随机森林原理及代码实现
机器学习系列
第一章 随机森林原理及代码实现
文章目录
- 随机森林原理及代码实现
- 机器学习系列
- 前言
- 一、集成算法是什么?
- 二、随机森林是什么
- 三、 数据预处理
- 3.1 先来看一下我们的文本数据
- 3.2 预处理
- 3.3 统计评论情感值积极与消极的占比
- 二、使用步骤
- 参数介绍(4个)
- 属性
- 1.模型构建
- 2.参数调参方法
- 总结
前言
例如:随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了机器学习的基础内容。
一、集成算法是什么?
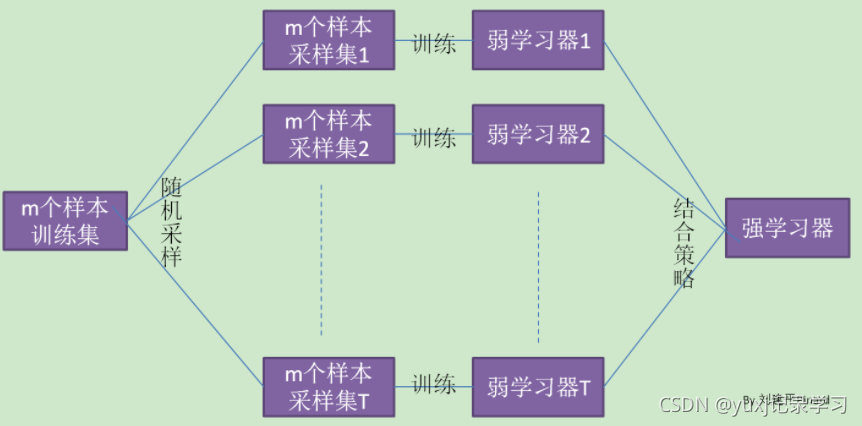
集成学习是通过在数据上构建多个模型,集成所有模型的建模结果,目的是获取比单个模型更好得到回归或分类现象。多个模型集成成为的模型叫做集成评估器(ensemble estimator),组成集成评估器的每个模型都叫做基评估器
(base estimator)。在这里,对于随机森林来说,它的基评估器就是决策树。
常见的集成算法有袋装法Bagging(举例随机森林)、提升法Boosting(举例梯度提升树 GBDT、Adaboost)和stacking。
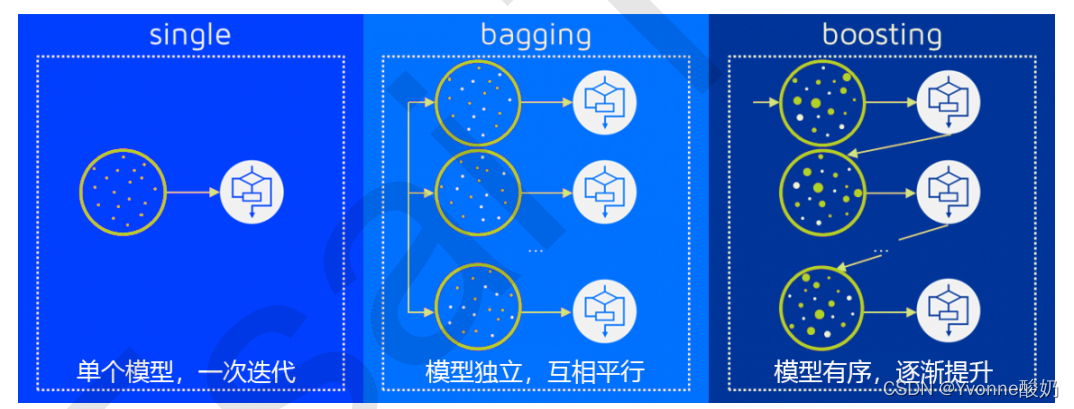
袋装法是构建多个相互独立的评估器,然后对其预测的结果求平均值或多数表决原则。
可是,如果每个树模型都比较弱,整体平均完也还是会很弱,那么这时候提升法Boosting就登场了。
提升法是
每个基评估器都是相关的,是按照顺序一一构建的。核心思想就是在一次次的建模过程当中,逐渐将模型方向调整到对难以评估的样本进行强烈预测。简单来说就是,在先采样,即样本1,然后构建一个模型,即模型1,对于样本中预测错误的样本,在下一轮采样中会增加它们的权重,一直重复上述操作。
二、随机森林是什么
三、 数据预处理
3.1 先来看一下我们的文本数据

数据解读:
情感标注列:1表示文本内容为积极的,0表示文本内容为消极的
content:文本
3.2 预处理
将数据分成2列,一列评论,一列情感值,对文本列进行分词、去停用词
数据分列:
import random
import numpy as np
import csv
import jieba file_path = '224.csv'
jieba.load_userdict("dict/否定词.txt") #用户词典,帮助分词更成功
jieba.load_userdict("dict/负面评价词语(中文).txt")
jieba.load_userdict("dict/负面情感词语(中文).txt")
jieba.load_userdict("dict/正面评价词语(中文).txt")
jieba.load_userdict("dict/正面情感词语(中文).txt")#加载文件
with open(file_path, 'r', encoding='UTF-8') as f:reader = csv.reader(f)rows = [row for row in reader]# 将读取出来的语料转为list
review_data = np.array(rows).tolist()# 打乱语料的顺序
random.shuffle(review_data)review_list = []
sentiment_list = []
# 第一列为差评/好评, 第二列为评论
for words in review_data:review_list.append(words[1])sentiment_list.append(words[0])
数据分词、去停用词:
在这里,由于此文本为知乎舆论文本,我获取不到知乎评论数据的分词词典,就用了现在主流的一些词典。
词典的获取链接:词典链接
提取码:pony
import re
import jiebastopword_path = 'D:/pythonzx/douban_sentiment_analysis-master/data/stopwords.txt'#加载停用词表
def load_stopwords(file_path):stop_words = []with open(file_path, encoding='UTF-8') as words:stop_words.extend([i.strip() for i in words.readlines()])return stop_words#分词、去停用词
def review_to_text(review):stop_words = load_stopwords(stopword_path)# 去除英文review = re.sub("[^\u4e00-\u9fa5^a-z^A-Z]", '', review)review = jieba.cut(review)# 去掉停用词if stop_words:all_stop_words = set(stop_words)words = [w for w in review if w not in all_stop_words]return words# 用于训练的评论,文字
review_train = [' '.join(review_to_text(review)) for review in review_list]
# 对于训练评论对应的好评/差评,01
sentiment_train = sentiment_list
查看预处理结果:

3.3 统计评论情感值积极与消极的占比
#训练的样本数中,积极评论占xx条
sum=0
for i in range(len(sentiment_train)):if sentiment_train[i] == "1":sum = sum + 1
print(sum)
#训练的样本数中,消极极评论占xx条
sum=0
for i in range(len(sentiment_train)):if sentiment_train[i] == "0":sum = sum + 1
print(sum)
为了训练模型构建的准确性,建议最好的积极消极各占一半
二、使用步骤
参数介绍(4个)
random_state:目的让模型稳定下来。
用来设置分枝中的随机模式的参数,默认None,在高维度时随机性会表现更明显,低维度的数据
(比如鸢尾花数据集),随机性几乎不会显现。输入任意整数,会一直长出同一棵树,让模型稳定下来。
n_estimators:控制森林中数目的数量。
这是森林中树木的数量,即基基评估器的数量。这个参数对随机森林模型的精确性影响是单调的,n_estimators
越大,模型的效果往往越好。
为了让每棵树(基分类器)尽量不一样,除了random_state,还有bootstarp。
bootstrap:默认True,代表采用这种有放回的随机抽样技术
在一个含有n个样本的原始训练集,我们进行随机采样,每次采样一个样本,并在抽取下一个样本的之前将这个样本放回原始训练集中,这样采集n次,最终得到一个和原始训练集一样大的,n个样本组成的自助集。
由于是随机采样,这样每次的自助集个原始数据集不同,它用来训练我们的基分类器。
oob_score:默认True,是否用袋外数据来测试我们的模型。当n和n_estimators足够大的时候,袋外数据约有37%的数据会被浪费掉。
37%怎么来的:
在一个自助集里一个样本会被抽到的概率:
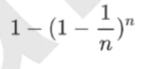
概率收敛于1-(1/e),约等于0.632。
那么在一个自助集里一个样本不会被抽到的概率为:
1-0.632=0.368,约等于37%。
属性
estimators_:查看森林中数的情况
oob_score_:计算袋外数据的预测准确率

1.模型构建
代码如下(示例):
# 划分训练集、测试集
from sklearn.model_selection import train_test_split
Xtrain, Xtest, Ytrain, Ytest = train_test_split(xtrain_vec,sentiment_train,test_size=0.3)
# 模型训练
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
clf = DecisionTreeClassifier(random_state=1)
rfc = RandomForestClassifier(random_state=1)
clf = clf.fit(Xtrain,Ytrain)
rfc = rfc.fit(Xtrain,Ytrain)
score_c = clf.score(Xtest,Ytest)
score_r = rfc.score(Xtest,Ytest)
print("Single Tree:{}".format(score_c),"Random Forest:{}".format(score_r))
2.参数调参方法
1、学习率曲线
# 这是森林中树木的数量,即基基评估器的数量。这个参数对随机森林模型的精确性影响是单调的
# n_estimators越大,模型的效果往往越好
# n_estimators的学习曲线
superpa = []
for i in range(200):rfc = RandomForestClassifier(n_estimators=i+1,n_jobs=-1,random_state=1)rfc_s = cross_val_score(rfc,xtrain_vec,sentiment_train,cv=10).mean()superpa.append(rfc_s)
# 打印分数最高时的分数和n_estimators的值
print(max(superpa),superpa.index(max(superpa))+1)
plt.figure(figsize=[20,5])
plt.plot(range(1,201),superpa)
plt.show()

可以看到此时n_estimators为138时,分数最高。
将上面n_estimators的最佳值放到下面的模型训练中去,寻找max_depth的最佳。
# max_depth的学习曲线
superpa = []
for i in range(20):rfc = RandomForestClassifier(max_depth=i+1,n_jobs=-1,random_state=1,n_estimators=138)rfc_s = cross_val_score(rfc,xtrain_vec,sentiment_train,cv=10).mean()superpa.append(rfc_s)
# 打印分数最高时的分数和max_depth的值
print(max(superpa),superpa.index(max(superpa))+1)
plt.figure(figsize=[20,5])
plt.plot(range(1,21),superpa)
plt.show()
2、网格调优
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score #K折交叉验证
from sklearn.model_selection import GridSearchCV # 网格调参
from sklearn.model_selection import RandomizedSearchCV
#分类问题,先建立一个分类器
clf = RandomForestClassifier(n_estimators=20)#给定参数搜索范围
param_test={'max_depth':[i for i in range(1, 25, 2)],'n_estimators':[i for i in range(1, 150, 5)],"min_samples_split": [i for i in range(1, 10, 2)]}#RandomSearch+CV选取超参数
random_search = RandomizedSearchCV(clf,param_distributions =param_test,n_iter=20,cv=5)random_search.fit(xtrain_vec,sentiment_train)print("随机搜索最优得分:",random_search.best_score_)
print("随机搜索最优参数组合:\n",random_search.best_params_)
总结
本篇在这里介绍了对评论情感分类采用了随机森林的方法,感觉预测效果一般,仅有60%左右的正确率,排除是文本标签是人工标注所导致的误差,在后面我们采用别的机器学习模型尝试一下,像是朴素贝叶斯等。


![[Machine Learning Algorithm] 随机森林(Random Forest)](https://images0.cnblogs.com/blog2015/764050/201506/182310220134010.png)