文章目录
- 背景
- yolo v4 中的空间金字塔池化(Space Pyramid Pool, SPP)模块和路径聚合网络(Path Aggregation Network, PANet)的结构
- SPP 模块
- Abstract
- Introduction
- Deep Networks with Spatial Paramid Pooling
- Training the Network
- SPP-Net for Image Classification
- SPP-Net for Object Detection
- Detection Algorithm
- 参考
背景
在yolo v5 中有很多策略包:
1)增大模型感受野:SPP、ASPP等
2)引入注意力机制:SE、SAM
3)特征集成:PAN,BiFPN
4)激活函数改进:Swish、Mish
5)后处理方法改进:soft NMS、DIoU NMS
yolo v4 中的空间金字塔池化(Space Pyramid Pool, SPP)模块和路径聚合网络(Path Aggregation Network, PANet)的结构
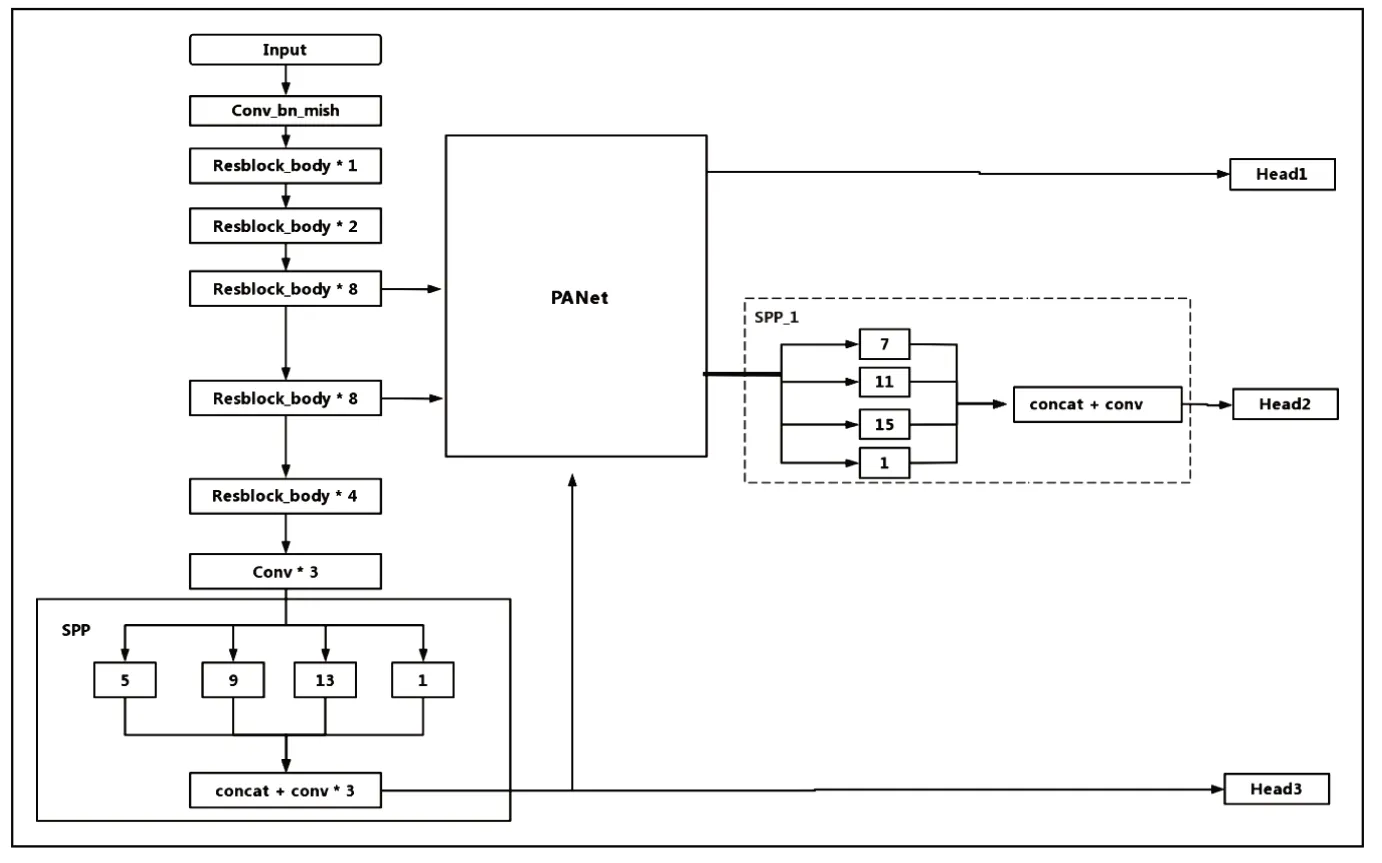
yolo v4 颈部网络采用了空间金字塔池化(Space Pyramid Pool, SPP)模块和路径聚合网络(Path Aggregation Network, PANet)的结构。
主要是用于对特征进行融合。SPP网络作为Neck的附加模块,采用四种不同尺度的最大化操作:1×1,5×5,9×9,13×13,对上层输出的feature map进行处理,再将不同尺度的特征图进行Concat操作。该模块显著的增加了主干特征的接收范围,并且将上下文特征信息分离出来。
FPN+PAN结构,FPN是自顶向下,将高层的特征通过上采用的方式进行传递融合,得到进行预测的特征图。而Neck这部分,除了FPN外,还在此基础上添加了一个自底向上的特征金字塔,其中包含两个PAN结构。避免了在传递的过程中出现信息丢失的问题,提高了网络预测的准确性。
1.2 SPPnet
卷积神经网络(CNN)通常由卷积层和全连接层组成。卷积层不需要输入数据的大小。然而,第一个完全连接的层要求输入大小必须是固定的。以VGG网络16为例,其输入大小固定为224×224,这在一定程度上限制了模型的泛化性能和应用场景。
SPP结构是在CSPDarknet53最后一个特征层之后,在对最后一个特征层进行三次卷积后,用四个不同尺寸的最大池化进行处理,四个不同尺寸的池化核大小分别为13x13、9x9、5x5、1x1。YOLOv4中通过添加SPP结构,增大感受野,分离出最重要的上下文特征,并且不会降低检测速度。
1.3 CSPNet 易于实现,且具有很好的通用性,可以构造在 ResNet、ResNeXt和 DenseNet等 网 络体系中。CSPDar knet53是在 Darknet53基础上,参考了CSPNet,其主干主要包括五个CSP模块。CSP模块先是将特征图分成两部分,一个部分是Resblock的结构,分别迭代1,2,8,8,4次,另一个部分是经过少量操作的残差边,最后进行通道叠加操作,主要目的是能够实现更丰富的梯度组合,同时减少计算量,用于解决需要大量推理计算的问题。
1.4 PANet
PANet的概念在Mask R-CNN中也存在。PANet是对特征金字塔网络(Feature Pyramid Network, FPN)的进一步改进。FPNet采用的是自顶向下的传输模式,将高层特征传入下层。因此底层的特征无法对高层特征产生影响。并且在FPNet的这种传输模式中,顶部的信息传入底部是逐层传输的,这也导致了计算量增大,所以提出了PANet来解决这一问题。
在PANet中引入了自底层向顶层向上传播信息的增强结构路径,避免了在传递过程中部分信息丢失的问题,并使得底层的信息更容易到达高层顶部。在加入了PANet后,在进行从顶层向下层的特征融合后,再进行自下层向顶层的特征融合,这样的特征传递方式穿越的特征图数量得到了大大的减少,因此减少了计算量。
SPP 模块
之前有个文章《3分钟理解Spatial Pyramid Pooling层 (SPP层)》,今天就论文看看具体情况。
这次是转载文章(3)SPP-Net:精进特征提取 + 开拓多尺度训练
论文:Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition 2015年
Abstract
现有的(传统的) CNNs 由于有全连接层所以必须需要固定输入图片的尺寸,比如 224 × 224 。本文为传统的网络结构增加了一个池化策略,即空间金字塔池化,spatial pyramid pooling,来突破全连接层对整个网络输入图像的约束。无论输入图像的尺寸是多少,SPP-Net 能够产生一个固定长度的特征向量,且能够适应形变,在分类和物体检测任务中都有很好的表现(妈妈再也不用担心我训练网络要被动地特意去 crop 或者 warp 啦~当然你还是可以主动选择用这个来做 data augmentation)。
和“前辈” RCNN 有哪些异同?相同点就是 pipeline 仍然是“缝合怪”,区域推荐 + 特征提取 + 分类 + 候选框回归 4 个部分每个部分都各干各的,散装的,拼在一块儿而已。而最后分类和候选框回归更是一模一样。
上面主要简单说相同点,现在重点说下提升。上一篇也有提过,RCNN 使用 Selective Search 提取了 2000 个 region proposal 之后,是使用 CNN 遍历这 2000 个 region分别依次提取特征的。这里肯定就限制了它的速度,而且还必须把各个对应的 region 强行 resize 送到 CNN 中,进一步约束了特征提取的效果(可能存在很多失真的情况),而且前面遍历 2000 也限制了后面使用更加复杂的特征提取方法(因为会更慢)。而 SPP-Net 中在这个部分的改进是,拿到 2000 个 region proposal 之后,CNN 提取特征是一起提取的,就是遍历全图一次,然后具体到针对某个 region 做分类的时候,映射到全图的 feature map 上拿这个 region 对应的那部分特征图(爱多大就多大无所谓,因为有空间金字塔池化可以拿到固定长度特征向量嘛),拿到这个 region 固定长度特征了再做分类就好了。
还有别的新颖的地方吗?应该是空间金字塔池化带来的多尺度训练神经网络的方法,通过将图片划分成一些尺寸等级,逐一替换尺寸等级来训练网络。
Introduction
传统 CNN 网络可以大致分为卷积和全连接两部分,其中卷积层是不挑输入图像尺寸的,完全是全连接的存在,才导致整个网络必须固定输入图像的大小。
空间金字塔池化原本就存在,是一种传统图像处理方法理论,算是一种词袋模型的拓展。它把图像的特征分成了不同的粒度有粗有细,组合在一起输出(相比单一尺度的特征要更能表达/代表原图)。
空间金字塔池化的加入,使得模型在预测/测试时可以不限定输入图像的大小,同时在训练阶段,也允许模型实现多尺度训练,这一点很有利于增强尺度不变性并降低过拟合的风险。
Deep Networks with Spatial Paramid Pooling
Convolutional Layers and Feature Maps, 按照 AlexNet 网络架构来讲,一共可以算作 7 层 = 5 层 卷积 + 2 层全连接,后面会根据情况跟上 N + 1 类的 softmax。卷积之后生成的通道图就是 feature map。
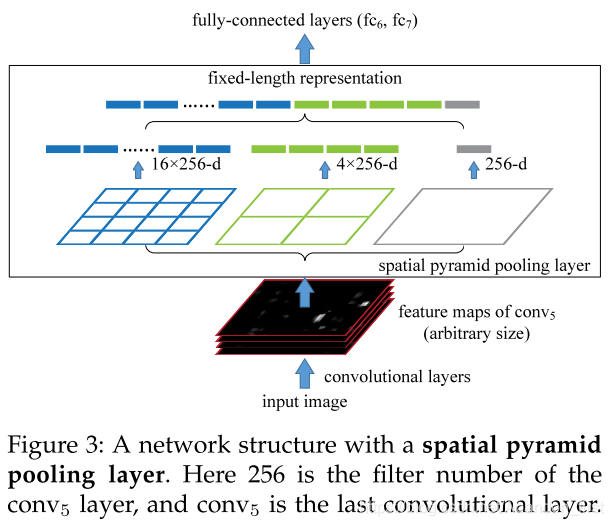
The Spatial Pyramid Pooling Layer
与已有的网络模型中的 pooling 相比,空间金字塔池化不会受 feature map 的大小影响,是按照 4 bin 16 bin 这样确定的,而不是根据 pooling 层中的 stride 来确定的。
SPP-Net 用空间金字塔池化替代掉了 AlexNet 中最后一个卷积输出的 feature map 后面紧跟的 pool5,意思就是用的 conv5 的 feature map,论文用的最大池化。(插播:表格结构识别里面网格池化跟 SPP-Net 有点像)
这个在多个尺度的图像上提取特征 SIFT 也用得很 6 了。
Training the Network
这里本来应该是随机输入尺寸变化的图像来训练网络,但是考虑到高效地利用 GPU 计算资源,最好还是同样尺寸的一起训练。
关于训练多尺度,论文此方面的工作也是逐步展开的(猫猫祟祟),先是固定输入 224 × 224,增加了三个变化尺寸的普通 pooling 层,发现 OK;然后直接变数据训练了另外一个一模一样的网络,OK。然后决定变换训练阶段只训练一个网络,每次变换输入图像的尺寸的时候,都保留之前的训练参数。
其实这里我觉得不是很好吧,就是每次完全替换尺度,按照我自己的理解应该是随机混着来最好,只不过确实没法高效利用 GPU 训练 batch 了,不能用 batch 的话,如果每次一张就更新,也是有可能比较震荡的,左右为难。
SPP-Net for Image Classification
SPP-Net 其实并不绑定任何形式 CNN,它的特性是独立的;
多层空间池化能提升模型性能,而且论文做了实验,证明并不是简单地因为多尺度进行空间金字塔池化参数更多,而是因为更多尺度能拿到“更好”的特征;
多尺度训练能提升模型性能,这个原因我觉得和上面一条有共性,也就是这样训练能帮助网络拿到更好的特征。
SPP-Net for Object Detection
前面已经提炼过这部分重点了,重点就是在 R-CNN 的基础上改进了提取所有 region proposal 特征的方式,不再是每个 region 单独跑一遍 CNN,而是在全图范围内一遍 CNN 提取特征,然后根据特定的某个 region 映射在 feature map 上获取仅该 region 对应的那部分feature map,然后再通过空间金字塔池化获取固定长度的特征向量,再送到二分类 SVM 做分类,再做框回归。
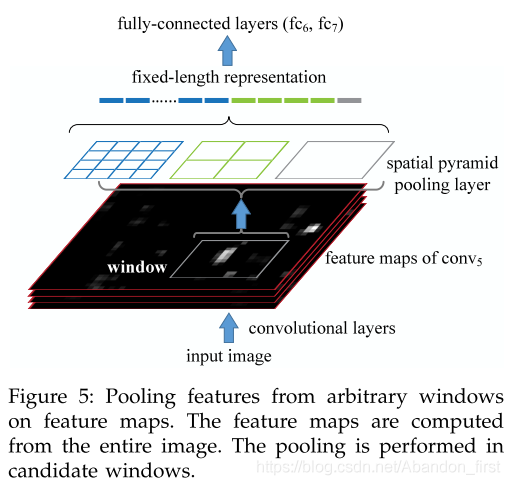
Detection Algorithm
用的空间金字塔池化是 4-level 的,每个通道上 1 × 1,2 × 2,3 × 3,6 × 6 一共 50 bins,如果你有 256 个通道,那就是每个 region 对应的 window 会生成 256 × 50 = 12800 维表征,这个向量再送到全连接。再单独训练 SVM 来分类。
多尺度训练时,resize 图片,使得图片的短边在尺度集合中,min(w,h)=s∈S={480,576,688,864,1200}。
Trick:把原图 resize 到多个尺度然后送进网络计算各个尺度的 conv5 特征,怎么用呢?(1)是把这些特征组合起来,然后逐个通道的做池化,(2)是发现选择原图中这个 region 分辨率最接近 224 × 224 的就可以。如果刚刚提到的多尺度足够“多”并且 region 对应的 window 足够“方”,上面两种方案比较接近。
小声逼逼,其实这里我也没太理解哦,为啥 224 × 224 的最好啊,难道多尺度训练之前也是有 224 × 224 预训练参数的?不然的话各个尺度如果都是比较均匀训练的,凭什么就是 224 呢,而不是个别的某个尺寸。
SPP-Net 微调了(仅仅微调了)空间金字塔池化之后的全连接,也就是从拿到了固定长度的特征之后。至于为啥不一起微调空间金字塔池化层以前的卷积层,还被后面 Fast R-CNN 点名 cue 了。
Implementation of Pooling Bins, 如果 feature map(可以是全图的,也可以是某个 region 对应的提出来的)尺寸为 w 和 h。如果某个 level 的金字塔要将这个 w × h 的 feature map 映射成 n × n 个 bins。那么第 i 行 第 j 列的 bin 在 feature map 上对应的坐标横向范围是 [ ⌊ i − 1 n ⋅ w ⌋ , ⌈ i n ⋅ w ⌉ ] [\ \lfloor \frac{i - 1}{n} \cdot w \rfloor, \lceil\frac{i}{n} \cdot w\rceil\ ] [ ⌊ni−1⋅w⌋,⌈ni⋅w⌉ ],纵向范围是 [ ⌊ j − 1 n ⋅ h ⌋ , ⌈ j n ⋅ h ⌉ ] [\ \lfloor \frac{j - 1}{n} \cdot h \rfloor, \lceil\frac{j}{n} \cdot h\rceil\ ] [ ⌊nj−1⋅h⌋,⌈nj⋅h⌉ ],好像也没啥好说的,注意范围界限和开闭区间就好了。
Mapping a Window to Feature Maps, 这里说些细节。卷积这一大块中每层都有卷积核的大小、padding 的大小和方式、stride 的大小。所以,初始的输入图中对应某个区域的位置(论文这部分一直叫它 window 了),经过了若干层卷积之后,落在此时的 feature map 上位置和大小是会变的。幸运的是,可以通过中间卷积层的各个参数,求解出这种映射。
一般来说,经过几层卷积之后 feature map 的尺寸相比初始输入图来说会明显变小。此时,在 feature map 上选中某一点暂且叫 P ′ ( x ′ , y ′ ) P’(x’, y’) P′(x′,y′),它在此前的几层卷积上都是有不同的感受野大小的。
如果卷积核的尺寸横纵方向是一致的,那么感受野就是正方形(除非遇到边界)。
如果所有的卷积 stride 都为 1,padding 是 same 模式(有点串戏突然用框架里面的词汇来讲,总之就是按照 kernel 大小补边),那么feature map 上的点 P’ 以及它在前面几层的感受野的中心 P 坐标是完全一致的。
如果 stride 不全都为 1,而 padding 仍然是 same,那么feature map 上 P’ 点与其对应初始输入图上的感受野中心 P(x,y) 之间就有映射关系 ( x , y ) = ( S ⋅ x ′ , S ⋅ y ′ ) (x, y) = (S \cdot x', S \cdot y') (x,y)=(S⋅x′,S⋅y′),其中这个 S 是前面几层 stride 的累乘。
但是回到这篇论文目标检测算法中的对应任务上来,我们需要计算 Selective Search 提的候选框(这是在原图上的)的 特征(在 feature map 上),所以不是要从 feature map 映射回原图,而是从原图映射到 feature map,即 P 到 P’。论文选取原图 region 对应的左上和右下两个角点,通过计算两个角点在 feature map 上的映射点,来计算原图 region 对应 feature map 上的坐标范围。不过左上和右下的具体映射方式略有不同,一个是向下取整再加 1,一个是向上取整再减 1,这个根本原因在于卷积实际计算中的细节。
左上: x ′ = ⌊ x S ⌋ + 1 x ′ = ⌊ S x ⌋ + 1 x' = \lfloor\frac {x}{S}\rfloor + 1 x′=⌊Sx⌋+1 x′=⌊Sx⌋+1x′=⌊Sx⌋+1
右下: x ′ = ⌈ x S ⌉ − 1 x ′ = ⌈ S x ⌉ − 1 x' = \lceil\frac {x}{S}\rceil - 1 x′=⌈Sx⌉−1 x′=⌈Sx⌉−1x′=⌈Sx⌉−1
记忆这种向上向下加加减减的太不靠谱了,时间长了我也记不住,我也不想长时间回来看不断增加记忆,又不是什么基础知识了没必要印在 DNA 里。所以我们按照极端个例来理解就行了。
就把左上角点当做原图中左上角即 (0, 0) 卷积一次,只要有 padding same,这个点卷积操作之后必然落在(1, 1),因为 feature map 上 (0, 0) 的位置你得对应 padding 啊,不然怎么 same,这就必得对应 +1 了;
而右下角点也取极端,就按照原图中右下点来算,padding 是 same 的情况下,一次卷积之后的尺寸就是 ⌈ l s ⌉ \lceil\frac {l}{s}\rceil ⌈sl⌉,就看是 w 方向还是 h 方向了,那你这个点映射到 feature map 既不能跑到图外面去,也不能去别的地儿呆了,就得蹲在 feature map 右下角啊,还能去哪儿,所以就是 ⌈ x S ⌉ − 1 \lceil\frac {x}{S}\rceil - 1 ⌈Sx⌉−1(下标从 0 开始啊)。
写到这里,我又想精分扮演一下杠精了23333。
R-CNN 不是说 CNN feature map 对应原图对不上吗?咋 SPP-Net 用上了这个映射?不是映射不准吗?
emmm 其实这里是有规模缩放的,从原图映射到 feature map 取特征的误差是相对较小的,因为 SPP-Net 这里也只是按照感受野中心点映射而已,重点在于取特征,只要能取到表征原图 region 部分的特征就行;而根据 feature map 根据感受野的整个规模映射回去原图误差可大了去了,而且你这么做的目的是为了定位区域的位置边界等蛮细节的信息,这么大误差是容忍不了的。
再说回来,SPP-Net 和 RCNN 的整体大的 pipeline 是完全一致的,四大块:区域推荐 + 特征提取 + 分类器 + 回归器,其中只有特征提取有变化而已,也就是 SPP-Net 只用了映射关系从比较确切的 region proposal 拿其 feature map 上的对应特征,别无其他。它仍然使用 Selective Search 做区域推荐,仍然单独训练二分类 SVM 做分类,仍然训练回归器微调 BoundingBox。
参考
https://www.fx361.com/page/2021/1217/11400445.shtml
https://blog.csdn.net/Abandon_first/article/details/117021640


![[小样本图像分割]PANet: Few-Shot Image Semantic Segmentation with Prototype Alignment](https://img-blog.csdnimg.cn/20210326093348728.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzM4OTMyMDcz,size_16,color_FFFFFF,t_70)







![PANet[详解]](https://img-blog.csdnimg.cn/20190306182650858.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl8zNzk5MzI1MQ==,size_16,color_FFFFFF,t_70)