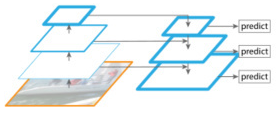
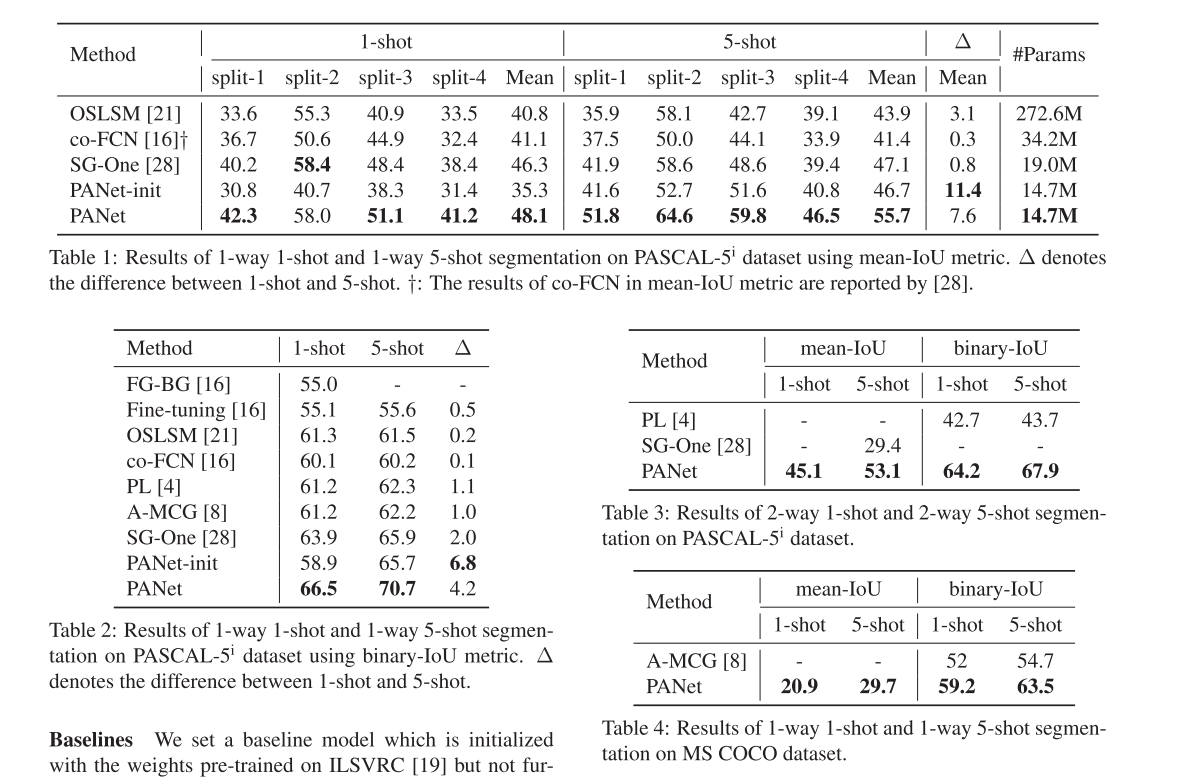
起初faster-r-cnn,只采用最后一层特作为rpn以及head部分的特征图 ,后来不断改进,有了FPN, 再后来有了Panet,一般来说网络的层数越深它的语义信息越丰富。但是随着网络层数的加深,检测所需的位置信息就会越差,CNN分类网络只需要知道一张图像的种类即可所以很多时候网络越深效果越好,但是不是分类效果越好的网越适合检测。FPN如下图所示,它用了不同大小的特征图进行预测,图中:下方的特征图较大,对应的感受野较小可以用来检测小目标,上部分的特征图尺寸较小,但是感受野较大适合检测大目标。
Panet 是对FPN的改进,如下图红线所示,在fpn中顶层底层信息距离太远,不要看红线中间只有三四个框,这是一个示意,其中 有好多的卷积操作所以顶层底层距离很远,所以在右侧 开辟了一条新的路(绿线),只要几个个卷积层,顶层信息就能快速与底层信息汇合。特征提取对结果的影响特别大,融合不同尺度的信息十分必要,M2det在SSD的基础上增加了部分网络来优化特征提取,得到的效果就比SSD效果好得多

代码是基于resnet50的特征提取部分实现的,上一张resnet50的网络结构

具体实现如下,其中fpn参考mmdetection种fpn的结构,Panet部分自己写的,如有不对请告知。
其中图像经过下采样再进行上采样的时候有可能大小不同,某一层图像下采样前的尺寸为单数。可以提前计算图像大小对输入图像直接padding,我用的是上采样时直接输入尺寸。
import torch
from torch import nn
import torch.nn.functional as Fclass Bottleneck(nn.Module):expansion = 4def __init__(self, in_size, size_u, stride=1, is_down=False):super(Bottleneck, self).__init__()self.conv1 = nn.Conv2d(in_size, size_u, kernel_size=1, stride=stride, bias=False)self.bn1 = nn.BatchNorm2d(size_u)self.conv2 = nn.Conv2d(size_u, size_u, kernel_size=3, padding=1, bias=False)self.bn2 = nn.BatchNorm2d(size_u)self.conv3 = nn.Conv2d(size_u, size_u * self.expansion, kernel_size=1, bias=False)self.bn3 = nn.BatchNorm2d(size_u * self.expansion)self.relu = nn.ReLU(inplace=True)self.downsample = nn.Sequential(nn.Conv2d(in_size, size_u * self.expansion, kernel_size=1, stride=stride, bias=False),nn.BatchNorm2d(size_u * self.expansion))self.stride = strideself.is_down = is_downdef forward(self, x):identity = xout = self.conv1(x)out = self.bn1(out)out = self.relu(out)out = self.conv2(out)out = self.bn2(out)out = self.relu(out)out = self.conv3(out)out = self.bn3(out)if self.is_down:identity = self.downsample(x)out += identityout = self.relu(out)return outclass Resnt50(nn.Module):def __init__(self):super(Resnt50, self).__init__()self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)self.bn1 = nn.BatchNorm2d(64)self.relu = nn.ReLU(inplace=True)self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)self.lysize = [64, 128, 256, 512, 1024, 2048]self.layer1 = nn.Sequential(Bottleneck(self.lysize[0], self.lysize[0], 1, True),Bottleneck(self.lysize[2], self.lysize[0], 1, False),Bottleneck(self.lysize[2], self.lysize[0], 1, False))self.layer2 = nn.Sequential(Bottleneck(self.lysize[2], self.lysize[1], 2, True),Bottleneck(self.lysize[3], self.lysize[1], 1, False),Bottleneck(self.lysize[3], self.lysize[1], 1, False),Bottleneck(self.lysize[3], self.lysize[1], 1, False))self.layer3 = nn.Sequential(Bottleneck(self.lysize[3], self.lysize[2], 2, True),Bottleneck(self.lysize[4], self.lysize[2], 1, False),Bottleneck(self.lysize[4], self.lysize[2], 1, False),Bottleneck(self.lysize[4], self.lysize[2], 1, False),Bottleneck(self.lysize[4], self.lysize[2], 1, False),Bottleneck(self.lysize[4], self.lysize[2], 1, False))self.layer4 = nn.Sequential(Bottleneck(self.lysize[4], self.lysize[3], 2, True),Bottleneck(self.lysize[5], self.lysize[3], 1, False),Bottleneck(self.lysize[5], self.lysize[3], 1, False))# self.avgpool = nn.AdaptiveAvgPool2d((1, 1))# self.fc = nn.Linear(self.lysize[5], 3)for m in self.modules():if isinstance(m, nn.Conv2d):nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')elif isinstance(m, nn.BatchNorm2d):nn.init.constant_(m.weight, 1)nn.init.constant_(m.bias, 0)def forward(self, x):conv1 = self.conv1(x)bn1 = self.bn1(conv1)relu = self.relu(bn1)maxpool = self.maxpool(relu)layer1 = self.layer1(maxpool)layer2 = self.layer2(layer1)layer3 = self.layer3(layer2)layer4 = self.layer4(layer3)# x = self.avgpool(layer4)# x = x.view(x.shape[0], -1)# x = self.fc(x)return layer1, layer2, layer3, layer4class FPN(nn.Module):def __init__(self):super(FPN, self).__init__()self.resnet_feature = Resnt50()self.conv1 = nn.Conv2d(in_channels=2048, out_channels=256, kernel_size=1, stride=1, padding=0)self.conv2 = nn.Conv2d(1024, 256, 1, 1, 0)self.conv3 = nn.Conv2d(512, 256, 1, 1, 0)self.conv4 = nn.Conv2d(256, 256, 1, 1, 0)self.fpn_convs = nn.Conv2d(256, 256, 3, 1, 1)def forward(self, x):layer1, layer2, layer3, layer4 = self.resnet_feature(x) # channel 256 512 1024 2048P5 = self.conv1(layer4)P4_ = self.conv2(layer3)P3_ = self.conv3(layer2)P2_ = self.conv4(layer1)size4 = P4_.shape[2:]size3 = P3_.shape[2:]size2 = P2_.shape[2:]P4 = P4_ + F.interpolate(P5, size=size4, mode='nearest')P3 = P3_ + F.interpolate(P4, size=size3, mode='nearest')P2 = P2_ + F.interpolate(P3, size=size2, mode='nearest')P5 = self.fpn_convs(P5)P4 = self.fpn_convs(P4)P3 = self.fpn_convs(P3)P2 = self.fpn_convs(P2)return P2, P3, P4, P5class Panet(nn.Module):def __init__(self, class_number=512):super(Panet, self).__init__()self.fpn = FPN()self.convN = nn.Conv2d(256, 256, 3, 2, 1)self.relu = nn.ReLU(inplace=True)def forward(self, x):P2, P3, P4, P5 = self.fpn(x)N2 = P2N2_ = self.convN(N2)N2_ = self.relu(N2_)N3 = N2_ + P3N3_ = self.convN(N3)N3_ = self.relu(N3_)N4 = N3_ + P4N4_ = self.convN(N4)N4_ = self.relu(N4_)N5 = N4_ + P5return N2, N3, N4, N5if __name__ == '__main__':from torchsummary import summarydevice = torch.device("cuda" if torch.cuda.is_available() else "cpu")model = FPN().to(device)summary(model, (3, 512, 512))
----------------------------------------------------------------------------------end---------------------------------------------------------------------------------





![PANet[详解]](https://img-blog.csdnimg.cn/20190306182650858.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl8zNzk5MzI1MQ==,size_16,color_FFFFFF,t_70)