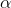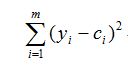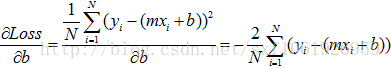写这篇文章之前,首先要对自己做一个小小的反思,很多时候在学习新技术的时候,看到出了什么什么框架,在这个框架上什么什么方法可以直接拿过来用,这样的好处就是我们可以减少写代码量,几个函数就可以帮我们解决需要写几十行代码才能解决的问题。这样看起来很好是建立在你对这个函数的底层有一个深入研究,如果你是一个新手,第一次你可能在网上查阅资料明白一个大概,但是你下次还是不会,究其原因:知其然,而不知其所以然。
对我而言,我身上也存在着这种通病,为了能:知其然,知其所以然。于是乎,我打算在学习机器学习算法的过程中,不调用机器学习函数库里面的一些封装方法,通过纯Python去实现,这一篇文章算是作为我践行:知其然,知其所以然这种思想的第一步。
好了,话不多说,开始进入我们的主题。
线性回归,就是能够用一条直线较为精确地描述数据之间的关系。这样当出现新的数据的时候,就能够预测出一个简单的值。线性回归中最常见的就是房价的问题。
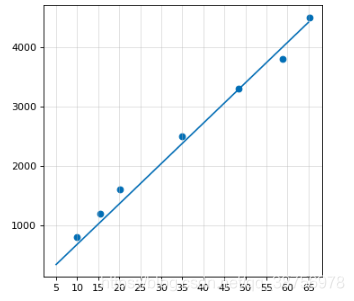
左图代表的是房价(纵坐标)与房间面积(横坐标)的关系,右图代表的是通过一条直线f = kx + b 来预测房屋关系。通过这条直线我们就可以大概知道房间面积对应的房价。
下面我们通过一个具体的例子通过Python来实现一个简单的线性回归
比如我们有一组数据,数据的格式如下所示(数据地址):


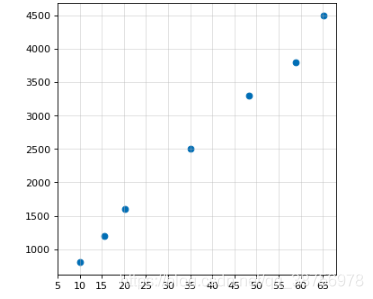
我们将这些数据通过python绘制出来,如下所示:

然后我们需要做的是找一条直线去最大化的拟合这些点,理想情况是所有点都落在直线上。希望所有点离直线的距离最近。简单起见,将距离求平方,误差可以表示为
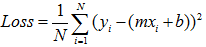
找到最能拟合数据的直线,也就是最小化误差。通常我们使用的是最小二乘法
上述公式只有m, b未知,因此可以看最一个m, b的二次方程,求Loss的问题就转变成了求极值问题。 这里不做详细说明。另每个变量的偏导数为0, 求方程组的解。
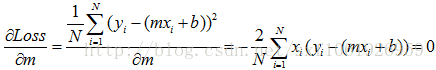

然后我们通过梯度下降的方法去更新m和b。
在动手写算法之前我们需要理一下编写思路。回归模型主体部分较为简单,关键在于如何在给出 MSE损失函数之后基于梯度下降的参数更新过程。首先我们需要写出模型的主体和损失函数以及基于损失函数的参数求导结果,然后对参数进行初始化,最后写出基于梯度下降法的参数更新过程。
import numpy as np
import matplotlib.pyplot as plt# 计算loss
def liner_loss(w,b,data):""":param w::param b::param data::return:"""x = data[:,0] # 代表的是第一列数据y = data[:,1] # 代表的是第二列数据# 损失函数:使用的是均方误差(MES)损失loss = np.sum((y - w * x - b) ** 2) / data.shape[0]# 返回lossreturn loss# 计算梯度并更新参数
def liner_gradient(w,b,data,lr):""":param w::param b::param data::param lr::return:"""# 数据集行数N = float(len(data))# 提取数据x = data[:,0]y = data[:,1]# 求梯度dw = np.sum(-(2 / N) * x * (y - w * x -b))db = np.sum(-(2 / N) * (y - w * x -b))# 更新参数w = w - (lr * dw)b = b - (lr * db)return w,b# 每次迭代做梯度下降
def optimer(data,w,b,lr,epcoh):""":param data::param w::param b::param lr::param epcoh:训练的次数:return:"""for i in range(epcoh):# 通过每次循环不断更新w,b的值w,b = liner_gradient(w,b,data,lr)# 每训练100次更新下loss值if i % 100 == 0 :print('epoch {0}:loss={1}'.format(i,liner_loss(w,b,data)))return w,b# 绘图
def plot_data(data,w,b):""":param data::param w::param b:"""x = data[:,0]y = data[:,1]y_predict = w * x + bplt.plot(x, y, 'o')plt.plot(x, y_predict, 'k-')plt.show()def liner_regression():"""构建模型"""# 加载数据data = np.loadtxt('D:\python-workspace\Machine_Learing\Regression\data.csv',delimiter=',')# 显示原始数据的分布x = data[:, 0]y = data[:, 1]plt.plot(x, y, 'o')plt.show()# 初始化参数lr = 0.01 # 学习率epoch = 1000 # 训练次数w = 0.0 # 权重b = 0.0 # 偏置# 输出各个参数初始值print('initial variables:\n initial_b = {0}\n intial_w = {1}\n loss of begin = {2} \n'\.format(b,w,liner_loss(w,b,data)))# 更新w和bw,b = optimer(data,w,b,lr,epoch)# 输出各个参数的最终值print('final formula parmaters:\n b = {1}\n w = {2}\n loss of end = {3} \n'.format(epoch,b,w,liner_loss(w,b,data)))# 显示plot_data(data,w,b)if __name__ == '__main__':liner_regression()
然后我们运行,结果如下:

| initial variables:
epoch 0:loss=3.265436338536489
|
好了,以上就是Python实现的一个简单的线性回归。
不积跬步,无以至千里。加油!