java使用poi读取跨行跨列excel
- 1.需求背景
- 2.实现思路分析
- 3.重要代码片码说明
- 4.完整的代码类如下:
- 5.完整的demo代码提供如下
- 6.demo执行结果
1.需求背景
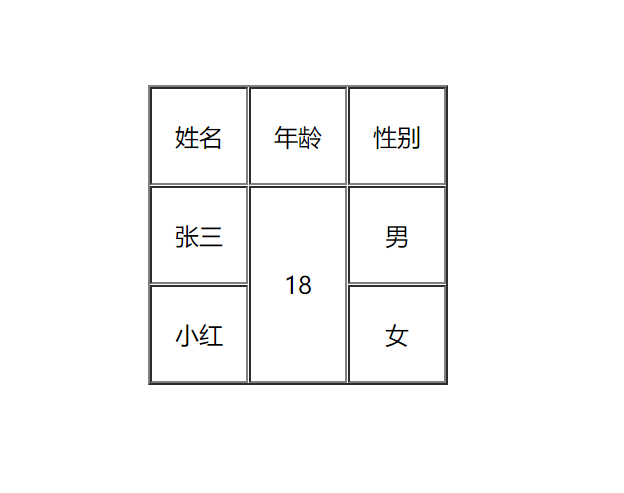
最近有一个工作任务是用户提供了一个基础的excel文件,要求首先将excel中的数据解析并入库,然后再做后续的一些业务处理,因此涉及到excel的数据读取,正常如果是一行一行数据的excel的读取,还是比较简单,但用户提供的数据涉及跨行跨列问题,就稍有点麻烦,比如数据样例如下:
需要将跨行跨列数据也读取出来最后进行入库处理,比如要解析成如下的数据并入库。


2.实现思路分析
首先以上的excel样例数据中,第一列共2个跨行区域,天河区和番禺区,每个跨行区域中在第二列又存在子跨行数据的问题,查看了poi的api,如获取到excel的工作表sheet后(通过如XSSFSheet sheet = xssfWorkbook.getSheetAt(0);获取),有个sheet.getNumMergedRegions()方法,此方法会返回excel中的所有关于合并单元格的信息,每个信息中包含了这个合并单元格的开始行,结束行,开始列,结束列。合并单元格的数据能通过第一行和第一列获取到。
因此,可以采用一个hashmap将以上的合并单元格的信息进行预先读取,将存在合并单元格的列记录入put进hashmap, 如key为行号+下划线+列号组成,value为记录了合并单元格的起始行号和起始列号组成的数组。
有了上面的hashmap之后,就可以按常规的遍历excel的行,然后再遍历excel的列进行数据的读取处理了,对每一个单元格进行判断,判断此单元格的行号+列号组成的key是不是在hashmap中存在,存在的话说明是一个合并单元格,读取数据就从value中取出合并单元格的起始行号和起始列号,通过合并单元格的起始行号和起始列号组成的单元格读取真正的数据(合并单元格的组据在首行和首列,其他行和列是空白)比如,以下的510075的数据,要通过读B2这一格才能读到数据

3.重要代码片码说明
- 获取存在合并单元格的列记录并以行号列号为key组成的map
//将存在合并单元格的列记录入put进hashmap并返回public Map<String,Integer[]> getMergedRegionMap(Sheet sheet){Map<String,Integer[]> result = new HashMap<String,Integer[]>();//获取excel中的所有合并单元格信息int sheetMergeCount = sheet.getNumMergedRegions();//遍历处理for (int i = 0; i < sheetMergeCount; i++) {//拿到每个合并单元格,开始行,结束行,开始列,结束列CellRangeAddress range = sheet.getMergedRegion(i); int firstColumn = range.getFirstColumn(); int lastColumn = range.getLastColumn(); int firstRow = range.getFirstRow(); int lastRow = range.getLastRow();//构造一个开始行和开始列组成的数组Integer[] firstRowNumberAndCellNumber = new Integer[]{firstRow,firstColumn};//遍历,将单元格中的所有行和所有列处理成由行号和下划线和列号组成的key,然后放在hashmap中for(int currentRowNumber = firstRow; currentRowNumber <= lastRow; currentRowNumber++) {for(int currentCellNumber = firstColumn; currentCellNumber <= lastColumn; currentCellNumber ++) {result.put(currentRowNumber+"_"+currentCellNumber, firstRowNumberAndCellNumber);}}}return result;}
4.完整的代码类如下:
package poitest;import java.io.IOException;
import java.io.InputStream;
import java.util.HashMap;
import java.util.Map;import org.apache.poi.ss.usermodel.Cell;
import org.apache.poi.ss.usermodel.CellType;
import org.apache.poi.ss.usermodel.Sheet;
import org.apache.poi.ss.util.CellRangeAddress;
import org.apache.poi.xssf.usermodel.XSSFRow;
import org.apache.poi.xssf.usermodel.XSSFSheet;
import org.apache.poi.xssf.usermodel.XSSFWorkbook;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;public class ExcelMergegionReadTest {private Logger logger = LoggerFactory.getLogger(this.getClass());public static void main(String[] args) {new ExcelMergegionReadTest().excelRegionReadStart();}public void excelRegionReadStart(){long start = System.currentTimeMillis();InputStream inputStream = null;// 输入流对象XSSFWorkbook xssfWorkbook = null; //工作簿try {inputStream = this.getClass().getClassLoader().getResourceAsStream("datatest.xlsx");//定义工作簿xssfWorkbook = new XSSFWorkbook(inputStream);//获取第一个sheetXSSFSheet sheet = xssfWorkbook.getSheetAt(0);//获取合并单元格信息的hashmapMap<String,Integer[]> mergedRegionMap = getMergedRegionMap(sheet);//拿到excel的最后一行的索引int lastRowNum = sheet.getLastRowNum();//从excel的第二行索行开始,遍历到最后一行(第一行是标题,直接跳过不读取)for(int i = 1; i<=lastRowNum ; i++) {//拿到excel的行对象XSSFRow row = sheet.getRow(i);//获取excel的行中有多个列int cellNum = row.getLastCellNum();//对每行进行列遍历,即一列一列的进行解析for(int j=0; j<cellNum; j++) {//拿到了excel的列对象Cell cell = row.getCell(j);//将列对象的行号和列号+下划线组成key去hashmap中查询,不为空说明当前的cell是合并单元列Integer[] firstRowNumberAndCellNumber = mergedRegionMap.get(i+"_"+j);//如果是合并单元列,就取合并单元格的首行和首列所在位置读数据,否则就是直接读数据if(firstRowNumberAndCellNumber != null) {XSSFRow rowTmp = sheet.getRow(firstRowNumberAndCellNumber[0]);Cell cellTmp = rowTmp.getCell(firstRowNumberAndCellNumber[1]);System.out.println(getCellValue(cellTmp));}else{System.out.println(getCellValue(cell));}}System.out.println("================================================");}} catch (Exception e) {logger.error("error",e);} finally {// 关闭文件流if (inputStream != null) {try {inputStream.close();} catch (IOException e) {logger.error("error",e);}}// 关闭工作簿if(xssfWorkbook != null){try {xssfWorkbook.close();} catch (IOException e) {logger.error("error",e);}}}long end = System.currentTimeMillis();System.out.println("spend ms: " + (end - start) + " ms.");}//将存在合并单元格的列记录入put进hashmap并返回public Map<String,Integer[]> getMergedRegionMap(Sheet sheet){Map<String,Integer[]> result = new HashMap<String,Integer[]>();//获取excel中的所有合并单元格信息int sheetMergeCount = sheet.getNumMergedRegions();//遍历处理for (int i = 0; i < sheetMergeCount; i++) {//拿到每个合并单元格,开始行,结束行,开始列,结束列CellRangeAddress range = sheet.getMergedRegion(i); int firstColumn = range.getFirstColumn(); int lastColumn = range.getLastColumn(); int firstRow = range.getFirstRow(); int lastRow = range.getLastRow();//构造一个开始行和开始列组成的数组Integer[] firstRowNumberAndCellNumber = new Integer[]{firstRow,firstColumn};//遍历,将单元格中的所有行和所有列处理成由行号和下划线和列号组成的key,然后放在hashmap中for(int currentRowNumber = firstRow; currentRowNumber <= lastRow; currentRowNumber++) {for(int currentCellNumber = firstColumn; currentCellNumber <= lastColumn; currentCellNumber ++) {result.put(currentRowNumber+"_"+currentCellNumber, firstRowNumberAndCellNumber);}}}return result;}/** * 获取单元格的值 * @param cell * @return */ public String getCellValue(Cell cell){ if(cell == null) return ""; if(cell.getCellType() == CellType.STRING){ return cell.getStringCellValue(); }else if(cell.getCellType() == CellType.BOOLEAN){ return String.valueOf(cell.getBooleanCellValue()); }else if(cell.getCellType() == CellType.FORMULA){ return cell.getCellFormula() ; }else if(cell.getCellType() == CellType.NUMERIC){ return String.valueOf(cell.getNumericCellValue()); }return "";} }
5.完整的demo代码提供如下
github: https://github.com/jxlhljh/excelmergeregiontest.git
gitee: https://gitee.com/jxlhljh/excelmergeregiontest.git
6.demo执行结果