原文:Underwater object detection using Invert Multi-Class Adaboost with deep learning
论文被International Joint Conference on Neural Networks (IJCNN) 2020(CCF C类)收录,
开源代码:https://github.com/LongChenCV/SWIPENet
达到URPC 2017的冠军结果,45.0map,冠军为45.1map
一句话总结:提出了一种用于水下目标小样本检测的SWIPENet,网络中提出了一种样本重加权算法IMA(Invert Multi-Class Adaboost),IMA会减少missed objects(丢失对象)的权重,以减少这些“干扰”样本的影响。Star: ⋆ \star ⋆
本文目录
- Abstract
- Introduction
- Related Work
- Underwater object detection
- Sample re-weighting
- Sample-weighted hyper network (SWIPENet)
- The architecture of our proposed SWIPENet
- 扩展:[空洞卷积(dilated convolution layers)](https://zhuanlan.zhihu.com/p/50369448)
- Sample-weighted loss
- Invert multi-class adaboost (IMA)
- The overview of IMA
- 扩展:[adaptive boosting (adaboost,自适应增强)](https://blog.csdn.net/v_JULY_v/article/details/40718799):听取多人意见,最后综合决策
- The mapping function f(.)
- Experiments on URPC2017 and URPC2018
- 消融实验:针对跳连、空洞卷积
- 消融实验:针对IMA
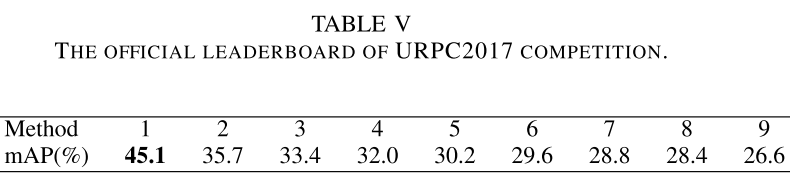
- 在URPC2017上的结果(URPC2017有18,982张训练图像和983张测试图像)
- URPC 2017比赛结果,SWIPENet的map达到第一名的方案的结果。
- 在URPC2018上的结果(URPC2018数据集具训练集中有2897个图像,但测试集尚未公开。论文是将URPC2018的训练集随机分为1,999张图像的训练集和898张图像的测试集。)
- Conclusion
Abstract
摘要—近年来,基于深度学习的方法已经在标准物体检测方面取得了令人鼓舞的性能。但是,由于这些挑战,这些方法缺乏足够的能力来处理 水下物体检测存在的这两个问题:(1)实际应用中的物体通常很小,并且其图像模糊,(2)水下数据集和实际应用中的图像伴随着异类噪声。 为了解决这两个问题, 我们首先提出了一种新颖的神经网络架构,即用于小物体检测的样本加权HyPEr网络(SWIPENet)。 SWIPENet由高分辨率和语义丰富的超特征图组成,可显着提高小物体检测的准确性。此外,我们提出了一种新颖的样本加权损失函数,该函数可以为SWIPENet建模样本权重,它使用一种新颖的样本重新加权算法,即反转多类Adaboost(IMA),以减少噪声对拟议的SWIPENet的影响。 在两个水下机器人选拔比赛数据集URPC2017和URPC2018上进行的实验表明,相对于几种最新的对象检测方法,所提出的SWIPENet + IMA框架在检测精度方面具有更好的性能。
索引词-水下物体检测,多级Adaboost,样品重加权,噪声数据
Introduction
水下物体检测旨在定位和识别水下场景中的物体。这项研究由于在海洋学[1],水下导航[2]和养鱼[3]等领域的广泛应用而引起了持续的关注。但是,由于复杂的水下环境和光照条件,这仍然是一项艰巨的任务。基于深度学习的对象检测系统具有在各种应用中表现出令人鼓舞的性能,但在水下物体检测方面仍然感到不足。这是因为, 首先,水下检测数据集稀少,可用的水下数据集和实际应用程序中的对象通常很小。当前基于深度学习的检测器无法有效检测小物体(请参见图1所示的示例)。 其次,现有水下数据集和实际应用中的图像杂乱无章。众所周知,在水下场景中,与波长有关的吸收和散射[4]会大大降低水下图像的质量。这导致许多问题,例如可见度损失,对比度差和颜色变化, 这给检测任务带来了许多挑战。为了解决这些问题,我们在这里提出一个名为Sample-WeIghted hyPEr Network(SWIPENet)的神经网络,它充分利用了多个Hyper Feature Maps来改善小物体检测。此外,我们引入了一个样本加权损失函数,该函数与Invert Multi-Class Adaboost(IMA)算法配合使用,以减少噪声对SWIPENet特征学习的影响。
本文的其余部分安排如下。第二节简要介绍相关工作。第三部分描述了SWIPENeT的结构和样本加权损失。第四部分介绍了反向多类Adaboost算法。第五节在两个水下数据集URPC2017和URPC2018上报告了该方法的结果。

Related Work
Underwater object detection
水下物体检测技术已被采用从事海洋生态研究多年。 Strachan等。 [5]使用颜色和形状描述符来识别在传送带上运输的鱼,并由数码相机监控。 Spampinato等。 [6]提出了一种用于实时视频中鱼的检测,跟踪和计数的视觉系统,该系统包括视频纹理分析,目标检测和跟踪过程。然而,上述方法严重依赖手工制作的特征,这限制了表示能力。 Choi [7]应用前景检测方法提取候选鱼窗,并使用卷积神经网络(CNN)对视场中的鱼类进行分类。 Ravanbakhsh等。 [8]将深度学习方法与定向网格直方图(HOG)+支持向量机(SVM)方法在检测珊瑚鱼中进行了比较,实验结果表明,深度学习方法在水下物体检测中的优势。 Li等。 [9]利用Fast RCNN [10]检测和识别鱼类。 Li等。 [11]使用Faster RCNN [12]加速了鱼的检测。但是,这些快速RCNN方法使用了来自神经网络最后一个卷积层的特征,这些特征很粗糙,不能用于有效地检测小物体。另外,水下物体检测数据集非常稀少,这阻碍了水下物体检测技术的发展。 最近,Jian等人。 [13],[14]提出了用于水下显着性检测的水下数据集,该数据集提供了对象级注释,可用于评估水下对象检测算法。
Sample re-weighting
样本重加权可用于解决嘈杂的数据问题[15]。它通常为每个样本分配一个权重,然后优化样本加权的训练损失。
对于基于训练损失的方法,我们可能有两个研究方向。例如,focal loss[16]和hard example mining(困难样本挖掘)[17]强调样本中训练损失较高,而self-placed learning[18]和curriculum learning(课程学习)[19]则鼓励学习样品损耗低。两种可能的解决方案对训练数据采用不同的假设。第一种解决方案假定高损耗样本是要学习的样本,而第二种解决方案假定高损耗样本容易产生干扰或嘈杂的数据。
与基于训练损失的方法不同,Multi-Class Adaboost [20]根据分类结果对样本进行加权。该方法着重于通过在迭代过程中增加权重来学习分类错误的样本。 在第四部分,我们提出了一种新颖的基于检测的样本重加权算法,即反转多类Adaboost(IMA),以通过重加权减少噪声的影响。
Sample-weighted hyper network (SWIPENet)
The architecture of our proposed SWIPENet
有证据表明,卷积神经网络的降采样切除产生强大的语义,从而导致许多分类任务的成功。 然而,这对于对象检测任务是不够的,该任务不仅需要识别对象的类别,而且还需要在空间上定位其位置。在应用了几次下采样操作之后,深层的空间分辨率太粗糙而无法处理小物体检测。
在本文中,我们提出了SWIPENet体系结构,该体系结构包括受反卷积单镜头检测器(Deconvolutional Single Shot Detector, DSSD)启发的数种高分辨率且语义丰富的超特征图[21]。 DSSD通过多个上采样反卷积层增强了快速下采样检测框架SSD [25],以提高特征图的分辨率。在DSSD体系结构中,首先,构造多个下采样卷积层以提取有利于对象分类的高语义特征图。经过几次下采样操作后,特征图太粗糙而无法为准确的小对象定位提供足够的信息,因此,添加了多个上采样反卷积层和跳过连接以恢复高分辨率的特征图。 但是,即使恢复了分辨率,下采样操作丢失的详细信息也无法完全恢复。为了改善DSSD,我们使用空洞卷积层(dilated convolution layers)[22],[23]获得强大的语义,同时又不丢失支持对象定位的详细信息。
扩展:空洞卷积(dilated convolution layers)


图2说明了我们提出的SWIPENet的概述,它由多个卷积块(红色),空洞卷积块(dilated convolution blocks)(绿色),反卷积块(蓝色)和新的样本加权损失(灰色)组成。 SWIPENet的前层基于标准VGG16模型[24]的体系结构(在Conv5 3层被截断)。与DSSD不同,我们在网络中添加了四个具有ReLU激活的空洞卷积层,它们可以在不牺牲特征图分辨率的情况下获得大的接受区域(大的接受区域会导致很强的语义,有助于分类)。 我们使用反卷积进一步对特征图进行上采样,然后使用跳跃连接将低层的精细细节传递给高层。最后,我们在反卷积层上构造多个Hyper Feature Map。 SWIPENet的预测部署了三个不同的反卷积层,即Deconv1 2,Deconv2 2和Deconv3 2(在图2中表示为Deconvx 2),它们的大小逐渐增加,并允许我们预测多个尺度的对象。 在三个反卷积层的每个位置,我们定义6个默认框,并使用3×3卷积核产生C + 1类分数(C表示对象类的数量,而1表示背景类)和4个相对坐标偏移还原为原始的默认框形状。
Sample-weighted loss
Loss的讲解看本小节下方原文,挺清楚的。


由于公式4的存在,SWIPENeT的特征学习主要由高权重样本决定,而低权重样本的特征学习则被忽略

Invert multi-class adaboost (IMA)
The overview of IMA
SWIPENet可能会丢失或错误地检测到一些训练集中的目标,可能会被视为嘈杂的数据[26] – [29]。这是因为嘈杂的数据非常模糊,并且与背景相似,因此容易被忽略或检测为背景。如果我们使用这些嘈杂的数据训练SWIPENet,则性能可能会受到影响。 SWIPENet无法将背景与物体区分开来,主要是由于噪音。 图3显示了示例测试图像及其通过SWIPENet的不正确检测。为了解决这个问题,我们在此提出一种受[30]启发的IMA算法,以减少不确定对象的权重,以提高SWIPENet的检测精度。

IMA基于Multi-Class Adaboost(多类自适应增强) [20]。Multi-Class Adaboost(MA)首先顺序训练多个基本分类器,并根据其错误率 E m E_{m} Em 分配权重值 α m \alpha_m αm。然后,对前一个分类器分类错误的样本分配较高的权重,从而使后一个分类器可以集中精力学习这些样本,最后,将所有弱基础分类器组合在一起,形成具有相应权重的整体分类器。我们的Invert multi-class adaboost (IMA)训练了M次SWIPENet,然后将它们整合为一个统一的模型,与Multi-Class Adaboost不同的是,在每次训练迭代中,IMA都会减少missed objects(丢失对象)的权重,以减少这些“干扰”样本的影响。
扩展:adaptive boosting (adaboost,自适应增强):听取多人意见,最后综合决策

提出的IMA算法的概述可在算法1中找到。 I t r a i n I_{train} Itrain 表示训练图像with groud truth B = { b 1 , b 2 , . . . , b N } B = \{b_1,b_2,...,b_N \} B={b1,b2,...,bN}, N是训练集中的对象数(注:这里的B是包含了整个训练集所有的ground truth检测框,不是某一张图片中的检测框,而是整个训练集所有检测框 ),
b j = ( c l s , c x , c y , w , h ) b_j =(cls,cx,cy,w,h) bj=(cls,cx,cy,w,h)是第 j 个对象的annotation。 我们表示 w j m w^m_j wjm作为第j个对象在第m次迭代中的的权重。第一次迭代中,每个样品的初始权重为 1 N \frac{1}{N} N1,即 w j 1 = 1 N w^1_j =\frac{1}{N} wj1=N1,j = 1,…,N.
Firstly,在第m次迭代中,我们首先计算正样品的权重。 如果在训练过程中第i个正样本与第j个对象匹配,则我们分配第j个对象的权重
w j m w^m_j wjm作为第i个正样本的权重 w ˉ i m \bar{w}^m_i wˉim,即 w ˉ i m = w j m \bar{w}^m_i = w^m_j wˉim=wjm。映射函数 f ( ⋅ ) f(\cdot) f(⋅) 将权重 m ˉ i m \bar{m}^m_i mˉim映射为 f ( m ˉ i m ) f(\bar{m}^m_i) f(mˉim) 通过使用公式10中的sample-weighted loss(样本加权损失)。
Secondly,我们使用 f ( m ˉ i m ) f(\bar{m}^m_i) f(mˉim)训练第m个SWIPENeT的 G m G_m Gm。
Thirdly,我们的第m个SWIPENeT在训练集上跑,并获得检测集 D m = d 1 , d 2 , . . . , d i D_m = {d_1,d_2,...,d_i} Dm=d1,d2,...,di,而 d i = ( c l s , s c o r e , c x , x y , w , h ) di =(cls,score,cx,xy,w,h) di=(cls,score,cx,xy,w,h)是第i个检测框的结果,包括类别(cls)得分(score)和坐标(cx,cy,w,h)。 通过公式(5)和(6),我们根据未检测到的物体的百分比计算出第m个SWIPENeT的错误率 E m E_m Em。

如果检测集 D m = { d 1 , d 2 , . . . , d i } D_m =\{d_1,d_2,...,d_i\} Dm={d1,d2,...,di}中存在检测框d与ground truth框 b j b_j bj的IoU大于θ(此处为0.5),且预测框d的类别与ground truth框 b j b_j bj的类别相同(即: b j . c l s = d . c l s b_j.cls=d.cls bj.cls=d.cls),则令 I ( b j ) = 0 I(b_j)=0 I(bj)=0,说明第j个object已经被检测到了。若 D m D_m Dm中不存在这样的检测框符合上述要求,则令 I ( b j ) = 1 I(b_j)=1 I(bj)=1,说明没有检测到第j个object。
属于相同类别的检测框d由于第j个地面真实物体bj(即bj.cls = d.cls)并且检测点与第j个物体之间的并集交集(IoU)大于,我们将I(bj )= 0表示已检测到第j个对象,I(bj)= 1表示未检测到第j个对象。
Fourthly,我们通过公式(7),在整体模型中计算第m个SWIPENeT的权重 α m \alpha_m αm。 C是对象类别的数量。
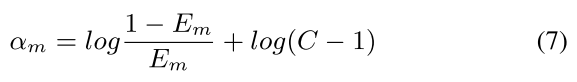
Finally,我们更新每个对象的权重 w j m w^m_j wjm。 不同于Multi-Class Adaboost,通过公式(8)我们降低了未检测到的物体的权重降低 。 z m z_m zm是归一化常数。 迭代重复执行,直到所有M个SWIPENeT都被训练过。
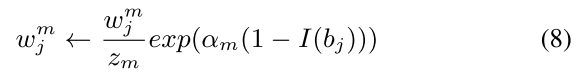
在测试阶段,我们首先在测试集 I t e s t I_{test} Itest上运行所有M个SWIPENeT,然后获得M个检测集 D m = G m ( I t e s t ) , m = 1 , 2 , . . . , M 。 D_m=G_m(I_{test}),m = 1,2,...,M。 Dm=Gm(Itest),m=1,2,...,M。 然后,我们根据 α m \alpha_m αm对 D m D_m Dm中的每个检测框d进行重新评分,即: d . s c o r e = α m d . s c o r e d.score ={\alpha_m}d.score d.score=αmd.score。 最后,我们结合所有检测框并应用公式(9)非极大抑制[31]来消除重叠的检测框生成最终检测。
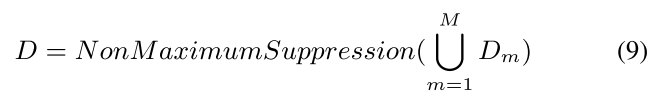

The mapping function f(.)
我们为第i个正样本定义了两个权重,即在IMA中学习的IMA权重 w i m w^m_i wim和样本加权损失中使用的权重 f ( w ˉ i m ) f(\bar{w}^m_i) f(wˉim)。 在IMA中,每个正样本的初始IMA权重为1/N(N是(训练数据中对象的数量),因此,在样本加权损失中使用的每个正样本的初始权重为1。因此,直观上看,在样本加权损失函数中,正样本的权重是IMA权重的N倍。 我们可以定义一个线性映射函数f(·),将IMA权重映射到样本加权损失中使用的权重。 在这里,我们首先第i个默认框(default box)的赋予第j个对象(ground truth)的权重(如果它们匹配),我们将第i个默认框和第j个对象的权重分别表示为 w ˉ i m 和 w j m \bar{w}^m_i和w^m_j wˉim和wjm ,因此有 w ˉ i m = w j m \bar{w}^m_i=w^m_j wˉim=wjm 然后,通过公式(10)我们映射IMA权重 w ˉ i m \bar{w}^m_i wˉim为用于样本加权损失的权重 f ( w ˉ i m ) f(\bar{w}^m_i) f(wˉim)。
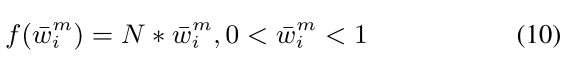
Experiments on URPC2017 and URPC2018
我们在水下机器人目标抓取大赛的两个水下数据集URPC2017和URPC2018上评估了我们的方法。 URPC2017数据集具有3个对象类别,包括海参,海胆和扇贝。 有18,982张训练图像和983张测试图像。 == URPC2018数据集具有4个对象类别,包括海参,海胆,扇贝和海星。 训练集中有2897个图像,但测试集尚未公开。== 我们将URPC2018的训练集随机分为1,999张图像的训练集和898张图像的测试集。 这两个数据集都提供了水下图像和框级注释(在补充说明中提供了详细说明)。 在本节中,我们首先在V-A小节中使用消融研究来分析我们的方法。 然后,我们将我们的方法与其他最先进的检测框架进行比较,这些检测框架包括V-B小节中显示的SSD [25],YOLOv3 [32]和Faster RCNN [12]。
消融实验:针对跳连、空洞卷积

消融实验:针对IMA

在URPC2017上的结果(URPC2017有18,982张训练图像和983张测试图像)

URPC 2017比赛结果,SWIPENet的map达到第一名的方案的结果。
在URPC2018上的结果(URPC2018数据集具训练集中有2897个图像,但测试集尚未公开。论文是将URPC2018的训练集随机分为1,999张图像的训练集和898张图像的测试集。)

Conclusion
在本文中,我们提出了一种神经网络架构-用于小型水下物体检测的称为“样本加权高等网络”Sample-WeIghted hyPEr Network (SWIPENet)。 此外,提出了一种样本重加权算法,称为Invert Multi-Class Adaboost(IMA),以解决噪声问题。 我们提出的方法在具有挑战性的数据集上实现了最先进的性能,但是它的时间复杂度是单个模型的M倍,因为它是M个深度神经网络的集合。 因此,在未来的工作中,降低我们提出的方法的计算复杂度至关重要。 另外,当前的深层模型引入了注意力机制和新颖的损失来解决噪声和小物体检测的问题,这为我们开发SWIPENet提供了深刻的想法。