目录
目录
1.选取数据
2.VMD函数-matlab代码
3.采用matlab脚本导入数据并做VMD分解
4.计算中心频率
5.结果展示
6.智能算法优化VMD参数
1.选取数据
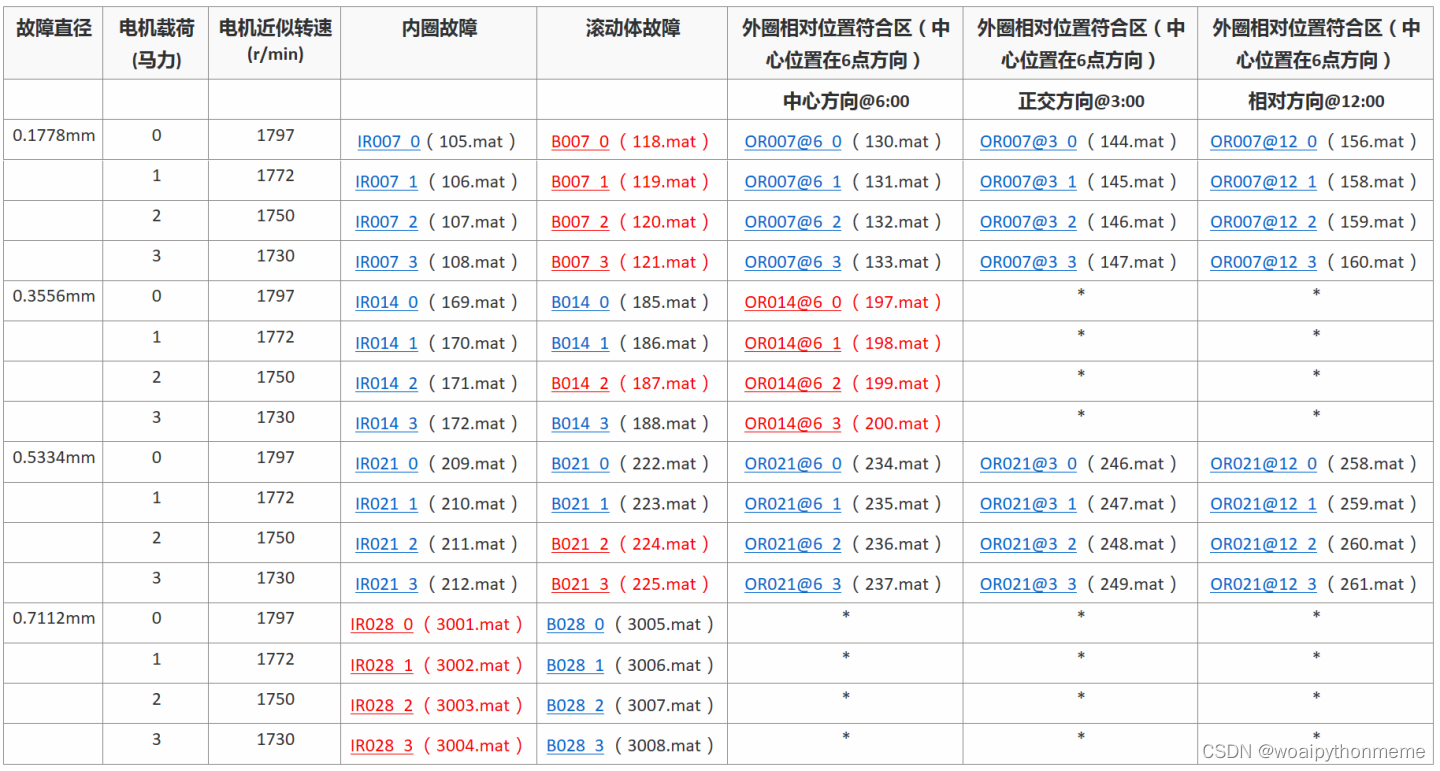
选取1797转速下的内圈故障数据,也就是105.mat,数据集可以在官网下载。下载数据文件|凯斯工程学院 |凯斯西储大学 (case.edu)![]() https://engineering.case.edu/bearingdatacenter/download-data-file
https://engineering.case.edu/bearingdatacenter/download-data-file
2.VMD函数-matlab代码
VMD函数的matlab代码实现,该代码作为函数实现,无需修改,直接使用即可。
function [u, u_hat, omega] = VMD(signal, alpha, tau, K, DC, init, tol)
% Variational Mode Decomposition% Input and Parameters:
% ---------------------
% signal - the time domain signal (1D) to be decomposed
% alpha - the balancing parameter of the data-fidelity constraint 惩罚因子
% tau - time-step of the dual ascent ( pick 0 for noise-slack )
% K - the number of modes to be recovered 模态分量
% DC - true if the first mode is put and kept at DC (0-freq)
% init - 0 = all omegas start at 0
% 1 = all omegas start uniformly distributed
% 2 = all omegas initialized randomly
% tol - tolerance of convergence criterion; typically around 1e-6
%
% Output:
% -------
% u - the collection of decomposed modes
% u_hat - spectra of the modes
% omega - estimated mode center-frequencies%---------- Preparations
% Period and sampling frequency of input signal
save_T = length(signal);
fs = 1/save_T;% extend the signal by mirroring
T = save_T;
f_mirror(1:T/2) = signal(T/2:-1:1);
f_mirror(T/2+1:3*T/2) = signal;
f_mirror(3*T/2+1:2*T) = signal(T:-1:T/2+1);
f = f_mirror;% Time Domain 0 to T (of mirrored signal)
T = length(f);
t = (1:T)/T;% Spectral Domain discretization
freqs = t-0.5-1/T;% Maximum number of iterations (if not converged yet, then it won't anyway)
N = 500;% For future generalizations: individual alpha for each mode
Alpha = alpha*ones(1,K);% Construct and center f_hat
f_hat = fftshift((fft(f)));
f_hat_plus = f_hat;
f_hat_plus(1:T/2) = 0;% matrix keeping track of every iterant // could be discarded for mem
u_hat_plus = zeros(N, length(freqs), K);% Initialization of omega_k
omega_plus = zeros(N, K);
switch initcase 1for i = 1:Komega_plus(1,i) = (0.5/K)*(i-1);endcase 2omega_plus(1,:) = sort(exp(log(fs) + (log(0.5)-log(fs))*rand(1,K)));otherwiseomega_plus(1,:) = 0;
end% if DC mode imposed, set its omega to 0
if DComega_plus(1,1) = 0;
end% start with empty dual variables
lambda_hat = zeros(N, length(freqs));% other inits
uDiff = tol+eps; % update step
n = 1; % loop counter
sum_uk = 0; % accumulator% ----------- Main loop for iterative updateswhile ( uDiff > tol && n < N ) % not converged and below iterations limit% update first mode accumulatork = 1;sum_uk = u_hat_plus(n,:,K) + sum_uk - u_hat_plus(n,:,1);% update spectrum of first mode through Wiener filter of residualsu_hat_plus(n+1,:,k) = (f_hat_plus - sum_uk - lambda_hat(n,:)/2)./(1+Alpha(1,k)*(freqs - omega_plus(n,k)).^2);% update first omega if not held at 0if ~DComega_plus(n+1,k) = (freqs(T/2+1:T)*(abs(u_hat_plus(n+1, T/2+1:T, k)).^2)')/sum(abs(u_hat_plus(n+1,T/2+1:T,k)).^2);end% update of any other modefor k=2:K% accumulatorsum_uk = u_hat_plus(n+1,:,k-1) + sum_uk - u_hat_plus(n,:,k);% mode spectrumu_hat_plus(n+1,:,k) = (f_hat_plus - sum_uk - lambda_hat(n,:)/2)./(1+Alpha(1,k)*(freqs - omega_plus(n,k)).^2);% center frequenciesomega_plus(n+1,k) = (freqs(T/2+1:T)*(abs(u_hat_plus(n+1, T/2+1:T, k)).^2)')/sum(abs(u_hat_plus(n+1,T/2+1:T,k)).^2);end% Dual ascentlambda_hat(n+1,:) = lambda_hat(n,:) + tau*(sum(u_hat_plus(n+1,:,:),3) - f_hat_plus);% loop countern = n+1;% converged yet?uDiff = eps;for i=1:KuDiff = uDiff + 1/T*(u_hat_plus(n,:,i)-u_hat_plus(n-1,:,i))*conj((u_hat_plus(n,:,i)-u_hat_plus(n-1,:,i)))';enduDiff = abs(uDiff);end%------ Postprocessing and cleanup% discard empty space if converged early
N = min(N,n);
omega = omega_plus(1:N,:);% Signal reconstruction
u_hat = zeros(T, K);
u_hat((T/2+1):T,:) = squeeze(u_hat_plus(N,(T/2+1):T,:));
u_hat((T/2+1):-1:2,:) = squeeze(conj(u_hat_plus(N,(T/2+1):T,:)));
u_hat(1,:) = conj(u_hat(end,:));u = zeros(K,length(t));for k = 1:Ku(k,:)=real(ifft(ifftshift(u_hat(:,k))));
end% remove mirror part
u = u(:,T/4+1:3*T/4);% recompute spectrum
clear u_hat;
for k = 1:Ku_hat(:,k)=fftshift(fft(u(k,:)))';
endend3.采用matlab脚本导入数据并做VMD分解
该段代码将内圈故障数据导入,并进行了VMD分解。其中得到的u即为分解出来的IMF分量。
clc
clear
fs=12000;%采样频率
Ts=1/fs;%采样周期
L=1500;%采样点数
t=(0:L-1)*Ts;%时间序列
STA=1; %采样起始位置
%----------------导入内圈故障的数据-----------------------------------------
load 105.mat
X = X105_DE_time(1:L)'; %这里可以选取DE(驱动端加速度)、FE(风扇端加速度)、BA(基座加速度),直接更改变量名,挑选一种即可。%--------- some sample parameters forVMD:对于VMD样品参数进行设置---------------
alpha = 2500; % moderate bandwidth constraint:适度的带宽约束/惩罚因子
tau = 0; % noise-tolerance (no strict fidelity enforcement):噪声容限(没有严格的保真度执行)
K = 8; % modes:分解的模态数,可以自行设置,这里以8为例。
DC = 0; % no DC part imposed:无直流部分
init = 1; % initialize omegas uniformly :omegas的均匀初始化
tol = 1e-7;
%--------------- Run actual VMD code:数据进行vmd分解---------------------------
[u, u_hat, omega] = VMD(X, alpha, tau, K, DC, init, tol); %其中u为分解得到的IMF分量4.计算中心频率
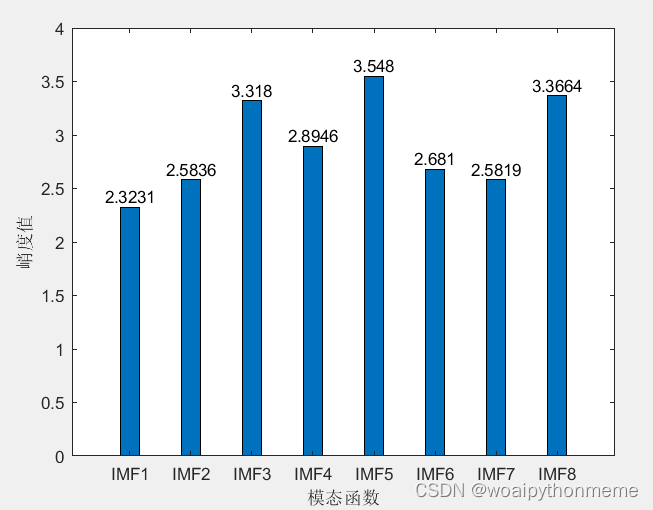
中心频率可以用来确定模态分量K的个数,average即为计算得出的中心频率。因为是要确定分解层数,将K设置不同的值,例如1-9,比较最后一个分量的频率。可以确定K值的依据为:一旦出现相似频率,此时的K值被确定为最佳K值。
5.结果展示
VMD分解图:
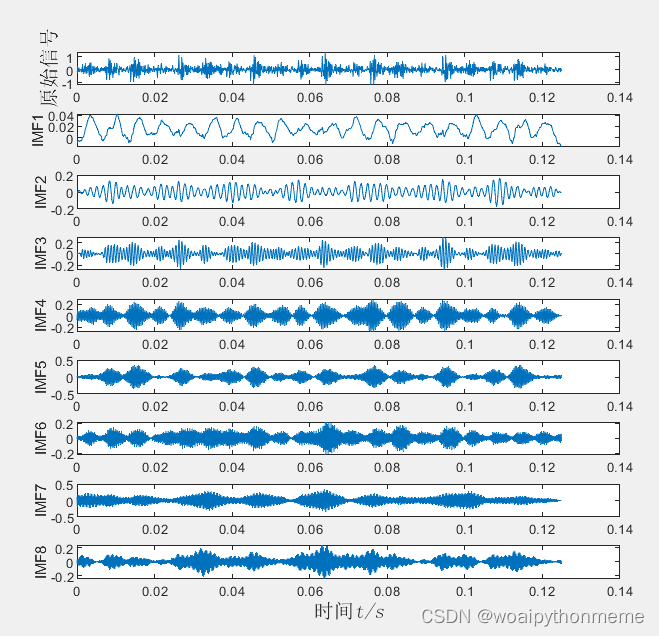
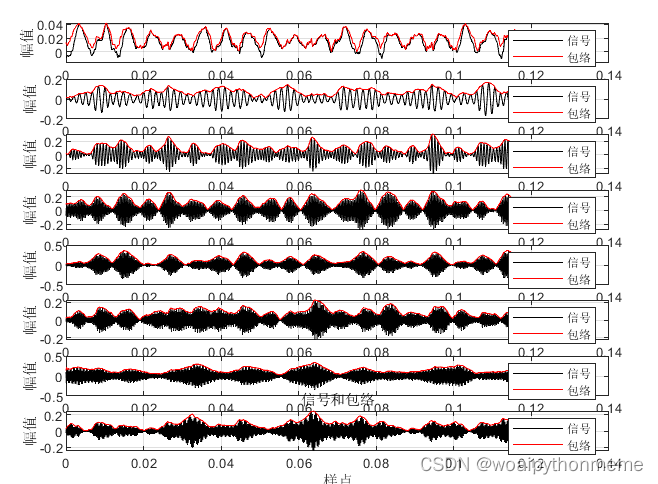
包络线图 :
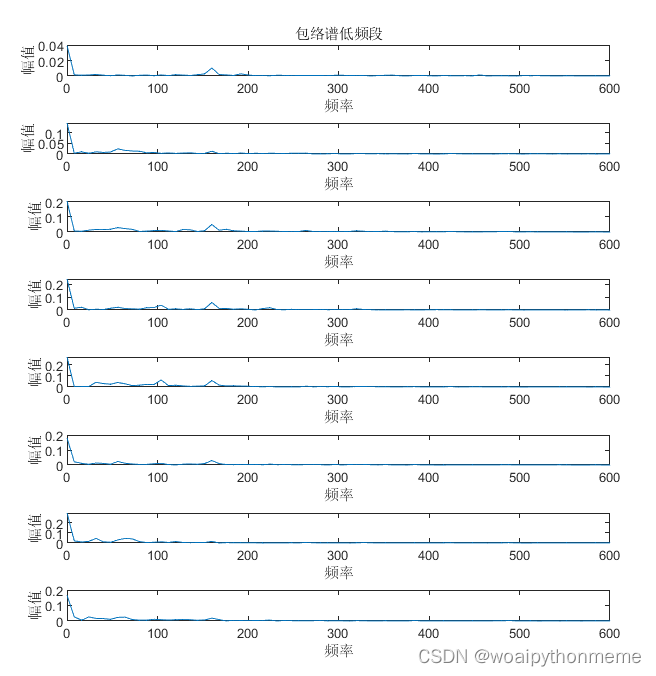
包络谱图:
峭度值:
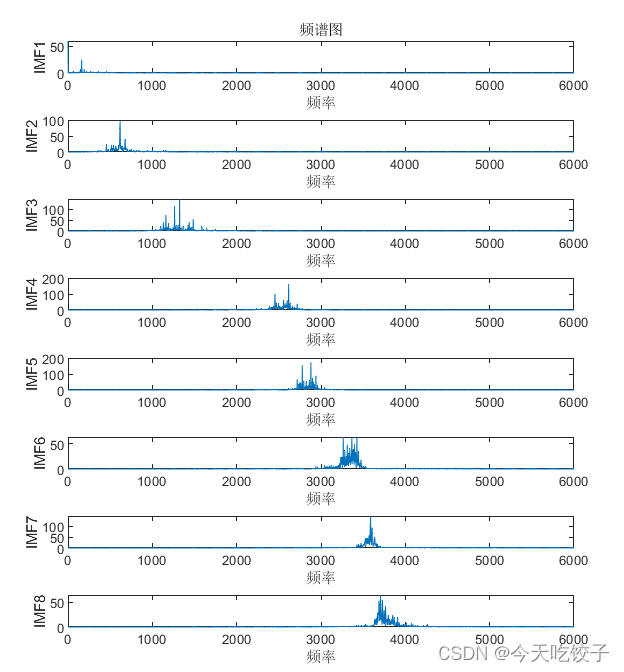
频谱图:
包络熵计算:
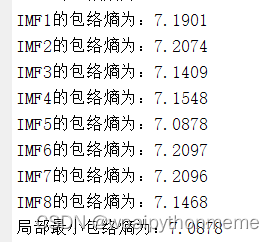
近似熵计算:
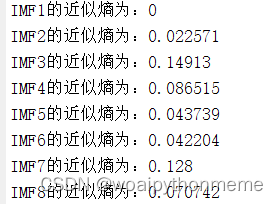
模糊熵计算:

排列熵计算:

多尺度排列熵计算结果:
样本熵计算结果:

6.智能算法优化VMD参数
智能算法优化VMD的模态分解数和惩罚因子两个参数将在下一篇文章介绍!敬请关注!
(2条消息) 麻雀算法SSA,优化VMD,适应度函数为最小包络熵,包含MATLAB源代码,直接复制粘贴!_今天吃饺子的博客-CSDN博客
完整代码获取:下方卡片回复关键词:VMD