写在前面
下面这篇文章首先主要简单介绍了目前较为先进的时间序列预测方法——时间卷积神经网络(TCN)的基本原理,然后基于TCN的开源代码,手把手教你如何通过时间卷积神经网络来进行股价预测,感兴趣的读者也可以基于此模型来用于自己的数据集的训练和预测。
1
TCN的基本原理与结构
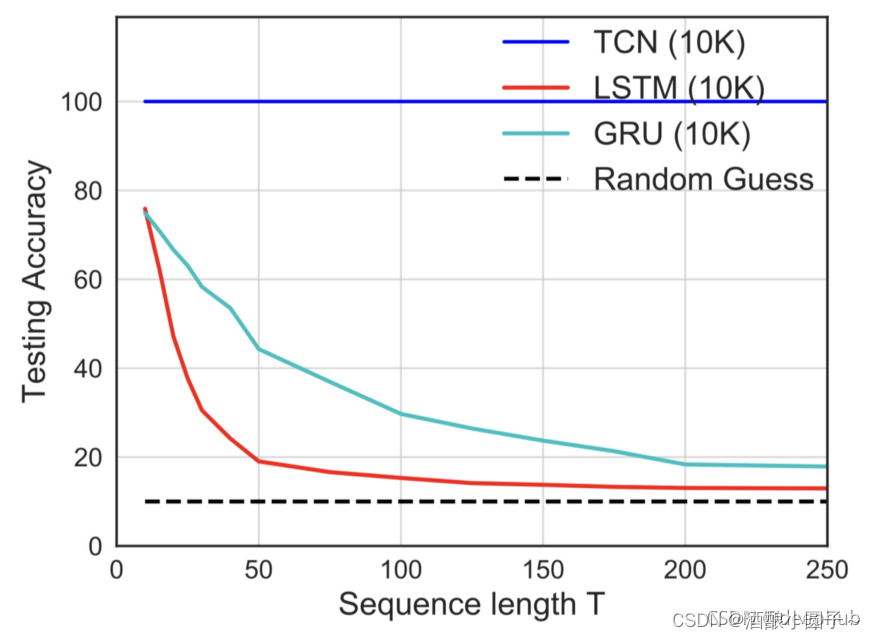
TCN全称Temporal Convolutional Network,时序卷积网络,是在2018年提出的一个模型,可以用于时序数据处理。卷积网络已被证明在提取结构化数据中的高级特征方面具有不错的效果。而时间卷积网络则是一种利用因果卷积和空洞卷积的神经网络模型,它可以适应时序数据的时序性并可以提供视野域用于时序建模。
1、因果卷积
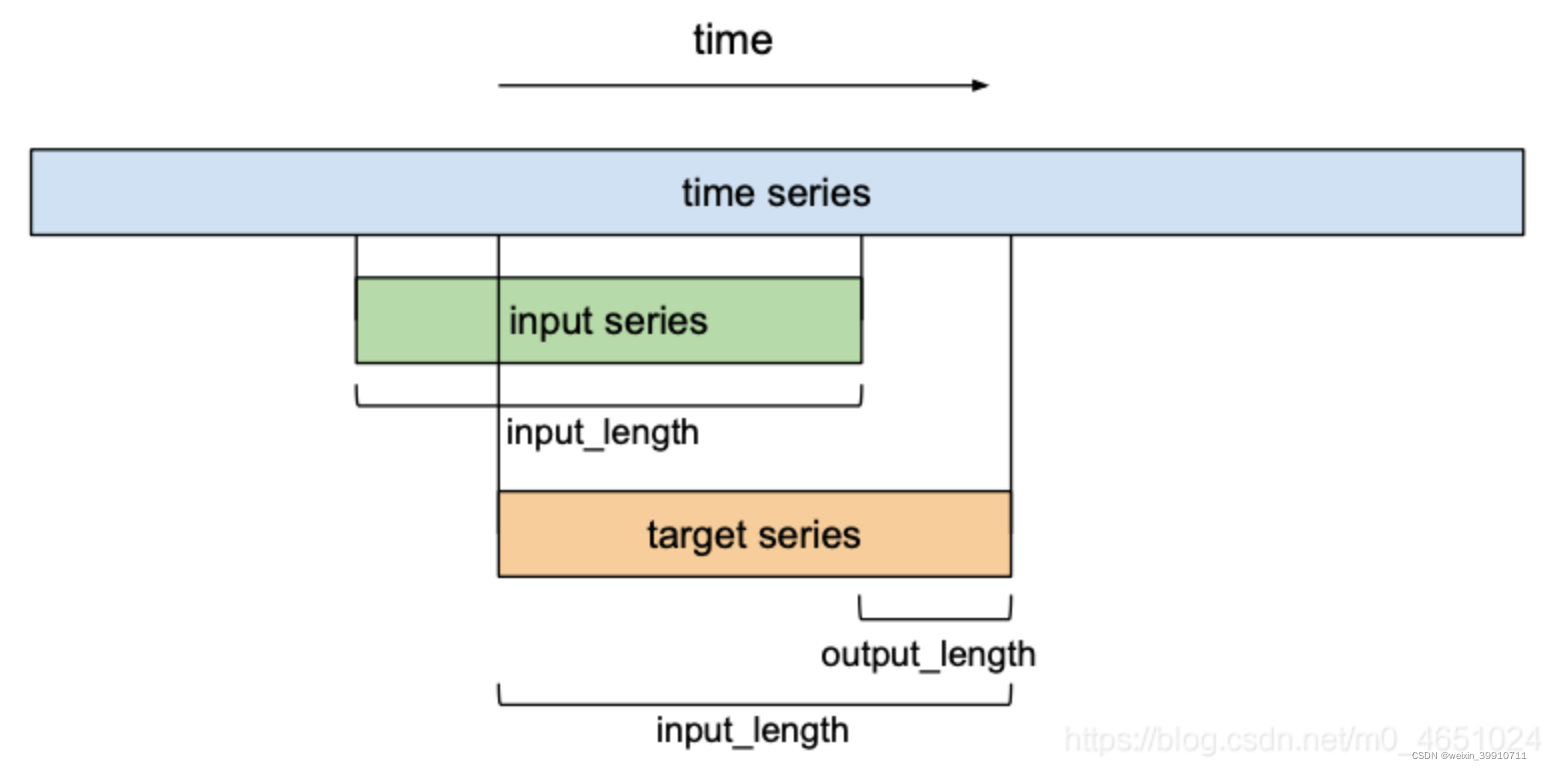
训练时间卷积网络预测输入时间序列的下 个值时,假设输入序列为 ,希望预测一些相应的输出 ,它的值等于输入值向前移动 个单位。在进行预测的时候主要的限制是,当预测某个时间步长t的输出 时,它只能使用前面观察到的输入 。
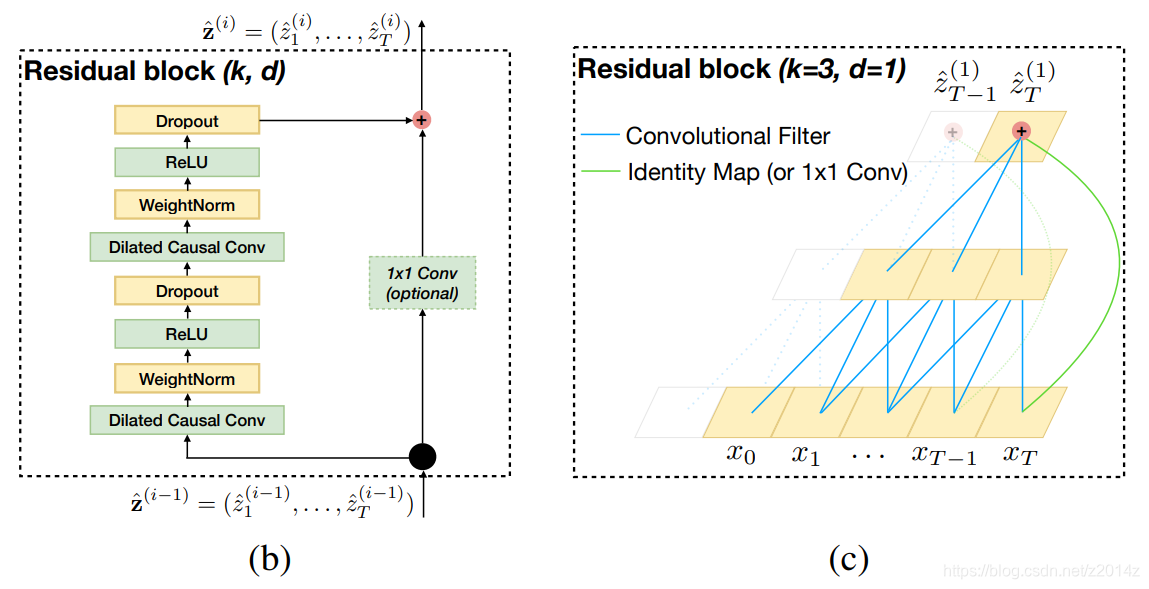
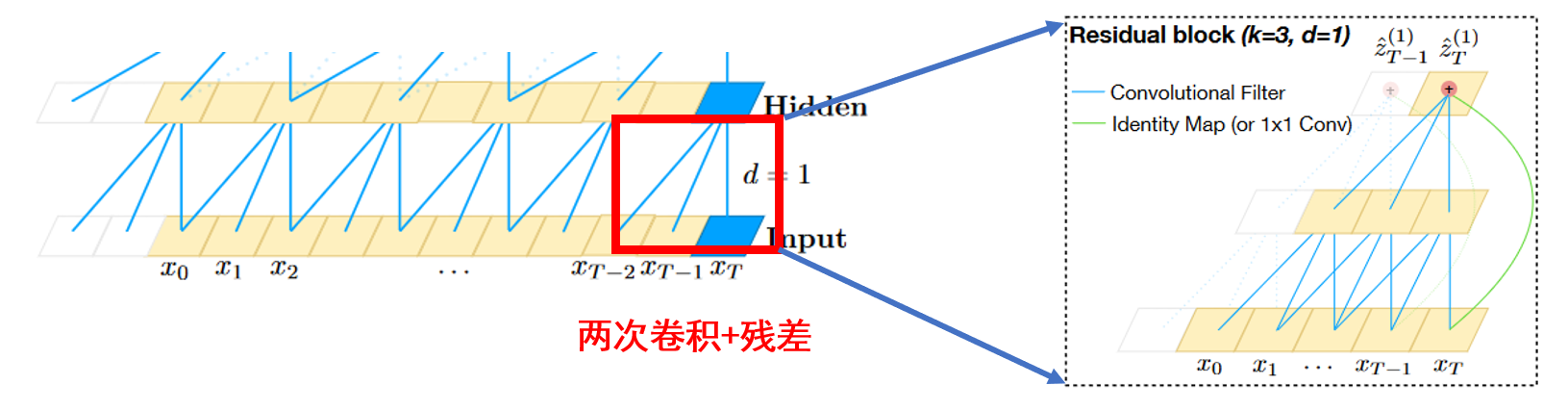
因此,TCN有两个主要约束:网络的输出应该与其输入具有相同的长度,并且网络只能使用过去时间步长的信息。为了满足这些时间性原则,TCN中使用了一个1维全卷积网络结构,即它的所有卷积层具有相同的长度,并带有零填充,以确保更高的层与之前的层相同的长度。此外,TCN使用因果卷积,即每一层的时间步长t的输出只计算不晚于前一层时间步长t的区域,如下图所示。对于一维数据,通过将常规卷积的输出移动几个时间步长,可以很容易地实现因果卷积。
2、空洞卷积
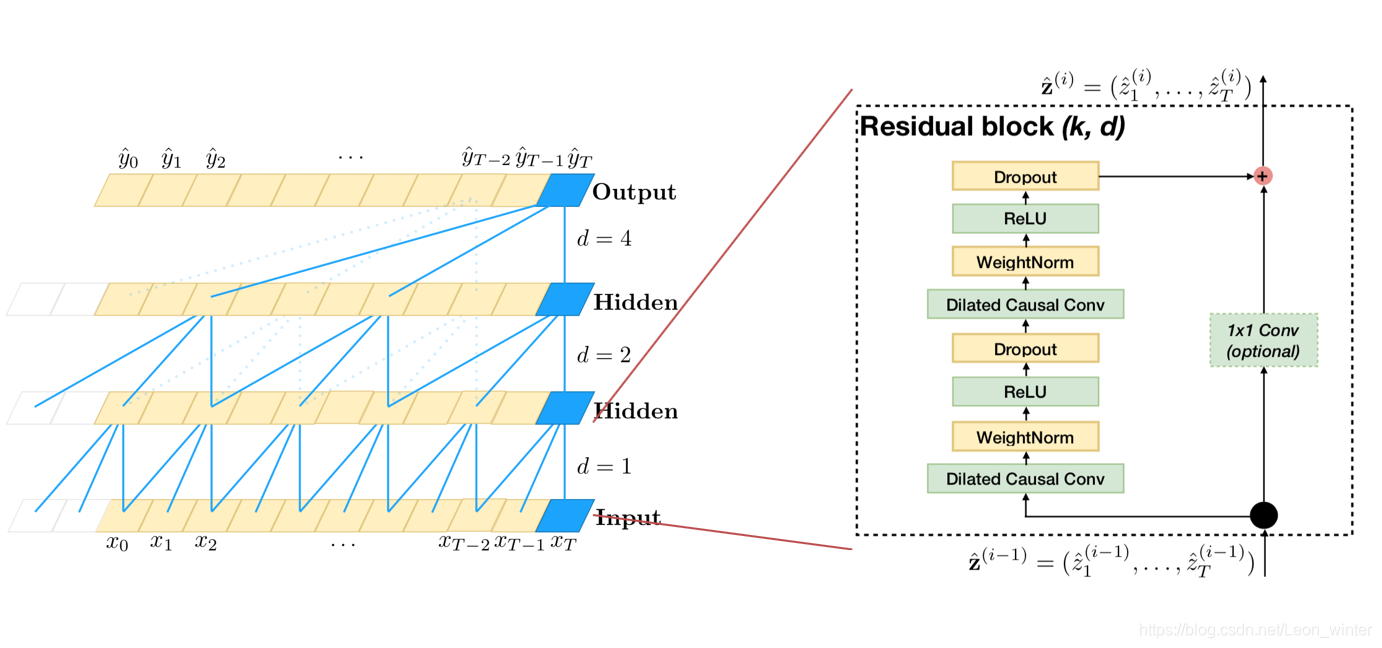
一般来说,在处理时间序列时,人们期望网络能够记住长期信息。然而,在我们前面展示的因果卷积中,除非叠加很多层,否则接收域的大小是有限的。因此,为了克服这些问题,这里使用了空洞卷积来实现有限层网络具有指数级别大小的接收域。空洞卷积是一种卷积,通过跳过给定步骤的大小,然后在一个比它的大小更大的区域上应用滤波器。这类似于池化或跨步卷积,因为它增强了接收区域的大小,但它使输出大小等于输入。当使用空洞卷积时,通常会随着网络的深度指数增加空洞夸张因子d。这保证了历史记录中每个输入的接收域,并通过使用深度网络获得一个非常大的接收域作为有效的历史记录。下图是一个因果空洞卷积的图示。
3、残差连接
由于TCN的接收域大小取决于网络深度n、滤波器大小k和空洞扩张因子d,因此使TCN变深变大是获得足够大的接收域的关键。从经验上看,使网络变深变窄,即叠加大量的层,选择较细尺度的过滤器尺寸,是一种有效的架构。残差连接已被证明是非常有效的训练深度网络。在残差网络中,整个网络采用跳跃连接,以加快训练过程,避免深度模型的梯度消失问题。
2
基于TCN进行股价预测
下面将介绍一个基于TCN进行股价预测的基本例子。用到的TCN模型的原理来自论文:An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling,TCN模型的代码来自github的开源代码:https://github.com/philipperemy/keras-tcn。
本地环境:
Python 3.7
IDE:Pycharm
库版本:
pandas 1.0.3
numpy 1.18.1
matplotlib 3.2.1
tensorflow 2.3.1
sklean 0.22.2
1、数据预处理以及数据集的划分
为了便于演示,数据用到了上证指数从2005到2018年的日线数据,感兴趣的读者也可以将其更换为自己本地的数据。首先,需要导入需要的相关模块,其中tcn模块来自上面的github链接中代码的tcn模块:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
from tcn.tcn import TCN
from tensorflow import keras
接下来需要定义几个全局变量:
window_size = 10 # 窗口大小
batch_size = 32 # 训练批次大小
epochs = 200 # 训练epoch
filter_nums = 10 # filter数量
kernel_size = 4 # kernel大小
然后,我们通过定义一个函数来读取数据并划分训练集和测试集,其中首先需要读取数据并对数据进行归一化处理,以便于模型的训练,这里以上证指数的开盘价为例。然后,通过滑动窗口的形式对数据进行划分,最后,划分后的数据前2000条作为训练集,后1000条数据作为测试集。具体代码如下所示:
def get_dataset():df = pd.read_csv('./000001_Daily_2006_2018.csv')scaler = MinMaxScaler()open_arr = scaler.fit_transform(df['Open'].values.reshape(-1, 1)).reshape(-1)X = np.zeros(shape=(len(open_arr) - window_size, window_size))label = np.zeros(shape=(len(open_arr) - window_size))for i in range(len(open_arr) - window_size):X[i, :] = open_arr[i:i+window_size]label[i] = open_arr[i+window_size]train_X = X[:2000, :]train_label = label[:2000]test_X = X[2000:3000, :]test_label = label[2000:3000]return train_X, train_label, test_X, test_label, scaler
2、模型的构建
模型的构建用到了keras,其中模型的输入层需要按照TCN层的指定形式,window_size表示窗口的大小,即输入数据的长度,1表示每个时间点的维度。之后的TCN层中,每个参数的含义如下所示:
-
nb_filters: 整数。在卷积层中使用的filter的数量。将类似于LSTM层中的units。
-
kernel_size: 整数。在每个卷积层中使用的kernel的大小。
-
dilation: 列表。表示每层中使用的空洞因子的大小的列表。例如:[1, 2, 4, 8, 16, 32, 64]。
-
nb_stacks: 整数。要使用残差块的堆栈数量。
-
padding: 字符串。在卷积中使用的填充。在因果网络中使用“causal”,而在非因果网络中使用“same”。
-
use_skip_connections: 布尔。如果我们想要添加从输入到每个残差块的skip connection。
-
return_sequences: 布尔。是返回输出序列中的最后一个输出,还是返回完整序列。
-
dropout_rate: 浮动在0和1之间。要dropout的比重。
-
activation: 使用的激活函数。
-
kernel_initializer: kernel权值矩阵(Conv1D)的初始化器。
-
use_batch_norm: 是否在使用批处理规范化。
-
kwargs: 用于配置父类层的任何其他参数。
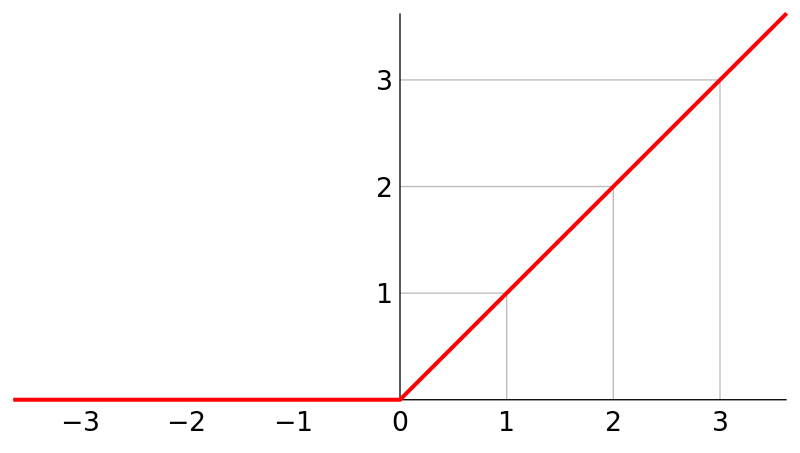
在完成了TCN层的设置之后,后面接一层一个输出的全连接层进行输出最后的预测结果,其中用到的激活函数是relu。最后对模型进行编译以及训练,训练的loss是mae,优化器是adam。
def build_model():train_X, train_label, test_X, test_label, scaler = get_dataset()model = keras.models.Sequential([keras.layers.Input(shape=(window_size, 1)),TCN(nb_filters=filter_nums, kernel_size=kernel_size, dilations=[1, 2, 4, 8]), keras.layers.Dense(units=1, activation='relu')])model.summary()model.compile(optimizer='adam', loss='mae', metrics=['mae'])model.fit(train_X, train_label, validation_split=0.2, epochs=epochs)
最后对模型进行评估,对预测结果进行反归一化并进行可视化:
model.evaluate(test_X, test_label)prediction = model.predict(test_X)scaled_prediction = scaler.inverse_transform(prediction.reshape(-1, 1)).reshape(-1)scaled_test_label = scaler.inverse_transform(test_label.reshape(-1, 1)).reshape(-1)print('RMSE ', RMSE(scaled_prediction, scaled_test_label))plot(scaled_prediction, scaled_test_label)
模型的结构以及训练过程如下所示:
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
tcn (TCN) (None, 10) 2940
_________________________________________________________________
dense (Dense) (None, 1) 11
=================================================================
Total params: 2,951
Trainable params: 2,951
Non-trainable params: 0
_________________________________________________________________
Epoch 1/200
50/50 [==============================] - 1s 14ms/step - loss: 0.0739 - mae: 0.0739 - val_loss: 0.0131 - val_mae: 0.0131
Epoch 2/200
50/50 [==============================] - 0s 5ms/step - loss: 0.0141 - mae: 0.0141 - val_loss: 0.0063 - val_mae: 0.0063
Epoch 3/200
50/50 [==============================] - 0s 7ms/step - loss: 0.0130 - mae: 0.0130 - val_loss: 0.0048 - val_mae: 0.0048
Epoch 4/200
50/50 [==============================] - 0s 6ms/step - loss: 0.0115 - mae: 0.0115 - val_loss: 0.0081 - val_mae: 0.0081
Epoch 5/200
50/50 [==============================] - 0s 6ms/step - loss: 0.0130 - mae: 0.0130 - val_loss: 0.0052 - val_mae: 0.0052
Epoch 6/200
50/50 [==============================] - 0s 6ms/step - loss: 0.0122 - mae: 0.0122 - val_loss: 0.0046 - val_mae: 0.0046
Epoch 7/200
50/50 [==============================] - 0s 6ms/step - loss: 0.0109 - mae: 0.0109 - val_loss: 0.0058 - val_mae: 0.0058
Epoch 8/200
50/50 [==============================] - 0s 6ms/step - loss: 0.0116 - mae: 0.0116 - val_loss: 0.0063 - val_mae: 0.0063
Epoch 9/200
50/50 [==============================] - 0s 6ms/step - loss: 0.0111 - mae: 0.0111 - val_loss: 0.0062 - val_mae: 0.0062
Epoch 10/200
50/50 [==============================] - 0s 5ms/step - loss: 0.0112 - mae: 0.0112 - val_loss: 0.0056 - val_mae: 0.0056
模型训练完之后,打印的RMSE如下所示:
RMSE 35.78251267773438
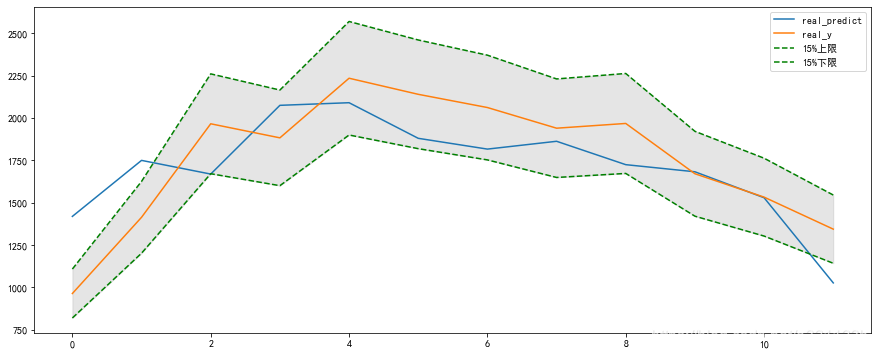
预测的效果如下图所示,可以看到模型的拟合效果还可以,基本拟合出了价格的基本走势。
完整代码如下所示:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
from tcn.tcn import TCN
from tensorflow import keraswindow_size = 10 # 窗口大小
batch_size = 32 # 训练批次大小
epochs = 200 # 训练epoch
filter_nums = 10 # filter数量
kernel_size = 4 # kernel大小def get_dataset():df = pd.read_csv('./000001_Daily_2006_2018.csv')scaler = MinMaxScaler()open_arr = scaler.fit_transform(df['Open'].values.reshape(-1, 1)).reshape(-1)X = np.zeros(shape=(len(open_arr) - window_size, window_size))label = np.zeros(shape=(len(open_arr) - window_size))for i in range(len(open_arr) - window_size):X[i, :] = open_arr[i:i+window_size]label[i] = open_arr[i+window_size]train_X = X[:2000, :]train_label = label[:2000]test_X = X[2000:3000, :]test_label = label[2000:3000]return train_X, train_label, test_X, test_label, scalerdef RMSE(pred, true):return np.sqrt(np.mean(np.square(pred - true)))def plot(pred, true):fig = plt.figure()ax = fig.add_subplot(111)ax.plot(range(len(pred)), pred)ax.plot(range(len(true)), true)plt.show()def build_model():train_X, train_label, test_X, test_label, scaler = get_dataset()model = keras.models.Sequential([keras.layers.Input(shape=(window_size, 1)),TCN(nb_filters=filter_nums, # 滤波器的个数,类比于unitskernel_size=kernel_size, # 卷积核的大小dilations=[1, 2, 4, 8]), # 空洞因子keras.layers.Dense(units=1, activation='relu')])model.summary()model.compile(optimizer='adam', loss='mae', metrics=['mae'])model.fit(train_X, train_label, validation_split=0.2, epochs=epochs)model.evaluate(test_X, test_label)prediction = model.predict(test_X)scaled_prediction = scaler.inverse_transform(prediction.reshape(-1, 1)).reshape(-1)scaled_test_label = scaler.inverse_transform(test_label.reshape(-1, 1)).reshape(-1)print('RMSE ', RMSE(scaled_prediction, scaled_test_label))plot(scaled_prediction, scaled_test_label)if __name__ == '__main__':build_model()4
总结
在这篇文章中,我们首先简单介绍了时间卷积网络的一些基本内容,然后基于开源的时间卷积网络的代码,实现了一个简单的例子,将其应用于上证指数价格的预测当中。从结果中可以看出,时间卷积网络具有很强的数据拟合能力和时序建模能力。当在将其应用于股价预测当中时,仍不可避免地面临过拟合、模式迁移以及市场噪声的影响。即便如此,在RNN、LSTM占据时序处理领域的情况下,TCN作为一种新颖的技术仍具有很强的研究意义与价值。
了解更多人工智能与
量化金融知识
<-请扫码关注
让我知道你在看