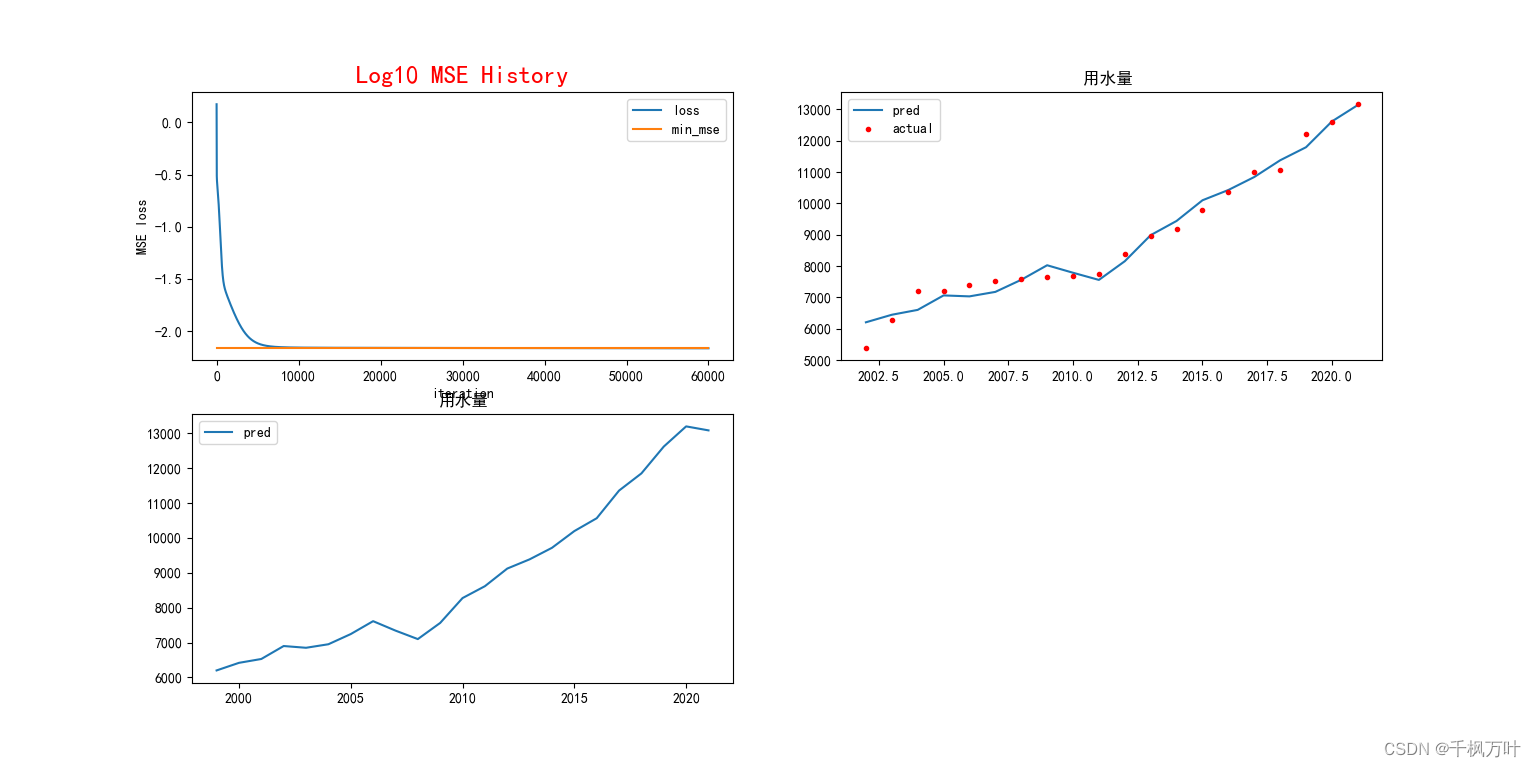
BP神经网络预测,预测结果与样本数据的理解。
输入节点数是3,说明输入向量的行数m=3,你给的样本只有1行,是不是不全?输出节点只有一个,说明每3个输入数据对应一个预测的输出数据。其实样本数量很少,就不需要训练那么多次了,训练了也白训练。
你问“这样的预测结果代表着什么?”,你也没说这些数据在现实中是什么,怎么会知道呢。
谷歌人工智能写作项目:神经网络伪原创

Matlab中BP神经网络训练结果求指导,萌新求各位大神给分析一下,感激不尽。
好文案。
P=[1;2;3;4;5];%月P=[P/50];T=[2;3;4;5;6];%月训练样本T=[T/50];threshold=[01;01;01;01;01;01;01];net=newff(threshold,[15,7],{'tansig','logsig'},'trainlm');net.trainParam.epochs=2000;=0.001;=0.1;net=train(net,P,T);P_test=[6月]';%6月数据预测7月P_test=[P_test/50];y=sim(net,P_test)y=[y*50]。
BP神经网络与 Modflow的预测结果对比
根据训练好的BP神经网络模型,对区内6个点2005~2015年的年沉降量进行预测(图8.36)。从图8.36中可以看出,随着开采量的减小,水位的上升,各点的年沉降量逐渐减小,变化趋势也基本一致。
预测到2015年,各点的年沉降量比2004年减小了21.8~56.8mm;年沉降量最大的点是位于芦台镇附近的CJ6,沉降量为21.6mm;年沉降量最小的点是位于研究区西侧的CJ2,沉降量只有6.6mm。
图8.36各监测点年沉降量预测图以2004年各个监测点的实测累积沉降量为起点,将神经网络预测的年沉降量进行累加,从而与Modflow数值模型的预测结果相对比(图8.37)。
从图8.37中可以看出这两种方法在各监测点处的预测结果基本一致。在局部点处(CJ2)相差较大,这主要是由于该点临近区域交界处,地面沉降过程受到邻区地下水开采的影响,使得BP网络模型的预测效果出现偏差。
BP网络与Modflow数值模型预测结果的相对误差见表8.18。从表8.18中可以看出,各点的年均相对误差在0.75%~6.86%之间,平均为2.9%。
说明本次建立的BP神经网络模型基本可以达到Modflow数值模型的预测效果。表8.18BP网络预测相对误差表续表图8.37各监测点累积沉降量预测对比图。
BP神经网络做数据预测,预测出来结果感觉不对,求大神指导
在看了案例二中的BP神经网络训练及预测代码后,我开始不明白BP神经网络究竟能做什么了。。。 程序最后得到
网络的训练过程与使用过程了两码事。
比如BP应用在分类,网络的训练是指的给你一些样本,同时告诉你这些样本属于哪一类,然后代入网络训练,使得这个网络具备一定的分类能力,训练完成以后再拿一个未知类别的数据通过网络进行分类。
这里的训练过程就是先伪随机生成权值,然后把样本输入进去算出每一层的输出,并最终算出来预测输出(输出层的输出),这是正向学习过程;最后通过某种训练算法(最基本的是感知器算法)使得代价(预测输出与实际输出的某范数)函数关于权重最小,这个就是反向传播过程。
您所说的那种不需要预先知道样本类别的网络属于无监督类型的网络,比如自组织竞争神经网络。
BP神经网络预测,不会看结果,请大神帮忙,谢谢
隐藏层神经元个数,你慢慢调试到最佳就好,虽然有经验公式也不一定有用。你输入输出有12年的数据,但是你把这12年数据,其中多少年的数据拿来做网络训练用,多少年的拿来测试用呢?
你没说明啊你应该是拿3年数据进行网络训练,9年拿来测试网络了,所以有九年的结果。建议你最好前九年数据拿来训练网络,最后三年用来测试网络,输出结果。望采纳,有问题继续讨论。
为什么我的BP神经网络的预测输出结果几乎是一样的呢
bp神经网络是有一定缺陷的,比如容易陷入局部极小值,还有训练的结果依赖初始随机权值,这就好比你下一个山坡,如果最开始的方向走错了,那么你可能永远也到不了正确的山脚。
可以说bp神经网络很难得到正确答案,也没有唯一解,有些时候只能是更多次地尝试、修改参数,这个更多依赖自己的经验,通俗点说就是“你觉得行了,那就是行了”,而不像1+1=2那样确切。
如果有耐心,确定方法没问题,那么接下来需要做的就是不停地尝试、训练,得到你想要的结果。另外,我不知道你预测的是什么,是时间序列么?比如证券?
这种预测,比较重要的就是输入参数是否合适,这个直接决定了结果精度。
我用bp神经网络做预测,可是每次预测出来的结果都不一样,且差的比较多,要怎么办?