一切皆卷积——包括时序相关任务
- 1.wavenet
- 1.1 wavenet的pytorch实现
- 1.1.1 wavenet类
- 1.1.2 ResidualConv1dGLU
- 1.2 wavenet在纳米孔测序中的应用
- 2.Temporal Convolutional Network(TCN)
- 2.1 TCN模型介绍
- 2.3 TCN代码实现及可视化
- 3.wavenet/TCN的优点
- 参考文献
RNN/LSTM在时序相关任务中可以说是优选模型。
那么CNN是否可以达到甚至超越这些模型在时序类任务中的效果呢?
今天就简单介绍两个模型,它们主要通过模块—dilated causal conv的多层叠加,来增加感受野,达到捕获时序特征的能力。
1.wavenet
wavenet由 deepmind 出品,原论文首先将其应用在了 Text-to-Speech 任务。
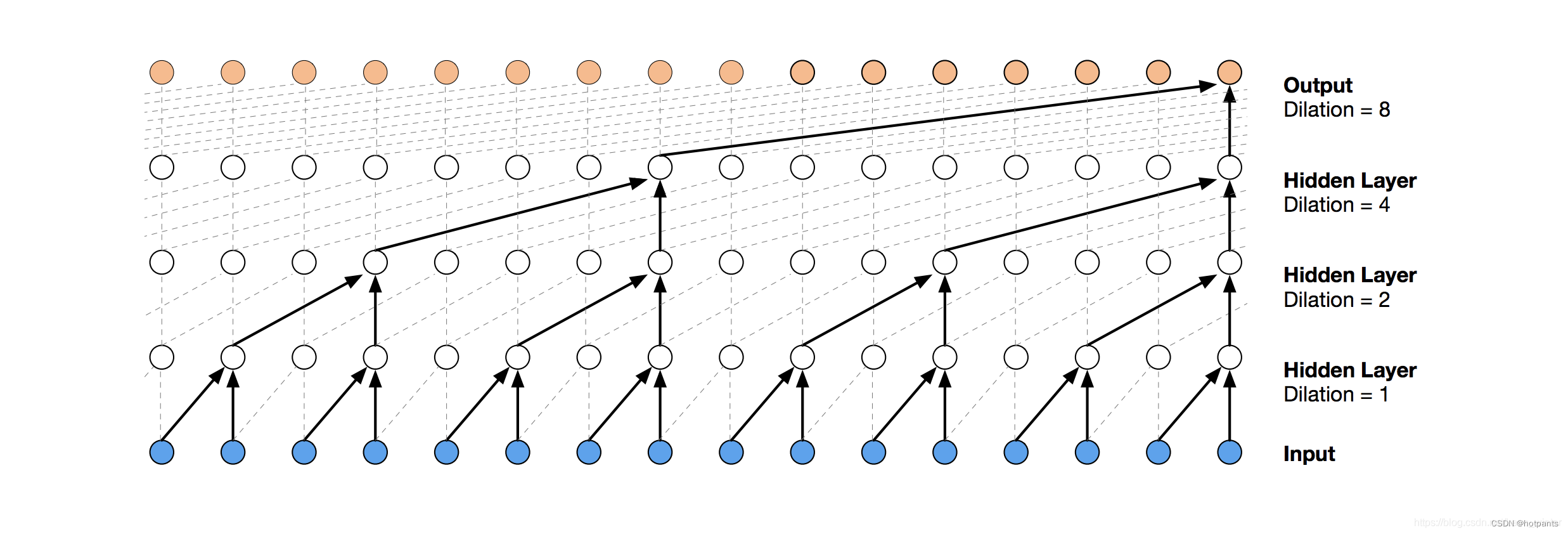
wavenet是一种全卷积的模型,包含了多个多层如下dilated的结构,随着dilated conv深度增加,来指数性地增大感受野,捕获序列之间较长的时间关系。

Deep Voice: Real-time Neural TTS 中有一张图,对wavenet的细节介绍的比较好,如下所示:

1.1 wavenet的pytorch实现
以下代码来自https://github.com/r9y9/wavenet_vocoder
1.1.1 wavenet类
r9y9实现wavenet类支持local 以及global conditioning作为输入。
class WaveNet(nn.Module):def __init__(self, out_channels=256, layers=20, stacks=2,residual_channels=512,gate_channels=512,skip_out_channels=512,kernel_size=3, dropout=1 - 0.95,cin_channels=-1, gin_channels=-1, n_speakers=None,upsample_conditional_features=False,upsample_net="ConvInUpsampleNetwork",upsample_params={"upsample_scales": [4, 4, 4, 4]},scalar_input=False,use_speaker_embedding=False,output_distribution="Logistic",cin_pad=0,):super(WaveNet, self).__init__()self.scalar_input = scalar_inputself.out_channels = out_channelsself.cin_channels = cin_channelsself.output_distribution = output_distributionassert layers % stacks == 0layers_per_stack = layers // stacksif scalar_input:self.first_conv = Conv1d1x1(1, residual_channels)else:self.first_conv = Conv1d1x1(out_channels, residual_channels)self.conv_layers = nn.ModuleList()for layer in range(layers):dilation = 2**(layer % layers_per_stack)conv = ResidualConv1dGLU(residual_channels, gate_channels,kernel_size=kernel_size,skip_out_channels=skip_out_channels,bias=True, # magenda uses bias, but musyoku doesn'tdilation=dilation, dropout=dropout,cin_channels=cin_channels,gin_channels=gin_channels)self.conv_layers.append(conv)self.last_conv_layers = nn.ModuleList([nn.ReLU(inplace=True),Conv1d1x1(skip_out_channels, skip_out_channels),nn.ReLU(inplace=True),Conv1d1x1(skip_out_channels, out_channels),])if gin_channels > 0 and use_speaker_embedding:assert n_speakers is not Noneself.embed_speakers = Embedding(n_speakers, gin_channels, padding_idx=None, std=0.1)else:self.embed_speakers = None# Upsample conv netif upsample_conditional_features:self.upsample_net = getattr(upsample, upsample_net)(**upsample_params)else:self.upsample_net = Noneself.receptive_field = receptive_field_size(layers, stacks, kernel_size)def forward(self, x, c=None, g=None, softmax=False):B, _, T = x.size()if g is not None:if self.embed_speakers is not None:# (B x 1) -> (B x 1 x gin_channels)g = self.embed_speakers(g.view(B, -1))# (B x gin_channels x 1)g = g.transpose(1, 2)assert g.dim() == 3# Expand global conditioning features to all time stepsg_bct = _expand_global_features(B, T, g, bct=True)if c is not None and self.upsample_net is not None:c = self.upsample_net(c)assert c.size(-1) == x.size(-1)# Feed data to networkx = self.first_conv(x)skips = 0for f in self.conv_layers:x, h = f(x, c, g_bct)skips += hskips *= math.sqrt(1.0 / len(self.conv_layers))x = skipsfor f in self.last_conv_layers:x = f(x)x = F.softmax(x, dim=1) if softmax else xreturn xResidualConv1dGLU是wavenet的主要部分,在1.1.2 中具体介绍。
1.1.2 ResidualConv1dGLU
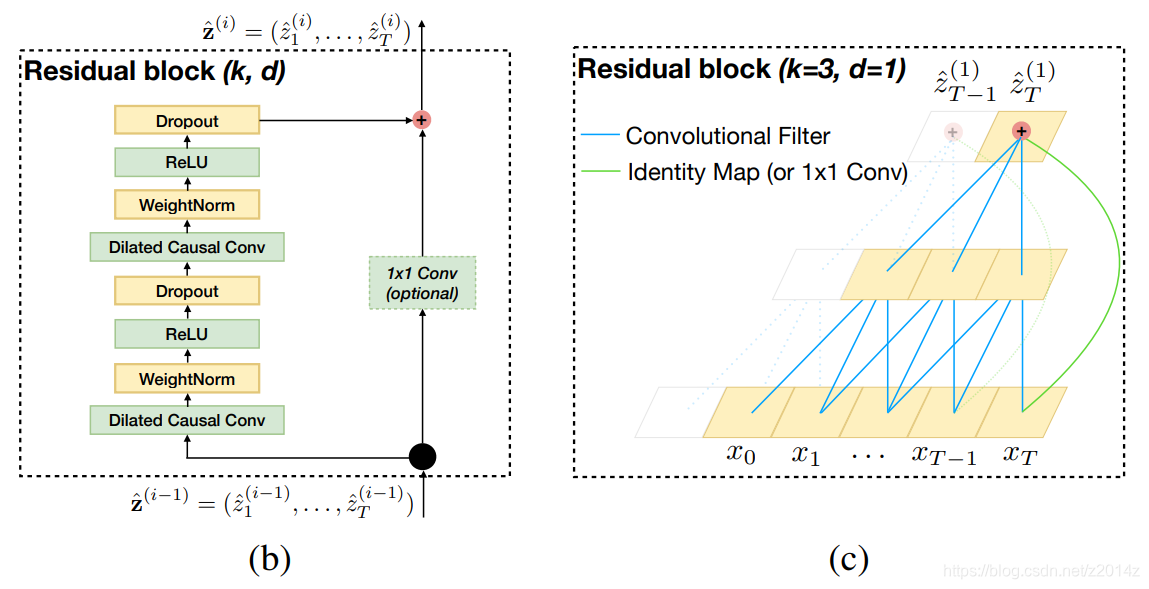
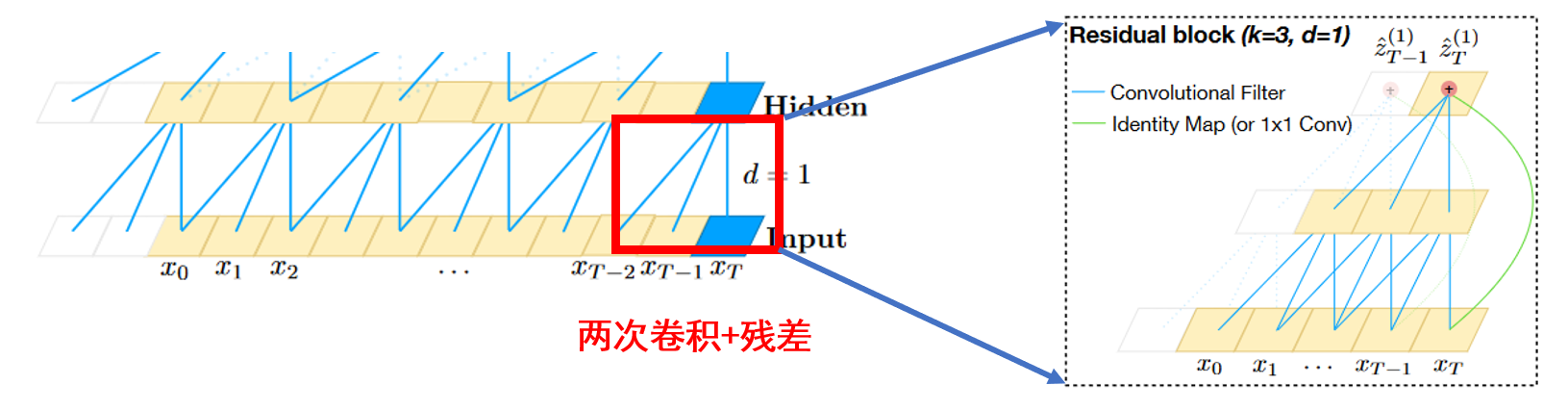
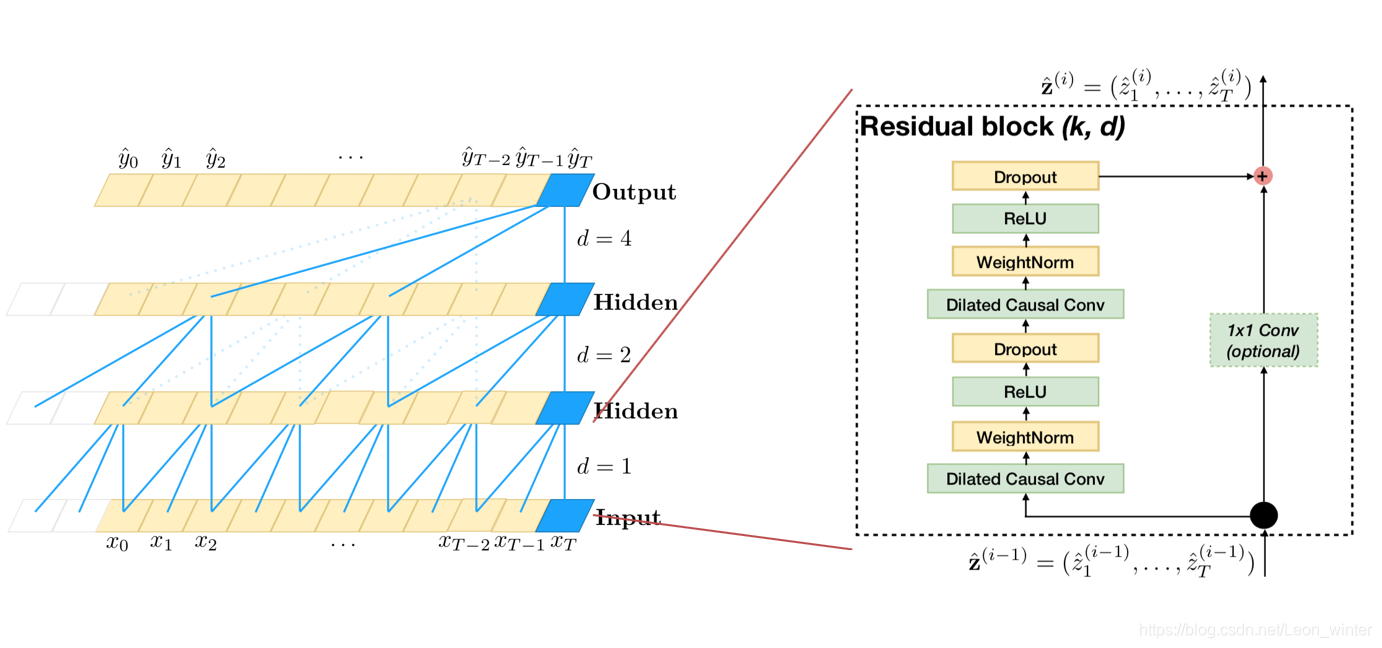
ResidualConv1dGLU即上图虚线框中的部分,它包含了Residual dilated conv1d 以及Gated linear unit(GLU)。
GLU: f ( x ) = ( X ∗ W + b ) ⊗ σ ( X ∗ V + c ) f(x)=(X*W+b)\otimes \sigma(X*V+c) f(x)=(X∗W+b)⊗σ(X∗V+c)
GTU: f ( x ) = tanh ( X ∗ W + b ) ⊗ σ ( X ∗ V + c ) f(x)=\tanh(X*W+b)\otimes \sigma(X*V+c) f(x)=tanh(X∗W+b)⊗σ(X∗V+c)
如果熟悉LSTM的话,LSTM中门控机制中就有多个GTU,可参考Deep Dive into Pytorch RNN/LSTM。
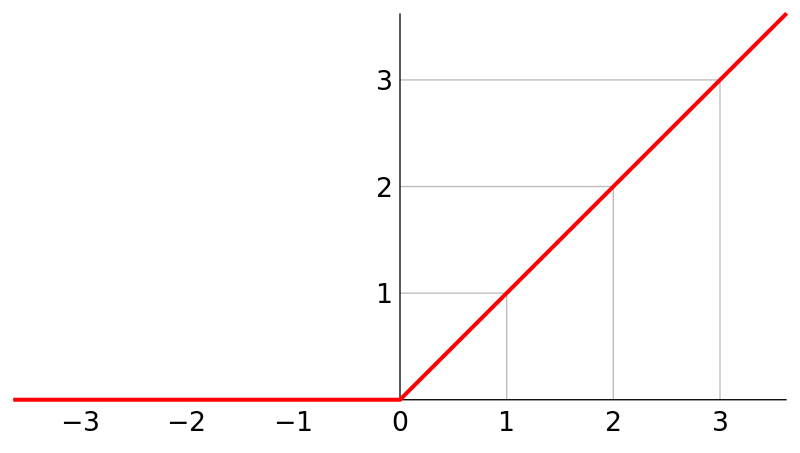
wavenet中用到的应该是GTU。
class ResidualConv1dGLU(nn.Module):def __init__(self, residual_channels, gate_channels, kernel_size,skip_out_channels=None,cin_channels=-1, gin_channels=-1,dropout=1 - 0.95, padding=None, dilation=1, causal=True,bias=True, *args, **kwargs):super(ResidualConv1dGLU, self).__init__()self.dropout = dropoutif skip_out_channels is None:skip_out_channels = residual_channelsif padding is None:# no future time stamps availableif causal:padding = (kernel_size - 1) * dilationelse:padding = (kernel_size - 1) // 2 * dilationself.causal = causalself.conv = Conv1d(residual_channels, gate_channels, kernel_size,padding=padding, dilation=dilation,bias=bias, *args, **kwargs)# local conditioningif cin_channels > 0:self.conv1x1c = Conv1d1x1(cin_channels, gate_channels, bias=False)else:self.conv1x1c = None# global conditioningif gin_channels > 0:self.conv1x1g = Conv1d1x1(gin_channels, gate_channels, bias=False)else:self.conv1x1g = None# conv output is split into two groupsgate_out_channels = gate_channels // 2self.conv1x1_out = Conv1d1x1(gate_out_channels, residual_channels, bias=bias)self.conv1x1_skip = Conv1d1x1(gate_out_channels, skip_out_channels, bias=bias)def forward(self, x, c=None, g=None):return self._forward(x, c, g, False)def _forward(self, x, c, g, is_incremental):residual = xx = F.dropout(x, p=self.dropout, training=self.training)splitdim = 1x = self.conv(x)# remove future time stepsx = x[:, :, :residual.size(-1)] if self.causal else xa, b = x.split(x.size(splitdim) // 2, dim=splitdim)# local conditioningif c is not None:assert self.conv1x1c is not Nonec = self.conv1x1c(c)ca, cb = c.split(c.size(splitdim) // 2, dim=splitdim)a, b = a + ca, b + cb# global conditioningif g is not None:assert self.conv1x1g is not Noneg = self.conv1x1g(g)ga, gb = g.split(g.size(splitdim) // 2, dim=splitdim)a, b = a + ga, b + gbx = torch.tanh(a) * torch.sigmoid(b)# For skip connections = _conv1x1_forward(self.conv1x1_skip, x, is_incremental)# For residual connectionx = _conv1x1_forward(self.conv1x1_out, x, is_incremental)x = (x + residual) * math.sqrt(0.5)return x, s
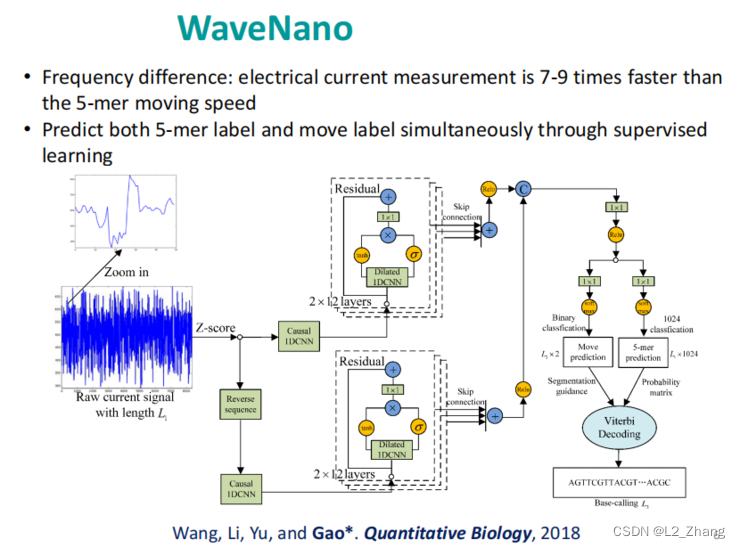
1.2 wavenet在纳米孔测序中的应用
纳米孔测序是一种三代测序技术,它是将生化反应产生的电流信号解码成ATCG序列信息。
Xin Gao教授等提出一种基于双向wavene的wavenano模型,来提高测序性能。
2.Temporal Convolutional Network(TCN)
2.1 TCN模型介绍
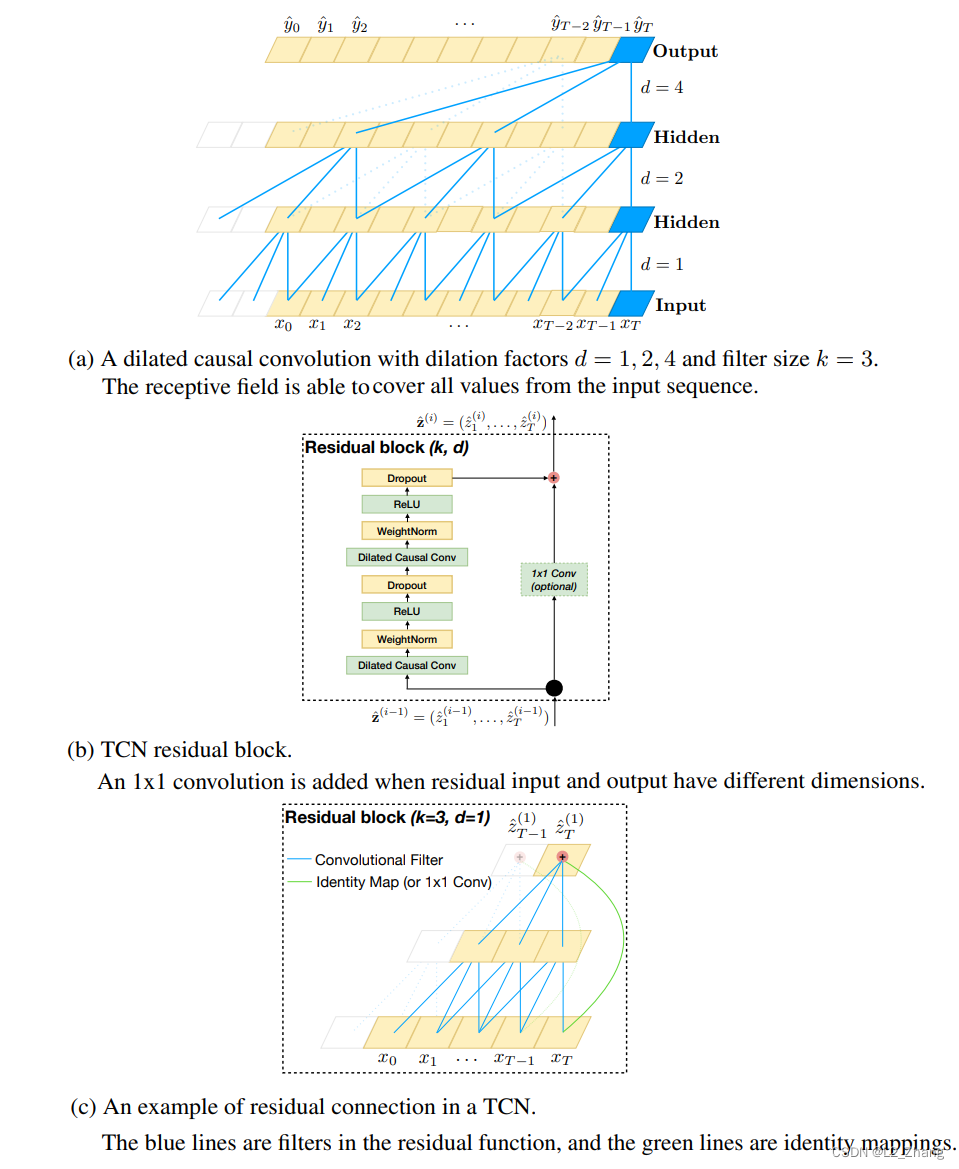
TCN出自论文An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling。其主要结构和wavenet并无二致,即基于dilated conv1D及residual特征。
与wavenet相比,主要不同点在于:
-取消了wavenet中的门控机制(GLU);
-增加了weightnorm及dropout。
2.3 TCN代码实现及可视化
模型实现可参考pytorch TCN。
import torch
from torch import nn
import torch.nn.functional as F
from torch.nn.utils import weight_normclass Chomp1d(nn.Module):def __init__(self, chomp_size):super(Chomp1d, self).__init__()self.chomp_size = chomp_sizedef forward(self, x):return x[:, :, :-self.chomp_size].contiguous()class TemporalBlock(nn.Module):def __init__(self, n_inputs, n_outputs, kernel_size, stride, dilation, padding, dropout=0.2):super(TemporalBlock, self).__init__()self.conv1 = weight_norm(nn.Conv1d(n_inputs, n_outputs, kernel_size,stride=stride, padding=padding, dilation=dilation))self.chomp1 = Chomp1d(padding)self.relu1 = nn.ReLU()self.dropout1 = nn.Dropout(dropout)self.conv2 = weight_norm(nn.Conv1d(n_outputs, n_outputs, kernel_size,stride=stride, padding=padding, dilation=dilation))self.chomp2 = Chomp1d(padding)self.relu2 = nn.ReLU()self.dropout2 = nn.Dropout(dropout)self.net = nn.Sequential(self.conv1, self.chomp1, self.relu1, self.dropout1,self.conv2, self.chomp2, self.relu2, self.dropout2)self.downsample = nn.Conv1d(n_inputs, n_outputs, 1) if n_inputs != n_outputs else Noneself.relu = nn.ReLU()self.init_weights()def init_weights(self):self.conv1.weight.data.normal_(0, 0.01)self.conv2.weight.data.normal_(0, 0.01)if self.downsample is not None:self.downsample.weight.data.normal_(0, 0.01)def forward(self, x):out = self.net(x)res = x if self.downsample is None else self.downsample(x)return self.relu(out + res)class TemporalConvNet(nn.Module):def __init__(self, num_inputs, num_channels, kernel_size=2, dropout=0.2):super(TemporalConvNet, self).__init__()layers = []num_levels = len(num_channels)for i in range(num_levels):dilation_size = 2 ** iin_channels = num_inputs if i == 0 else num_channels[i-1]out_channels = num_channels[i]layers += [TemporalBlock(in_channels, out_channels, kernel_size, stride=1, dilation=dilation_size,padding=(kernel_size-1) * dilation_size, dropout=dropout)]self.network = nn.Sequential(*layers)def forward(self, x):return self.network(x)针对论文中的Sequential MNIST任务,构建由2个TCN block组成的模型,输出为10个类别:
class TCN(nn.Module):def __init__(self, input_size, output_size, num_channels, kernel_size, dropout):super(TCN, self).__init__()self.tcn = TemporalConvNet(input_size, num_channels, kernel_size=kernel_size, dropout=dropout)self.linear = nn.Linear(num_channels[-1], output_size)def forward(self, inputs):"""Inputs have to have dimension (N, C_in, L_in)"""y1 = self.tcn(inputs) # input should have dimension (N, C, L)o = self.linear(y1[:, :, -1])return F.log_softmax(o, dim=1)if __name__ == '__main__':import netronn_classes = 10channel_sizes = [25]*2x = torch.rand(8, 1, 28*28)input_channels = x.shape[1]model = TCN(input_channels, n_classes, channel_sizes,kernel_size=3, dropout=0.05)o = model(x)onnx_path = "D:\\onnx_model_name.onnx"torch.onnx.export(model, x, onnx_path)netron.start(onnx_path)
使用netron进行可视化:

表明看起来和普通的resblock没有差别~
3.wavenet/TCN的优点
如TCN中所述,与RNN架构相比,wavenet/TCN模型在处理时序相关任务时,有如下优势:
-RNN结构的模型,在训练及推断时,t时刻的计算需要t-1时刻的状态,因此无法实现并行;
-wavenet/TCN中通过stacked dilated causal conv来增大感受野,这是RNNs无法实现的;
-RNNs在训练时存在梯度爆炸/消失等情况,导致训练比较困难;而在CNN结构中较少出现;
-RNNs在训练阶段需要存储很多偏导结果,导致较大的内存开销。
参考文献
[1] wavenet
[2] Deep Voice: Real-time Neural TTS
[3] An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling
[4] 初步理解TCN与WaveNet
[5] https://github.com/r9y9/wavenet_vocoder/blob/master/wavenet_vocoder/wavenet.py