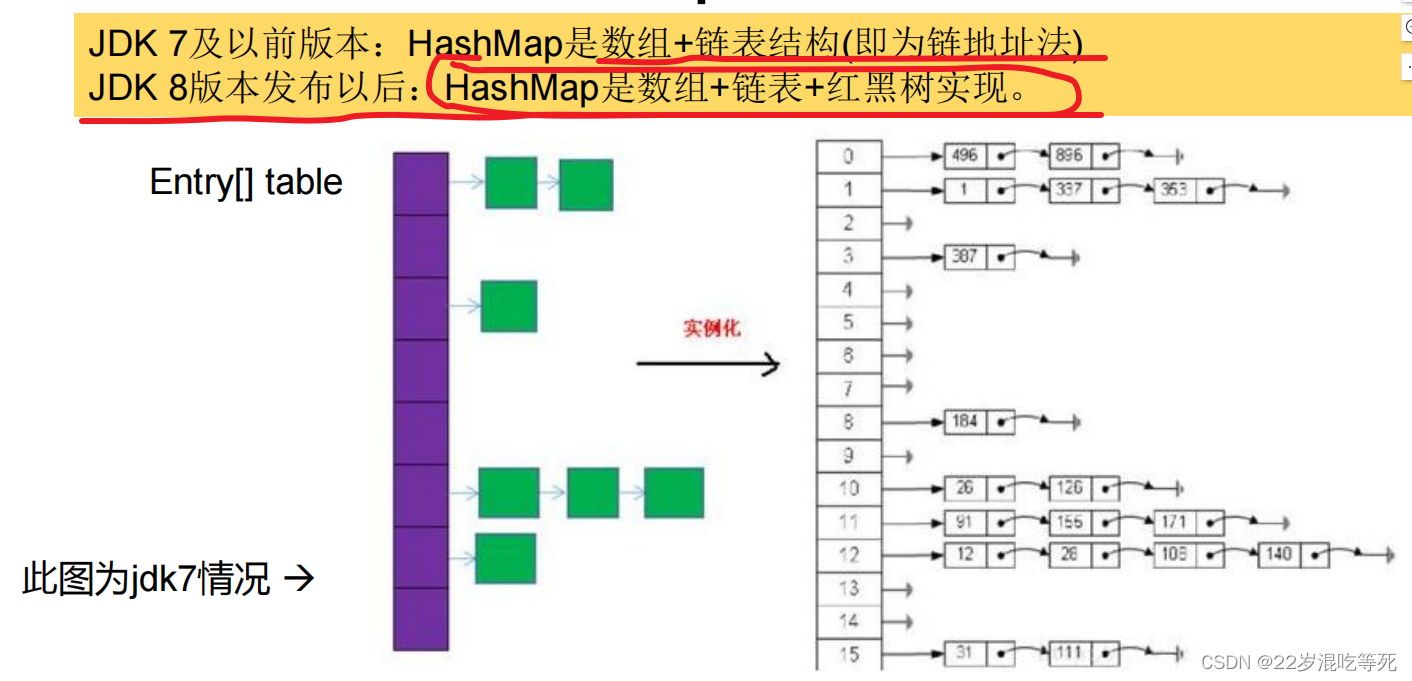
- JDK 1.8之前
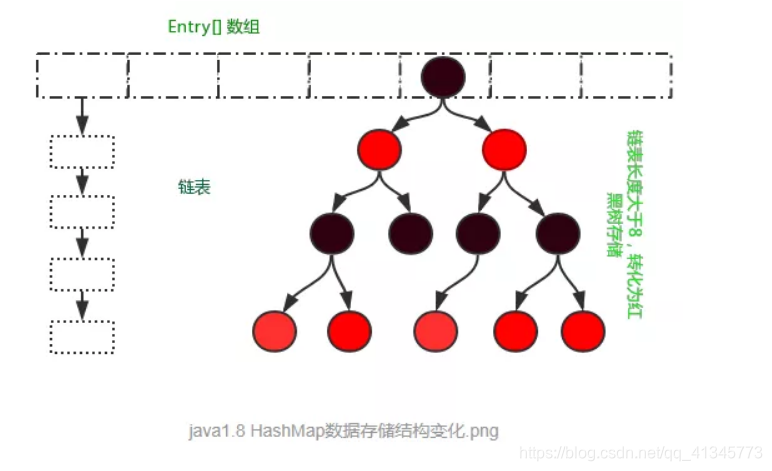
- JDK 1.8
- 总结:JDK1.8相较于之前的变化:
- 面试题:
- 深入分析 HashMap
- 一、传统 HashMap 的缺点
- 二、JDK1.8 中 HashMap 的数据结构
- 2.2HashMap 中关于红黑树的三个关键参数
- 2.3HashMap 在 JDK 1.8 中新增的操作:桶的树形化 treeifyBin()
- 三、分析 HashMap 的 put 方法
- 3.1HashMap 的 put 方法执行过程可以通过下图来理解,自己有兴趣可以去对比源码更清楚地研究学习。
- JDK1.8HashMap 的 put 方法源码
- HashMap源码
总述
阅读下面内容,可以帮助读者,快速了解HashMap的最为核心的知识。
HashMap是Java集合框架中的一种实现类,它提供了一种将键映射到值的数据结构。
HashMap继承自AbstractMap类,实现了Map接口,可以存储键值对,并且允许通过键来查找值,具有高效的查找和插入操作。
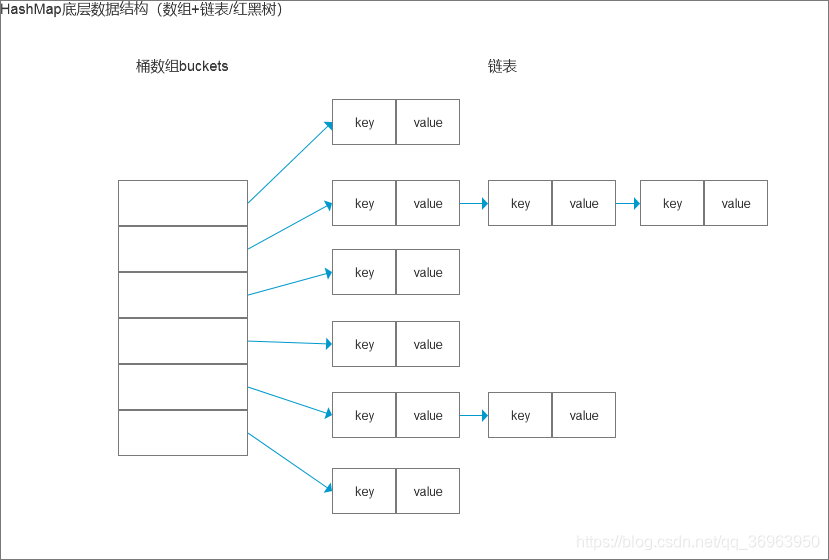
HashMap的实现是基于哈希表的,它通过哈希函数计算每个键的哈希码,并根据哈希码存储在哈希表的相应位置上。HashMap使用链表来解决哈希冲突,如果多个键映射到同一个位置,就会将它们放在同一个链表中。
下面是一些HashMap的详细信息:
- 构造函数:HashMap有多个构造函数,其中最常用的是不带参数的构造函数,它创建一个初始容量为16,负载因子为0.75的空HashMap。另外还有带初始容量和负载因子参数的构造函数。
- 负载因子:负载因子是指哈希表中的实际元素数量与哈希表容量的比率。当哈希表中的元素数量达到负载因子乘以容量时,哈希表会自动扩容。默认情况下,负载因子为0.75,这是一个经验值,可以在时间和空间之间进行权衡。
- 扩容:当哈希表中的元素数量达到负载因子乘以容量时,哈希表会自动扩容。扩容后,哈希表的容量将变为原来的两倍,并且所有的键值对将重新散列到新的位置上。
- put方法:put方法用于向HashMap中添加键值对,它接收两个参数,一个是键,一个是值。首先,它会计算键的哈希码,并根据哈希码找到键在哈希表中的位置。如果该位置已经有元素,那么就遍历链表,如果找到了相同的键,就用新的值替换旧的值。否则,就在链表的末尾添加一个新的节点。如果该位置没有元素,就创建一个新的节点,并将其放在该位置。
- get方法:get方法用于获取指定键的值,它接收一个参数,即要查找的键。首先,它会计算键的哈希码,并根据哈希码找到键在哈希表中的位置。然后,它遍历链表,找到与该键相同的节点,并返回节点的值。如果没有找到该键,就返回null。
- 遍历:HashMap提供了多种遍历方式,最常用的是使用迭代器遍历。可以通过keySet()、values()、entrySet()方法获得一个Set视图,然后通过该Set视图的迭代器进行遍历。例如,可以通过以下方式遍历HashMap中的所有键值对:
HashMap<String, Integer> map = new HashMap<>();
// 添加键值对
map.put("apple", 1);
map.put("banana", 2);
map.put("orange", 3);// 获取keySet()视图并遍历
Set<String> keys = map.keySet();
for (String key : keys) {System.out.println(key + " : " + map.get(key));
}// 获取entrySet()视图并遍历
Set<Map.Entry<String, Integer>> entries = map.entrySet();for (Map.Entry<String, Integer> entry : entries) {System.out.println(entry.getKey() + " : " + entry.getValue());
}- 并发:HashMap是非线程安全的,如果多个线程同时访问同一个HashMap实例,可能会导致数据不一致的问题。可以使用ConcurrentHashMap来解决这个问题,它是一个线程安全的HashMap实现。
- 避免哈希冲突:为了避免哈希冲突,可以在键对象的hashCode()方法中返回一个具有良好分布性的哈希码。另外,还可以在键对象的equals()方法中实现正确的相等比较,确保只有相同的键对象才会映射到同一个位置。
总的来说,HashMap是一个非常常用的集合类,它提供了高效的键值对存储和查找功能。但是需要注意的是,由于哈希表的实现,哈希冲突可能会影响HashMap的性能,因此需要注意键对象的哈希码计算和相等比较的实现。同时,在多线程环境下使用HashMap需要注意线程安全问题。
下面开始进入详细的探讨
从集合出发探讨HashMap

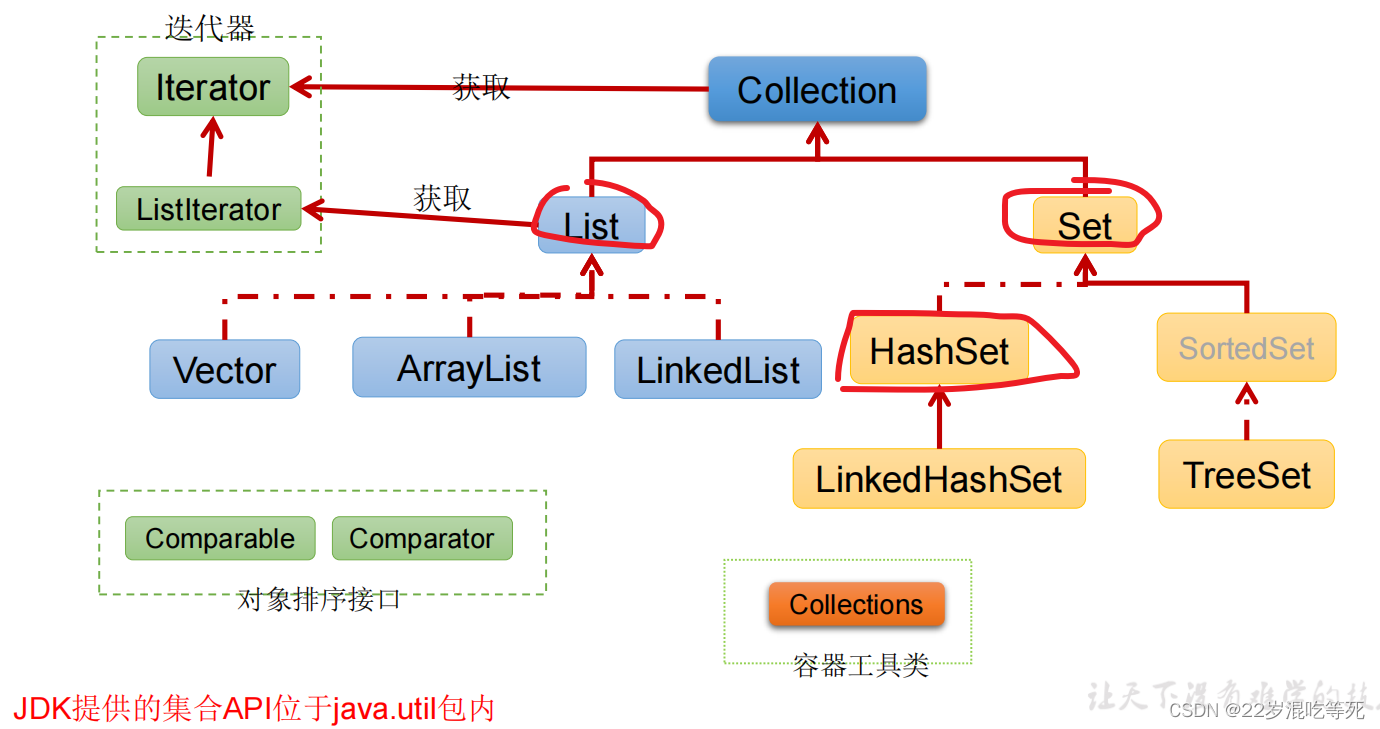
Collection接口继承树
Map接口继承树
从Map接口来,一步一步深入其中

Map接口概述

Map接口:常用方法
添加、删除、修改操作:
Object put(Object key,Object value):将指定key-value添加到(或修改)当前map对象中
void putAll(Map m):将m中的所有key-value对存放到当前map中
Object remove(Object key):移除指定key的key-value对,并返回value
void clear():清空当前map中的所有数据 元素查询的操作:
Object get(Object key):获取指定key对应的value
boolean containsKey(Object key):是否包含指定的key
boolean containsValue(Object value):是否包含指定的value
int size():返回map中key-value对的个数
boolean isEmpty():判断当前map是否为空
boolean equals(Object obj):判断当前map和参数对象obj是否相等 元视图操作的方法:
Set keySet():返回所有key构成的Set集合
Collection values():返回所有value构成的Collection集合
Set entrySet():返回所有key-value对构成的Set集合Map接口
Map map = new HashMap();
//map.put(..,..)省略
System.out.println("map的所有key:");
Set keys = map.keySet();// HashSet
for (Object key : keys) {System.out.println(key + "->" + map.get(key));
}System.out.println("map的所有的value:");
Collection values = map.values();
Iterator iter = values.iterator();
while (iter.hasNext()) {System.out.println(iter.next());
}System.out.println("map所有的映射关系:");
// 映射关系的类型是Map.Entry类型,它是Map接口的内部接口
Set mappings = map.entrySet();
for (Object mapping : mappings) {Map.Entry entry = (Map.Entry) mapping;System.out.println("key是:" + entry.getKey() + ",value是:" + entry.getValue());
}
Map实现类之一:HashMap

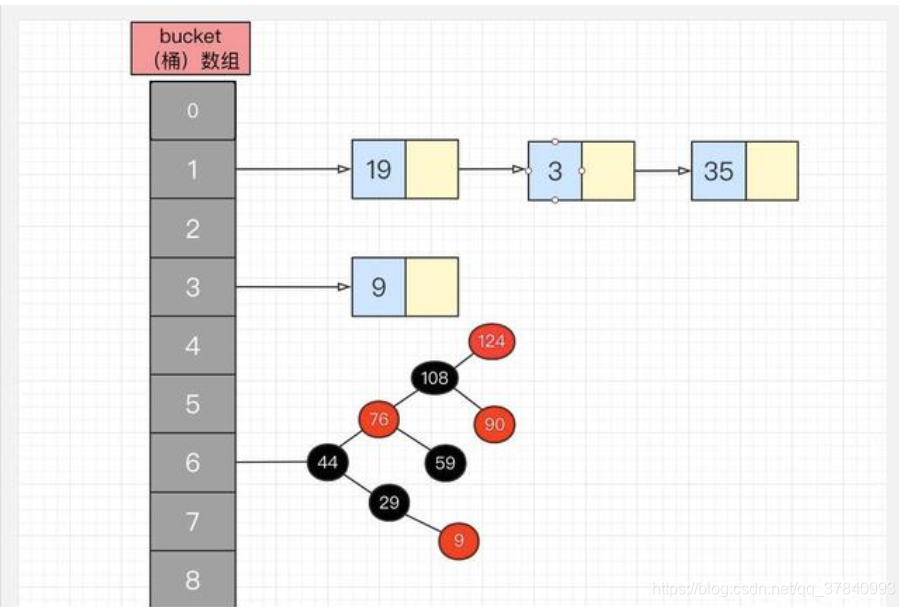
HashMap的存储结构
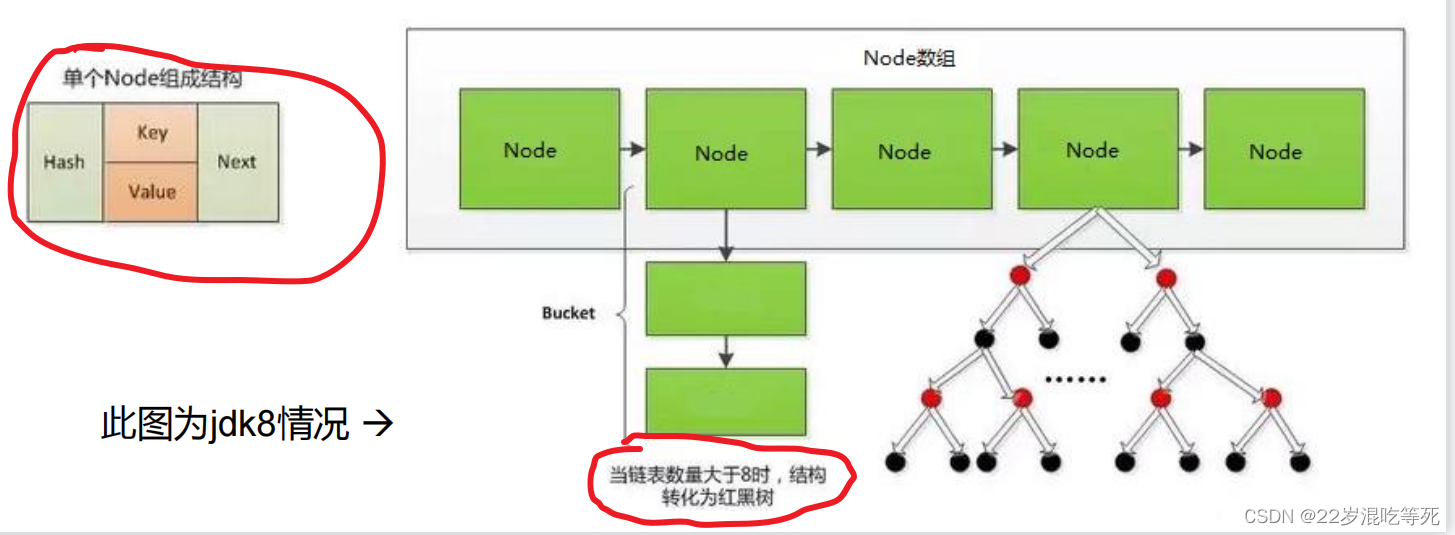
HashMap源码中的重要常量

JDK 1.8之前


JDK 1.8



总结:JDK1.8相较于之前的变化:
1. HashMap map = new HashMap();//默认情况下,先不创建长度为16的数组
2. 当首次调用map.put()时,再创建长度为16的数组
3. 数组为Node类型,在jdk7中称为Entry类型
4. 形成链表结构时,新添加的key-value对在链表的尾部(七上八下)
5. 当数组指定索引位置的链表长度>8时,且map中的数组的长度> 64时,此索引位置
上的所有key-value对使用红黑树进行存储
面试题:

put(Object key,Object value):将指定key-value添加到(或修改)当前map对象中。
Object get(Object key):获取指定key对应的value
---------------------------------------------------------------------------------------------------------------------
当HashMap中的元素个数超过数组大小(数组总大小length,不是数组中个数size)loadFactor 时 , 就会进行数组扩容 , loadFactor 的默认值(DEFAULT_LOAD_FACTOR)为0.75,这是一个折中的取值。
也就是说,默认情况下,数组大小(DEFAULT_INITIAL_CAPACITY)为16,那么当HashMap中元素个数超过160.75=12(这个值就是代码中的threshold值,也叫做临界值)的时候,
就把数组的大小扩展为 2*16=32,即扩大一倍,然后重新计算每个元素在数组中的位置,

深入分析 HashMap
一、传统 HashMap 的缺点

二、JDK1.8 中 HashMap 的数据结构
2.1HashMap 是数组+链表+红黑树(JDK1.8 增加了红黑树部分)实现的

新增红黑树
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {TreeNode<K,V> parent; // red-black tree linksTreeNode<K,V> left;TreeNode<K,V> right;TreeNode<K,V> prev; // needed to unlink next upon deletionboolean red;
}
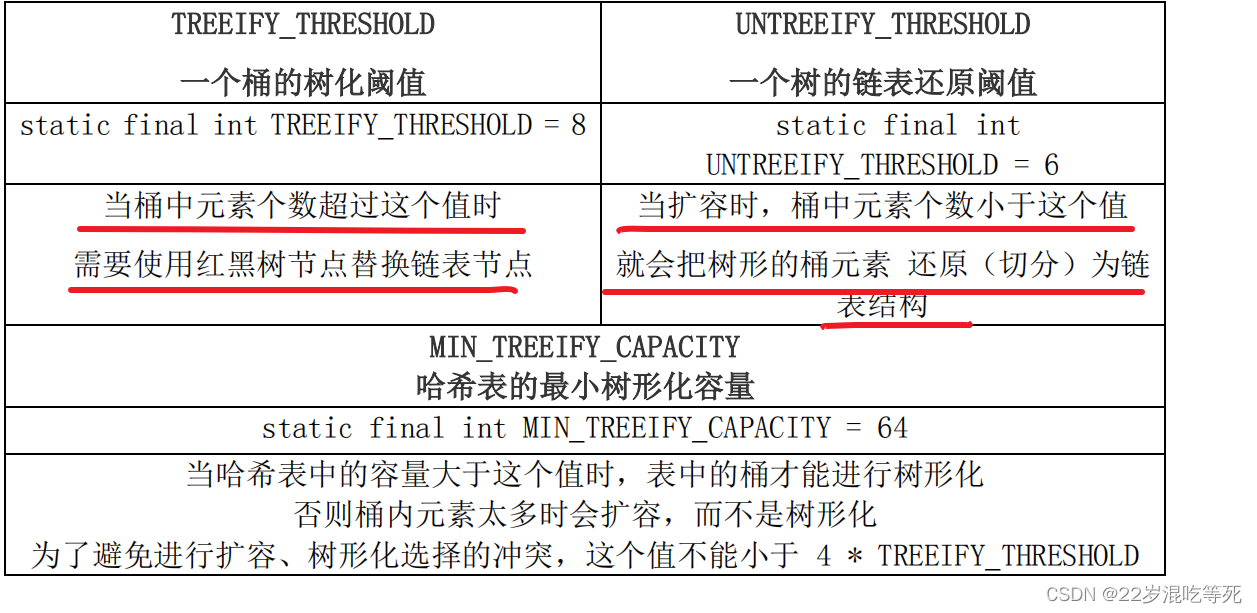
2.2HashMap 中关于红黑树的三个关键参数
2.3HashMap 在 JDK 1.8 中新增的操作:桶的树形化 treeifyBin()
在 Java 8 中,如果一个桶中的元素个数超过 TREEIFY_THRESHOLD(默认是 8 ),就使用红黑树来替换链表,从而提高速度。
这个替换的方法叫 treeifyBin() 即树形化。
//将桶内所有的 链表节点 替换成 红黑树节点
1 final void treeifyBin(Node<K,V>[] tab, int hash) {
2 int n, index; Node<K,V> e;
3 //如果当前哈希表为空,或者哈希表中元素的个数小于 进行树形化的阈值(默认为 64),就去新建/扩容
4 if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
5 resize();
6 else if ((e = tab[index = (n - 1) & hash]) != null) {
7 //如果哈希表中的元素个数超过了 树形化阈值,进行树形化
8 // e 是哈希表中指定位置桶里的链表节点,从第一个开始
9 TreeNode<K,V> hd = null, tl = null; //红黑树的头、尾节点
10 do {
11 //新建一个树形节点,内容和当前链表节点 e 一致
12 TreeNode<K,V> p = replacementTreeNode(e, null);
13 if (tl == null) //确定树头节点
14 hd = p;
15 else {
16 p.prev = tl;
17 tl.next = p;
18 }
19 tl = p;
20 } while ((e = e.next) != null);
21 //让桶的第一个元素指向新建的红黑树头结点,以后这个桶里的元素就是红黑树而不是链表了
22 if ((tab[index] = hd) != null)
23 hd.treeify(tab);
24 }
25 }
26 TreeNode<K,V> replacementTreeNode(Node<K,V> p, Node<K,V> next) {
27 return new TreeNode<>(p.hash, p.key, p.value, next);
28 }

三、分析 HashMap 的 put 方法
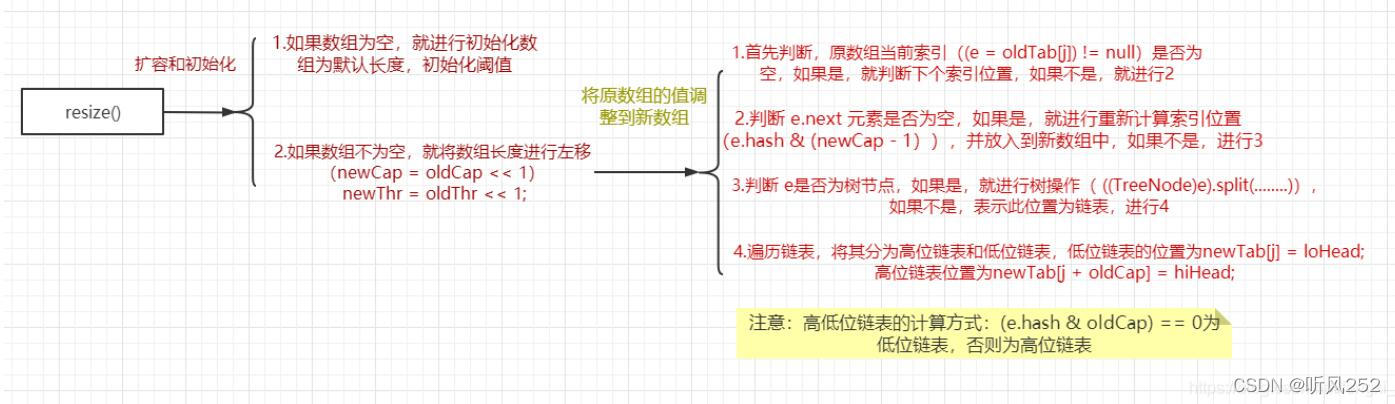
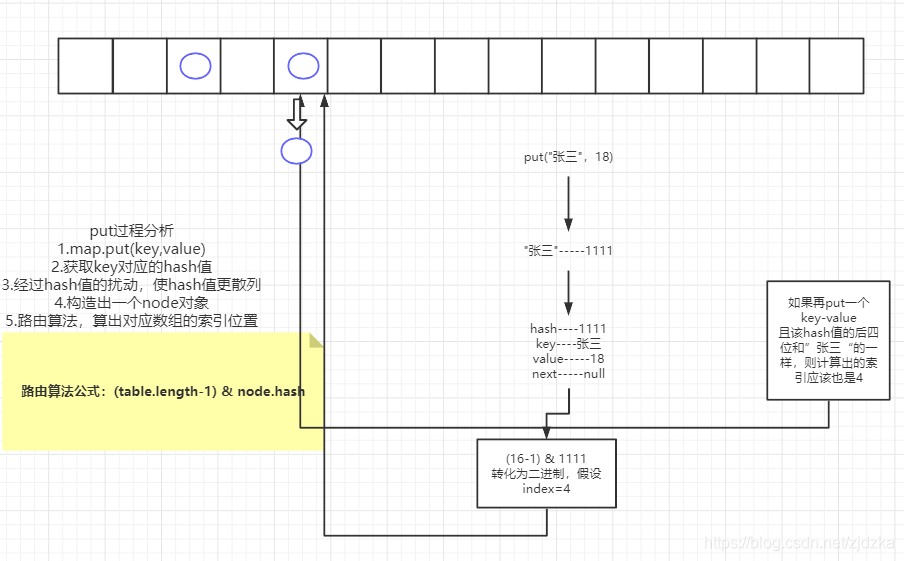
3.1HashMap 的 put 方法执行过程可以通过下图来理解,自己有兴趣可以去对比源码更清楚地研究学习。
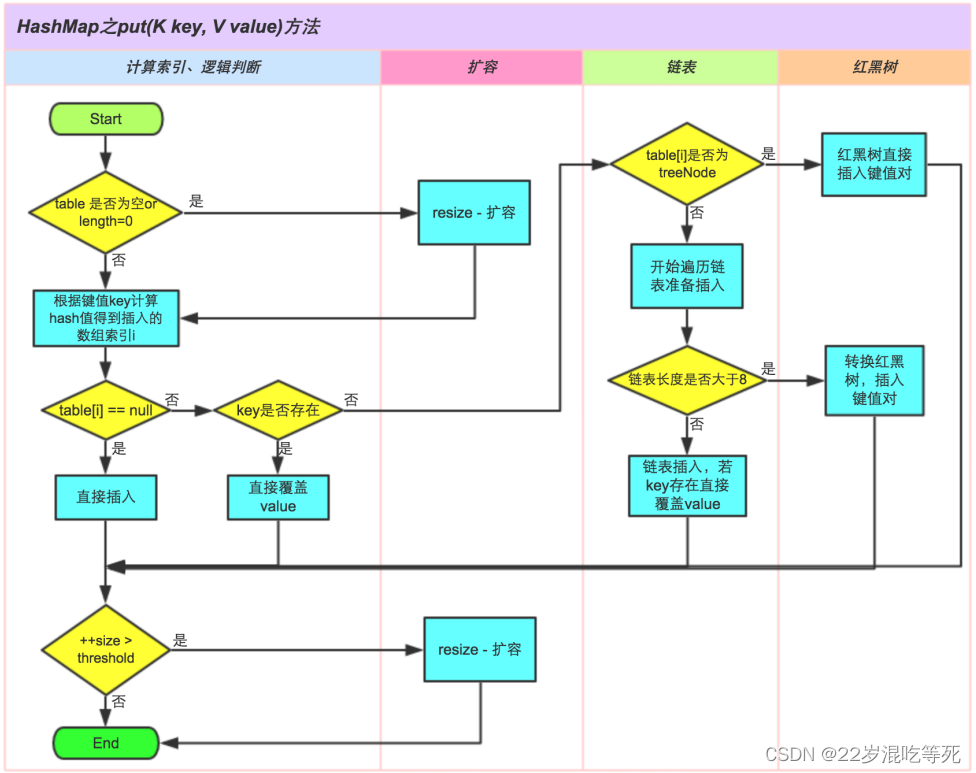

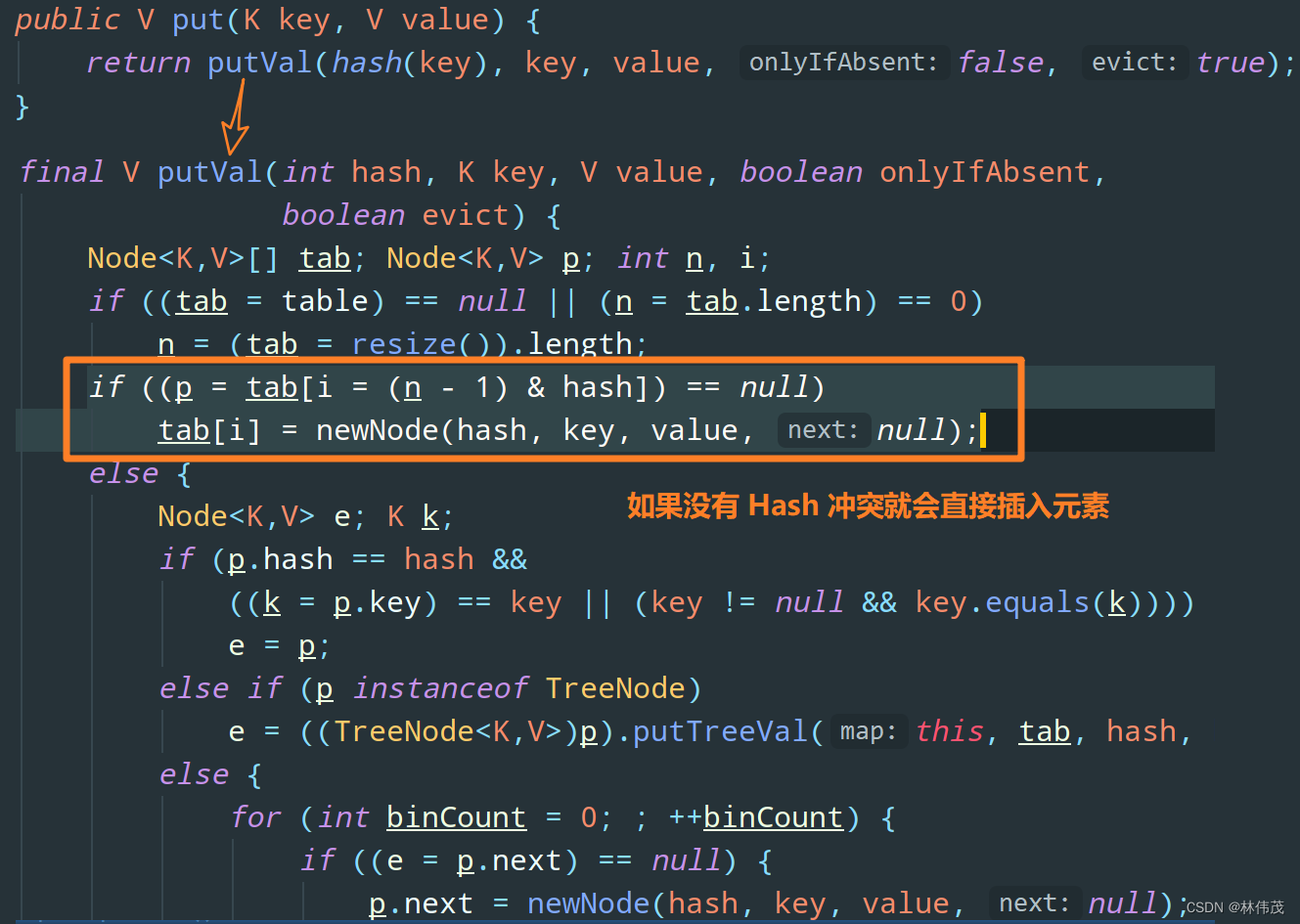
JDK1.8HashMap 的 put 方法源码
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {Node<K,V>[] tab; Node<K,V> p; int n, i;if ((tab = table) == null || (n = tab.length) == 0)n = (tab = resize()).length;if ((p = tab[i = (n - 1) & hash]) == null)tab[i] = newNode(hash, key, value, null);else {Node<K,V> e; K k;if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))e = p;else if (p instanceof TreeNode)e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);else {for (int binCount = 0; ; ++binCount) {if ((e = p.next) == null) {p.next = newNode(hash, key, value, null);if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1sttreeifyBin(tab, hash);break;}if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))break;p = e;}}if (e != null) { // existing mapping for keyV oldValue = e.value;if (!onlyIfAbsent || oldValue == null)e.value = value;afterNodeAccess(e);return oldValue;}}++modCount;if (++size > threshold)resize();afterNodeInsertion(evict);return null;}
HashMap源码
/** Copyright (c) 1997, 2021, Oracle and/or its affiliates. All rights reserved.* ORACLE PROPRIETARY/CONFIDENTIAL. Use is subject to license terms.*********************/package java.util;import java.io.IOException;
import java.io.InvalidObjectException;
import java.io.ObjectInputStream;
import java.io.Serializable;
import java.lang.reflect.ParameterizedType;
import java.lang.reflect.Type;
import java.util.function.BiConsumer;
import java.util.function.BiFunction;
import java.util.function.Consumer;
import java.util.function.Function;
import sun.misc.SharedSecrets;/*** Hash table based implementation of the <tt>Map</tt> interface. This* implementation provides all of the optional map operations, and permits* <tt>null</tt> values and the <tt>null</tt> key. (The <tt>HashMap</tt>* class is roughly equivalent to <tt>Hashtable</tt>, except that it is* unsynchronized and permits nulls.) This class makes no guarantees as to* the order of the map; in particular, it does not guarantee that the order* will remain constant over time.** <p>This implementation provides constant-time performance for the basic* operations (<tt>get</tt> and <tt>put</tt>), assuming the hash function* disperses the elements properly among the buckets. Iteration over* collection views requires time proportional to the "capacity" of the* <tt>HashMap</tt> instance (the number of buckets) plus its size (the number* of key-value mappings). Thus, it's very important not to set the initial* capacity too high (or the load factor too low) if iteration performance is* important.** <p>An instance of <tt>HashMap</tt> has two parameters that affect its* performance: <i>initial capacity</i> and <i>load factor</i>. The* <i>capacity</i> is the number of buckets in the hash table, and the initial* capacity is simply the capacity at the time the hash table is created. The* <i>load factor</i> is a measure of how full the hash table is allowed to* get before its capacity is automatically increased. When the number of* entries in the hash table exceeds the product of the load factor and the* current capacity, the hash table is <i>rehashed</i> (that is, internal data* structures are rebuilt) so that the hash table has approximately twice the* number of buckets.** <p>As a general rule, the default load factor (.75) offers a good* tradeoff between time and space costs. Higher values decrease the* space overhead but increase the lookup cost (reflected in most of* the operations of the <tt>HashMap</tt> class, including* <tt>get</tt> and <tt>put</tt>). The expected number of entries in* the map and its load factor should be taken into account when* setting its initial capacity, so as to minimize the number of* rehash operations. If the initial capacity is greater than the* maximum number of entries divided by the load factor, no rehash* operations will ever occur.** <p>If many mappings are to be stored in a <tt>HashMap</tt>* instance, creating it with a sufficiently large capacity will allow* the mappings to be stored more efficiently than letting it perform* automatic rehashing as needed to grow the table. Note that using* many keys with the same {@code hashCode()} is a sure way to slow* down performance of any hash table. To ameliorate impact, when keys* are {@link Comparable}, this class may use comparison order among* keys to help break ties.** <p><strong>Note that this implementation is not synchronized.</strong>* If multiple threads access a hash map concurrently, and at least one of* the threads modifies the map structurally, it <i>must</i> be* synchronized externally. (A structural modification is any operation* that adds or deletes one or more mappings; merely changing the value* associated with a key that an instance already contains is not a* structural modification.) This is typically accomplished by* synchronizing on some object that naturally encapsulates the map.** If no such object exists, the map should be "wrapped" using the* {@link Collections#synchronizedMap Collections.synchronizedMap}* method. This is best done at creation time, to prevent accidental* unsynchronized access to the map:<pre>* Map m = Collections.synchronizedMap(new HashMap(...));</pre>** <p>The iterators returned by all of this class's "collection view methods"* are <i>fail-fast</i>: if the map is structurally modified at any time after* the iterator is created, in any way except through the iterator's own* <tt>remove</tt> method, the iterator will throw a* {@link ConcurrentModificationException}. Thus, in the face of concurrent* modification, the iterator fails quickly and cleanly, rather than risking* arbitrary, non-deterministic behavior at an undetermined time in the* future.** <p>Note that the fail-fast behavior of an iterator cannot be guaranteed* as it is, generally speaking, impossible to make any hard guarantees in the* presence of unsynchronized concurrent modification. Fail-fast iterators* throw <tt>ConcurrentModificationException</tt> on a best-effort basis.* Therefore, it would be wrong to write a program that depended on this* exception for its correctness: <i>the fail-fast behavior of iterators* should be used only to detect bugs.</i>** <p>This class is a member of the* <a href="{@docRoot}/../technotes/guides/collections/index.html">* Java Collections Framework</a>.** @param <K> the type of keys maintained by this map* @param <V> the type of mapped values** @author Doug Lea* @author Josh Bloch* @author Arthur van Hoff* @author Neal Gafter* @see Object#hashCode()* @see Collection* @see Map* @see TreeMap* @see Hashtable* @since 1.2*/
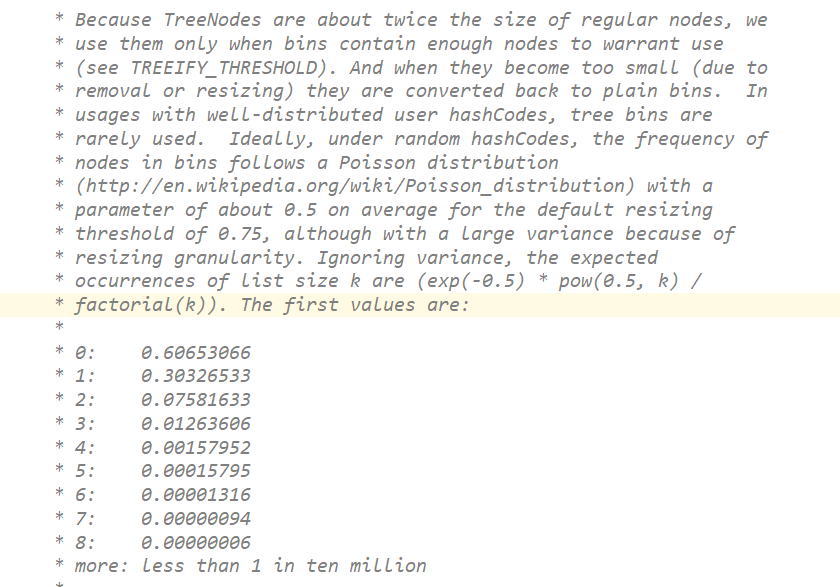
public class HashMap<K,V> extends AbstractMap<K,V>implements Map<K,V>, Cloneable, Serializable {private static final long serialVersionUID = 362498820763181265L;/** Implementation notes.** This map usually acts as a binned (bucketed) hash table, but* when bins get too large, they are transformed into bins of* TreeNodes, each structured similarly to those in* java.util.TreeMap. Most methods try to use normal bins, but* relay to TreeNode methods when applicable (simply by checking* instanceof a node). Bins of TreeNodes may be traversed and* used like any others, but additionally support faster lookup* when overpopulated. However, since the vast majority of bins in* normal use are not overpopulated, checking for existence of* tree bins may be delayed in the course of table methods.** Tree bins (i.e., bins whose elements are all TreeNodes) are* ordered primarily by hashCode, but in the case of ties, if two* elements are of the same "class C implements Comparable<C>",* type then their compareTo method is used for ordering. (We* conservatively check generic types via reflection to validate* this -- see method comparableClassFor). The added complexity* of tree bins is worthwhile in providing worst-case O(log n)* operations when keys either have distinct hashes or are* orderable, Thus, performance degrades gracefully under* accidental or malicious usages in which hashCode() methods* return values that are poorly distributed, as well as those in* which many keys share a hashCode, so long as they are also* Comparable. (If neither of these apply, we may waste about a* factor of two in time and space compared to taking no* precautions. But the only known cases stem from poor user* programming practices that are already so slow that this makes* little difference.)** Because TreeNodes are about twice the size of regular nodes, we* use them only when bins contain enough nodes to warrant use* (see TREEIFY_THRESHOLD). And when they become too small (due to* removal or resizing) they are converted back to plain bins. In* usages with well-distributed user hashCodes, tree bins are* rarely used. Ideally, under random hashCodes, the frequency of* nodes in bins follows a Poisson distribution* (http://en.wikipedia.org/wiki/Poisson_distribution) with a* parameter of about 0.5 on average for the default resizing* threshold of 0.75, although with a large variance because of* resizing granularity. Ignoring variance, the expected* occurrences of list size k are (exp(-0.5) * pow(0.5, k) /* factorial(k)). The first values are:** 0: 0.60653066* 1: 0.30326533* 2: 0.07581633* 3: 0.01263606* 4: 0.00157952* 5: 0.00015795* 6: 0.00001316* 7: 0.00000094* 8: 0.00000006* more: less than 1 in ten million** The root of a tree bin is normally its first node. However,* sometimes (currently only upon Iterator.remove), the root might* be elsewhere, but can be recovered following parent links* (method TreeNode.root()).** All applicable internal methods accept a hash code as an* argument (as normally supplied from a public method), allowing* them to call each other without recomputing user hashCodes.* Most internal methods also accept a "tab" argument, that is* normally the current table, but may be a new or old one when* resizing or converting.** When bin lists are treeified, split, or untreeified, we keep* them in the same relative access/traversal order (i.e., field* Node.next) to better preserve locality, and to slightly* simplify handling of splits and traversals that invoke* iterator.remove. When using comparators on insertion, to keep a* total ordering (or as close as is required here) across* rebalancings, we compare classes and identityHashCodes as* tie-breakers.** The use and transitions among plain vs tree modes is* complicated by the existence of subclass LinkedHashMap. See* below for hook methods defined to be invoked upon insertion,* removal and access that allow LinkedHashMap internals to* otherwise remain independent of these mechanics. (This also* requires that a map instance be passed to some utility methods* that may create new nodes.)** The concurrent-programming-like SSA-based coding style helps* avoid aliasing errors amid all of the twisty pointer operations.*//*** The default initial capacity - MUST be a power of two.*/static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16/*** The maximum capacity, used if a higher value is implicitly specified* by either of the constructors with arguments.* MUST be a power of two <= 1<<30.*/static final int MAXIMUM_CAPACITY = 1 << 30;/*** The load factor used when none specified in constructor.*/static final float DEFAULT_LOAD_FACTOR = 0.75f;/*** The bin count threshold for using a tree rather than list for a* bin. Bins are converted to trees when adding an element to a* bin with at least this many nodes. The value must be greater* than 2 and should be at least 8 to mesh with assumptions in* tree removal about conversion back to plain bins upon* shrinkage.*/static final int TREEIFY_THRESHOLD = 8;/*** The bin count threshold for untreeifying a (split) bin during a* resize operation. Should be less than TREEIFY_THRESHOLD, and at* most 6 to mesh with shrinkage detection under removal.*/static final int UNTREEIFY_THRESHOLD = 6;/*** The smallest table capacity for which bins may be treeified.* (Otherwise the table is resized if too many nodes in a bin.)* Should be at least 4 * TREEIFY_THRESHOLD to avoid conflicts* between resizing and treeification thresholds.*/static final int MIN_TREEIFY_CAPACITY = 64;/*** Basic hash bin node, used for most entries. (See below for* TreeNode subclass, and in LinkedHashMap for its Entry subclass.)*/static class Node<K,V> implements Map.Entry<K,V> {final int hash;final K key;V value;Node<K,V> next;Node(int hash, K key, V value, Node<K,V> next) {this.hash = hash;this.key = key;this.value = value;this.next = next;}public final K getKey() { return key; }public final V getValue() { return value; }public final String toString() { return key + "=" + value; }public final int hashCode() {return Objects.hashCode(key) ^ Objects.hashCode(value);}public final V setValue(V newValue) {V oldValue = value;value = newValue;return oldValue;}public final boolean equals(Object o) {if (o == this)return true;if (o instanceof Map.Entry) {Map.Entry<?,?> e = (Map.Entry<?,?>)o;if (Objects.equals(key, e.getKey()) &&Objects.equals(value, e.getValue()))return true;}return false;}}/* ---------------- Static utilities -------------- *//*** Computes key.hashCode() and spreads (XORs) higher bits of hash* to lower. Because the table uses power-of-two masking, sets of* hashes that vary only in bits above the current mask will* always collide. (Among known examples are sets of Float keys* holding consecutive whole numbers in small tables.) So we* apply a transform that spreads the impact of higher bits* downward. There is a tradeoff between speed, utility, and* quality of bit-spreading. Because many common sets of hashes* are already reasonably distributed (so don't benefit from* spreading), and because we use trees to handle large sets of* collisions in bins, we just XOR some shifted bits in the* cheapest possible way to reduce systematic lossage, as well as* to incorporate impact of the highest bits that would otherwise* never be used in index calculations because of table bounds.*/static final int hash(Object key) {int h;return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);}/*** Returns x's Class if it is of the form "class C implements* Comparable<C>", else null.*/static Class<?> comparableClassFor(Object x) {if (x instanceof Comparable) {Class<?> c; Type[] ts, as; Type t; ParameterizedType p;if ((c = x.getClass()) == String.class) // bypass checksreturn c;if ((ts = c.getGenericInterfaces()) != null) {for (int i = 0; i < ts.length; ++i) {if (((t = ts[i]) instanceof ParameterizedType) &&((p = (ParameterizedType)t).getRawType() ==Comparable.class) &&(as = p.getActualTypeArguments()) != null &&as.length == 1 && as[0] == c) // type arg is creturn c;}}}return null;}/*** Returns k.compareTo(x) if x matches kc (k's screened comparable* class), else 0.*/@SuppressWarnings({"rawtypes","unchecked"}) // for cast to Comparablestatic int compareComparables(Class<?> kc, Object k, Object x) {return (x == null || x.getClass() != kc ? 0 :((Comparable)k).compareTo(x));}/*** Returns a power of two size for the given target capacity.*/static final int tableSizeFor(int cap) {int n = cap - 1;n |= n >>> 1;n |= n >>> 2;n |= n >>> 4;n |= n >>> 8;n |= n >>> 16;return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;}/* ---------------- Fields -------------- *//*** The table, initialized on first use, and resized as* necessary. When allocated, length is always a power of two.* (We also tolerate length zero in some operations to allow* bootstrapping mechanics that are currently not needed.)*/transient Node<K,V>[] table;/*** Holds cached entrySet(). Note that AbstractMap fields are used* for keySet() and values().*/transient Set<Map.Entry<K,V>> entrySet;/*** The number of key-value mappings contained in this map.*/transient int size;/*** The number of times this HashMap has been structurally modified* Structural modifications are those that change the number of mappings in* the HashMap or otherwise modify its internal structure (e.g.,* rehash). This field is used to make iterators on Collection-views of* the HashMap fail-fast. (See ConcurrentModificationException).*/transient int modCount;/*** The next size value at which to resize (capacity * load factor).** @serial*/// (The javadoc description is true upon serialization.// Additionally, if the table array has not been allocated, this// field holds the initial array capacity, or zero signifying// DEFAULT_INITIAL_CAPACITY.)int threshold;/*** The load factor for the hash table.** @serial*/final float loadFactor;/* ---------------- Public operations -------------- *//*** Constructs an empty <tt>HashMap</tt> with the specified initial* capacity and load factor.** @param initialCapacity the initial capacity* @param loadFactor the load factor* @throws IllegalArgumentException if the initial capacity is negative* or the load factor is nonpositive*/public HashMap(int initialCapacity, float loadFactor) {if (initialCapacity < 0)throw new IllegalArgumentException("Illegal initial capacity: " +initialCapacity);if (initialCapacity > MAXIMUM_CAPACITY)initialCapacity = MAXIMUM_CAPACITY;if (loadFactor <= 0 || Float.isNaN(loadFactor))throw new IllegalArgumentException("Illegal load factor: " +loadFactor);this.loadFactor = loadFactor;this.threshold = tableSizeFor(initialCapacity);}/*** Constructs an empty <tt>HashMap</tt> with the specified initial* capacity and the default load factor (0.75).** @param initialCapacity the initial capacity.* @throws IllegalArgumentException if the initial capacity is negative.*/public HashMap(int initialCapacity) {this(initialCapacity, DEFAULT_LOAD_FACTOR);}/*** Constructs an empty <tt>HashMap</tt> with the default initial capacity* (16) and the default load factor (0.75).*/public HashMap() {this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted}/*** Constructs a new <tt>HashMap</tt> with the same mappings as the* specified <tt>Map</tt>. The <tt>HashMap</tt> is created with* default load factor (0.75) and an initial capacity sufficient to* hold the mappings in the specified <tt>Map</tt>.** @param m the map whose mappings are to be placed in this map* @throws NullPointerException if the specified map is null*/public HashMap(Map<? extends K, ? extends V> m) {this.loadFactor = DEFAULT_LOAD_FACTOR;putMapEntries(m, false);}/*** Implements Map.putAll and Map constructor.** @param m the map* @param evict false when initially constructing this map, else* true (relayed to method afterNodeInsertion).*/final void putMapEntries(Map<? extends K, ? extends V> m, boolean evict) {int s = m.size();if (s > 0) {if (table == null) { // pre-sizefloat ft = ((float)s / loadFactor) + 1.0F;int t = ((ft < (float)MAXIMUM_CAPACITY) ?(int)ft : MAXIMUM_CAPACITY);if (t > threshold)threshold = tableSizeFor(t);}else if (s > threshold)resize();for (Map.Entry<? extends K, ? extends V> e : m.entrySet()) {K key = e.getKey();V value = e.getValue();putVal(hash(key), key, value, false, evict);}}}/*** Returns the number of key-value mappings in this map.** @return the number of key-value mappings in this map*/public int size() {return size;}/*** Returns <tt>true</tt> if this map contains no key-value mappings.** @return <tt>true</tt> if this map contains no key-value mappings*/public boolean isEmpty() {return size == 0;}/*** Returns the value to which the specified key is mapped,* or {@code null} if this map contains no mapping for the key.** <p>More formally, if this map contains a mapping from a key* {@code k} to a value {@code v} such that {@code (key==null ? k==null :* key.equals(k))}, then this method returns {@code v}; otherwise* it returns {@code null}. (There can be at most one such mapping.)** <p>A return value of {@code null} does not <i>necessarily</i>* indicate that the map contains no mapping for the key; it's also* possible that the map explicitly maps the key to {@code null}.* The {@link #containsKey containsKey} operation may be used to* distinguish these two cases.** @see #put(Object, Object)*/public V get(Object key) {Node<K,V> e;return (e = getNode(hash(key), key)) == null ? null : e.value;}/*** Implements Map.get and related methods.** @param hash hash for key* @param key the key* @return the node, or null if none*/final Node<K,V> getNode(int hash, Object key) {Node<K,V>[] tab; Node<K,V> first, e; int n; K k;if ((tab = table) != null && (n = tab.length) > 0 &&(first = tab[(n - 1) & hash]) != null) {if (first.hash == hash && // always check first node((k = first.key) == key || (key != null && key.equals(k))))return first;if ((e = first.next) != null) {if (first instanceof TreeNode)return ((TreeNode<K,V>)first).getTreeNode(hash, key);do {if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))return e;} while ((e = e.next) != null);}}return null;}/*** Returns <tt>true</tt> if this map contains a mapping for the* specified key.** @param key The key whose presence in this map is to be tested* @return <tt>true</tt> if this map contains a mapping for the specified* key.*/public boolean containsKey(Object key) {return getNode(hash(key), key) != null;}/*** Associates the specified value with the specified key in this map.* If the map previously contained a mapping for the key, the old* value is replaced.** @param key key with which the specified value is to be associated* @param value value to be associated with the specified key* @return the previous value associated with <tt>key</tt>, or* <tt>null</tt> if there was no mapping for <tt>key</tt>.* (A <tt>null</tt> return can also indicate that the map* previously associated <tt>null</tt> with <tt>key</tt>.)*/public V put(K key, V value) {return putVal(hash(key), key, value, false, true);}/*** Implements Map.put and related methods.** @param hash hash for key* @param key the key* @param value the value to put* @param onlyIfAbsent if true, don't change existing value* @param evict if false, the table is in creation mode.* @return previous value, or null if none*/final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {Node<K,V>[] tab; Node<K,V> p; int n, i;if ((tab = table) == null || (n = tab.length) == 0)n = (tab = resize()).length;if ((p = tab[i = (n - 1) & hash]) == null)tab[i] = newNode(hash, key, value, null);else {Node<K,V> e; K k;if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))e = p;else if (p instanceof TreeNode)e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);else {for (int binCount = 0; ; ++binCount) {if ((e = p.next) == null) {p.next = newNode(hash, key, value, null);if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1sttreeifyBin(tab, hash);break;}if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))break;p = e;}}if (e != null) { // existing mapping for keyV oldValue = e.value;if (!onlyIfAbsent || oldValue == null)e.value = value;afterNodeAccess(e);return oldValue;}}++modCount;if (++size > threshold)resize();afterNodeInsertion(evict);return null;}/*** Initializes or doubles table size. If null, allocates in* accord with initial capacity target held in field threshold.* Otherwise, because we are using power-of-two expansion, the* elements from each bin must either stay at same index, or move* with a power of two offset in the new table.** @return the table*/final Node<K,V>[] resize() {Node<K,V>[] oldTab = table;int oldCap = (oldTab == null) ? 0 : oldTab.length;int oldThr = threshold;int newCap, newThr = 0;if (oldCap > 0) {if (oldCap >= MAXIMUM_CAPACITY) {threshold = Integer.MAX_VALUE;return oldTab;}else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&oldCap >= DEFAULT_INITIAL_CAPACITY)newThr = oldThr << 1; // double threshold}else if (oldThr > 0) // initial capacity was placed in thresholdnewCap = oldThr;else { // zero initial threshold signifies using defaultsnewCap = DEFAULT_INITIAL_CAPACITY;newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);}if (newThr == 0) {float ft = (float)newCap * loadFactor;newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?(int)ft : Integer.MAX_VALUE);}threshold = newThr;@SuppressWarnings({"rawtypes","unchecked"})Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];table = newTab;if (oldTab != null) {for (int j = 0; j < oldCap; ++j) {Node<K,V> e;if ((e = oldTab[j]) != null) {oldTab[j] = null;if (e.next == null)newTab[e.hash & (newCap - 1)] = e;else if (e instanceof TreeNode)((TreeNode<K,V>)e).split(this, newTab, j, oldCap);else { // preserve orderNode<K,V> loHead = null, loTail = null;Node<K,V> hiHead = null, hiTail = null;Node<K,V> next;do {next = e.next;if ((e.hash & oldCap) == 0) {if (loTail == null)loHead = e;elseloTail.next = e;loTail = e;}else {if (hiTail == null)hiHead = e;elsehiTail.next = e;hiTail = e;}} while ((e = next) != null);if (loTail != null) {loTail.next = null;newTab[j] = loHead;}if (hiTail != null) {hiTail.next = null;newTab[j + oldCap] = hiHead;}}}}}return newTab;}/*** Replaces all linked nodes in bin at index for given hash unless* table is too small, in which case resizes instead.*/final void treeifyBin(Node<K,V>[] tab, int hash) {int n, index; Node<K,V> e;if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)resize();else if ((e = tab[index = (n - 1) & hash]) != null) {TreeNode<K,V> hd = null, tl = null;do {TreeNode<K,V> p = replacementTreeNode(e, null);if (tl == null)hd = p;else {p.prev = tl;tl.next = p;}tl = p;} while ((e = e.next) != null);if ((tab[index] = hd) != null)hd.treeify(tab);}}/*** Copies all of the mappings from the specified map to this map.* These mappings will replace any mappings that this map had for* any of the keys currently in the specified map.** @param m mappings to be stored in this map* @throws NullPointerException if the specified map is null*/public void putAll(Map<? extends K, ? extends V> m) {putMapEntries(m, true);}/*** Removes the mapping for the specified key from this map if present.** @param key key whose mapping is to be removed from the map* @return the previous value associated with <tt>key</tt>, or* <tt>null</tt> if there was no mapping for <tt>key</tt>.* (A <tt>null</tt> return can also indicate that the map* previously associated <tt>null</tt> with <tt>key</tt>.)*/public V remove(Object key) {Node<K,V> e;return (e = removeNode(hash(key), key, null, false, true)) == null ?null : e.value;}/*** Implements Map.remove and related methods.** @param hash hash for key* @param key the key* @param value the value to match if matchValue, else ignored* @param matchValue if true only remove if value is equal* @param movable if false do not move other nodes while removing* @return the node, or null if none*/final Node<K,V> removeNode(int hash, Object key, Object value,boolean matchValue, boolean movable) {Node<K,V>[] tab; Node<K,V> p; int n, index;if ((tab = table) != null && (n = tab.length) > 0 &&(p = tab[index = (n - 1) & hash]) != null) {Node<K,V> node = null, e; K k; V v;if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))node = p;else if ((e = p.next) != null) {if (p instanceof TreeNode)node = ((TreeNode<K,V>)p).getTreeNode(hash, key);else {do {if (e.hash == hash &&((k = e.key) == key ||(key != null && key.equals(k)))) {node = e;break;}p = e;} while ((e = e.next) != null);}}if (node != null && (!matchValue || (v = node.value) == value ||(value != null && value.equals(v)))) {if (node instanceof TreeNode)((TreeNode<K,V>)node).removeTreeNode(this, tab, movable);else if (node == p)tab[index] = node.next;elsep.next = node.next;++modCount;--size;afterNodeRemoval(node);return node;}}return null;}/*** Removes all of the mappings from this map.* The map will be empty after this call returns.*/public void clear() {Node<K,V>[] tab;modCount++;if ((tab = table) != null && size > 0) {size = 0;for (int i = 0; i < tab.length; ++i)tab[i] = null;}}/*** Returns <tt>true</tt> if this map maps one or more keys to the* specified value.** @param value value whose presence in this map is to be tested* @return <tt>true</tt> if this map maps one or more keys to the* specified value*/public boolean containsValue(Object value) {Node<K,V>[] tab; V v;if ((tab = table) != null && size > 0) {for (int i = 0; i < tab.length; ++i) {for (Node<K,V> e = tab[i]; e != null; e = e.next) {if ((v = e.value) == value ||(value != null && value.equals(v)))return true;}}}return false;}/*** Returns a {@link Set} view of the keys contained in this map.* The set is backed by the map, so changes to the map are* reflected in the set, and vice-versa. If the map is modified* while an iteration over the set is in progress (except through* the iterator's own <tt>remove</tt> operation), the results of* the iteration are undefined. The set supports element removal,* which removes the corresponding mapping from the map, via the* <tt>Iterator.remove</tt>, <tt>Set.remove</tt>,* <tt>removeAll</tt>, <tt>retainAll</tt>, and <tt>clear</tt>* operations. It does not support the <tt>add</tt> or <tt>addAll</tt>* operations.** @return a set view of the keys contained in this map*/public Set<K> keySet() {Set<K> ks = keySet;if (ks == null) {ks = new KeySet();keySet = ks;}return ks;}final class KeySet extends AbstractSet<K> {public final int size() { return size; }public final void clear() { HashMap.this.clear(); }public final Iterator<K> iterator() { return new KeyIterator(); }public final boolean contains(Object o) { return containsKey(o); }public final boolean remove(Object key) {return removeNode(hash(key), key, null, false, true) != null;}public final Spliterator<K> spliterator() {return new KeySpliterator<>(HashMap.this, 0, -1, 0, 0);}public final void forEach(Consumer<? super K> action) {Node<K,V>[] tab;if (action == null)throw new NullPointerException();if (size > 0 && (tab = table) != null) {int mc = modCount;for (int i = 0; i < tab.length; ++i) {for (Node<K,V> e = tab[i]; e != null; e = e.next)action.accept(e.key);}if (modCount != mc)throw new ConcurrentModificationException();}}}/*** Returns a {@link Collection} view of the values contained in this map.* The collection is backed by the map, so changes to the map are* reflected in the collection, and vice-versa. If the map is* modified while an iteration over the collection is in progress* (except through the iterator's own <tt>remove</tt> operation),* the results of the iteration are undefined. The collection* supports element removal, which removes the corresponding* mapping from the map, via the <tt>Iterator.remove</tt>,* <tt>Collection.remove</tt>, <tt>removeAll</tt>,* <tt>retainAll</tt> and <tt>clear</tt> operations. It does not* support the <tt>add</tt> or <tt>addAll</tt> operations.** @return a view of the values contained in this map*/public Collection<V> values() {Collection<V> vs = values;if (vs == null) {vs = new Values();values = vs;}return vs;}final class Values extends AbstractCollection<V> {public final int size() { return size; }public final void clear() { HashMap.this.clear(); }public final Iterator<V> iterator() { return new ValueIterator(); }public final boolean contains(Object o) { return containsValue(o); }public final Spliterator<V> spliterator() {return new ValueSpliterator<>(HashMap.this, 0, -1, 0, 0);}public final void forEach(Consumer<? super V> action) {Node<K,V>[] tab;if (action == null)throw new NullPointerException();if (size > 0 && (tab = table) != null) {int mc = modCount;for (int i = 0; i < tab.length; ++i) {for (Node<K,V> e = tab[i]; e != null; e = e.next)action.accept(e.value);}if (modCount != mc)throw new ConcurrentModificationException();}}}/*** Returns a {@link Set} view of the mappings contained in this map.* The set is backed by the map, so changes to the map are* reflected in the set, and vice-versa. If the map is modified* while an iteration over the set is in progress (except through* the iterator's own <tt>remove</tt> operation, or through the* <tt>setValue</tt> operation on a map entry returned by the* iterator) the results of the iteration are undefined. The set* supports element removal, which removes the corresponding* mapping from the map, via the <tt>Iterator.remove</tt>,* <tt>Set.remove</tt>, <tt>removeAll</tt>, <tt>retainAll</tt> and* <tt>clear</tt> operations. It does not support the* <tt>add</tt> or <tt>addAll</tt> operations.** @return a set view of the mappings contained in this map*/public Set<Map.Entry<K,V>> entrySet() {Set<Map.Entry<K,V>> es;return (es = entrySet) == null ? (entrySet = new EntrySet()) : es;}final class EntrySet extends AbstractSet<Map.Entry<K,V>> {public final int size() { return size; }public final void clear() { HashMap.this.clear(); }public final Iterator<Map.Entry<K,V>> iterator() {return new EntryIterator();}public final boolean contains(Object o) {if (!(o instanceof Map.Entry))return false;Map.Entry<?,?> e = (Map.Entry<?,?>) o;Object key = e.getKey();Node<K,V> candidate = getNode(hash(key), key);return candidate != null && candidate.equals(e);}public final boolean remove(Object o) {if (o instanceof Map.Entry) {Map.Entry<?,?> e = (Map.Entry<?,?>) o;Object key = e.getKey();Object value = e.getValue();return removeNode(hash(key), key, value, true, true) != null;}return false;}public final Spliterator<Map.Entry<K,V>> spliterator() {return new EntrySpliterator<>(HashMap.this, 0, -1, 0, 0);}public final void forEach(Consumer<? super Map.Entry<K,V>> action) {Node<K,V>[] tab;if (action == null)throw new NullPointerException();if (size > 0 && (tab = table) != null) {int mc = modCount;for (int i = 0; i < tab.length; ++i) {for (Node<K,V> e = tab[i]; e != null; e = e.next)action.accept(e);}if (modCount != mc)throw new ConcurrentModificationException();}}}// Overrides of JDK8 Map extension methods@Overridepublic V getOrDefault(Object key, V defaultValue) {Node<K,V> e;return (e = getNode(hash(key), key)) == null ? defaultValue : e.value;}@Overridepublic V putIfAbsent(K key, V value) {return putVal(hash(key), key, value, true, true);}@Overridepublic boolean remove(Object key, Object value) {return removeNode(hash(key), key, value, true, true) != null;}@Overridepublic boolean replace(K key, V oldValue, V newValue) {Node<K,V> e; V v;if ((e = getNode(hash(key), key)) != null &&((v = e.value) == oldValue || (v != null && v.equals(oldValue)))) {e.value = newValue;afterNodeAccess(e);return true;}return false;}@Overridepublic V replace(K key, V value) {Node<K,V> e;if ((e = getNode(hash(key), key)) != null) {V oldValue = e.value;e.value = value;afterNodeAccess(e);return oldValue;}return null;}@Overridepublic V computeIfAbsent(K key,Function<? super K, ? extends V> mappingFunction) {if (mappingFunction == null)throw new NullPointerException();int hash = hash(key);Node<K,V>[] tab; Node<K,V> first; int n, i;int binCount = 0;TreeNode<K,V> t = null;Node<K,V> old = null;if (size > threshold || (tab = table) == null ||(n = tab.length) == 0)n = (tab = resize()).length;if ((first = tab[i = (n - 1) & hash]) != null) {if (first instanceof TreeNode)old = (t = (TreeNode<K,V>)first).getTreeNode(hash, key);else {Node<K,V> e = first; K k;do {if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k)))) {old = e;break;}++binCount;} while ((e = e.next) != null);}V oldValue;if (old != null && (oldValue = old.value) != null) {afterNodeAccess(old);return oldValue;}}V v = mappingFunction.apply(key);if (v == null) {return null;} else if (old != null) {old.value = v;afterNodeAccess(old);return v;}else if (t != null)t.putTreeVal(this, tab, hash, key, v);else {tab[i] = newNode(hash, key, v, first);if (binCount >= TREEIFY_THRESHOLD - 1)treeifyBin(tab, hash);}++modCount;++size;afterNodeInsertion(true);return v;}public V computeIfPresent(K key,BiFunction<? super K, ? super V, ? extends V> remappingFunction) {if (remappingFunction == null)throw new NullPointerException();Node<K,V> e; V oldValue;int hash = hash(key);if ((e = getNode(hash, key)) != null &&(oldValue = e.value) != null) {V v = remappingFunction.apply(key, oldValue);if (v != null) {e.value = v;afterNodeAccess(e);return v;}elseremoveNode(hash, key, null, false, true);}return null;}@Overridepublic V compute(K key,BiFunction<? super K, ? super V, ? extends V> remappingFunction) {if (remappingFunction == null)throw new NullPointerException();int hash = hash(key);Node<K,V>[] tab; Node<K,V> first; int n, i;int binCount = 0;TreeNode<K,V> t = null;Node<K,V> old = null;if (size > threshold || (tab = table) == null ||(n = tab.length) == 0)n = (tab = resize()).length;if ((first = tab[i = (n - 1) & hash]) != null) {if (first instanceof TreeNode)old = (t = (TreeNode<K,V>)first).getTreeNode(hash, key);else {Node<K,V> e = first; K k;do {if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k)))) {old = e;break;}++binCount;} while ((e = e.next) != null);}}V oldValue = (old == null) ? null : old.value;V v = remappingFunction.apply(key, oldValue);if (old != null) {if (v != null) {old.value = v;afterNodeAccess(old);}elseremoveNode(hash, key, null, false, true);}else if (v != null) {if (t != null)t.putTreeVal(this, tab, hash, key, v);else {tab[i] = newNode(hash, key, v, first);if (binCount >= TREEIFY_THRESHOLD - 1)treeifyBin(tab, hash);}++modCount;++size;afterNodeInsertion(true);}return v;}@Overridepublic V merge(K key, V value,BiFunction<? super V, ? super V, ? extends V> remappingFunction) {if (value == null)throw new NullPointerException();if (remappingFunction == null)throw new NullPointerException();int hash = hash(key);Node<K,V>[] tab; Node<K,V> first; int n, i;int binCount = 0;TreeNode<K,V> t = null;Node<K,V> old = null;if (size > threshold || (tab = table) == null ||(n = tab.length) == 0)n = (tab = resize()).length;if ((first = tab[i = (n - 1) & hash]) != null) {if (first instanceof TreeNode)old = (t = (TreeNode<K,V>)first).getTreeNode(hash, key);else {Node<K,V> e = first; K k;do {if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k)))) {old = e;break;}++binCount;} while ((e = e.next) != null);}}if (old != null) {V v;if (old.value != null)v = remappingFunction.apply(old.value, value);elsev = value;if (v != null) {old.value = v;afterNodeAccess(old);}elseremoveNode(hash, key, null, false, true);return v;}if (value != null) {if (t != null)t.putTreeVal(this, tab, hash, key, value);else {tab[i] = newNode(hash, key, value, first);if (binCount >= TREEIFY_THRESHOLD - 1)treeifyBin(tab, hash);}++modCount;++size;afterNodeInsertion(true);}return value;}@Overridepublic void forEach(BiConsumer<? super K, ? super V> action) {Node<K,V>[] tab;if (action == null)throw new NullPointerException();if (size > 0 && (tab = table) != null) {int mc = modCount;for (int i = 0; i < tab.length; ++i) {for (Node<K,V> e = tab[i]; e != null; e = e.next)action.accept(e.key, e.value);}if (modCount != mc)throw new ConcurrentModificationException();}}@Overridepublic void replaceAll(BiFunction<? super K, ? super V, ? extends V> function) {Node<K,V>[] tab;if (function == null)throw new NullPointerException();if (size > 0 && (tab = table) != null) {int mc = modCount;for (int i = 0; i < tab.length; ++i) {for (Node<K,V> e = tab[i]; e != null; e = e.next) {e.value = function.apply(e.key, e.value);}}if (modCount != mc)throw new ConcurrentModificationException();}}/* ------------------------------------------------------------ */// Cloning and serialization/*** Returns a shallow copy of this <tt>HashMap</tt> instance: the keys and* values themselves are not cloned.** @return a shallow copy of this map*/@SuppressWarnings("unchecked")@Overridepublic Object clone() {HashMap<K,V> result;try {result = (HashMap<K,V>)super.clone();} catch (CloneNotSupportedException e) {// this shouldn't happen, since we are Cloneablethrow new InternalError(e);}result.reinitialize();result.putMapEntries(this, false);return result;}// These methods are also used when serializing HashSetsfinal float loadFactor() { return loadFactor; }final int capacity() {return (table != null) ? table.length :(threshold > 0) ? threshold :DEFAULT_INITIAL_CAPACITY;}/*** Save the state of the <tt>HashMap</tt> instance to a stream (i.e.,* serialize it).** @serialData The <i>capacity</i> of the HashMap (the length of the* bucket array) is emitted (int), followed by the* <i>size</i> (an int, the number of key-value* mappings), followed by the key (Object) and value (Object)* for each key-value mapping. The key-value mappings are* emitted in no particular order.*/private void writeObject(java.io.ObjectOutputStream s)throws IOException {int buckets = capacity();// Write out the threshold, loadfactor, and any hidden stuffs.defaultWriteObject();s.writeInt(buckets);s.writeInt(size);internalWriteEntries(s);}/*** Reconstitutes this map from a stream (that is, deserializes it).* @param s the stream* @throws ClassNotFoundException if the class of a serialized object* could not be found* @throws IOException if an I/O error occurs*/private void readObject(ObjectInputStream s)throws IOException, ClassNotFoundException {ObjectInputStream.GetField fields = s.readFields();// Read loadFactor (ignore threshold)float lf = fields.get("loadFactor", 0.75f);if (lf <= 0 || Float.isNaN(lf))throw new InvalidObjectException("Illegal load factor: " + lf);lf = Math.min(Math.max(0.25f, lf), 4.0f);HashMap.UnsafeHolder.putLoadFactor(this, lf);reinitialize();s.readInt(); // Read and ignore number of bucketsint mappings = s.readInt(); // Read number of mappings (size)if (mappings < 0) {throw new InvalidObjectException("Illegal mappings count: " + mappings);} else if (mappings == 0) {// use defaults} else if (mappings > 0) {float fc = (float)mappings / lf + 1.0f;int cap = ((fc < DEFAULT_INITIAL_CAPACITY) ?DEFAULT_INITIAL_CAPACITY :(fc >= MAXIMUM_CAPACITY) ?MAXIMUM_CAPACITY :tableSizeFor((int)fc));float ft = (float)cap * lf;threshold = ((cap < MAXIMUM_CAPACITY && ft < MAXIMUM_CAPACITY) ?(int)ft : Integer.MAX_VALUE);// Check Map.Entry[].class since it's the nearest public type to// what we're actually creating.SharedSecrets.getJavaOISAccess().checkArray(s, Map.Entry[].class, cap);@SuppressWarnings({"rawtypes","unchecked"})Node<K,V>[] tab = (Node<K,V>[])new Node[cap];table = tab;// Read the keys and values, and put the mappings in the HashMapfor (int i = 0; i < mappings; i++) {@SuppressWarnings("unchecked")K key = (K) s.readObject();@SuppressWarnings("unchecked")V value = (V) s.readObject();putVal(hash(key), key, value, false, false);}}}// Support for resetting final field during deserializingprivate static final class UnsafeHolder {private UnsafeHolder() { throw new InternalError(); }private static final sun.misc.Unsafe unsafe= sun.misc.Unsafe.getUnsafe();private static final long LF_OFFSET;static {try {LF_OFFSET = unsafe.objectFieldOffset(HashMap.class.getDeclaredField("loadFactor"));} catch (NoSuchFieldException e) {throw new InternalError();}}static void putLoadFactor(HashMap<?, ?> map, float lf) {unsafe.putFloat(map, LF_OFFSET, lf);}}/* ------------------------------------------------------------ */// iteratorsabstract class HashIterator {Node<K,V> next; // next entry to returnNode<K,V> current; // current entryint expectedModCount; // for fast-failint index; // current slotHashIterator() {expectedModCount = modCount;Node<K,V>[] t = table;current = next = null;index = 0;if (t != null && size > 0) { // advance to first entrydo {} while (index < t.length && (next = t[index++]) == null);}}public final boolean hasNext() {return next != null;}final Node<K,V> nextNode() {Node<K,V>[] t;Node<K,V> e = next;if (modCount != expectedModCount)throw new ConcurrentModificationException();if (e == null)throw new NoSuchElementException();if ((next = (current = e).next) == null && (t = table) != null) {do {} while (index < t.length && (next = t[index++]) == null);}return e;}public final void remove() {Node<K,V> p = current;if (p == null)throw new IllegalStateException();if (modCount != expectedModCount)throw new ConcurrentModificationException();current = null;K key = p.key;removeNode(hash(key), key, null, false, false);expectedModCount = modCount;}}final class KeyIterator extends HashIteratorimplements Iterator<K> {public final K next() { return nextNode().key; }}final class ValueIterator extends HashIteratorimplements Iterator<V> {public final V next() { return nextNode().value; }}final class EntryIterator extends HashIteratorimplements Iterator<Map.Entry<K,V>> {public final Map.Entry<K,V> next() { return nextNode(); }}/* ------------------------------------------------------------ */// spliteratorsstatic class HashMapSpliterator<K,V> {final HashMap<K,V> map;Node<K,V> current; // current nodeint index; // current index, modified on advance/splitint fence; // one past last indexint est; // size estimateint expectedModCount; // for comodification checksHashMapSpliterator(HashMap<K,V> m, int origin,int fence, int est,int expectedModCount) {this.map = m;this.index = origin;this.fence = fence;this.est = est;this.expectedModCount = expectedModCount;}final int getFence() { // initialize fence and size on first useint hi;if ((hi = fence) < 0) {HashMap<K,V> m = map;est = m.size;expectedModCount = m.modCount;Node<K,V>[] tab = m.table;hi = fence = (tab == null) ? 0 : tab.length;}return hi;}public final long estimateSize() {getFence(); // force initreturn (long) est;}}static final class KeySpliterator<K,V>extends HashMapSpliterator<K,V>implements Spliterator<K> {KeySpliterator(HashMap<K,V> m, int origin, int fence, int est,int expectedModCount) {super(m, origin, fence, est, expectedModCount);}public KeySpliterator<K,V> trySplit() {int hi = getFence(), lo = index, mid = (lo + hi) >>> 1;return (lo >= mid || current != null) ? null :new KeySpliterator<>(map, lo, index = mid, est >>>= 1,expectedModCount);}public void forEachRemaining(Consumer<? super K> action) {int i, hi, mc;if (action == null)throw new NullPointerException();HashMap<K,V> m = map;Node<K,V>[] tab = m.table;if ((hi = fence) < 0) {mc = expectedModCount = m.modCount;hi = fence = (tab == null) ? 0 : tab.length;}elsemc = expectedModCount;if (tab != null && tab.length >= hi &&(i = index) >= 0 && (i < (index = hi) || current != null)) {Node<K,V> p = current;current = null;do {if (p == null)p = tab[i++];else {action.accept(p.key);p = p.next;}} while (p != null || i < hi);if (m.modCount != mc)throw new ConcurrentModificationException();}}public boolean tryAdvance(Consumer<? super K> action) {int hi;if (action == null)throw new NullPointerException();Node<K,V>[] tab = map.table;if (tab != null && tab.length >= (hi = getFence()) && index >= 0) {while (current != null || index < hi) {if (current == null)current = tab[index++];else {K k = current.key;current = current.next;action.accept(k);if (map.modCount != expectedModCount)throw new ConcurrentModificationException();return true;}}}return false;}public int characteristics() {return (fence < 0 || est == map.size ? Spliterator.SIZED : 0) |Spliterator.DISTINCT;}}static final class ValueSpliterator<K,V>extends HashMapSpliterator<K,V>implements Spliterator<V> {ValueSpliterator(HashMap<K,V> m, int origin, int fence, int est,int expectedModCount) {super(m, origin, fence, est, expectedModCount);}public ValueSpliterator<K,V> trySplit() {int hi = getFence(), lo = index, mid = (lo + hi) >>> 1;return (lo >= mid || current != null) ? null :new ValueSpliterator<>(map, lo, index = mid, est >>>= 1,expectedModCount);}public void forEachRemaining(Consumer<? super V> action) {int i, hi, mc;if (action == null)throw new NullPointerException();HashMap<K,V> m = map;Node<K,V>[] tab = m.table;if ((hi = fence) < 0) {mc = expectedModCount = m.modCount;hi = fence = (tab == null) ? 0 : tab.length;}elsemc = expectedModCount;if (tab != null && tab.length >= hi &&(i = index) >= 0 && (i < (index = hi) || current != null)) {Node<K,V> p = current;current = null;do {if (p == null)p = tab[i++];else {action.accept(p.value);p = p.next;}} while (p != null || i < hi);if (m.modCount != mc)throw new ConcurrentModificationException();}}public boolean tryAdvance(Consumer<? super V> action) {int hi;if (action == null)throw new NullPointerException();Node<K,V>[] tab = map.table;if (tab != null && tab.length >= (hi = getFence()) && index >= 0) {while (current != null || index < hi) {if (current == null)current = tab[index++];else {V v = current.value;current = current.next;action.accept(v);if (map.modCount != expectedModCount)throw new ConcurrentModificationException();return true;}}}return false;}public int characteristics() {return (fence < 0 || est == map.size ? Spliterator.SIZED : 0);}}static final class EntrySpliterator<K,V>extends HashMapSpliterator<K,V>implements Spliterator<Map.Entry<K,V>> {EntrySpliterator(HashMap<K,V> m, int origin, int fence, int est,int expectedModCount) {super(m, origin, fence, est, expectedModCount);}public EntrySpliterator<K,V> trySplit() {int hi = getFence(), lo = index, mid = (lo + hi) >>> 1;return (lo >= mid || current != null) ? null :new EntrySpliterator<>(map, lo, index = mid, est >>>= 1,expectedModCount);}public void forEachRemaining(Consumer<? super Map.Entry<K,V>> action) {int i, hi, mc;if (action == null)throw new NullPointerException();HashMap<K,V> m = map;Node<K,V>[] tab = m.table;if ((hi = fence) < 0) {mc = expectedModCount = m.modCount;hi = fence = (tab == null) ? 0 : tab.length;}elsemc = expectedModCount;if (tab != null && tab.length >= hi &&(i = index) >= 0 && (i < (index = hi) || current != null)) {Node<K,V> p = current;current = null;do {if (p == null)p = tab[i++];else {action.accept(p);p = p.next;}} while (p != null || i < hi);if (m.modCount != mc)throw new ConcurrentModificationException();}}public boolean tryAdvance(Consumer<? super Map.Entry<K,V>> action) {int hi;if (action == null)throw new NullPointerException();Node<K,V>[] tab = map.table;if (tab != null && tab.length >= (hi = getFence()) && index >= 0) {while (current != null || index < hi) {if (current == null)current = tab[index++];else {Node<K,V> e = current;current = current.next;action.accept(e);if (map.modCount != expectedModCount)throw new ConcurrentModificationException();return true;}}}return false;}public int characteristics() {return (fence < 0 || est == map.size ? Spliterator.SIZED : 0) |Spliterator.DISTINCT;}}/* ------------------------------------------------------------ */// LinkedHashMap support/** The following package-protected methods are designed to be* overridden by LinkedHashMap, but not by any other subclass.* Nearly all other internal methods are also package-protected* but are declared final, so can be used by LinkedHashMap, view* classes, and HashSet.*/// Create a regular (non-tree) nodeNode<K,V> newNode(int hash, K key, V value, Node<K,V> next) {return new Node<>(hash, key, value, next);}// For conversion from TreeNodes to plain nodesNode<K,V> replacementNode(Node<K,V> p, Node<K,V> next) {return new Node<>(p.hash, p.key, p.value, next);}// Create a tree bin nodeTreeNode<K,V> newTreeNode(int hash, K key, V value, Node<K,V> next) {return new TreeNode<>(hash, key, value, next);}// For treeifyBinTreeNode<K,V> replacementTreeNode(Node<K,V> p, Node<K,V> next) {return new TreeNode<>(p.hash, p.key, p.value, next);}/*** Reset to initial default state. Called by clone and readObject.*/void reinitialize() {table = null;entrySet = null;keySet = null;values = null;modCount = 0;threshold = 0;size = 0;}// Callbacks to allow LinkedHashMap post-actionsvoid afterNodeAccess(Node<K,V> p) { }void afterNodeInsertion(boolean evict) { }void afterNodeRemoval(Node<K,V> p) { }// Called only from writeObject, to ensure compatible ordering.void internalWriteEntries(java.io.ObjectOutputStream s) throws IOException {Node<K,V>[] tab;if (size > 0 && (tab = table) != null) {for (int i = 0; i < tab.length; ++i) {for (Node<K,V> e = tab[i]; e != null; e = e.next) {s.writeObject(e.key);s.writeObject(e.value);}}}}/* ------------------------------------------------------------ */// Tree bins/*** Entry for Tree bins. Extends LinkedHashMap.Entry (which in turn* extends Node) so can be used as extension of either regular or* linked node.*/static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {TreeNode<K,V> parent; // red-black tree linksTreeNode<K,V> left;TreeNode<K,V> right;TreeNode<K,V> prev; // needed to unlink next upon deletionboolean red;TreeNode(int hash, K key, V val, Node<K,V> next) {super(hash, key, val, next);}/*** Returns root of tree containing this node.*/final TreeNode<K,V> root() {for (TreeNode<K,V> r = this, p;;) {if ((p = r.parent) == null)return r;r = p;}}/*** Ensures that the given root is the first node of its bin.*/static <K,V> void moveRootToFront(Node<K,V>[] tab, TreeNode<K,V> root) {int n;if (root != null && tab != null && (n = tab.length) > 0) {int index = (n - 1) & root.hash;TreeNode<K,V> first = (TreeNode<K,V>)tab[index];if (root != first) {Node<K,V> rn;tab[index] = root;TreeNode<K,V> rp = root.prev;if ((rn = root.next) != null)((TreeNode<K,V>)rn).prev = rp;if (rp != null)rp.next = rn;if (first != null)first.prev = root;root.next = first;root.prev = null;}assert checkInvariants(root);}}/*** Finds the node starting at root p with the given hash and key.* The kc argument caches comparableClassFor(key) upon first use* comparing keys.*/final TreeNode<K,V> find(int h, Object k, Class<?> kc) {TreeNode<K,V> p = this;do {int ph, dir; K pk;TreeNode<K,V> pl = p.left, pr = p.right, q;if ((ph = p.hash) > h)p = pl;else if (ph < h)p = pr;else if ((pk = p.key) == k || (k != null && k.equals(pk)))return p;else if (pl == null)p = pr;else if (pr == null)p = pl;else if ((kc != null ||(kc = comparableClassFor(k)) != null) &&(dir = compareComparables(kc, k, pk)) != 0)p = (dir < 0) ? pl : pr;else if ((q = pr.find(h, k, kc)) != null)return q;elsep = pl;} while (p != null);return null;}/*** Calls find for root node.*/final TreeNode<K,V> getTreeNode(int h, Object k) {return ((parent != null) ? root() : this).find(h, k, null);}/*** Tie-breaking utility for ordering insertions when equal* hashCodes and non-comparable. We don't require a total* order, just a consistent insertion rule to maintain* equivalence across rebalancings. Tie-breaking further than* necessary simplifies testing a bit.*/static int tieBreakOrder(Object a, Object b) {int d;if (a == null || b == null ||(d = a.getClass().getName().compareTo(b.getClass().getName())) == 0)d = (System.identityHashCode(a) <= System.identityHashCode(b) ?-1 : 1);return d;}/*** Forms tree of the nodes linked from this node.*/final void treeify(Node<K,V>[] tab) {TreeNode<K,V> root = null;for (TreeNode<K,V> x = this, next; x != null; x = next) {next = (TreeNode<K,V>)x.next;x.left = x.right = null;if (root == null) {x.parent = null;x.red = false;root = x;}else {K k = x.key;int h = x.hash;Class<?> kc = null;for (TreeNode<K,V> p = root;;) {int dir, ph;K pk = p.key;if ((ph = p.hash) > h)dir = -1;else if (ph < h)dir = 1;else if ((kc == null &&(kc = comparableClassFor(k)) == null) ||(dir = compareComparables(kc, k, pk)) == 0)dir = tieBreakOrder(k, pk);TreeNode<K,V> xp = p;if ((p = (dir <= 0) ? p.left : p.right) == null) {x.parent = xp;if (dir <= 0)xp.left = x;elsexp.right = x;root = balanceInsertion(root, x);break;}}}}moveRootToFront(tab, root);}/*** Returns a list of non-TreeNodes replacing those linked from* this node.*/final Node<K,V> untreeify(HashMap<K,V> map) {Node<K,V> hd = null, tl = null;for (Node<K,V> q = this; q != null; q = q.next) {Node<K,V> p = map.replacementNode(q, null);if (tl == null)hd = p;elsetl.next = p;tl = p;}return hd;}/*** Tree version of putVal.*/final TreeNode<K,V> putTreeVal(HashMap<K,V> map, Node<K,V>[] tab,int h, K k, V v) {Class<?> kc = null;boolean searched = false;TreeNode<K,V> root = (parent != null) ? root() : this;for (TreeNode<K,V> p = root;;) {int dir, ph; K pk;if ((ph = p.hash) > h)dir = -1;else if (ph < h)dir = 1;else if ((pk = p.key) == k || (k != null && k.equals(pk)))return p;else if ((kc == null &&(kc = comparableClassFor(k)) == null) ||(dir = compareComparables(kc, k, pk)) == 0) {if (!searched) {TreeNode<K,V> q, ch;searched = true;if (((ch = p.left) != null &&(q = ch.find(h, k, kc)) != null) ||((ch = p.right) != null &&(q = ch.find(h, k, kc)) != null))return q;}dir = tieBreakOrder(k, pk);}TreeNode<K,V> xp = p;if ((p = (dir <= 0) ? p.left : p.right) == null) {Node<K,V> xpn = xp.next;TreeNode<K,V> x = map.newTreeNode(h, k, v, xpn);if (dir <= 0)xp.left = x;elsexp.right = x;xp.next = x;x.parent = x.prev = xp;if (xpn != null)((TreeNode<K,V>)xpn).prev = x;moveRootToFront(tab, balanceInsertion(root, x));return null;}}}/*** Removes the given node, that must be present before this call.* This is messier than typical red-black deletion code because we* cannot swap the contents of an interior node with a leaf* successor that is pinned by "next" pointers that are accessible* independently during traversal. So instead we swap the tree* linkages. If the current tree appears to have too few nodes,* the bin is converted back to a plain bin. (The test triggers* somewhere between 2 and 6 nodes, depending on tree structure).*/final void removeTreeNode(HashMap<K,V> map, Node<K,V>[] tab,boolean movable) {int n;if (tab == null || (n = tab.length) == 0)return;int index = (n - 1) & hash;TreeNode<K,V> first = (TreeNode<K,V>)tab[index], root = first, rl;TreeNode<K,V> succ = (TreeNode<K,V>)next, pred = prev;if (pred == null)tab[index] = first = succ;elsepred.next = succ;if (succ != null)succ.prev = pred;if (first == null)return;if (root.parent != null)root = root.root();if (root == null|| (movable&& (root.right == null|| (rl = root.left) == null|| rl.left == null))) {tab[index] = first.untreeify(map); // too smallreturn;}TreeNode<K,V> p = this, pl = left, pr = right, replacement;if (pl != null && pr != null) {TreeNode<K,V> s = pr, sl;while ((sl = s.left) != null) // find successors = sl;boolean c = s.red; s.red = p.red; p.red = c; // swap colorsTreeNode<K,V> sr = s.right;TreeNode<K,V> pp = p.parent;if (s == pr) { // p was s's direct parentp.parent = s;s.right = p;}else {TreeNode<K,V> sp = s.parent;if ((p.parent = sp) != null) {if (s == sp.left)sp.left = p;elsesp.right = p;}if ((s.right = pr) != null)pr.parent = s;}p.left = null;if ((p.right = sr) != null)sr.parent = p;if ((s.left = pl) != null)pl.parent = s;if ((s.parent = pp) == null)root = s;else if (p == pp.left)pp.left = s;elsepp.right = s;if (sr != null)replacement = sr;elsereplacement = p;}else if (pl != null)replacement = pl;else if (pr != null)replacement = pr;elsereplacement = p;if (replacement != p) {TreeNode<K,V> pp = replacement.parent = p.parent;if (pp == null)root = replacement;else if (p == pp.left)pp.left = replacement;elsepp.right = replacement;p.left = p.right = p.parent = null;}TreeNode<K,V> r = p.red ? root : balanceDeletion(root, replacement);if (replacement == p) { // detachTreeNode<K,V> pp = p.parent;p.parent = null;if (pp != null) {if (p == pp.left)pp.left = null;else if (p == pp.right)pp.right = null;}}if (movable)moveRootToFront(tab, r);}/*** Splits nodes in a tree bin into lower and upper tree bins,* or untreeifies if now too small. Called only from resize;* see above discussion about split bits and indices.** @param map the map* @param tab the table for recording bin heads* @param index the index of the table being split* @param bit the bit of hash to split on*/final void split(HashMap<K,V> map, Node<K,V>[] tab, int index, int bit) {TreeNode<K,V> b = this;// Relink into lo and hi lists, preserving orderTreeNode<K,V> loHead = null, loTail = null;TreeNode<K,V> hiHead = null, hiTail = null;int lc = 0, hc = 0;for (TreeNode<K,V> e = b, next; e != null; e = next) {next = (TreeNode<K,V>)e.next;e.next = null;if ((e.hash & bit) == 0) {if ((e.prev = loTail) == null)loHead = e;elseloTail.next = e;loTail = e;++lc;}else {if ((e.prev = hiTail) == null)hiHead = e;elsehiTail.next = e;hiTail = e;++hc;}}if (loHead != null) {if (lc <= UNTREEIFY_THRESHOLD)tab[index] = loHead.untreeify(map);else {tab[index] = loHead;if (hiHead != null) // (else is already treeified)loHead.treeify(tab);}}if (hiHead != null) {if (hc <= UNTREEIFY_THRESHOLD)tab[index + bit] = hiHead.untreeify(map);else {tab[index + bit] = hiHead;if (loHead != null)hiHead.treeify(tab);}}}/* ------------------------------------------------------------ */// Red-black tree methods, all adapted from CLRstatic <K,V> TreeNode<K,V> rotateLeft(TreeNode<K,V> root,TreeNode<K,V> p) {TreeNode<K,V> r, pp, rl;if (p != null && (r = p.right) != null) {if ((rl = p.right = r.left) != null)rl.parent = p;if ((pp = r.parent = p.parent) == null)(root = r).red = false;else if (pp.left == p)pp.left = r;elsepp.right = r;r.left = p;p.parent = r;}return root;}static <K,V> TreeNode<K,V> rotateRight(TreeNode<K,V> root,TreeNode<K,V> p) {TreeNode<K,V> l, pp, lr;if (p != null && (l = p.left) != null) {if ((lr = p.left = l.right) != null)lr.parent = p;if ((pp = l.parent = p.parent) == null)(root = l).red = false;else if (pp.right == p)pp.right = l;elsepp.left = l;l.right = p;p.parent = l;}return root;}static <K,V> TreeNode<K,V> balanceInsertion(TreeNode<K,V> root,TreeNode<K,V> x) {x.red = true;for (TreeNode<K,V> xp, xpp, xppl, xppr;;) {if ((xp = x.parent) == null) {x.red = false;return x;}else if (!xp.red || (xpp = xp.parent) == null)return root;if (xp == (xppl = xpp.left)) {if ((xppr = xpp.right) != null && xppr.red) {xppr.red = false;xp.red = false;xpp.red = true;x = xpp;}else {if (x == xp.right) {root = rotateLeft(root, x = xp);xpp = (xp = x.parent) == null ? null : xp.parent;}if (xp != null) {xp.red = false;if (xpp != null) {xpp.red = true;root = rotateRight(root, xpp);}}}}else {if (xppl != null && xppl.red) {xppl.red = false;xp.red = false;xpp.red = true;x = xpp;}else {if (x == xp.left) {root = rotateRight(root, x = xp);xpp = (xp = x.parent) == null ? null : xp.parent;}if (xp != null) {xp.red = false;if (xpp != null) {xpp.red = true;root = rotateLeft(root, xpp);}}}}}}static <K,V> TreeNode<K,V> balanceDeletion(TreeNode<K,V> root,TreeNode<K,V> x) {for (TreeNode<K,V> xp, xpl, xpr;;) {if (x == null || x == root)return root;else if ((xp = x.parent) == null) {x.red = false;return x;}else if (x.red) {x.red = false;return root;}else if ((xpl = xp.left) == x) {if ((xpr = xp.right) != null && xpr.red) {xpr.red = false;xp.red = true;root = rotateLeft(root, xp);xpr = (xp = x.parent) == null ? null : xp.right;}if (xpr == null)x = xp;else {TreeNode<K,V> sl = xpr.left, sr = xpr.right;if ((sr == null || !sr.red) &&(sl == null || !sl.red)) {xpr.red = true;x = xp;}else {if (sr == null || !sr.red) {if (sl != null)sl.red = false;xpr.red = true;root = rotateRight(root, xpr);xpr = (xp = x.parent) == null ?null : xp.right;}if (xpr != null) {xpr.red = (xp == null) ? false : xp.red;if ((sr = xpr.right) != null)sr.red = false;}if (xp != null) {xp.red = false;root = rotateLeft(root, xp);}x = root;}}}else { // symmetricif (xpl != null && xpl.red) {xpl.red = false;xp.red = true;root = rotateRight(root, xp);xpl = (xp = x.parent) == null ? null : xp.left;}if (xpl == null)x = xp;else {TreeNode<K,V> sl = xpl.left, sr = xpl.right;if ((sl == null || !sl.red) &&(sr == null || !sr.red)) {xpl.red = true;x = xp;}else {if (sl == null || !sl.red) {if (sr != null)sr.red = false;xpl.red = true;root = rotateLeft(root, xpl);xpl = (xp = x.parent) == null ?null : xp.left;}if (xpl != null) {xpl.red = (xp == null) ? false : xp.red;if ((sl = xpl.left) != null)sl.red = false;}if (xp != null) {xp.red = false;root = rotateRight(root, xp);}x = root;}}}}}/*** Recursive invariant check*/static <K,V> boolean checkInvariants(TreeNode<K,V> t) {TreeNode<K,V> tp = t.parent, tl = t.left, tr = t.right,tb = t.prev, tn = (TreeNode<K,V>)t.next;if (tb != null && tb.next != t)return false;if (tn != null && tn.prev != t)return false;if (tp != null && t != tp.left && t != tp.right)return false;if (tl != null && (tl.parent != t || tl.hash > t.hash))return false;if (tr != null && (tr.parent != t || tr.hash < t.hash))return false;if (t.red && tl != null && tl.red && tr != null && tr.red)return false;if (tl != null && !checkInvariants(tl))return false;if (tr != null && !checkInvariants(tr))return false;return true;}}}