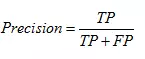随机森林-----集成算法之一,分类,回归和特征选择
算法步骤:
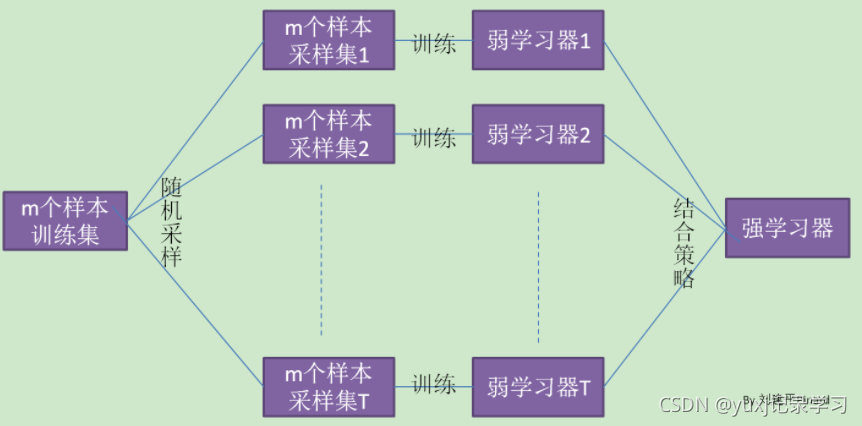
1.用有抽样放回的方法(bootstrap)从样本集中选取n个样本作为一个训练集
2.用抽样得到的样本集生成一棵决策树。在生成的每一个结点:
1.随机不重复地选择d个特征
2.利用这d个特征分别对样本集进行划分,找到最佳的划分特征(可用基尼系数、增益率或者信息增益判别)
3.重复步骤1到步骤2共k次,k即为随机森林中决策树的个数。
4.用训练得到的随机森林对测试样本进行预测,并用票选法决定预测的结果。
优点:
1) 每棵树都选择部分样本及部分特征,一定程度避免过拟合;
2) 每棵树随机选择样本并随机选择特征,使得具有很好的抗噪能力,性能稳定;
3) 能处理很高维度的数据,并且不用做特征选择;
4) 适合并行计算;
5) 实现比较简单;
6) 对部分特征缺失不敏感。
缺点:
1) 参数较复杂;
2) 模型训练和预测都比较慢;
在 sklearn中,随机森林的函数模型是:
RandomForestClassifier(bootstrap=True, class_weight=None, criterion='gini',
max_depth=None, max_features='auto', max_leaf_nodes=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=10, n_jobs=1,
oob_score=False, random_state=None, verbose=0,
warm_start=False)
A. max_features:随机森林允许单个决策树使用特征的最大数量
Auto/None :简单地选取所有特征,每颗树都可以利用他们。这种情况下,每颗树都没有任何的限制。
sqrt :此选项是每颗子树可以利用总特征数的平方根个。 例如,如果变量(特征)的总数是100,所以每颗子树只能取其中的10个。“log2”是另一种相似类型的选项。
0.2:此选项允许每个随机森林的子树可以利用变量(特征)数的20%。如果想考察的特征x%的作用, 我们可以使用“0.X”的格式。
B. n_estimators: 在利用最大投票数或平均值来预测之前,你想要建立子树的数量
C. min_sample_leaf: 如果您以前编写过一个决策树,你能体会到最小样本叶片大小的重要性。 叶是决策树的末端节点。 较小的叶子使模型更容易捕捉训练数据中的噪声。 一般来说,我更偏向于将最小叶子节点数目设置为大于50。在你自己的情况中,你应该尽量尝试多种叶子大小种类,以找到最优的那个。
算法步骤:
1.用有抽样放回的方法(bootstrap)从样本集中选取n个样本作为一个训练集
2.用抽样得到的样本集生成一棵决策树。在生成的每一个结点:
1.随机不重复地选择d个特征
2.利用这d个特征分别对样本集进行划分,找到最佳的划分特征(可用基尼系数、增益率或者信息增益判别)
3.重复步骤1到步骤2共k次,k即为随机森林中决策树的个数。
4.用训练得到的随机森林对测试样本进行预测,并用票选法决定预测的结果。
优点:
1) 每棵树都选择部分样本及部分特征,一定程度避免过拟合;
2) 每棵树随机选择样本并随机选择特征,使得具有很好的抗噪能力,性能稳定;
3) 能处理很高维度的数据,并且不用做特征选择;
4) 适合并行计算;
5) 实现比较简单;
6) 对部分特征缺失不敏感。
缺点:
1) 参数较复杂;
2) 模型训练和预测都比较慢;
在 sklearn中,随机森林的函数模型是:
RandomForestClassifier(bootstrap=True, class_weight=None, criterion='gini',
max_depth=None, max_features='auto', max_leaf_nodes=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=10, n_jobs=1,
oob_score=False, random_state=None, verbose=0,
warm_start=False)
A. max_features:随机森林允许单个决策树使用特征的最大数量
Auto/None :简单地选取所有特征,每颗树都可以利用他们。这种情况下,每颗树都没有任何的限制。
sqrt :此选项是每颗子树可以利用总特征数的平方根个。 例如,如果变量(特征)的总数是100,所以每颗子树只能取其中的10个。“log2”是另一种相似类型的选项。
0.2:此选项允许每个随机森林的子树可以利用变量(特征)数的20%。如果想考察的特征x%的作用, 我们可以使用“0.X”的格式。
B. n_estimators: 在利用最大投票数或平均值来预测之前,你想要建立子树的数量
C. min_sample_leaf: 如果您以前编写过一个决策树,你能体会到最小样本叶片大小的重要性。 叶是决策树的末端节点。 较小的叶子使模型更容易捕捉训练数据中的噪声。 一般来说,我更偏向于将最小叶子节点数目设置为大于50。在你自己的情况中,你应该尽量尝试多种叶子大小种类,以找到最优的那个。
适用情景:
数据维度相对低(几十维),同时对准确性有较高要求时。
因为不需要很多参数调整就可以达到不错的效果,基本上不知道用什么方法的时候都可以先试一下随机森林。
数据维度相对低(几十维),同时对准确性有较高要求时。
因为不需要很多参数调整就可以达到不错的效果,基本上不知道用什么方法的时候都可以先试一下随机森林。
面试经典问题:
随机森林为什么不容易产生过拟合的现象? 因为随机森林的随机性。
随机森林的随机性表现在哪里? 随机森林的随机性体现在每颗树的训练样本是随机的,树中每个节点的分裂属性集合也是随机选择确定的。
随机森林与决策树的关系? 随机森林顾名思义,是用随机的方式建立一个森林,森林里面有很多的决策树组成,随机森林的每一棵决策树之间是没有关联的。
随机森林的优缺点和适用情景?
随机森林为什么不容易产生过拟合的现象? 因为随机森林的随机性。
随机森林的随机性表现在哪里? 随机森林的随机性体现在每颗树的训练样本是随机的,树中每个节点的分裂属性集合也是随机选择确定的。
随机森林与决策树的关系? 随机森林顾名思义,是用随机的方式建立一个森林,森林里面有很多的决策树组成,随机森林的每一棵决策树之间是没有关联的。
随机森林的优缺点和适用情景?
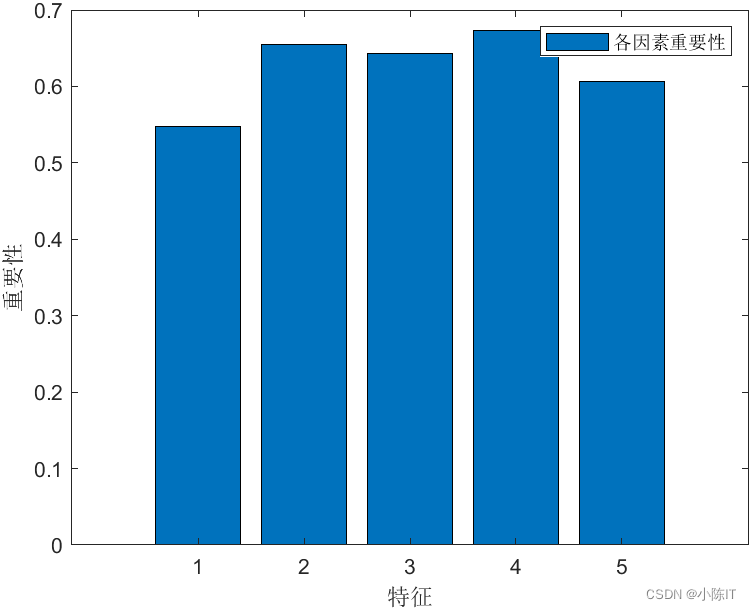
特征选择:
提供了两种特征选择的方法:平均不纯度减少 mean decrease impurity 和 平均精确率减少 mean decrease accuracy。
提供了两种特征选择的方法:平均不纯度减少 mean decrease impurity 和 平均精确率减少 mean decrease accuracy。
1)平均不纯度减少
随机森林由多个决策树构成。决策树中的每一个节点都是关于某个特征的条件,为的是将数据集按照不同的响应变量一分为二。利用不纯度可以确定节点(最优条件),对于分类问题,通常采用 基尼不纯度 或者 信息增益 ,对于回归问题,通常采用的是 方差 或者最小二乘拟合。当训练决策树的时候,可以计算出每个特征减少了多少树的不纯度。对于一个决策树森林来说,可以算出每个特征平均减少了多少不纯度,并把它平均减少的不纯度作为特征选择的值。
python实现:
from sklearn.datasets import load_boston
from sklearn.ensemble import RandomForestRegressor
import numpy as np
#Load boston housing dataset as an example
boston = load_boston()
X = boston["data"]
Y = boston["target"]
names = boston["feature_names"]
rf = RandomForestRegressor()
rf.fit(X, Y)
print "Features sorted by their score:"
print sorted(zip(map(lambda x: round(x, 4), rf.feature_importances_), names),
reverse=True)
2)平均精确率减少
直接度量每个特征对模型精确率的影响。主要思路是打乱每个特征的特征值顺序,并且度量顺序变动对模型的精确率的影响。很明显,对于不重要的变量来说,打乱顺序对模型的精确率影响不会太大,但是对于重要的变量来说,打乱顺序就会降低模型的精确率。
from sklearn.cross_validation import ShuffleSplit
from sklearn.metrics import r2_score
from collections import defaultdict
X = boston["data"]
Y = boston["target"]
rf = RandomForestRegressor()
scores = defaultdict(list)
#crossvalidate the scores on a number of different random splits of the data
for train_idx, test_idx in ShuffleSplit(len(X), 100, .3):
X_train, X_test = X[train_idx], X[test_idx]
Y_train, Y_test = Y[train_idx], Y[test_idx]
r = rf.fit(X_train, Y_train)
acc = r2_score(Y_test, rf.predict(X_test))
for i in range(X.shape[1]):
X_t = X_test.copy()
np.random.shuffle(X_t[:, i])
shuff_acc = r2_score(Y_test, rf.predict(X_t))
scores[names[i]].append((acc-shuff_acc)/acc)
print "Features sorted by their score:"
print sorted([(round(np.mean(score), 4), feat) for
feat, score in scores.items()], reverse=True)

随机森林由多个决策树构成。决策树中的每一个节点都是关于某个特征的条件,为的是将数据集按照不同的响应变量一分为二。利用不纯度可以确定节点(最优条件),对于分类问题,通常采用 基尼不纯度 或者 信息增益 ,对于回归问题,通常采用的是 方差 或者最小二乘拟合。当训练决策树的时候,可以计算出每个特征减少了多少树的不纯度。对于一个决策树森林来说,可以算出每个特征平均减少了多少不纯度,并把它平均减少的不纯度作为特征选择的值。
python实现:
from sklearn.datasets import load_boston
from sklearn.ensemble import RandomForestRegressor
import numpy as np
#Load boston housing dataset as an example
boston = load_boston()
X = boston["data"]
Y = boston["target"]
names = boston["feature_names"]
rf = RandomForestRegressor()
rf.fit(X, Y)
print "Features sorted by their score:"
print sorted(zip(map(lambda x: round(x, 4), rf.feature_importances_), names),
reverse=True)
2)平均精确率减少
直接度量每个特征对模型精确率的影响。主要思路是打乱每个特征的特征值顺序,并且度量顺序变动对模型的精确率的影响。很明显,对于不重要的变量来说,打乱顺序对模型的精确率影响不会太大,但是对于重要的变量来说,打乱顺序就会降低模型的精确率。
from sklearn.cross_validation import ShuffleSplit
from sklearn.metrics import r2_score
from collections import defaultdict
X = boston["data"]
Y = boston["target"]
rf = RandomForestRegressor()
scores = defaultdict(list)
#crossvalidate the scores on a number of different random splits of the data
for train_idx, test_idx in ShuffleSplit(len(X), 100, .3):
X_train, X_test = X[train_idx], X[test_idx]
Y_train, Y_test = Y[train_idx], Y[test_idx]
r = rf.fit(X_train, Y_train)
acc = r2_score(Y_test, rf.predict(X_test))
for i in range(X.shape[1]):
X_t = X_test.copy()
np.random.shuffle(X_t[:, i])
shuff_acc = r2_score(Y_test, rf.predict(X_t))
scores[names[i]].append((acc-shuff_acc)/acc)
print "Features sorted by their score:"
print sorted([(round(np.mean(score), 4), feat) for
feat, score in scores.items()], reverse=True)

![[Machine Learning Algorithm] 随机森林(Random Forest)](https://images0.cnblogs.com/blog2015/764050/201506/182310220134010.png)