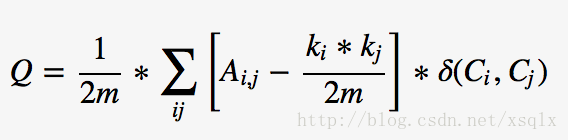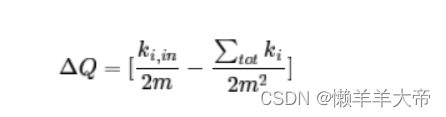文章目录
- 例子一:创建一个属性图(无权)
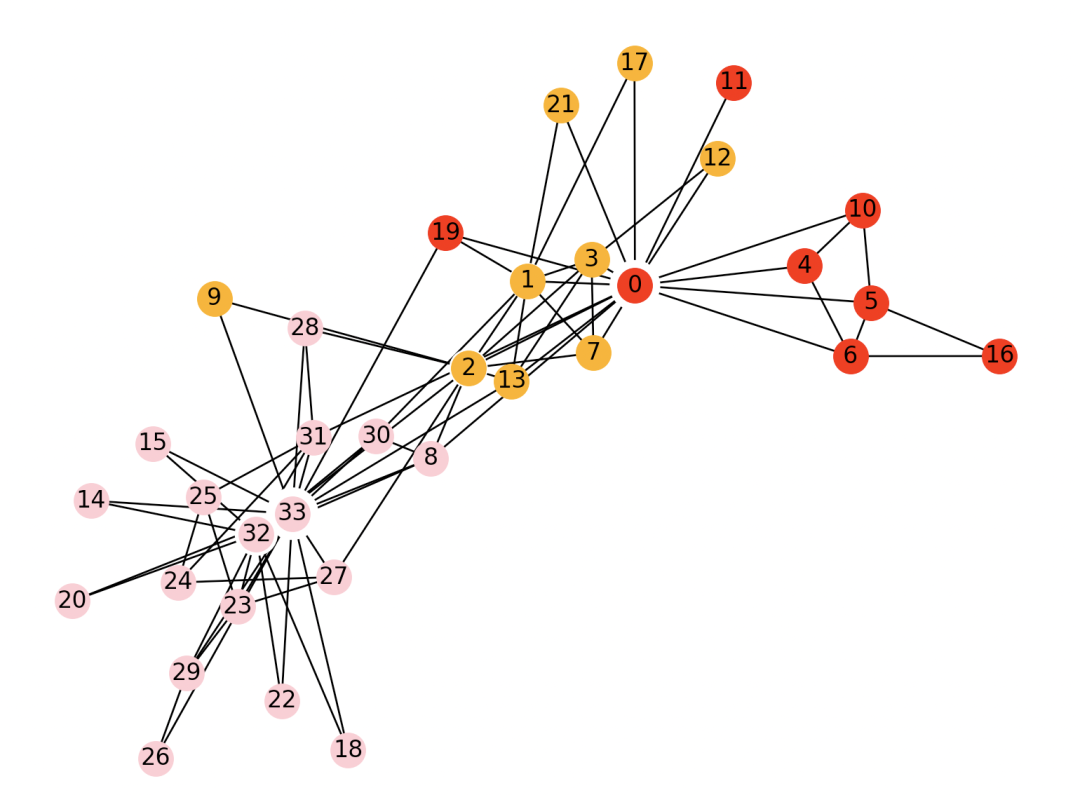
- 一、属性图如下
- 二、实现算法
- 1.stream模式执行Louvain算法(匿名图)
- 2.结果如下
- 总结一:
- 例子二:创建一个属性图(有权)
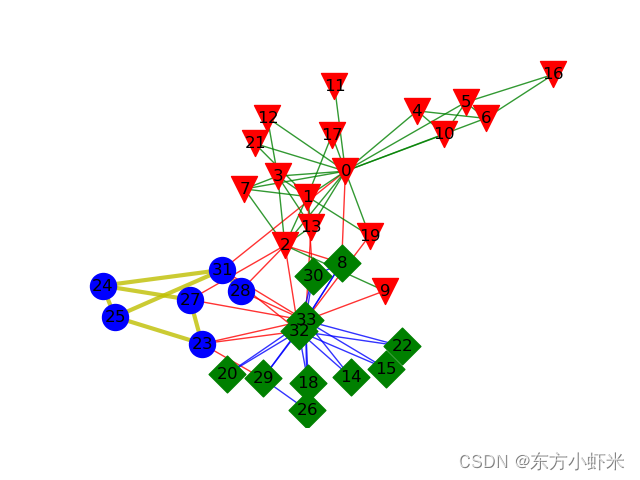
- 一、属性图如下
- 二、算法实现
- 1.stream模式执行Louvain算法(命名图)
- 2.结果如下
- 3.带权值计算
- 4.结果如下
- 5.含原始社区属性计算
- 6.结果如下
- 总结二:
例子一:创建一个属性图(无权)
这次用的方法是本地load导入的,两个代码块分别导入节点、节点间关系。
load csv with headers from "file:///sw-nodes.csv" as rowmerge (place:Place{id:row.id})
load csv with headers from "file:///sw-relationships.csv" as rowmatch (origin:Place{id:row.src})match (destination:Place{id:row.dst})merge (origin) - [r:DEPENDS_ON]->(destination)
一、属性图如下

二、实现算法
1.stream模式执行Louvain算法(匿名图)
CALL gds.louvain.stream({nodeProjection: 'Place',relationshipProjection: {TYPE: {type: 'DEPENDS_ON',orientation: 'undirected',aggregation: 'NONE'}},includeIntermediateCommunities:True
}) YIELD nodeId, communityId
RETURN gds.util.asNode(nodeId).id AS name, communityId
ORDER BY name ASC
参数<>includeIntermediateCommunities:True,为真的时候,显示划分时出现的中间社团,结果最后一列表示该节点都曾被划分到哪个社团。中间一列表示节点最后所在社团。
2.结果如下


总结一:
如果你熟悉其他算法,会发现这个结果和连通分量算法(Connected components algorithm)结果一样,因为这是属性图中只包含了三个独立的社团,很容易区分开来。而且这个属性图本身是无权的。
例子二:创建一个属性图(有权)
CREATE(nAlice:User {name: 'Alice', seed: 42}),(nBridget:User {name: 'Bridget', seed: 42}),(nCharles:User {name: 'Charles', seed: 42}),(nDoug:User {name: 'Doug'}),(nMark:User {name: 'Mark'}),(nMichael:User {name: 'Michael'}),(nAlice)-[:LINK {weight: 1}]->(nBridget),(nAlice)-[:LINK {weight: 1}]->(nCharles),(nCharles)-[:LINK {weight: 1}]->(nBridget),(nAlice)-[:LINK {weight: 5}]->(nDoug),(nMark)-[:LINK {weight: 1}]->(nDoug),(nMark)-[:LINK {weight: 1}]->(nMichael),(nMichael)-[:LINK {weight: 1}]->(nMark);
一、属性图如下

二、算法实现
1.stream模式执行Louvain算法(命名图)
图命名:myGraph
CALL gds.graph.create('myGraph','User',{LINK: {orientation: 'UNDIRECTED'}},{nodeProperties: 'seed',relationshipProperties: 'weight'}
)
结果如下:

执行算法:
CALL gds.louvain.stream('myGraph',{includeIntermediateCommunities: true}
)
YIELD nodeId, communityId, intermediateCommunityIds
RETURN gds.util.asNode(nodeId).name AS name, communityId, intermediateCommunityIds
ORDER BY name ASC
2.结果如下

这里划分两个社团
3.带权值计算
CALL gds.louvain.stream('myGraph',{ relationshipWeightProperty: 'weight' ,includeIntermediateCommunities: true}
)
YIELD nodeId, communityId, intermediateCommunityIds
RETURN gds.util.asNode(nodeId).name AS name, communityId, intermediateCommunityIds
ORDER BY name ASC
4.结果如下

带权值之后,划分了三个社团
5.含原始社区属性计算
参数<>seedProperty:Used to set the initial community for a node. The property value needs to be a number.
用于设置节点的初始社区。属性值必须是数字。
CALL gds.louvain.stream('myGraph',{ seedProperty: 'seed',relationshipWeightProperty: 'weight' ,includeIntermediateCommunities: true}
)
YIELD nodeId, communityId, intermediateCommunityIds
RETURN gds.util.asNode(nodeId).name AS name, communityId, intermediateCommunityIds
ORDER BY name ASC6.结果如下

其实仅带有seedProperty属性,去掉关系权重“relationshipWeightProperty: ‘weight’ ,”这句话,该属性图可以直接划分为两个社区,结果和本例子初次执行结果一致,社团【2】【5】。因为有权重的影响Alice被划分出去,最终三个社团,这更加符合现实情况。
总结二:
这个算法的最优解还是需要考虑权重、迭代次数等等因素,从而符合最终预期目标,如果有需要可以参考文档(有需要请留言)。