HikariCP
1 简介
数据库连接池就是在程序初始化的时候,预先创建一定数量的数据库连接对象,当后续需要数据库连接的时候,如果此时有连接未被使用,那么他就可以直接使用已经创建好的连接,不需要再重新创建新的连接,从而避免频繁的创建以及关闭资源带来的开销。
2 作用
- 资源可以重复利用,避免频繁的建立以及关闭连接
- 响应速度快,可以直接从数据库连接池当中获取连接对象
- 可以防止服务器崩溃(限制数据库连接的最大数量)
- 可以避免数据库连接泄露(定时检测,打印警告日志)
3 实现方式
添加maven的依赖
<dependency><groupId>com.zaxxer</groupId><artifactId>HikariCP</artifactId><version>3.4.5</version>
</dependency>
进行配置(如果是采用的是SpringBoot):
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
spring.datasource.url=jdbc:mysql://127.0.0.1:3306/datebook?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&useSSL=false&zeroDateTimeBehavior=convertToNull
spring.datasource.username=root
spring.datasource.password=root
spring.datasource.type=com.zaxxer.hikari.HikariDataSource
spring.datasource.hikari.minimum-idle=15
spring.datasource.hikari.maximum-pool-size=15
spring.datasource.hikari.auto-commit=true
spring.datasource.hikari.idle-timeout=30000
spring.datasource.hikari.pool-name=DatebookHikariCP
spring.datasource.hikari.max-lifetime=1800000
spring.datasource.hikari.connection-timeout=30000
4 主要参数
| 参数 | 描述 | 默认值 |
| url | jdbc访问地址 | - |
| driver-name-class | 驱动类 | - |
| username | 用户名 | - |
| password | 密码 | - |
| autocommit | 是否自动提交 | true |
| connectionTimeOut | 连接超时时间(毫秒) 规定时间内没有连接可用,抛出SQLException | 30000 |
| idleTimeout | 空闲超时时间(毫秒) 只有在minimumIdle<maximumPoolSize时候生效,超时的可能被回收,数值0表示空闲连接永不回收 | 600000 |
| maxLifetime | 连接池中的连接的最长生命周期(毫秒),此参数必须小于数据库连接的最大空闲时间(time_wait),数值0表示不限制 | 1800000 |
| connectionTestQuery | 连接池每分配一条连接前执行的查询语句(如:SELECT 1),以验证该连接是否是有效的 | - |
| minimumIdle | 最小空闲连接数 | - |
| maximumPoolSize | 连接池中可同时连接的最大连接数 | 10 |
| poolName | 连接池名称,主要用于显示在日志记录和 JMX 管理控制台中 | 自动生成 |
5 优势
1 代码量
相比较其他数据库连接池的代码量,Hikari数据库连接池代码量更少,代码执行效率更高,发生bug概率更小。2 优化代理
利用了第三方的Java字节码修改类库Javassist来生成委托实现动态代理,同时对字节码文件进行了精简以及简化,同时也会触发方法的内联优化,利用此生成动态代理相比较jdk自带的动态代理,其速度更快,而且生成的字节码更少。
方法的内联优化:
方法的内联优化是由JIT编译器在运行时完成的,方法内联的条件:
● 被调用方法是否达到热点数:取决于被调用的次数,次数阈值默认为10000,就是运行时被调用次数超过10000的方法。
● 被调用方法大小是否合适:对于过大的方法,JIT认为是不适合做内联的,这个方法大小阈值是由-XX:FreqInlineSize指定。
方法内联的原理:在函数方法的调用过程中,首先会有一个执行栈,存储当前线程所有活跃的方法以及他们的本地变量和参数,当有一个新的方法被调用的时候,一个新的栈帧会被加到栈顶,分配的本地变量和参数也会存储在这个栈帧,然后执行新的方法,当方法返回的时候,本地方法和参数会被销毁,同时从栈顶移除,如果说是在一个线程当中,方法的嵌套比较多,那么会导致压栈出栈比较频繁,而方法的内联优化其实就是讲被调用的函数代码直接复制到调用函数里面,从而减少因函数调用而开销的资源。
3 自定义数组类型(FastList代替ArrayList)
查找优化:ArrayList在查找数据的时候,首先会检查数组下标是否合法,而FastList当中,直接去除这一个数组下标的检查。
删除优化: 如果说在一个Connection当中,依次建了5个Statement,分别是S1,S2,S3,S4,S5,按照正常编码习惯,关闭的时候应该是S5,S4,S3,S2,S1,ArrayList删除的时候是顺序查找,逆序删除,如果这时候采用ArrayList,效率是很慢的,而FastList是逆序查找,逆序删除,效率有很大的提升
4 自定义集合的类型(ConcurrentBag)
常规的创建一个数据库连接池的思想就是创建两个阻塞队列,一个用来存放空闲连接,一个用来存放正在使用的连接,获取连接也就是将空闲的数据库 连接从空闲队列移动到忙碌队列,关闭连接也就是将数据库连接从忙碌队列移动到空闲队列,这种方案设计的思想就是将并发问题交给阻塞队列,实现简单,但是性能却不理想,在高并发环境下,由于锁的争用对其性能影响很大。 Hikari并没有使用阻塞队列,而是自己实现了一个并发容器ConcurrentBag,他的一个核心设计是使用ThreadLocal来避免部分并发问题,也就是在线程本地存储连接,在ConcurrentBag中有四个关键的属性
private final CopyOnWriteArrayList<T> sharedList; //用于存储所有的数据库连接
private final ThreadLocal<List<Object>> threadList; //线程本地存储的数据库连接
private final SynchronousQueue<T> handoffQueue; //长度为1的消息队列
private final AtomicInteger waiters; //等待数据库连接的等待着数量
属性分析:CopyOnWriteArrayList:是一种线程安全的数据结构,底层数据结构是数组,在获取数据的时候是不加锁的,可以更快的进行查找,但是在修改的时候,他是首先进行加锁,然后将原来的数组复制一份,然后在新复制的数组里面进行修改,最后将引用指向新复制的数组,如果说在修改数据的过程中去查找,那么他读取到的数据是原来旧的那一份。由于在每次修改数据的时候,他都会加锁,并且复制旧的数组,虽然可以保证线程安全,但是对性能影响比较大,所以CopyOnWriteArrayList使用于读多写少的应用场景,而在Hikari当中,大多数数据库连接都是可以复用的,查找频率远远多于修改频率,所以他采用CopyOnWriteArrayList。ThreadLocal:当前线程里面存储一定数量的数据库连接,获取连接的时候首先从ThreadLocal当中获取,这样很大程度上可以避免锁的争用。SynChronousQueue:长度为1的消息队列,如果说是ThreadLocal和CopyOnWriteArrayList里面都没有可用的连接,waiters>=1,这个时候会尝试将新的连接放入到这个队列当中,在Hikari当中,默认采用的是TransferStack非公平锁,也就是多个连接都争先放入到这个队列,放入到队列之后,然后会交给消费者,只有当放入的元素被消费后(从队列中移除),新的连接才会添加到这个队列,在获取元素的时候,如果说是队列当中有元素,会尝试去读,读的时候也是非公平锁抢占式读取,如果读取不到,会一直阻塞。AtomicInteger:原子操作,统计等待数据库连接的等待着数量
6 线程池
有三个线程池:
addConnectionExecutor: ThreadPoolExecutor executor = new ThreadPoolExecutor(1 , 1 , 5 , SECONDS, queue, threadFactory, policy);
核心线程池数量和最大线程池数量都是1,线程池维护线程的空闲时间是5分钟,queue是一个定长的LinkedBlochingQueue,长度是maxPoolSize,threadFactory是创建线程的类,拒绝策略是DiscardOldestPolicy,也就是对拒绝任务不抛弃,而是抛弃队列里面等待最久的一个任务,然后把拒绝任务加到队列。这个线程池主要是用来添加连接到ConcurrentBag里面。
closeConnectionExecutor:ThreadPoolExecutor executor = new ThreadPoolExecutor(1 , 1 , 5 , SECONDS, queue, threadFactory, policy);
核心线程池数量和最大线程池数量都是1,线程池维护线程的空闲时间是5分钟,queue是一个定长的LinkedBlochingQueue,长度是maxPoolSize,threadFactory是创建线程的类,拒绝策略是CallerRunsPolicy,也就是重试添加当前的任务,直到成功。这个线程是用来关闭连接
ScheduledThreadPoolExecutor:
ThreadPoolExecutor executor = new ThreadPoolExecutor(1 , Integer.MAX_VALUE , 5 , SECONDS, queue, threadFactory, policy);
核心线程数一个,最大线程数是214 7483647,线程池维护线程的空闲时间是5分钟,queue是DelayedWorkQueue队列,这个队列是一个阻塞队列,是用数组来存储队列当中的元素,初始长度是16,threadFactory是创建线程的类,拒绝策略是DiscardPolicy,对拒绝任务直接抛弃,没有异常信息,主要用来检测是否有可以回收的连接7 核心类图关系

8 生命周期
取用连接:

HikariPool负责对物理资源进行管理,ConcurrentBag是存放物理连接的,PoolEntry是对物理资源的封装(物理连接的基本信息), HakariPool通过调用borrow方法从ConcurrentBag中取出,返回一个PoolEntry实体,最后调用ProxyFactory工厂类生成HikariProxyConnection。具体执行过程如下:

borrow具体执行方法如下:
在1的操作当中,也就是从ThreadLocal当中获取连接的时候,如果说是拿到这个连接了,那么返回这个连接,同时将此连接从集合当中删除。在2的操作当中,也就是从CopyOnWriteArrayList当中获取连接,他只是将连接返回,不从集合当中删除。在ConcurrentBag里面如果是多个线程同时获取连接,ConcurrentBag利用CAS确保多线程下面的安全问题,也就是首先判断获取到的连接是是不是未使用的,如果是未使用的,则把他的状态更改为在使用。首先是从当前线程的ThreadLocal里面查看是否有可用的连接,因为是在当前线程里面获取连接,这样可以避免锁的竞争,很大程度上提高效率,如果没有可用的,则从共享集合CopyOnWriteArrayList里面查看是否有可用的连接,如果说没有可用的,那么他会去请求IBagItemListener的addBagItem(waitingf)方法去创建一个新的连接将其放入到SynchronousQueue队列当中,如果说是线程池的数量已经达到最大,不能创建,那么此时他将在一定时间内循环查看SynchronousQueue队列当中是否有可用的连接,因为在循环的查看过程中,这个时候如果有可用的连接,他会将其放入到SynchronousQueue队列当中判断连接是否有效: 
归还连接:

生成连接:

HikariCp通过独立的线程池addConnectionExecutor进行新连接的生成,连接生成方法为PoolEntryCreater,之后通过PoolBase封装成PoolEntry,同时提交一个延时任务来关闭连接,延时的时间是事先配置的maxLifeTime,为了避免多个连接在同一时间失效,Hikari设定的延时时间是用maxLifeTime减去一个随机数作为最终的延迟时间,通过ConcurrentBag的add方法添加到共享集合里面 ,当ConCurrentBag存在等待线程,或者有连接被关闭的时候,会触发IBagItemListener的addBagItem(wait)方法,调用PoolEntryCreater进行新连接的生成。
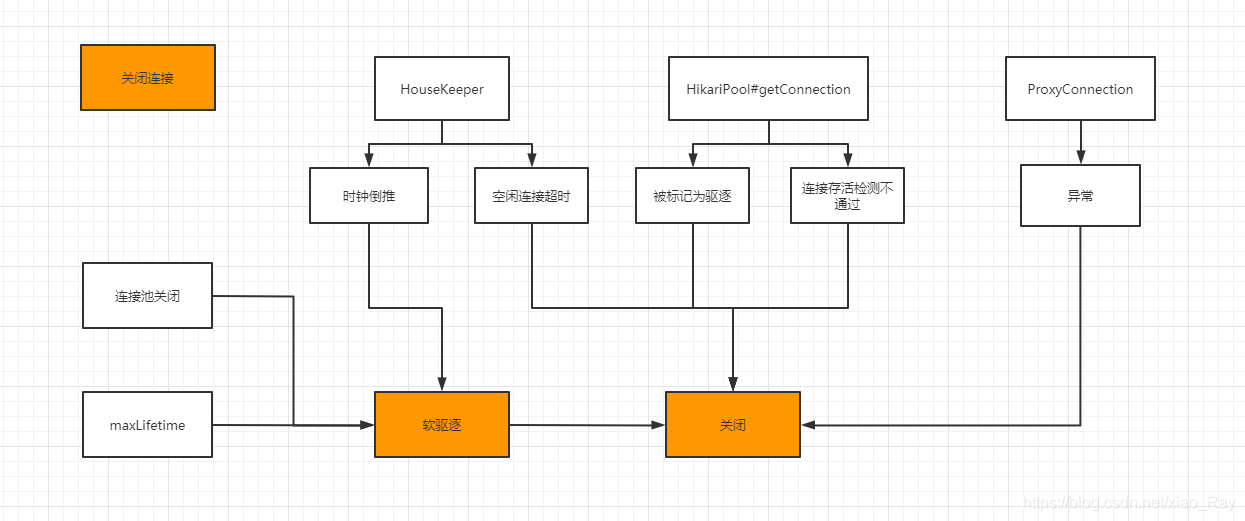
关闭连接:

Hikari通过HikariPool的closeConnection(PoolEntry)进行物理连接的关闭,同时也会取消定时任务的检测,首先就是把连接从发ConcurrentBag里面移除,然后根据需要补充新的连接,关闭物理连接的条件如下:
1:连接断开
2:连接的存活时间超出最大生存时间(maxLifeTime)
3:连接的空闲时间超出最大空闲时间(idleTime)
定时检测回收以及补充新的连接:

HouseKeeper是一个定时任务,首先通过HikariPool的构造器进行初始化,默认是初始化后100毫秒执行,之后隔housekeepingPeriodMs(30s)时间执行,也就是获取ConcurrentBag里面未使用的连接,如果发现时钟倒退(空闲的连接突然被利用,需要重现计算连接的空闲时间),然后退出;如果说是回收连接成功,会调用fillPoll来试图维持空闲连接到minimumldle的数值。总流程图:

9 HikariCP监控设置
在HikariCP当中,Hikari会记录一些关键的指标,比如等待连接的数量,空闲连接数,总连接数,活动连接数,最大连接数,最小连接数,以及连接的创建时间,使用时间等以获取空闲连接数为例: public int getCount(final int state){int count = 0;for (IConcurrentBagEntry e : sharedList) {if (e.getState() == state) {count++;}}return count;}
查看共享集合里里面所有的连接,通过判断连接的状态从而获取到空闲连接的数量,如果是统计时间的话,那么就是在方法执行的前后计算出执行的时间。
问题补充:
1:为什么使用CopyOnWriteArrayList存储连接?
CopyOnWriteArrayList:是一种线程安全的数据结构,底层数据结构是数组,在获取数据的时候是不加锁的,多个线程可以并发进行查找,查找效率高,但是在修改的时候,他是首先进行加锁,然后将原来的数组复制一份,然后在新复制的数组里面进行修改,最后将引用指向新复制的数组,如果说在修改数据的过程中去查找,那么他读取到的数据是原来旧的那一份。由于在每次修改数据的时候,他都会加锁,并且复制旧的数组,虽然可以保证线程安全,但是对性能影响比较大,所以CopyOnWriteArrayList适用于读多写少的应用场景,而在Hikari当中,大多数连接都是可以复用的,查找频率远远多于修改频率,所以他采用CopyOnWriteArrayList。
查找:

修改:

2: SynChronousQueue是如何进行消息传递的?
SynChronousQueue: 长度为1的消息队列,是一种生产者消费者模式,有两个具体的实现类TransferStack(非公平,使用的是栈),TransferQueue(公平 ,使用的是队列),Hikari当中用的是公平的实现类,如果说是ThreadLocal和CopyOnWriteArrayList里面都没有可用的连接,waiters>=1,这个时候多个获取连接的线程按照顺序存储在队列中,等待获取连接,如果此时有空闲的连接,那么试图将此连接放入到生产者队列当中,并且与消费者队列中的首元素(等待时间最久的线程)进行匹配,将数据交给队首的线程,队列后面的消费线程继续等待

3:回收一个连接后,如果当前连接数量小于空闲连接数,会尝试去新建一个连接,那为什么不直接使用即将回收的连接,而是回收以后又尝试去新建连接?
回收连接的对象一般是回收坏死了的连接,不可用的连接,可用连接超过最大生命周期的连接。如果说要使用即将回收的连接,避免回收以后再去创建,那么可以将连接的最大生命周期设置为0(0表示为不限制),这样可用的连接就一直不会被回收,如果说是配置了连接生命周期大于0的某一个数,那么就必须遵从它的规范。
4:threadLocal当中存储的连接是否有可能会造成内存泄露?
通过配置,可以让threadLocal当中存储的连接是弱引用,当发生GC的时候,回收threadLocal当中的连接,但是默认情况下,threadLocal当中存储的都是强引用,有可能会造成内存泄露的可能(在tomcat应用中,提供了发现内存泄露的功能,可以避免这种情况),但是为了更高的效率,采用强引用是值得的,毕竟threadlocal当中存储的连接是有上限的,可以避免对象过多。