自适应Huffman编码,可用初始编码表(数字音视频技术,实验二)
如果你已经理解了 自适应Huffman编码 ,那么你不应该浪费时间在无聊的实验上
实验目的
1、深入掌握自适应Huffman编码的原理
2、掌握自适应Huffman编码算法的实现过程
3、掌握和熟悉利用编程语言实现自适应Huffman编码器和解码器
实验要求
1、实现编码器,对输入字符给出相应的编码结果;
2、实现解码器,对步骤1中的编码结果进行解码;
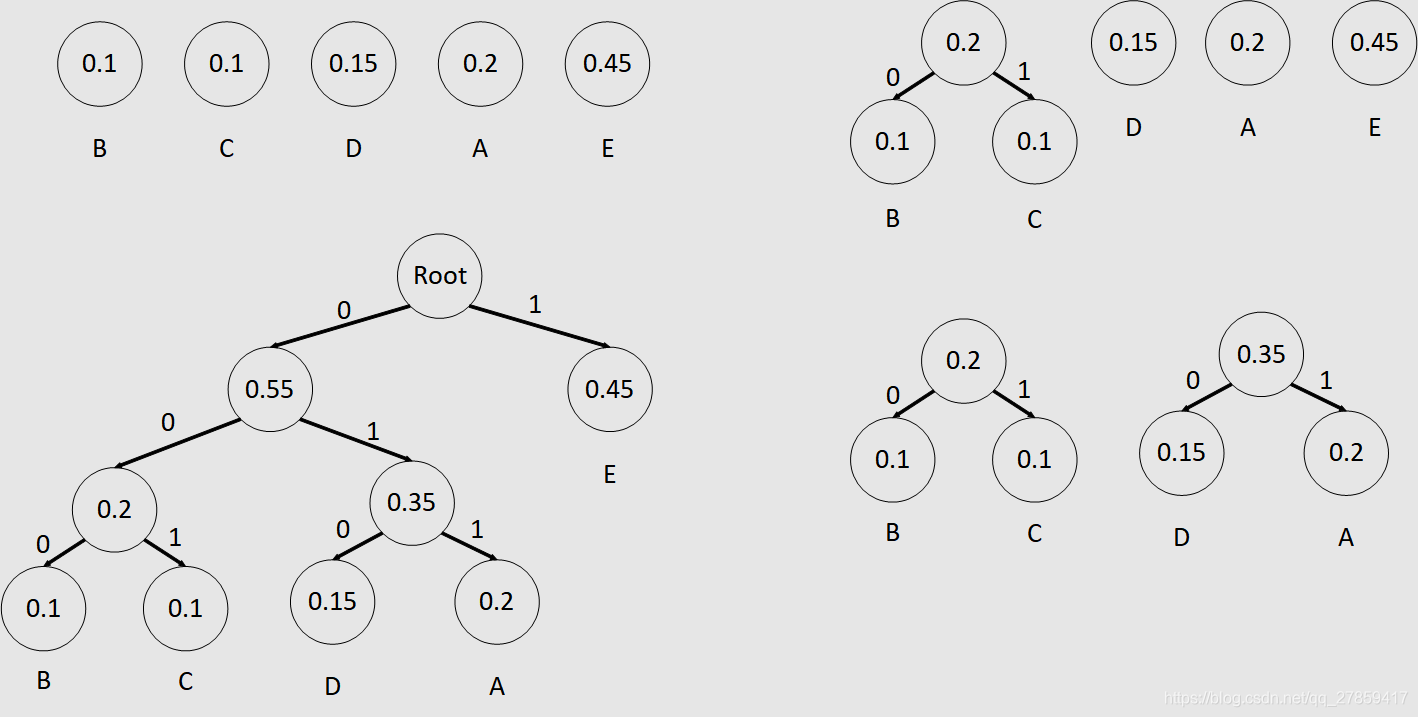
3、请使用初始编码表如下:

4、对字符串ABBCADAD进行编码;
5、截图显示编码中间结果,并保证最终解码结果正确;
6、编辑程序说明文档。
实验步骤
附实验代码及说明文档
实验体会
记录实验过程中碰到的问题及解决方法、最终实验结果。
实现代码:
cpp文件,main函数里包含初始编码表 代码片.
#include "huffmanTree.h"
#include <map>
map<char, string> initCode;BinaryTree::BinaryTree(int num, int weight)
{p_root = new Node(nullptr, nullptr, nullptr);p_root->num = num; //节点的序号p_root->weight = weight; //节点的权重值
}BinaryTree::~BinaryTree()
{deleteNode(p_root);
}bool BinaryTree::swap(Node * p_nodeA, Node * p_nodeB)
{if (p_nodeA == nullptr || p_nodeB == nullptr || p_nodeA == p_nodeB)return false;Node *pTemp;if (getBrotherState(p_nodeA) == LeftChild) { //如果A节点是左孩子if (getBrotherState(p_nodeB) == LeftChild) { // 如果B节点是左孩子pTemp = p_nodeA->p_parent->p_left;p_nodeA->p_parent->p_left = p_nodeB->p_parent->p_left;p_nodeB->p_parent->p_left = pTemp;}else {pTemp = p_nodeA->p_parent->p_left;p_nodeA->p_parent->p_left = p_nodeB->p_parent->p_right;p_nodeB->p_parent->p_right = pTemp;}}else {if (getBrotherState(p_nodeB) == LeftChild) {pTemp = p_nodeA->p_parent->p_right;p_nodeA->p_parent->p_right = p_nodeB->p_parent->p_left;p_nodeB->p_parent->p_left = pTemp;}else {pTemp = p_nodeA->p_parent->p_right;p_nodeA->p_parent->p_right = p_nodeB->p_parent->p_right;p_nodeB->p_parent->p_right = pTemp;}}pTemp = p_nodeA->p_parent;p_nodeA->p_parent = p_nodeB->p_parent;p_nodeB->p_parent = pTemp;return true;}bool BinaryTree::addNode(Node * p_parent, Node * p_child, Brother brotherState)
{if (p_parent == nullptr || p_child == nullptr)return false;if (brotherState == LeftChild) { if (p_parent->p_left != nullptr) {std::cout << "error:left child exist!" << std::endl;return false;//如果父节点有左孩子,则不能添加到左孩子位置}p_parent->p_left = p_child;//否则可以添加}else if (brotherState == RightChild) { if (p_parent->p_right != nullptr) {std::cout << "error:right child exist!" << std::endl;return false;//如果父节点有右孩子,则不能添加到右孩子位置}p_parent->p_right = p_child;//否则可以添加}else {std::cout << "error:brotherState is wrong!" << std::endl;//读取位置信息错误return false;}p_child->p_parent = p_parent;return true;
}bool BinaryTree::isAncestor(Node * p_nodeChild, Node * p_nodeAncestor)
{while (p_nodeChild != p_root) {if (p_nodeChild == p_nodeAncestor) {return true;}else {p_nodeChild = p_nodeChild->p_parent;}}return false;
}void BinaryTree::deleteNode(Node *p_node)
{if (p_node->p_left != nullptr) {deleteNode(p_node->p_left);}if (p_node->p_right != nullptr) {deleteNode(p_node->p_right);}delete p_node;
}BinaryTree::Brother BinaryTree::getBrotherState(Node *p_node)
{if (p_node->p_parent->p_left == p_node) {return LeftChild;}else {return RightChild;}
}HuffmanTree::HuffmanTree() :tree(0, 0)
{sum = 1;
}string HuffmanTree::getHuffmanCode(Node *p_n)
{std::string huffmanCode = "";std::stack<Node *> stack;std::deque<char> code;if (p_n == tree.getRoot())return "0";while (p_n != tree.getRoot()) {if (tree.getBrotherState(p_n) == tree.LeftChild) {code.push_back('0');}else {code.push_back('1');}p_n = p_n->p_parent;}while (!code.empty()) {huffmanCode += code.back();code.pop_back();}return huffmanCode;
}Node * HuffmanTree::findLarge(Node *p_node)
{std::stack<Node *> stack;Node *p = tree.getRoot();Node *large = p;while (p || !stack.empty()) {if (p != nullptr) {stack.push(p);if (p->weight == p_node->weight) {//如果large不在同权重下,则置large为pif (large->weight != p->weight) {large = p;}//同权重下的large比p小,则置large为pelse if (large->num > p->num) {large = p;}}p = p->p_left;}else {p = stack.top();stack.pop();p = p->p_right;}}if (large == tree.getRoot()) {return p_node;}return large;
}void HuffmanTree::encode( string input)
{char cbuffer;Node *nyt = tree.getRoot();bool exist = false;for (int i = 0; i < input.length(); i++) { cbuffer = input[i]; exist = false;string code;auto existNode = buffers.begin(); for (existNode; existNode != buffers.end(); existNode++) {if (existNode->key == cbuffer) {code = existNode->value;exist = true;cout << cbuffer << " 在树中存在,编码为: " << existNode->value << endl; break;}}if (exist) { Node *root = existNode->p;weightAdd(root);}else {Node *c = new Node(nullptr, nullptr, nyt);c->num = sum++;c->weight = 1;Node *NYT = new Node(nullptr, nullptr, nyt);NYT->num = sum++;NYT->weight = 0;cout << "\n NYT:" << getHuffmanCode(nyt) << endl;tree.addNode(nyt, NYT, BinaryTree::LeftChild);tree.addNode(nyt, c, BinaryTree::RightChild);nyt->weight = 1;cout << cbuffer << "首次出现,编码为:"<< initCode.at(cbuffer) << endl;charMap* new_cm = new charMap();new_cm->key = cbuffer;new_cm->p = nyt->p_right;new_cm->value = getHuffmanCode(nyt->p_right);buffers.push_back(*new_cm);Node *root = nyt->p_parent;weightAdd(root);nyt = nyt->p_left;}}}void HuffmanTree::weightAdd(Node * p_node)
{while (p_node != nullptr) {Node* large = findLarge(p_node);if (large != p_node && !tree.isAncestor(p_node, large)) { tree.swap(large, p_node);int temp;temp = large->num;large->num = p_node->num;p_node->num = temp;for (auto iterator = buffers.begin(); iterator != buffers.end(); iterator++) {iterator->value = getHuffmanCode(iterator->p);}}p_node->weight++; p_node = p_node->p_parent;}
}void HuffmanTree::decode(string input)
{Node *nyt = tree.getRoot();int p = 0;int l = 1;string temp;bool exit = false;for (;p+l<= input.length();){exit = false;temp = input.substr(p, l);cout << "\n循环: " << temp ;//如果是NYT,说明有新的if (temp == getHuffmanCode(nyt)) {p+=l;l = 5;temp = input.substr(p, l);//在字典中寻找对应值for (auto iter = initCode.begin(); iter != initCode.end(); ++iter) {string cur = iter->second;if (cur == temp){//找到了就加新的cout << " 新码的:" << iter->first << endl;Node *c = new Node(nullptr, nullptr, nyt);c->num = sum++;c->weight = 1;Node *NYT = new Node(nullptr, nullptr, nyt);NYT->num = sum++;NYT->weight = 0;tree.addNode(nyt, NYT, BinaryTree::LeftChild);tree.addNode(nyt, c, BinaryTree::RightChild);nyt->weight = 1;charMap* new_cm = new charMap();new_cm->key = iter->first;new_cm->p = nyt->p_right;new_cm->value = getHuffmanCode(nyt->p_right);buffers.push_back(*new_cm);//依次增加权重Node *root = nyt->p_parent;weightAdd(root);//设置新的nyt节点为原nyt节点的左孩子nyt = nyt->p_left;}}p += l;l = 1;exit = true;}else//如果不是NYT,就在树里面找{auto existNode = buffers.begin();for (existNode; existNode != buffers.end(); existNode++) {if (existNode->value == temp) {//找到cout << " 在树中存在,为: " << existNode->key << endl;Node *root = existNode->p;weightAdd(root);p += l;l = 1;exit = true;break;}}}//如果即不再树中也不在字典中,l++if(!exit)l++;}}//主函数程序
int main()
{HuffmanTree huff;//这个字典是初始编码表initCode['A'] = "00001";initCode['B'] = "00010";initCode['C'] = "00011";initCode['D'] = "00100";string input = "ABBCADAD";huff.encode(input);//进行编码的函数//以下是解码函数HuffmanTree dhuff;dhuff.decode("0000010000100100000110110000100111001");system("PAUSE");return 0;
}
.h头文件 代码片.
#pragma once
#include <fstream>
#include<iostream>
#include<vector>
#include<queue>
#include<stack>
#include<string>using namespace std;struct Node {int weight; int num; Node* p_left; Node* p_right; Node* p_parent; Node(Node* p_left, Node* p_right, Node* p_parent) : p_left(p_left), p_right(p_right), p_parent(p_parent) {};
};class BinaryTree
{
public:enum Brother { LeftChild, RightChild };BinaryTree(int num = 0, int weight = 0);~BinaryTree();bool swap(Node* p_nodeA, Node* p_nodeB);bool addNode(Node* p_parent, Node* p_child, Brother brotherState);Node* findNode(string in);void deleteNode(Node *p_node);Node* getRoot() { return p_root; }Brother getBrotherState(Node *p_node);bool isAncestor(Node* p_nodeChild, Node* p_nodeAncestor);
private:Node *p_root;};class HuffmanTree
{
public:int sum;HuffmanTree();void encode(string input);void weightAdd(Node* p_node);void decode(string input);BinaryTree tree;struct charMap {char key;std::string value;Node* p;};vector<charMap> buffers;string getHuffmanCode(Node *p);Node * findLarge(Node *);}; - 源代码修改自https://blog.csdn.net/qq_36533706/article/details/80381457?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522163819021616780366596114%2522%252C%2522scm%2522%253A%252220140713.130102334…%2522%257D&request_id=163819021616780366596114&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2allsobaiduend~default-2-80381457.first_rank_v2_pc_rank_v29&utm_term=%E8%87%AA%E9%80%82%E5%BA%94Huffman%E7%BC%96%E7%A0%81&spm=1018.2226.3001.4187