bp神经网络对输入数据和输出数据有什么要求
p神经网络的输入数据越多越好,输出数据需要反映网络的联想记忆和预测能力。BP网络能学习和存贮大量的输入-输出模式映射关系,而无需事前揭示描述这种映射关系的数学方程。
它的学习规则是使用最速下降法,通过反向传播来不断调整网络的权值和阈值,使网络的误差平方和最小。
BP神经网络模型拓扑结构包括输入层(input)、隐层(hide layer)和输出层(output layer)。
BP网络具有高度非线性和较强的泛化能力,但也存在收敛速度慢、迭代步数多、易于陷入局部极小和全局搜索能力差等缺点。
扩展资料:BP算法主要思想是:输入学习样本,使用反向传播算法对网络的权值和偏差进行反复的调整训练,使输出的向量与期望向量尽可能地接近,当网络输出层的误差平方和小于指定的误差时训练完成,保存网络的权值和偏差。
1、初始化,随机给定各连接权及阀值。
2、由给定的输入输出模式对计算隐层、输出层各单元输出3、计算新的连接权及阀值,计算公式如下:4、选取下一个输入模式对返回第2步反复训练直到网络设输出误差达到要求结束训练。
参考资料来源:百度百科-BP神经网络。
谷歌人工智能写作项目:神经网络伪原创

BP神经网络的训练集需要大样本吗?一般样本个数为多少?
BP神经网络的训练集需要大样本吗?一般样本个数为多少?
BP神经网络样本数有什么影响学习神经网络这段时间,有一个疑问,BP神经网络中训练的次数指的网络的迭代次数,如果有a个样本,每个样本训练次数n,则网络一共迭代an次,在n>>a 情况下 , 网络在不停的调整权值,减小误差,跟样本数似乎关系不大文案狗。
而且,a大了的话训练时间必然会变长。换一种说法,将你的数据集看成一个固定值, 那么样本集与测试集 也可以按照某种规格确定下来如7:3 所以如何看待 样本集的多少与训练结果呢?
或者说怎么使你的网络更加稳定,更加符合你的所需 。
我尝试从之前的一个例子中看下区别如何用70行Java代码实现深度神经网络算法作者其实是实现了一个BP神经网络 ,不多说,看最后的例子一个运用神经网络的例子最后我们找个简单例子来看看神经网络神奇的效果。
为了方便观察数据分布,我们选用一个二维坐标的数据,下面共有4个数据,方块代表数据的类型为1,三角代表数据的类型为0,可以看到属于方块类型的数据有(1,2)和(2,1),属于三角类型的数据有(1,1),(2,2),现在问题是需要在平面上将4个数据分成1和0两类,并以此来预测新的数据的类型。
图片描述我们可以运用逻辑回归算法来解决上面的分类问题,但是逻辑回归得到一个线性的直线做为分界线,可以看到上面的红线无论怎么摆放,总是有一个样本被错误地划分到不同类型中,所以对于上面的数据,仅仅一条直线不能很正确地划分他们的分类,如果我们运用神经网络算法,可以得到下图的分类效果,相当于多条直线求并集来划分空间,这样准确性更高。
图片描述简单粗暴,用作者的代码运行后 训练5000次 。
根据训练结果来预测一条新数据的分类(3,1)预测值 (3,1)的结果跟(1,2)(2,1)属于一类 属于正方形这时如果我们去掉 2个样本,则样本输入变成如下//设置样本数据,对应上面的4个二维坐标数据 double[][] data = new double[][]{{1,2},{2,2}}; //设置目标数据,对应4个坐标数据的分类 double[][] target = new double[][]{{1,0},{0,1}};12341234则(3,1)结果变成了三角形,如果你选前两个点 你会发现直接一条中间线就可以区分 这时候的你的结果跟之前4个点时有区别 so 你得增加样本 直到这些样本按照你所想要的方式分类 ,所以样本的多少 重要性体现在,样本得能反映所有的特征值(也就是输入值) ,样本多少或者特征(本例子指点的位置特征)决定的你的网络的训练结果,!
!!这是 我们反推出来的结果 。这里距离深度学习好像近了一步。另外,这个70行代码的神经网络没有保存你训练的网络 ,所以你每次运行都是重新训练的网络。
其实,在你训练过后 权值已经确定了下来,我们确定网络也就是根据权值,so只要把训练后的权值保存下来,将需要分类的数据按照这种权值带入网络,即可得到输出值,也就是一旦网络确定, 权值也就确定,一个输入对应一个固定的输出,不会再次改变!
个人见解。
最后附上作者的源码,作者的文章见开头链接下面的实现程序可以直接拿去使用,import .Random;public class BpDeep{ public double[][] layer;//神经网络各层节点 public double[][] layerErr;//神经网络各节点误差 public double[][][] layer_weight;//各层节点权重 public double[][][] layer_weight_delta;//各层节点权重动量 public double mobp;//动量系数 public double rate;//学习系数 public BpDeep(int[] layernum, double rate, double mobp){ = mobp; = rate; layer = new double[layernum.length][]; layerErr = new double[layernum.length][]; layer_weight = new double[layernum.length][][]; layer_weight_delta = new double[layernum.length][][]; Random random = new Random(); for(int l=0;l。
在用bp神经网络时,需要输入数据,但有些数据是定性数据,如何将定性数据定量化
你所说的应该是输入数据的预处理 即pre-processing,你使用ST Nueral Networks的话,里面有自动的预处理,你输入定性数据(nominal variable)后,软件可以自动预处理后转化为神经网络可以识别的数值. 或者你自己设置 例1 根据年鉴记载的某些地区经度,纬度与台风类型的关系预测任意经纬度下台风类型(台风A或者台风B),台风类型就属于定性数据在STNN中你可以现将输出变量设置为nominal variable,然后设置输出变量的数目为2,分别是V1和V2,构建网络的时候经纬度对应台风A的,设置输出值为V1,为台风B的设置为V2,预测时,网络可以给出结果V1或者V2,你就知道是哪种台风了. 例2 根据现有的水质标准以及数种污染物的采样值预测该河流的水质级别输出值为水质级别,同样为nominal variable,你可以将输出值作一个标准化处理,设总共有五个水质级别,你可以将输出变量区间化分为0-0.2,0.2-0.4,0.4-0.6,0.6-0.8,0.8-1,设置第一级别水质对应的输出值为0.2 第2级水质对应0.4,等等,第5级水质对应1。
BP神经网络预测,预测结果与样本数据的理解。
输入节点数是3,说明输入向量的行数m=3,你给的样本只有1行,是不是不全?输出节点只有一个,说明每3个输入数据对应一个预测的输出数据。其实样本数量很少,就不需要训练那么多次了,训练了也白训练。
你问“这样的预测结果代表着什么?”,你也没说这些数据在现实中是什么,怎么会知道呢。
bp神经网络预测是不是数据越多,预测能力就越好?
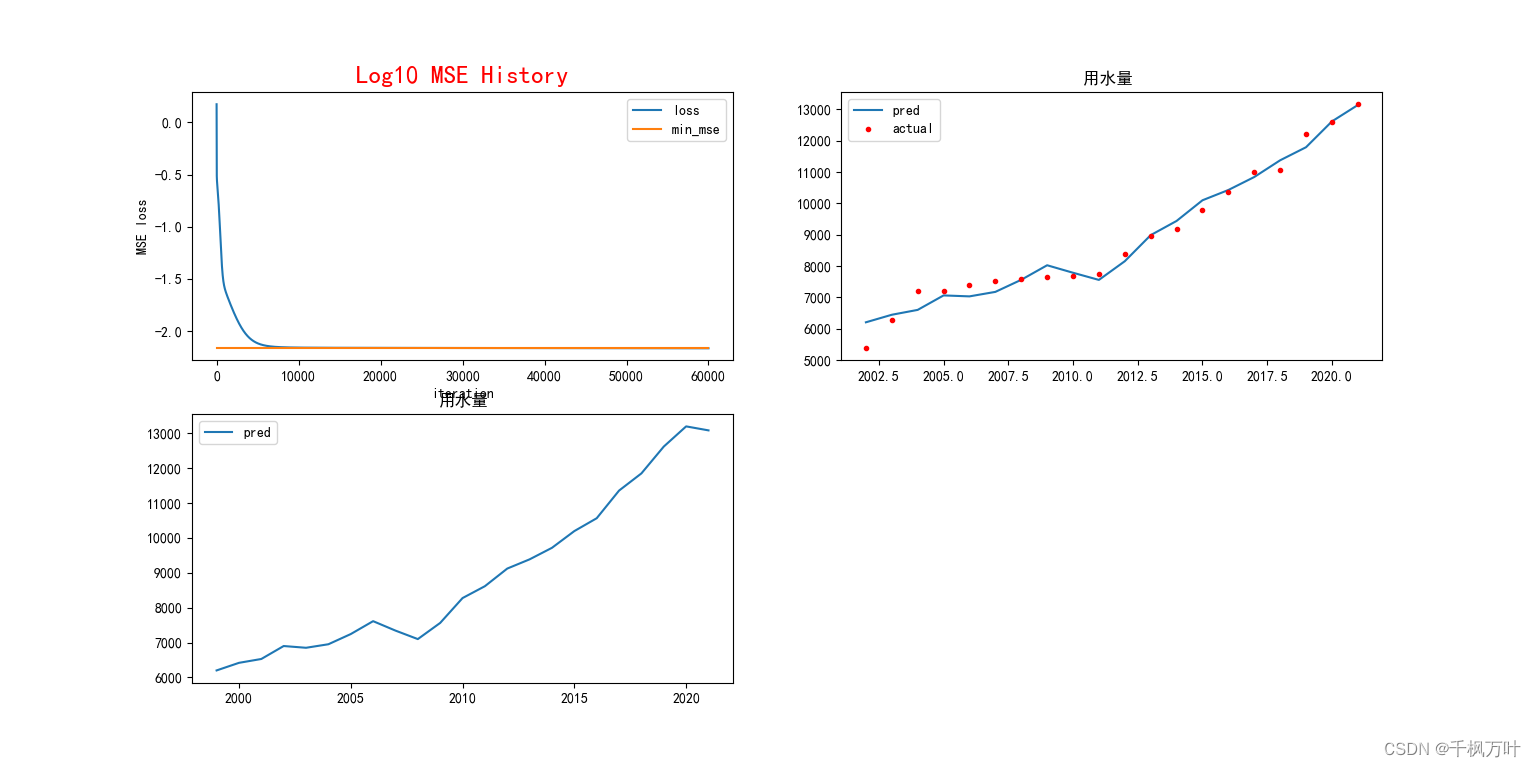
基于时间序列matlab的BP神经网络预测
BP网络训练图: P = [1998 1999 2000 2001 2002 2003 2004 2005 2006 2007 2008 2009];%输入向量 T = [115.4 212.1 259.7 251.8 352 463.4 509 558 614 700 696 712];%期望输出 Z=[2010 2011 2012 2013 2014 2015 2016 2017 2018 2019 2020] %创建两层的BP网络: net = newff([1998 2009],[100 1],{'tansig' 'purelin'}); =50; %每次循环50次 net.trainParam.epochs = 500;%最大循环500次 net = train(net,P,T);%对网络进行反复训练只给出了一部分程序,其余的QQ传给你,留你的QQ。
结果: Y = Columns 1 through 7 115.4067 212.0911 259.7029 251.7979 352.0027 463.4023 508.9910 Columns 8 through 12 558.0155 613.9892 699.9980 696.0063 711.9970 预测值a =Columns 1 through 7 711.9970 711.7126 749.4216 749.2672 746.7096 746.7096 751.0786 Columns 8 through 11 760.2729 757.3316 696.5151 696.5151 分别是2010-2020年的预测数据。