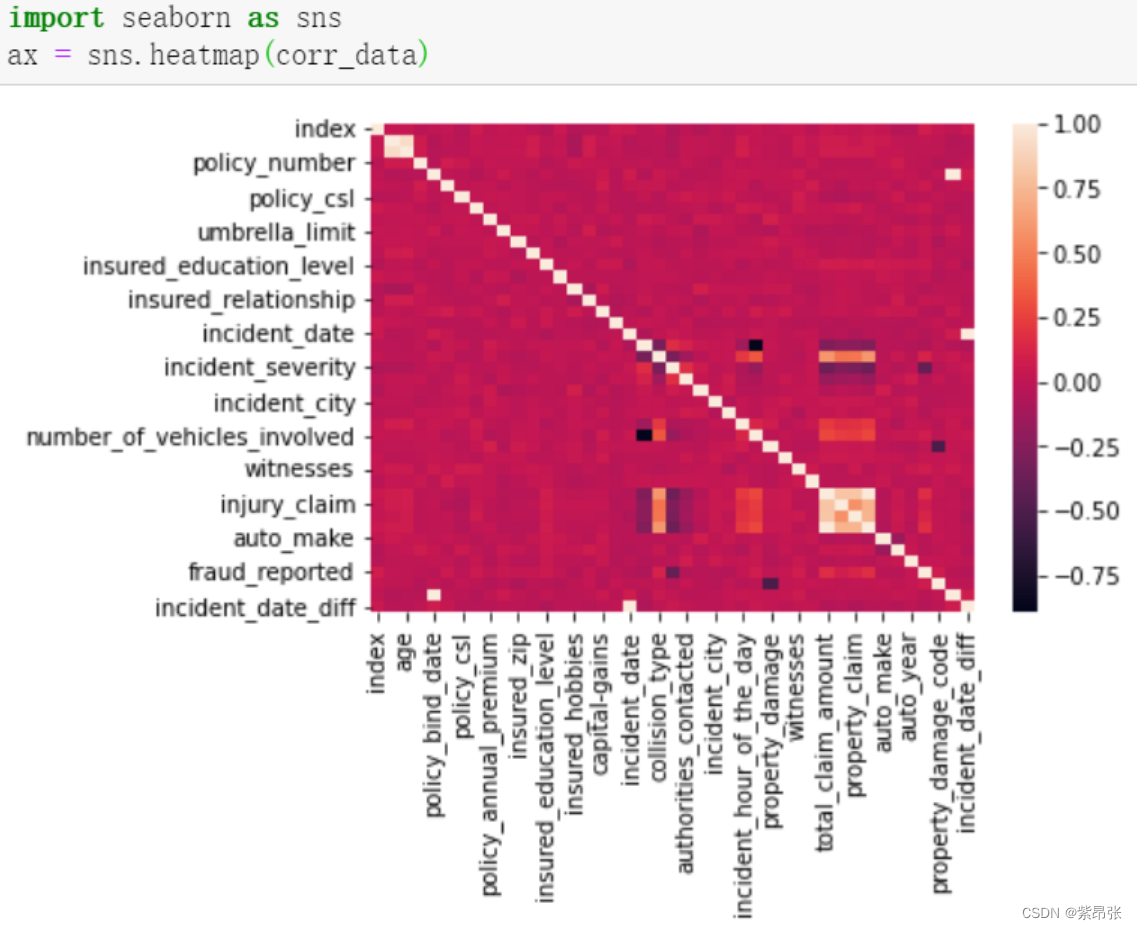
我有以下熊猫数据框Top15:

我创建了一个列来估计每个人的可引用文档数:
1
2Top15['PopEst'] = Top15['Energy Supply'] / Top15['Energy Supply per Capita']
Top15['Citable docs per Capita'] = Top15['Citable documents'] / Top15['PopEst']
我想知道人均可引用文件数量与人均能源供应之间的关系。所以我使用了.corr()方法(皮尔逊相关法):
1
2data = Top15[['Citable docs per Capita','Energy Supply per Capita']]
correlation = data.corr(method='pearson')
我想返回一个数字,但结果是:

我认为你是对的。但是你能告诉我为什么"data.corr(method='pearson')"只返回能源供应和能源供应之间的关系吗?
它没有。它应该返回一个2x2矩阵;显示其左上角的条目。如果直接将.corr应用于数据帧,它将返回所有的成对相关性;这就是为什么您随后在矩阵的对角线处观察1s(每列与自身完全相关)。见下面我的编辑。
如果你认为答案已经回答了你的问题,请考虑接受它。
我接受了你的回答,谢谢
我找不到你说的按钮。我只是按你答案旁边的上箭头
这个问题直接来源于课程"Python数据科学导论"课程。具体来说,作业3,问题9。当指导老师克里斯·布鲁克斯鼓励学生们把问题堆得满满的时候,我不认为他是说他们应该逐字地把作业中的问题贴出来。
如果没有实际的数据,很难回答这个问题,但我想您正在寻找这样的问题:
1Top15['Citable docs per Capita'].corr(Top15['Energy Supply per Capita'])
它计算两列'Citable docs per Capita'和'Energy Supply per Capita'之间的相关性。
举个例子:
1
2
3
4
5
6
7
8
9import pandas as pd
df = pd.DataFrame({'A': range(4), 'B': [2*i for i in range(4)]})
A B
0 0 0
1 1 2
2 2 4
3 3 6
然后
1df['A'].corr(df['B'])
按预期给予1。
现在,如果您更改一个值,例如
1
2
3
4
5
6
7df.loc[2, 'B'] = 4.5
A B
0 0 0.0
1 1 2.0
2 2 4.5
3 3 6.0
命令
1df['A'].corr(df['B'])
收益率
10.99586
它仍然接近1,如预期的那样。
如果直接将.corr应用于数据帧,它将返回列之间的所有成对关联;这就是为什么您随后在矩阵的对角线处观察1s(每个列与自身完全关联)。
1df.corr()
因此将返回
1
2
3A B
A 1.000000 0.995862
B 0.995862 1.000000
在您展示的图形中,仅表示相关矩阵的左上角(我假设)。
有些情况下,您的解决方案中可能会有NaNs—请查看本文中的示例。
如果要筛选高于/低于某个阈值的条目,可以检查此问题。如果你想绘制一个相关系数的热图,你可以检查这个答案,然后如果你遇到重叠轴标签的问题,检查下面的文章。
这可以按行应用吗?
@厄运博士:是的,它只需要一系列,例如,df.loc[1, :].corr(df.loc[2, :])也可以。对于整个数据帧,您可以简单地转置:df.T.corr()。
不过,我尝试了您的建议,即使在使用df.loc[2,'b']=4.5更改了B列中的A值之后,计算仍然返回1。也许我只是对计算有点困惑
@厄运博士:很难帮助,因为我不知道你的密码。我是否正确理解,我上面的例子在您的案例中返回了1,而不是0.99586?
是的,我用了你的密码。它总是返回1
尝试将pandas导入为pd import numpy作为np示例df=pd.dataframe(np.random.randn(5,5),np.arange(5))打印示例df.iloc[1,:]打印示例df.iloc[2,:]打印示例df.iloc[1,:]corr(示例df.iloc[2,:])
@厄运博士:不能繁殖。用np.random.seed(0)我得到0.771616539283。你能试试这个种子吗?
让我们在聊天中继续讨论。
因为数据集是维度500*10,所以dataset.corr()应该给出矩阵10*10的输出,但是它给出的输出矩阵是1*1…为什么?
@劳拉:不知道你的数据很难说。也许你可以打开一个新的问题,并以此作为参考!?确保包括一个可重复的例子。
我也遇到了同样的问题。似乎Citable Documents per Person是一个float,而python默认情况下会跳过它。我的数据框架中的所有其他列都是numpy格式,所以我通过将columnt转换为np.float64来解决这个问题。
1Top15['Citable Documents per Person']=np.float64(Top15['Citable Documents per Person'])
记住这正是你自己计算的列
工作原理如下:
1
2
3
4
5Top15['Citable docs per Capita']=np.float64(Top15['Citable docs per Capita'])
Top15['Energy Supply per Capita']=np.float64(Top15['Energy Supply per Capita'])
Top15['Energy Supply per Capita'].corr(Top15['Citable docs per Capita'])
我的解决方案是将数据转换为数字类型:
1Top15[['Citable docs per Capita','Energy Supply per Capita']].corr()
当你称之为:
1
2data = Top15[['Citable docs per Capita','Energy Supply per Capita']]
correlation = data.corr(method='pearson')
因为dataframe.corr()函数执行逐对关联,所以有两个变量中的四对。所以,基本上,你得到的是对角线值作为自相关(与自身相关,因为你有两个变量,所以有两个值),另外两个值作为一个和另一个的交叉相关,反之亦然。
在两个序列之间执行相关性以获取单个值:
1
2
3
4from scipy.stats.stats import pearsonr
docs_col = Top15['Citable docs per Capita'].values
energy_col = Top15['Energy Supply per Capita'].values
corr , _ = pearsonr(docs_col, energy_col)
或者,如果要从同一个函数(数据帧的corr)获取单个值:
1single_value = correlation[0][1]
希望这有帮助。
如果需要所有列对之间的关联,可以这样做:
1
2
3
4
5
6
7
8
9
10
11
12import pandas as pd
import numpy as np
def get_corrs(df):
col_correlations = df.corr()
col_correlations.loc[:, :] = np.tril(col_correlations, k=-1)
cor_pairs = col_correlations.stack()
return cor_pairs.to_dict()
my_corrs = get_corrs(df)
# and the following line to retrieve the single correlation
print(my_corrs[('Citable docs per Capita','Energy Supply per Capita')])
我通过更改数据类型解决了这个问题。如果你看到"人均能源供应"是一个数字类型,"人均可引用文件"是一个对象类型。我使用astype将列转换为float。我对一些np函数也有同样的问题:count_nonzero和sum工作,而mean和std不工作。