文章目录
- 写在前面
- 键值对的存储——哈希
- 哈希冲突
- redis解决哈希冲突过多的方式——rehash
- 双向链表
- 数组
- 压缩链表
- 压缩链表的连锁更新
- 压缩列表的缺陷
- 整数数组和压缩列表在查找时间复杂度方面并没有很大的优势,那为什么 Redis 还会把它们作为底层数据结构呢?
- 一个数据类型都对应了很多种底层数据结构。以List为例,什么情况下是双向链表,反之又在什么情况下是压缩列表呢?还是说是并存状态?
- ziplist、quicklist、listpack 这三者是如何协助redis的数据类型的呢?
- 跳表
- 各种数据结构的时间复杂度
- 参考资料
写在前面
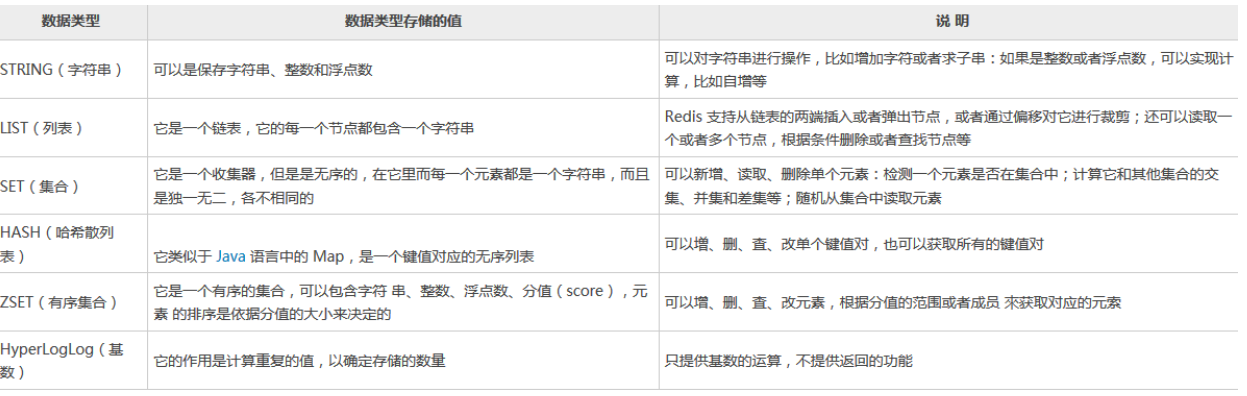
我们都知道,redis有五种基本的数据类型: String(字符串)、List(列表)、Hash(哈希)、Set(集合)和 Sorted Set(有序集合)。
今天,我们就一起聊聊我们熟知的这些数据类型,底层是如何实现的。
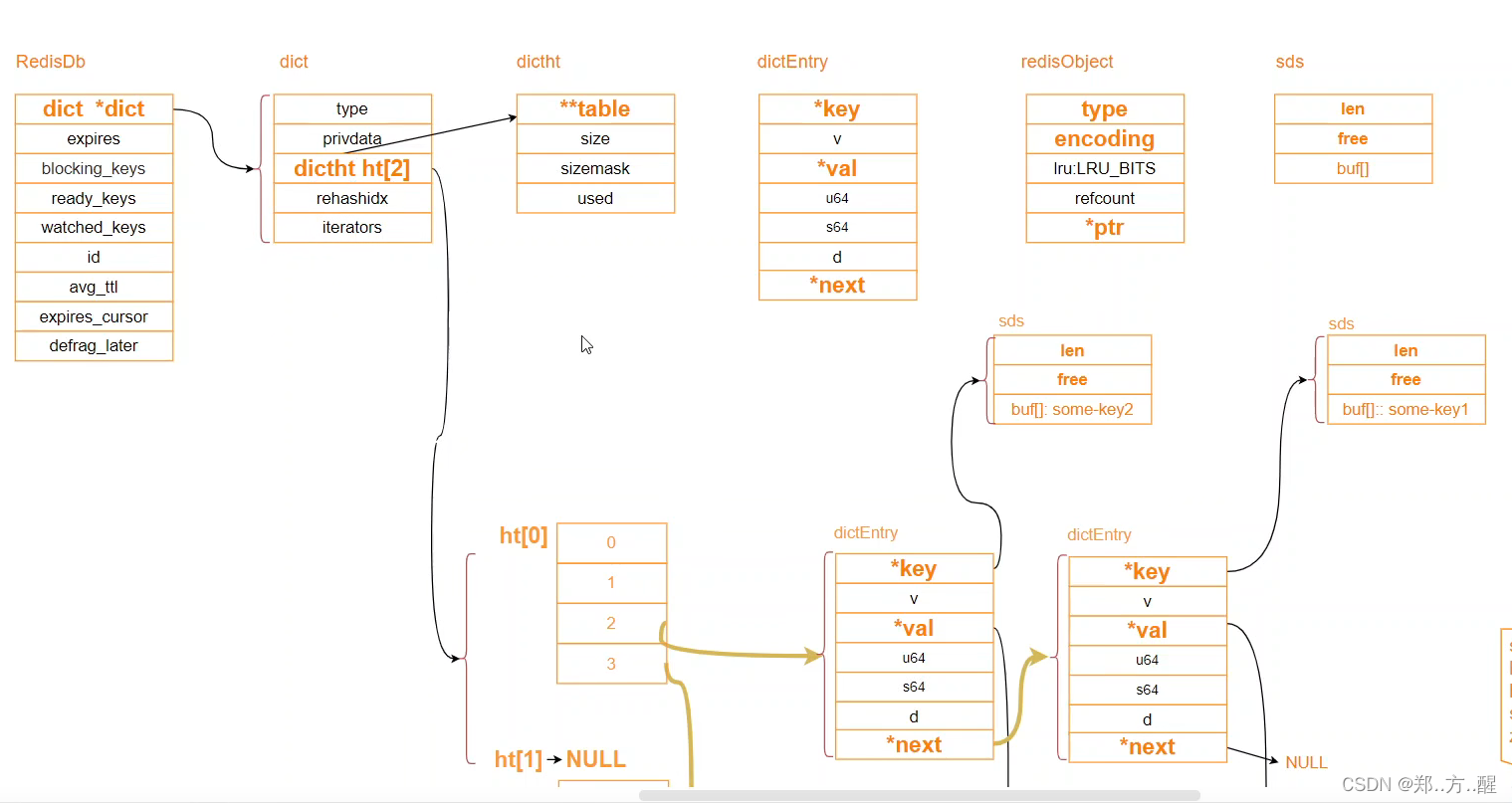
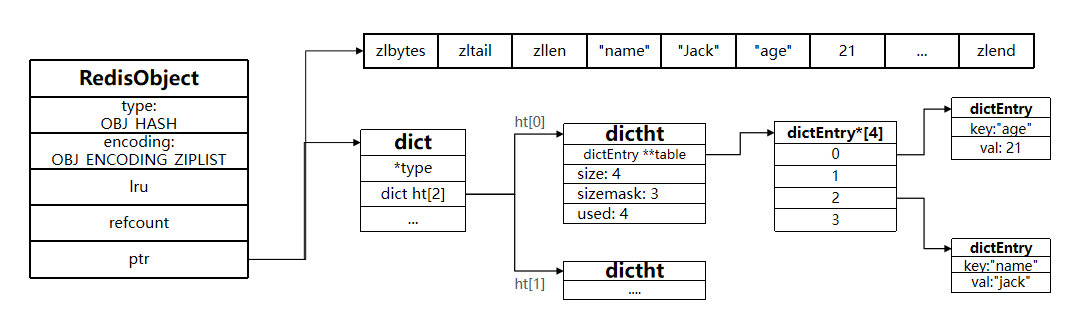
其实,底层数据结构一共有 6 种,分别是简单动态字符串、双向链表、压缩列表、哈希表、跳表和整数数组。它们和数据类型的对应关系如下图所示:
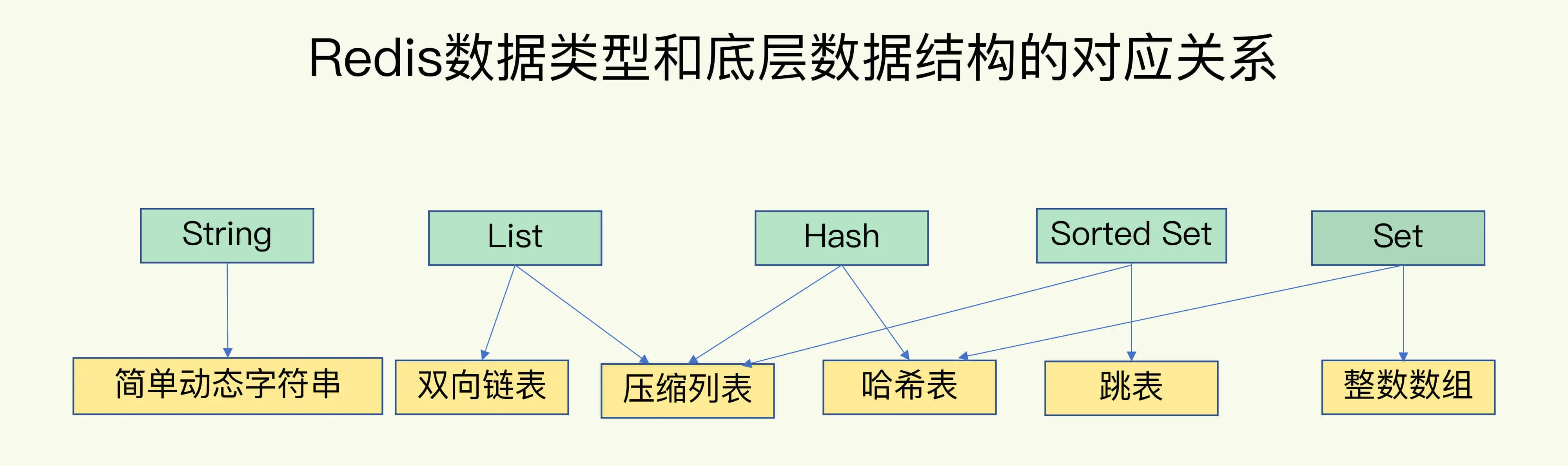
键值对的存储——哈希
为了实现从键到值的快速访问,Redis 使用了一个哈希表来保存所有键值对。哈希表随机访问数据的时间复杂度是 O(1) ,这个查找过程主要依赖于哈希计算,和数据量的多少并没有直接关系。也就是说,不管哈希表里有 10 万个键还是 100 万个键,我们只需要一次计算就能找到相应的键。
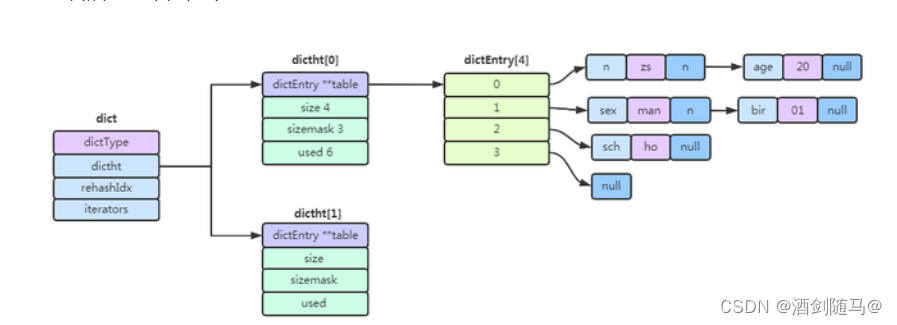
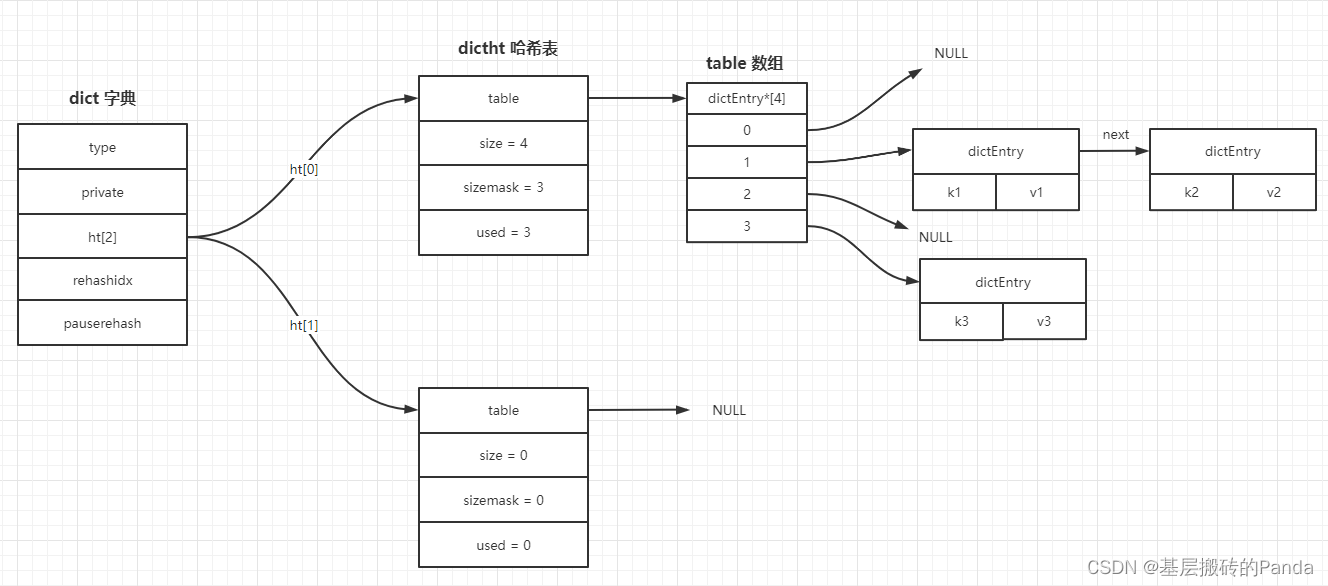
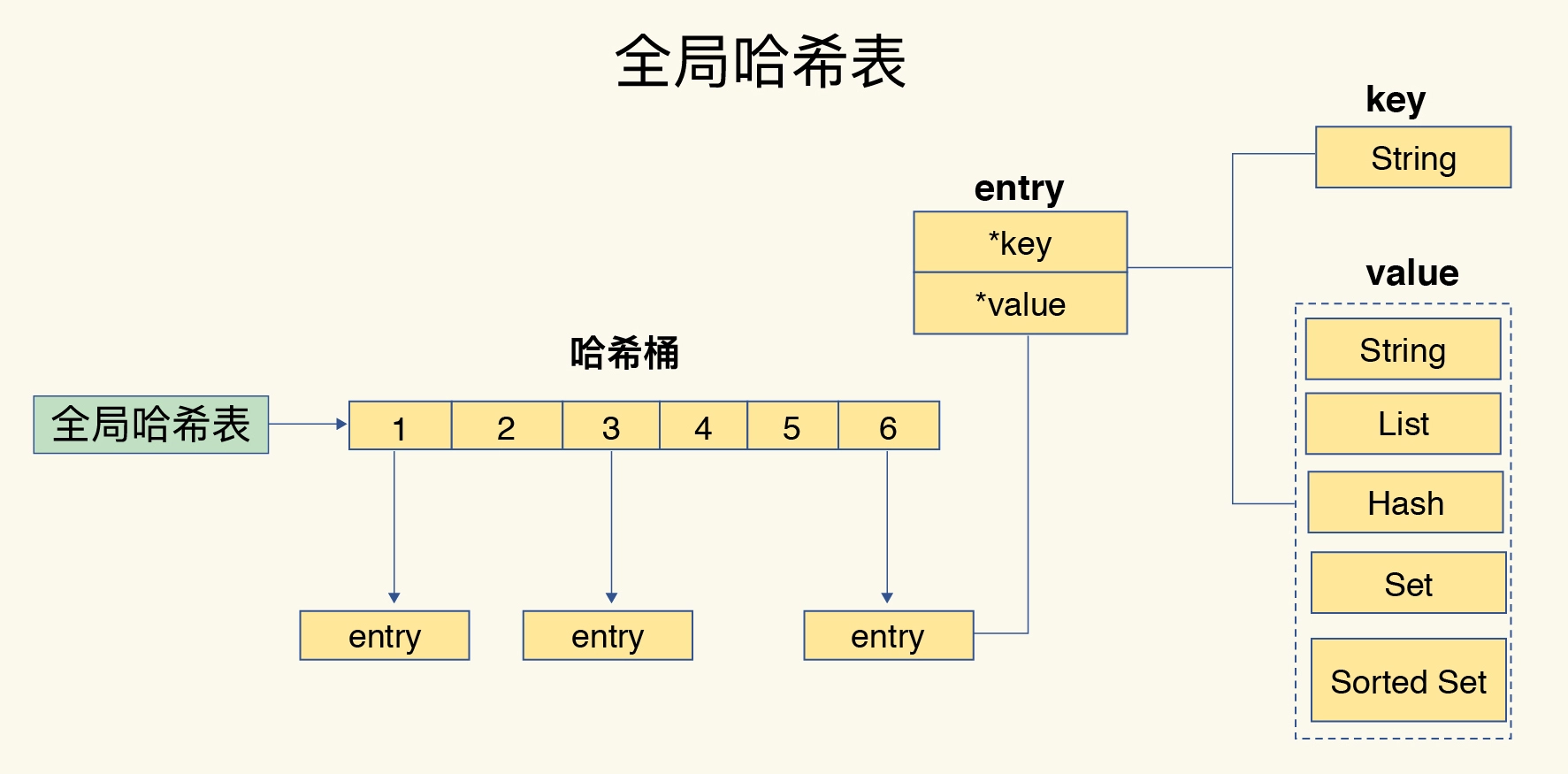
一个哈希表,其实就是一个数组,数组的每个元素称为一个哈希桶。所以,哈希表是由多个哈希桶组成的,每个哈希桶中保存了键值对数据。
这里要注意一点,哈希桶中的元素保存的并不是值本身,而是指向具体值的指针。这也就是说,不管值是 String,还是集合类型,哈希桶中的元素都是指向它们的指针。
如下图,哈希桶中的 entry 元素中保存了key和value指针,分别指向了实际的键和值,不管值是String还是集合,也可以通过*value指针被查找到,下图详细描述了这个关系:
哈希冲突
使用哈希存储数据,不可避免的会发生哈希冲突的情况。
而哈希冲突有很多种解决方案,详情请看算法-hash散列表查找详解
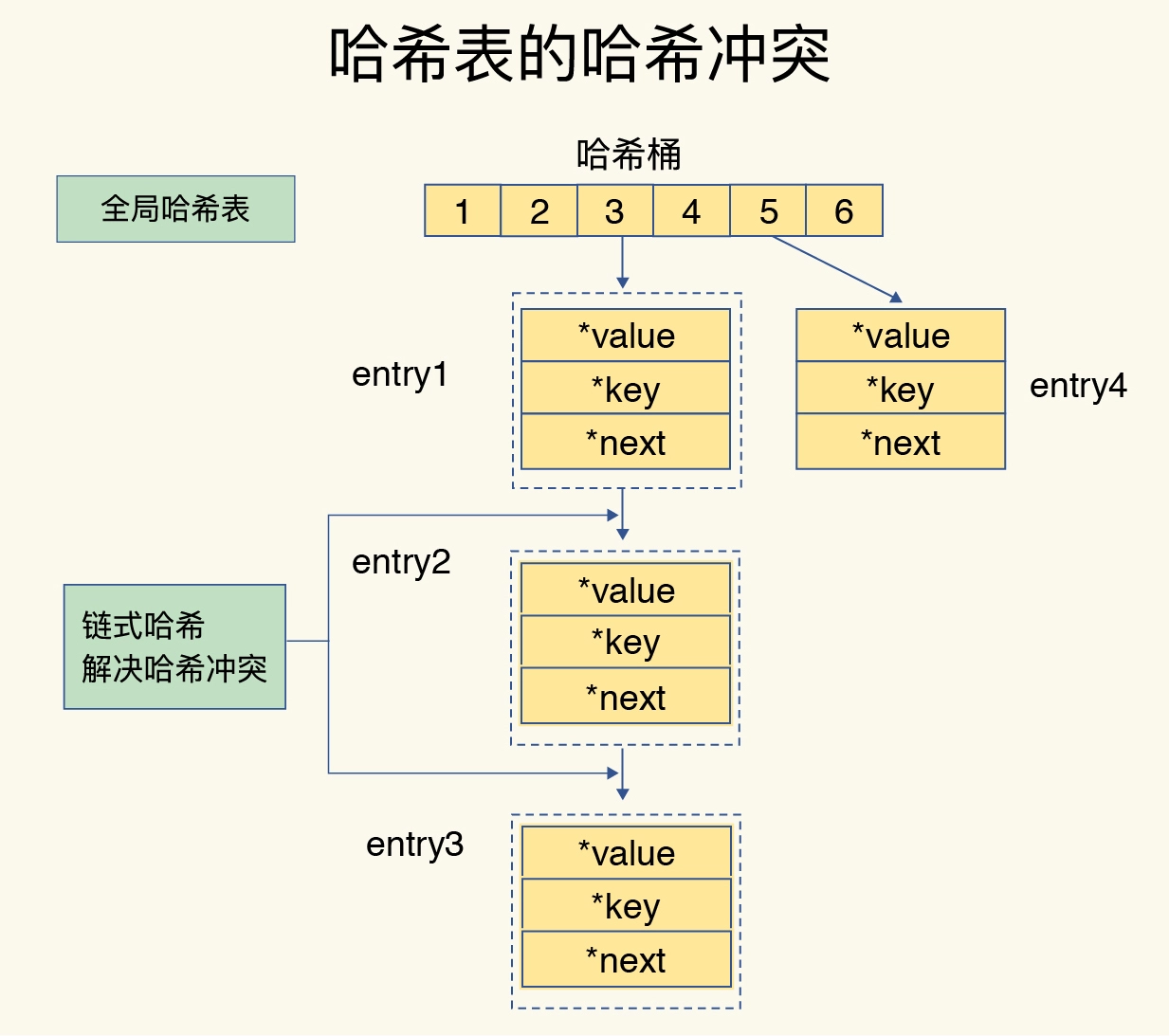
而redis解决哈希冲突的方式,就是使用拉链法的链式哈希。链式哈希也很容易理解,就是指发生哈希冲突时,同一个哈希桶中的多个元素用一个链表来保存,它们之间依次用指针连接。
如下图所示:entry1、entry2 和 entry3 都需要保存在哈希桶 3 中,导致了哈希冲突。此时,entry1 元素会通过一个next指针指向 entry2,同样,entry2 也会通过next指针指向 entry3。这样一来,即使哈希桶 3 中的元素有 100 个,我们也可以通过 entry 元素中的指针,把它们连起来。这就形成了一个链表,也叫作哈希冲突链。
redis解决哈希冲突过多的方式——rehash
上面我们说到,hash冲突时,会在冲突的hash上拉出来一个链表,哈希冲突链上的元素只能通过指针逐一查找再操作,如果哈希表里写入的数据越来越多,哈希冲突可能也会越来越多,这就会导致某些哈希冲突链过长,进而导致这个链上的元素查找耗时长,效率降低。
(小tip:用过Java的可能会知道,HashMap解决hash冲突就是使用拉链法,与redis不同,hashmap为了提高效率会将链表升级为红黑树,redis则使用rehash的方式)
rehash 也就是增加现有的哈希桶数量,让逐渐增多的 entry 元素能在更多的桶之间分散保存,减少单个桶中的元素数量,从而减少单个桶中的冲突。
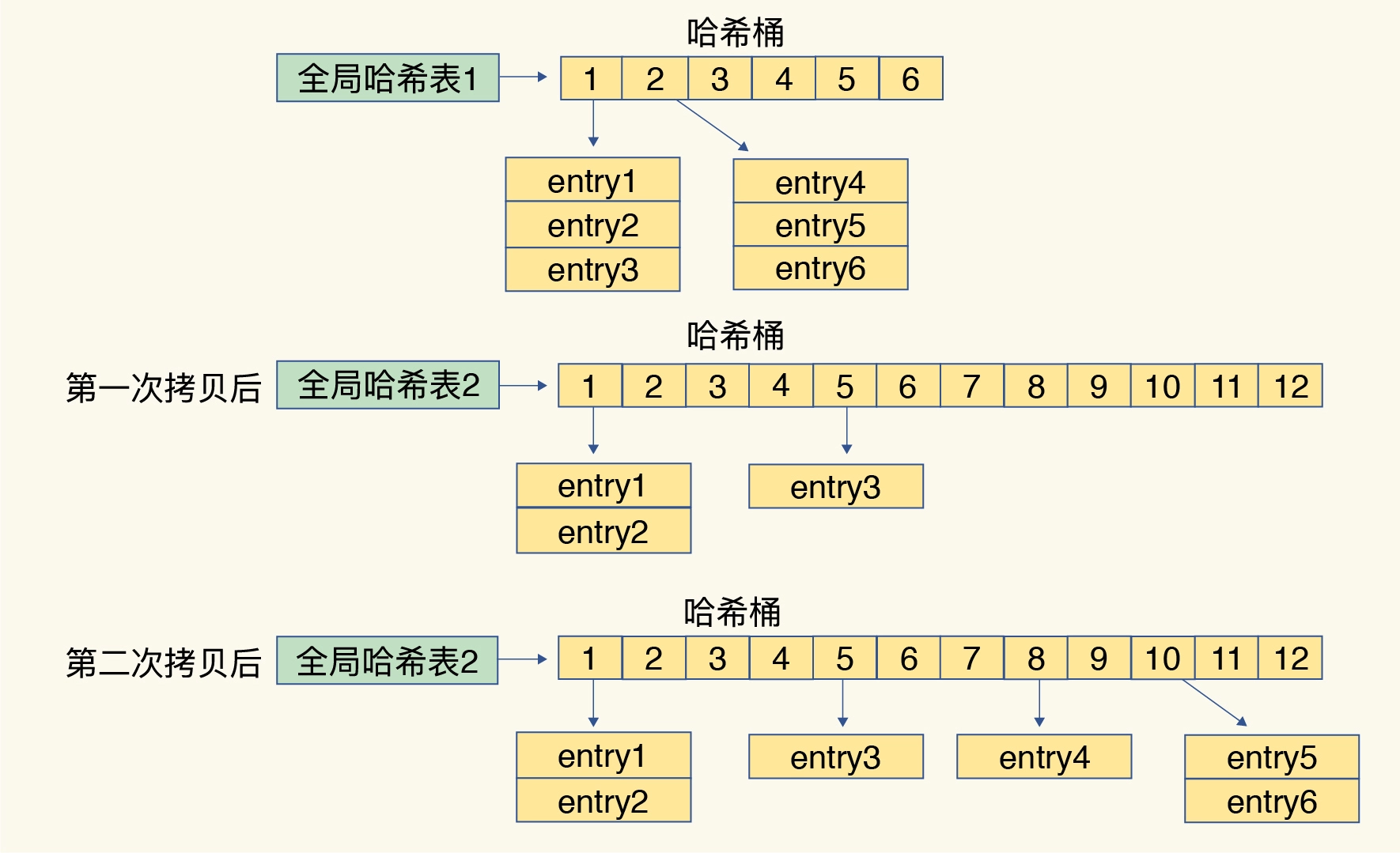
为了使 rehash 操作更高效,Redis 默认使用了两个全局哈希表:哈希表 1 和哈希表 2。一开始,当你刚插入数据时,默认使用哈希表 1,此时的哈希表 2 并没有被分配空间。随着数据逐步增多,Redis 开始执行 rehash,这个过程分为三步:
- 给哈希表 2 分配更大的空间,例如是当前哈希表 1 大小的两倍;
- 把哈希表 1 中的数据重新映射并拷贝到哈希表 2 中;
- 释放哈希表 1 的空间。
到此,我们就可以从哈希表 1 切换到哈希表 2,用增大的哈希表 2 保存更多数据,而原来的哈希表 1 留作下一次 rehash 扩容备用。
这个过程看似简单,但是第二步涉及大量的数据拷贝,如果一次性把哈希表 1 中的数据都迁移完,会造成 Redis 线程阻塞,无法服务其他请求。此时,Redis 就无法快速访问数据了。
渐进式hash
为了避免以上问题,Redis 采用了渐进式 rehash。
简单来说就是在第二步拷贝数据时,Redis 仍然正常处理客户端请求,每处理一个请求时,从哈希表 1 中的第一个索引位置开始,顺带着将这个索引位置上的所有 entries 拷贝到哈希表 2 中;等处理下一个请求时,再顺带拷贝哈希表 1 中的下一个索引位置的 entries。如下图所示:
这样就巧妙地把一次性大量拷贝的开销,分摊到了多次处理请求的过程中,避免了耗时操作,保证了数据的快速访问。
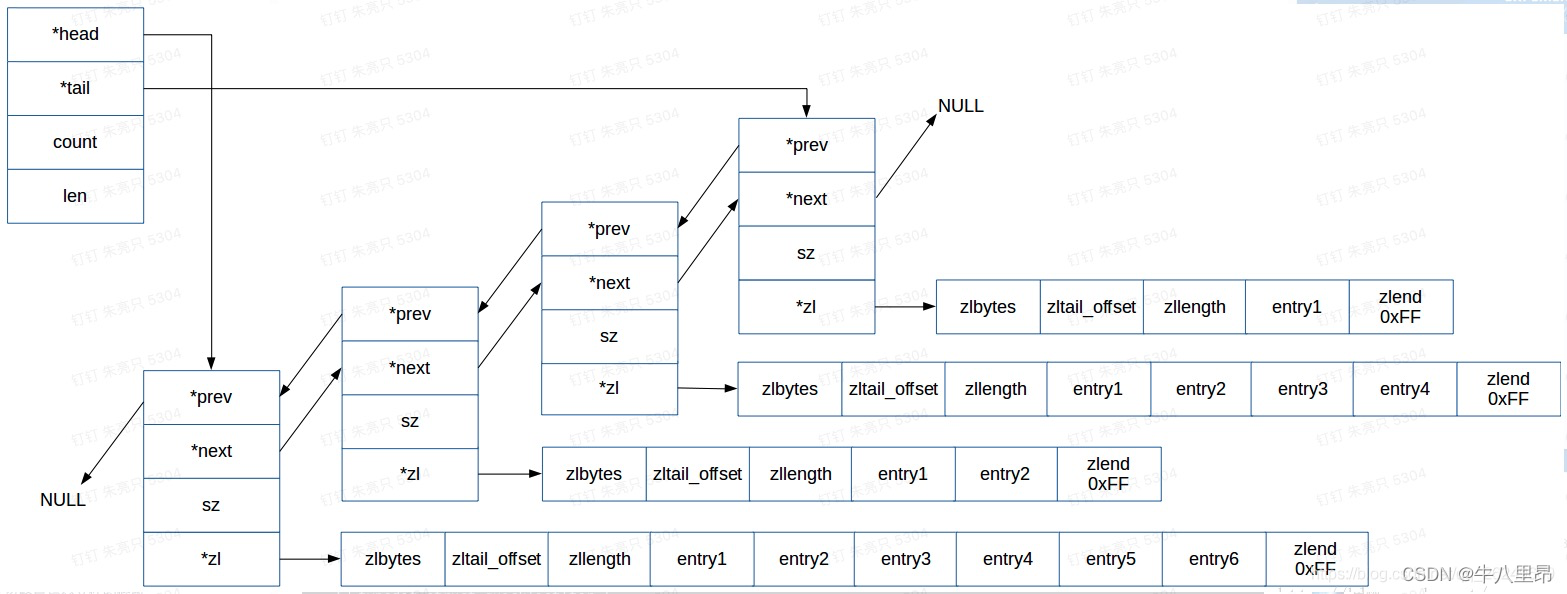
双向链表
双向链表也叫双链表,是链表的一种,它的每个数据结点中都有两个指针,分别指向直接后继和直接前驱。所以,从双向链表中的任意一个结点开始,都可以很方便地访问它的前驱结点和后继结点。
关于链表大家应该都不陌生,详情可以翻阅数据结构-线性表详解(类C语言版)
数组
数组相信刚接触计算机的同学们就接触了,这里也不再赘述,详情可以翻阅数据结构-数组详解(类C语言版)
压缩链表
Redis 3.0 的 List 对象在数据量比较少的情况下,会采用「压缩列表」作为底层数据结构的实现,它的优势是节省内存空间,并且是内存紧凑型的数据结构。
压缩列表的最大特点,就是它被设计成一种内存紧凑型的数据结构,占用一块连续的内存空间,不仅可以利用 CPU 缓存,而且会针对不同长度的数据,进行相应编码,这种方法可以有效地节省内存开销。
因此,Redis 对象(List 对象、Hash 对象、Zset 对象)包含的元素数量较少,或者元素值不大的情况才会使用压缩列表作为底层数据结构。
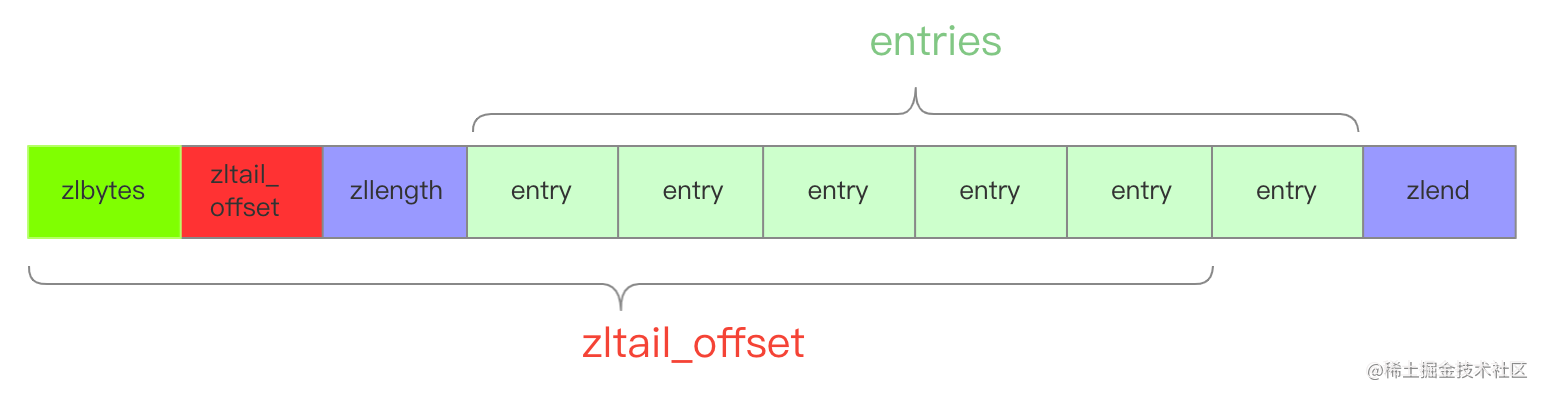
压缩列表实际上类似于一个数组,数组中的每一个元素都对应保存一个数据。和数组不同的是,压缩列表在表头有三个字段 zlbytes、zltail 和 zllen,分别表示列表长度、列表尾的偏移量和列表中的 entry 个数;压缩列表在表尾还有一个 zlend,表示列表结束。
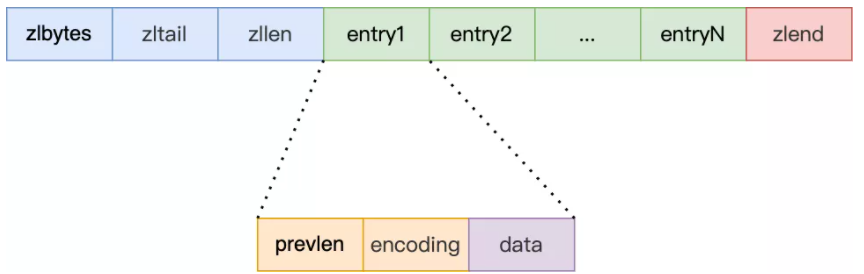
压缩列表有四个字段:
① zlbytes,记录整个压缩列表占用对内存字节数;
② zltail,记录压缩列表「尾部」节点距离起始地址由多少字节,也就是列表尾的偏移量;
③ zllen,记录压缩列表包含的节点数量;
④ zlend,标记压缩列表的结束点,固定值 0xFF(十进制255)。
压缩列表节点包含三部分内容:
① prevlen,记录了「前一个节点」的长度;
② encoding,记录了当前节点实际数据的类型以及长度;
③ data,记录了当前节点的实际数据
当我们往压缩列表中插入数据时,压缩列表就会根据数据是字符串还是整数,以及数据的大小,会使用不同空间大小的 prevlen 和 encoding 这两个元素里保存的信息,这种根据数据大小和类型进行不同的空间大小分配的设计思想,正是 Redis 为了节省内存而采用的。
分别说下,prevlen 和 encoding 是如何根据数据的大小和类型来进行不同的空间大小分配。
压缩列表里的每个节点中的 prevlen 属性都记录了「前一个节点的长度」,而且 prevlen 属性的空间大小跟前一个节点长度值有关,比如:
① 如果前一个节点的长度小于 254 字节,那么 prevlen 属性需要用 1 字节的空间来保存这个长度值;
② 如果前一个节点的长度大于等于 254 字节,那么 prevlen 属性需要用 5 字节的空间来保存这个长度值;
encoding 属性的空间大小跟数据是字符串还是整数,以及字符串的长度有关:
① 如果当前节点的数据是整数,则 encoding 会使用 1 字节的空间进行编码。
② 如果当前节点的数据是字符串,根据字符串的长度大小,encoding 会使用 1 字节/2字节/5字节的空间进行编码。
在压缩列表中,如果我们要查找定位第一个元素和最后一个元素,可以通过表头三个字段的长度直接定位,复杂度是 O(1)。而查找其他元素时,就没有这么高效了,只能逐个查找,此时的复杂度就是 O(N) 了。因此压缩列表不适合保存过多的元素。
压缩链表的连锁更新
压缩列表除了查找复杂度高的问题,还有一个问题。
压缩列表新增某个元素或修改某个元素时,如果空间不不够,压缩列表占用的内存空间就需要重新分配。而当新插入的元素较大时,可能会导致后续元素的 prevlen 占用空间都发生变化,从而引起「连锁更新」问题,导致每个元素的空间都要重新分配,造成访问压缩列表性能的下降。
压缩列表的缺陷
空间扩展操作也就是重新分配内存,因此连锁更新一旦发生,就会导致压缩列表占用的内存空间要多次重新分配,这就会直接影响到压缩列表的访问性能。
所以说,虽然压缩列表紧凑型的内存布局能节省内存开销,但是如果保存的元素数量增加了,或是元素变大了,会导致内存重新分配,最糟糕的是会有「连锁更新」的问题。
因此,压缩列表只会用于保存的节点数量不多的场景,只要节点数量足够小,即使发生连锁更新,也是能接受的。
在后来的版本中,新增设计了两种数据结构:quicklist(Redis 3.2 引入) 和 listpack(Redis 5.0 引入)。这两种数据结构的设计目标,就是尽可能地保持压缩列表节省内存的优势,同时解决压缩列表的「连锁更新」的问题。
整数数组和压缩列表在查找时间复杂度方面并没有很大的优势,那为什么 Redis 还会把它们作为底层数据结构呢?
两方面原因:
1、内存利用率,数组和压缩列表都是非常紧凑的数据结构,它比链表占用的内存要更少。Redis是内存数据库,大量数据存到内存中,此时需要做尽可能的优化,提高内存的利用率。
2、数组对CPU高速缓存支持更友好,所以Redis在设计时,集合数据元素较少情况下,默认采用内存紧凑排列的方式存储,同时利用CPU高速缓存不会降低访问速度。当数据元素超过设定阈值后,避免查询时间复杂度太高,转为哈希和跳表数据结构存储,保证查询效率。
一个数据类型都对应了很多种底层数据结构。以List为例,什么情况下是双向链表,反之又在什么情况下是压缩列表呢?还是说是并存状态?
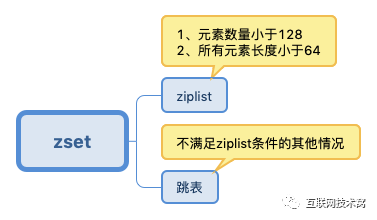
1、Hash 和 ZSet 是数据量少采用压缩列表存储,数据量变大转为哈希表或跳表存储
2、但 List 不是这样,是并存的状态,List 是双向链表 + 压缩列表
ziplist、quicklist、listpack 这三者是如何协助redis的数据类型的呢?
ziplist设计初衷是节省内存,List/Hash/ZSet底层都用到了ziplist。其中Hash/ZSet当元素很少时,采用ziplist存储,每个数据项紧凑排列。
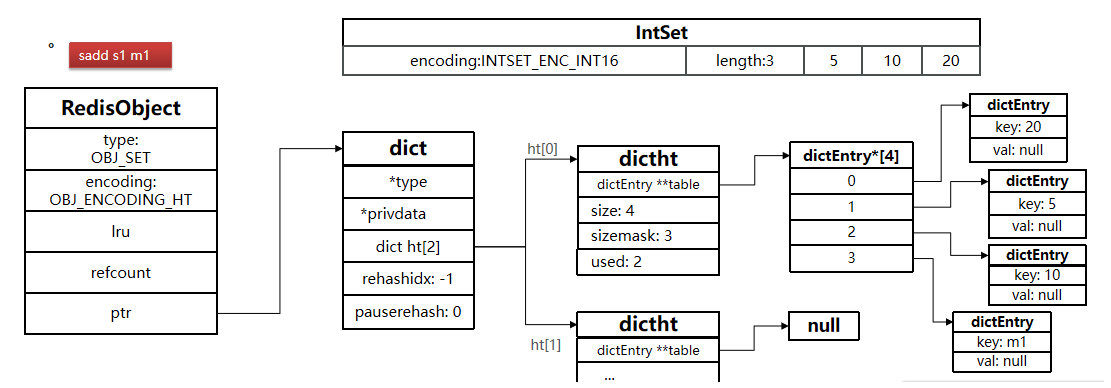
Set如果存储都是int类型,底层是intset,否则会转换为hashtbale。
ZSet如果数据较多,会转换为skplist + hashtable存储。
List是采用quicklist + ziplist结合的方式使用,因为List的操作需要频繁修改头尾的数据,避免ziplist级联更新,所以用quicklist(链表)+ ziplist缓解这种情况。
listpack是为了取代ziplist设计的,目的也是节省内存,但没有ziplist级联更新问题,目前只用在Stream上,其它数据类型后期待替换,不过时间会比较漫长。
跳表
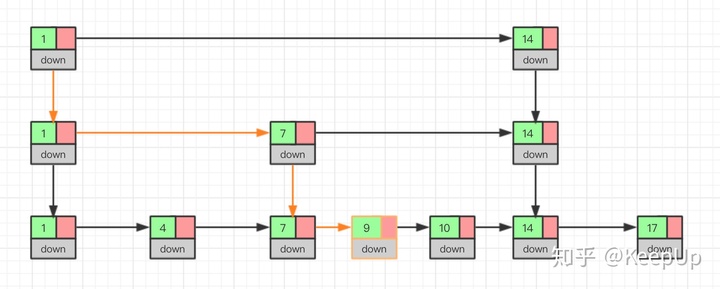
简单来说,跳表在链表的基础上,增加了多级索引,通过索引位置的几个跳转,实现数据的快速定位,如下图所示:

如果我们要在链表中查找 33 这个元素,只能从头开始遍历链表,查找 6 次,直到找到 33 为止。此时,复杂度是 O(N),查找效率很低。
为了提高查找速度,我们来增加一级索引:从第一个元素开始,每两个元素选一个出来作为索引。这些索引再通过指针指向原始的链表。例如,从前两个元素中抽取元素 1 作为一级索引,从第三、四个元素中抽取元素 11 作为一级索引。此时,我们只需要 4 次查找就能定位到元素 33 了。
如果我们还想再快,可以再增加二级索引:从一级索引中,再抽取部分元素作为二级索引。例如,从一级索引中抽取 1、27、100 作为二级索引,二级索引指向一级索引。这样,我们只需要 3 次查找,就能定位到元素 33 了。
可以看到,这个查找过程就是在多级索引上跳来跳去,最后定位到元素。这也正好符合“跳”表的叫法。当数据量很大时,跳表的查找复杂度就是 O(logN)。
关于跳表,更多详情请点击:
https://blog.csdn.net/yjw123456/article/details/105159817/
https://baijiahao.baidu.com/s?id=1710441201075985657&wfr=spider&for=pc
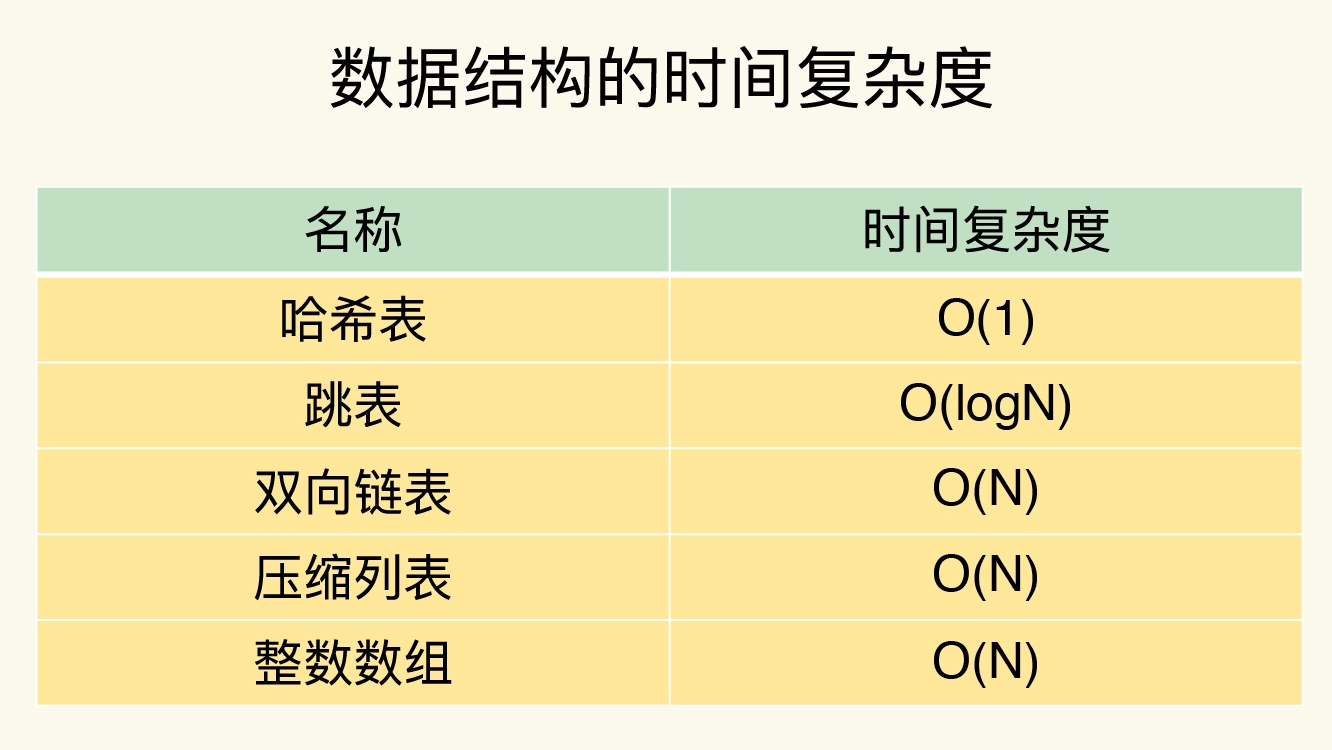
各种数据结构的时间复杂度
参考资料
蒋德钧老师 对于redis的讲解
https://www.cnblogs.com/panxianhao/p/15993924.html
https://www.yuque.com/docs/share/9677b389-1af5-4d22-805b-ee2d651100d9