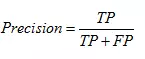本文代码及数据集来自《Python大数据分析与机器学习商业案例实战》
集成模型简介
集成学习模型使用一系列弱学习器(也称为基础模型或基模型)进行学习,并将各个弱学习器的结果进行整合,从而获得比单个学习器更好的学习效果。集成学习模型的常见算法有Bagging算法和Boosting算法两种。Bagging算法的典型机器学习模型为随机森林模型,而Boosting算法的典型机器学习模型则为AdaBoost、GBDT、XGBoost和LightGBM模型。
- Bagging算法
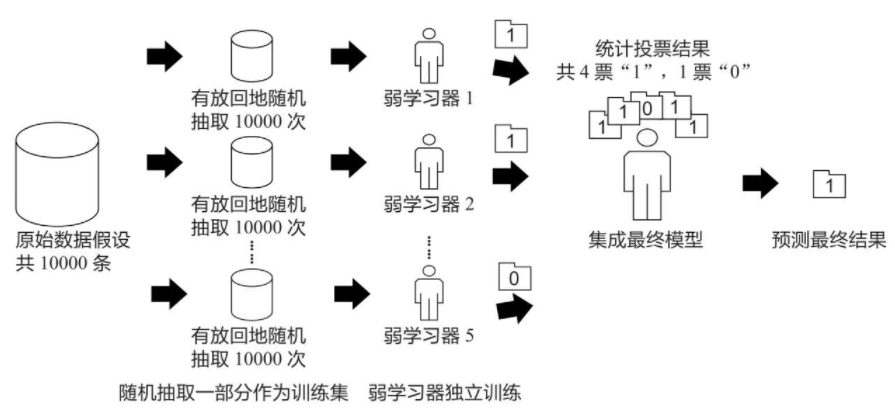
假设原始数据共有10000条,从中随机有放回地抽取10000次数据构成一个新的训练集,每次使用一个训练集训练一个弱学习器。这样有放回地随机抽取n次后,训练结束时就能获得由不同的训练集训练出的n个弱学习器,根据这n个弱学习器的预测结果,按照“少数服从多数”的原则,获得一个更加准确、合理的最终预测结果。在分类问题中是用n个弱学习器投票的方式获取最终结果,在回归问题中则是取n个弱学习器的平均值作为最终结果。
- Boosting算法
Boosting算法的本质是将弱学习器提升为强学习器,它和Bagging算法的区别在于:Bagging算法对待所有的弱学习器一视同仁;而Boosting算法则会对弱学习器“区别对待”,通俗来讲就是注重“培养精英”和“重视错误”。
“培养精英”就是每一轮训练后对预测结果较准确的弱学习器给予较大的权重,对表现不好的弱学习器则降低其权重。这样在最终预测时,“优秀模型”的权重是大的,相当于它可以投出多票,而“一般模型”只能投出一票或不能投票。
“重视错误”就是在每一轮训练后改变训练集的权值或概率分布,通过提高在前一轮被弱学习器预测错误的样例的权值,降低前一轮被弱学习器预测正确的样例的权值,来提高弱学习器对预测错误的数据的重视程度,从而提升模型的整体预测效果。

随机森林模型的基本原理
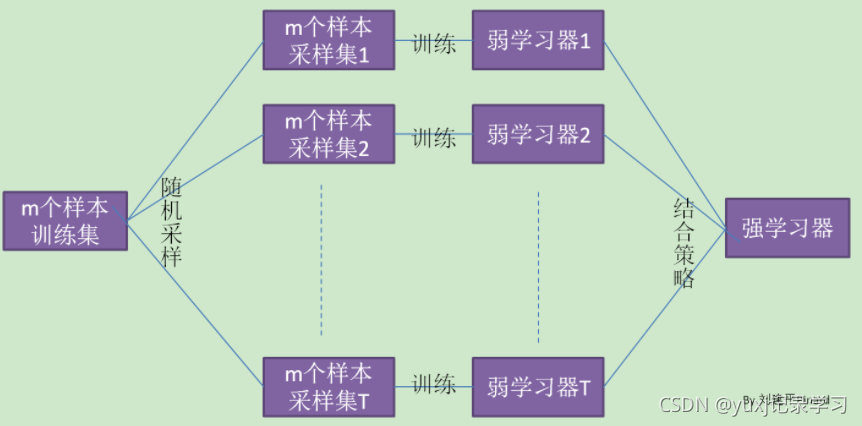
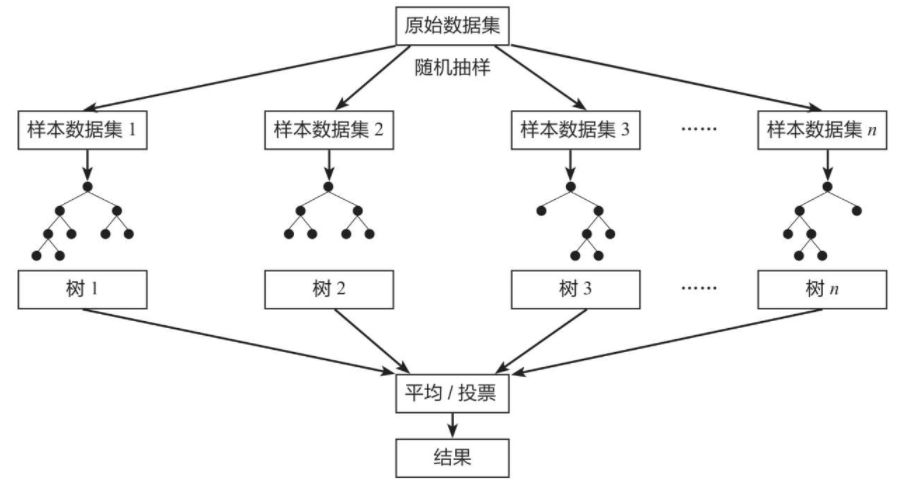
随机森林(Random Forest)是一种经典的Bagging模型,其弱学习器为决策树模型。如下图所示,随机森林模型会在原始数据集中随机抽样,构成n个不同的样本数据集,然后根据这些数据集搭建n个不同的决策树模型,最后根据这些决策树模型的平均值(针对回归模型)或者投票情况(针对分类模型)来获取最终结果。
案例:股票预测
书上案例用的tushare现在已经不支持了,要使用tushare pro,调用它的接口需要登录注册获取token,关键是需要达到一定积分才有权限。呵呵,果断弃用。下面直接把代码贴出来,学习下模型从头到尾的搭建过程。
# 多因子模型搭建
# **1.引入之后需要用到的库**
import tushare as ts
import numpy as np
import pandas as pd
import talib
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
import warnings
warnings.filterwarnings("ignore")# **2.股票数据处理与衍生变量生成**
# 1.股票基本数据获取
df = ts.get_k_data('000002',start='2015-01-01',end='2019-12-31')
df = df.set_index('date')# 2.简单衍生变量构造
df['close-open'] = (df['close'] - df['open'])/df['open']
df['high-low'] = (df['high'] - df['low'])/df['low']df['pre_close'] = df['close'].shift(1)
df['price_change'] = df['close']-df['pre_close']
df['p_change'] = (df['close']-df['pre_close'])/df['pre_close']*100
其中close-open表示(收盘价-开盘价)/开盘价;high-low表示(最高价-最低价)/最低价;pre_close表示昨日收盘价,用shift(1)将close列的所有数据向下移动1行并形成新的1列,如果是shift(-1)则表示向上移动1行;price_change表示今日收盘价-昨日收盘价,即当天的股价变化;p_change表示当天股价变化的百分比,也称为当天股价的涨跌幅。
# 3.移动平均线相关数据构造
df['MA5'] = df['close'].rolling(5).mean()
df['MA10'] = df['close'].rolling(10).mean()
df.dropna(inplace=True) # 删除空值
MA是移动平均线的意思,“平均”是指最近n天收盘的算术平均值,“移动”是指在计算中始终采用最近n天的价格数据。以MA5的计算为例,假设已知下表中的数据。

根据上述数据,5号的MA5值为(1.2+1.4+1.6+1.8+2.0)/5=1.6,而6号的MA5值则为(1.4+1.6+1.8+2.0+2.2)/5=1.8,依此类推。将一段时期内股价的移动平均值连成曲线,即为移动平均线。同理,MA10为从计算当天起前10天的股价平均值。
# 4.通过Ta_lib库构造衍生变量
df['RSI'] = talib.RSI(df['close'], timeperiod=12)
df['MOM'] = talib.MOM(df['close'], timeperiod=5)
df['EMA12'] = talib.EMA(df['close'], timeperiod=12)
df['EMA26'] = talib.EMA(df['close'], timeperiod=26)
df['MACD'], df['MACDsignal'], df['MACDhist'] = talib.MACD(df['close'], fastperiod=12, slowperiod=26, signalperiod=9)
df.dropna(inplace=True)
df.tail() #各种金融指标,不解释了# **3.特征变量和目标变量提取**
X = df[['close', 'volume', 'close-open', 'MA5', 'MA10', 'high-low', 'RSI', 'MOM', 'EMA12', 'MACD', 'MACDsignal', 'MACDhist']]
y = np.where(df['price_change'].shift(-1)> 0, 1, -1)
最后一行代码中使用了NumPy库中的where()函数,传入的3个参数的含义分别为判断条件、满足条件的赋值、不满足条件的赋值。其中df[‘price_change’].shift(-1)是利用shift()函数将price_change(股价变化)这一列的所有数据向上移动1行,这样就获得了每一行对应的下一天的股价变化。因此,这里的判断条件就是下一天的股价变化是否大于0,如果大于0,说明下一天股价涨了,则y赋值为1;如果不大于0,说明下一天股价不变或跌了,则y赋值为-1。预测结果就只有1或-1两种分类。
# **3.训练集和测试集数据划分**
X_length = X.shape[0] # shape属性获取X的行数和列数,shape[0]即表示行数
split = int(X_length * 0.9)
X_train, X_test = X[:split], X[split:]
y_train, y_test = y[:split], y[split:]
需要注意的是,划分要按照时间序列进行,而不能用train_test_split()函数进行随机划分。这是因为股价的变化趋势具有时间性特征,而随机划分会破坏这种特征。因此,将前90%的数据作为训练集,后10%的数据作为测试集。
# **4.模型搭建**
model = RandomForestClassifier(max_depth=3, n_estimators=10, min_samples_leaf=10, random_state=1)
model.fit(X_train, y_train)# 模型使用与评估
# **1.预测下一天的涨跌情况**
y_pred = model.predict(X_test)
print(y_pred)a = pd.DataFrame() # 创建一个空DataFrame
a['预测值'] = list(y_pred)
a['实际值'] = list(y_test)
a.head()y_pred_proba = model.predict_proba(X_test)
print(y_pred_proba[0:5])# **2.模型准确度评估**
score = accuracy_score(y_pred, y_test)
print(score)
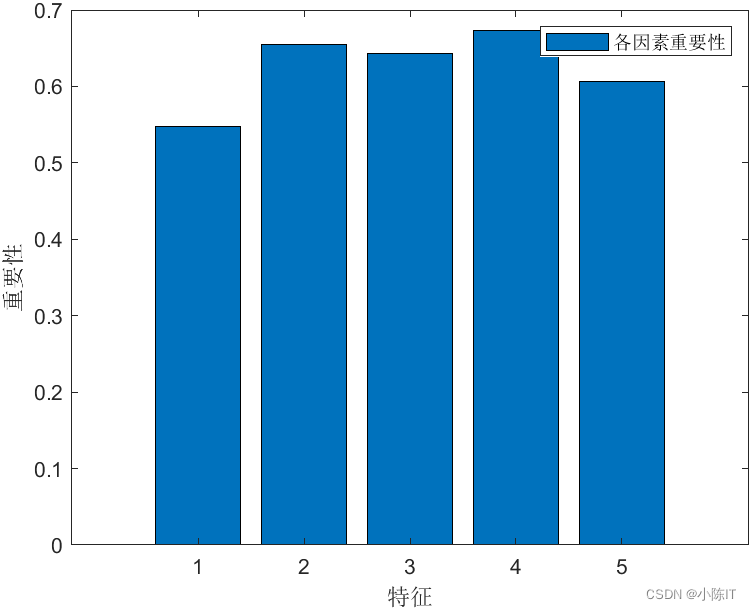
print(model.score(X_test, y_test))# **3.分析数据特征的重要性**
print(model.feature_importances_)features = X.columns
importances = model.feature_importances_
a = pd.DataFrame()
a['特征'] = features
a['特征重要性'] = importances
a = a.sort_values('特征重要性', ascending=False)
print(a)# 参数调优
from sklearn.model_selection import GridSearchCV # 网格搜索合适的超参数
parameters = {'n_estimators':[5, 10, 20], 'max_depth':[2, 3, 4, 5], 'min_samples_leaf':[5, 10, 20, 30]}
new_model = RandomForestClassifier(random_state=1) # 构建分类器
grid_search = GridSearchCV(new_model, parameters, cv=6, scoring='accuracy') # cv=6表示交叉验证6次,scoring='roc_auc'表示以ROC曲线的AUC评分作为模型评价准则, 默认为'accuracy', 即按准确度评分grid_search.fit(X_train, y_train) # 传入数据
print(grid_search.best_params_) # 输出参数的最优值# 收益回测曲线绘制
X_test['prediction'] = model.predict(X_test)
X_test['p_change'] = (X_test['close'] - X_test['close'].shift(1)) / X_test['close'].shift(1)
X_test['origin'] = (X_test['p_change'] + 1).cumprod()
X_test['strategy'] = (X_test['prediction'].shift(1) * X_test['p_change'] + 1).cumprod()
X_test[['strategy', 'origin']].tail()X_test[['strategy', 'origin']].dropna().plot()
plt.gcf().autofmt_xdate()
plt.show()
随机森林模型参数
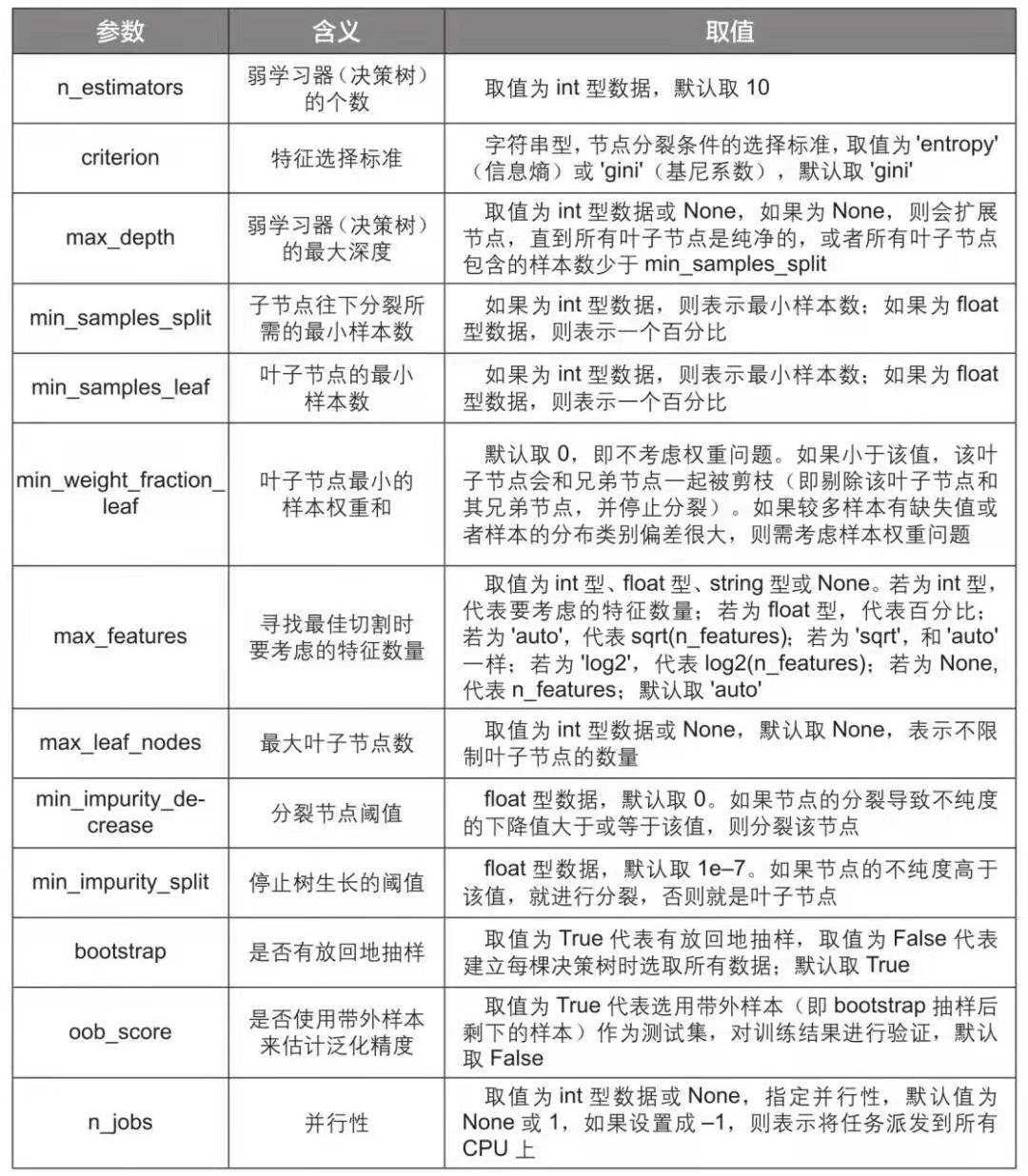
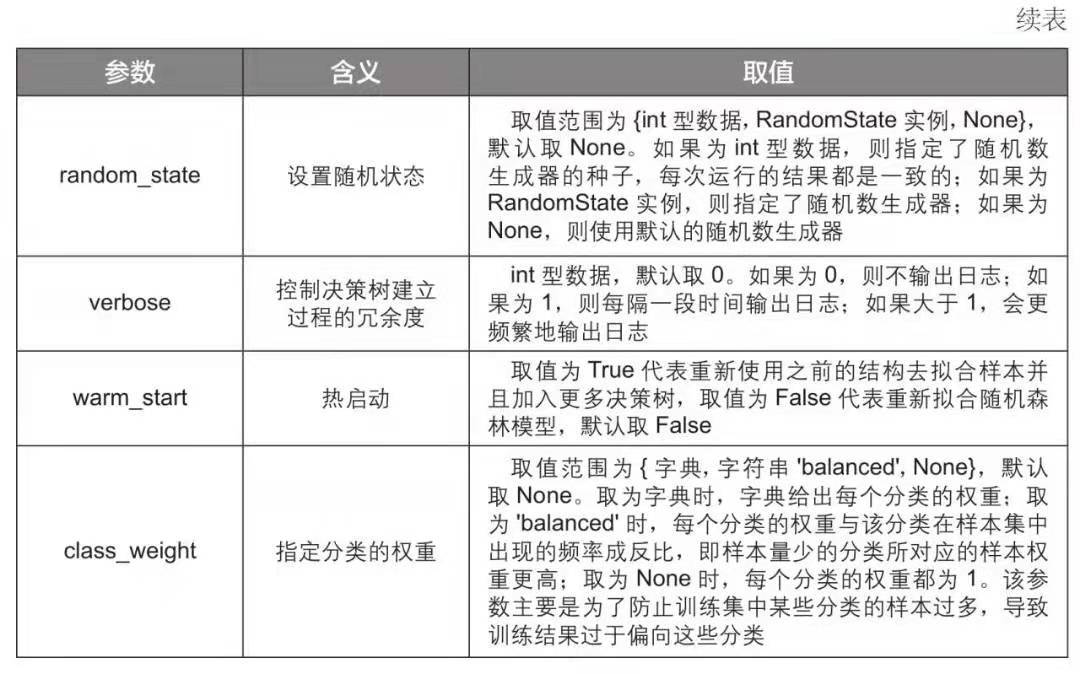
随机森林模型是一种非常重要的集成模型,它集成了决策树模型的众多优点,又规避了决策树模型容易过度拟合等缺点,在实战中应用较为广泛,需要好好掌握。



![[Machine Learning Algorithm] 随机森林(Random Forest)](https://images0.cnblogs.com/blog2015/764050/201506/182310220134010.png)