今天我会带大家真正写一个Django项目,对于入门来说是有点难度的,因为逻辑比较复杂,但是真正的知识就是函数与面向对象,这也是培养用Django思维写项目的开始
Django文件配置
Django模版文件配置
文件路径 test_site -- test_site -- settings.py
TEMPLATES = [{'BACKEND': 'django.template.backends.django.DjangoTemplates','DIRS': [os.path.join(BASE_DIR, "template")], # template文件夹位置'APP_DIRS': True,'OPTIONS': {'context_processors': ['django.template.context_processors.debug','django.template.context_processors.request','django.contrib.auth.context_processors.auth','django.contrib.messages.context_processors.messages',],},},
]
Django静态文件配置
文件路径 test_site -- test_site -- settings.py
STATIC_URL = '/static/' # HTML中使用的静态文件夹前缀
STATICFILES_DIRS = [os.path.join(BASE_DIR, "static"), # 静态文件存放位置
]
看不明白?有图有真相:

刚开始学习时可在配置文件中暂时禁用csrf中间件,方便表单提交测试。
文件路径 test_site -- test_site -- settings.py
MIDDLEWARE = ['django.middleware.security.SecurityMiddleware','django.contrib.sessions.middleware.SessionMiddleware','django.middleware.common.CommonMiddleware',# 'django.middleware.csrf.CsrfViewMiddleware','django.contrib.auth.middleware.AuthenticationMiddleware','django.contrib.messages.middleware.MessageMiddleware','django.middleware.clickjacking.XFrameOptionsMiddleware',
]
Django 数据库配置
Django为什么要配置数据库
因为Django默认采用的是sqlite3数据库,而我们用Pycharm编写程序时使用的是Pymysql模块和数据库交互的,为了能够简化编写程序的流程,我们需要修改默认数据库配置
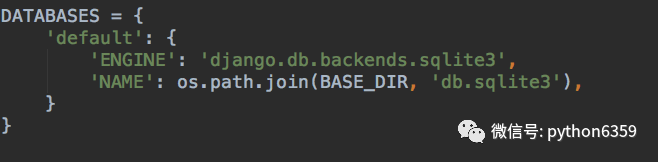
在修改数据配置之前,我们是不是要先有数据库,请先创建一个MySQL数据库吧
文件路径 test_site -- test_site -- settings.py
DATABASES = {'default': {'ENGINE': 'django.db.backends.mysql', # 注意这几个用大写的单词,必须写大写,这些坑我都走过,也浪费了不少时间,希望你不要再走'NAME': 'test_site','HOST': '127.0.0.1','PORT': 3306,'USER': 'root','PASSWORD': '', # 我的数据库是没有密码的,你的密码是什么就写什么,没有就留空}
}
在和settings.py同目录下的 __init__.py文件中做配置
文件路径 test_site -- test_site -- __init__.py
import pymysql
pymysql.install_as_MySQLdb()
至此,用Django写项目,相关的配置已完成,但是有一些关于Django的基础知识要学习,就像print一样简单,这也是我们写项目的准备工作之一
Django基础必备三件套(三个小模块)
HttpResponse 把数据返回给浏览器
这个模块名字起的特别好,根据名字就能大概猜出来的他的意思,真会起名字,不想某些人,写一套编程语言,用个什么蟒蛇,写个框架用个乐手的名字,真的是不为程序员着想
内部传入一个字符串,返回给浏览器,我们在上一章的Hello World就是这么写的
def index(request):# 业务逻辑代码return HttpResponse("Hello World")
render 对位填充
render 本意就是着色,粉刷的意思,很好理解,使用方式需要记住
除request参数外还接受一个待渲染的模板文件和一个保存具体数据的字典参数。
将数据填充进模板文件,最后把结果返回给浏览器。(类似于我们上章用到的jinja2)
def index(request):# 业务逻辑代码return render(request, "index.html", {"name": "Albert", "hobby": ["音乐", "篮球"]})
redirect 重定向
接受一个URL参数,表示跳转到指定的URL
注意:“” 里面的两个/ / 能少,不写会报错!注意:“” 里面的两个/ / 能少,不写会报错!注意:“” 里面的两个/ / 能少,不写会报错!
def index(request):# 业务逻辑代码return redirect("/home/")
重定向实现原理

redirect 默认的302(临时重定向),30* 都是重定向,301是永久重定向,对于seo工程师用永久重定向比较多,如果要变为永久重定向,只需要
在redirect()里面增加这段代码即可
permanent=True
Django写图书管理系统
目标要求:
-
分别展示出出版社页面,书籍页面和作者页面
-
一个出版社可以出版多本书籍(一对多)
-
一个作者可以写多本书,一本书也可有多个作者(多对多)
在完成以上配置之后,其实这个程序就已经写了一半了,是Django帮你写的,接下来真正的Python代码我们只需要写函数和类,在实际的工作中,也是这样的
为了能让大家更清楚掌握用Django写程序的过程,接下来我们按照过程先后带领大家把这个程序实现
创建Django项目
开始项目
在终端下写入如下指令
# Django-admin startproject lms# cd lms# python3 manage.py startapp app01
当然以上操作你也可以在Pycharm上进行,完全没有问题
创建数据库
注意数据库的名字,自己创建
修改配置
按照以上方法操作执行
建立url对应关系
在用户通过链接访问你的网站的时候,对于用户来说这是一个链接地址,对于程序来时其实是一个函数,通过这个函数才找到数据库中的对象,对象的方法和整个的前端页面
文件路径:和settings同目录下
"""lms URL ConfigurationThe `urlpatterns` list routes URLs to views. For more information please see:https://docs.djangoproject.com/en/1.11/topics/http/urls/
Examples:
Function views1. Add an import: from my_app import views2. Add a URL to urlpatterns: url(r'^$', views.home, name='home')
Class-based views1. Add an import: from other_app.views import Home2. Add a URL to urlpatterns: url(r'^$', Home.as_view(), name='home')
Including another URLconf1. Import the include() function: from django.conf.urls import url, include2. Add a URL to urlpatterns: url(r'^blog/', include('blog.urls'))
"""
from django.conf.urls import url
from django.contrib import admin
from app01 import viewsurlpatterns = [# 管理员账户登陆url(r'^admin/', admin.site.urls),# 出版社列表url(r'^publisher_list/', views.publisher_list),# 添加出版社url(r'^add_publisher/', views.add_publisher),# 删除出版社url(r'^drop_publisher/', views.drop_publisher),# 修改出版社url(r'^edit_publisher/', views.edit_publisher),url(r'^book_list/', views.book_list),url(r'^add_book/', views.add_book),url(r'^drop_book/', views.drop_book),url(r'^edit_book/', views.edit_book),url(r'^author_list/', views.author_list),url(r'^add_author/', views.add_author),url(r'^drop_author/', views.drop_author),url(r'^edit_author/', views.edit_author),url(r'^$', views.publisher_list), # 只有跟网址,默认匹配
]
开始写Django项目
创建对象,并关联数据库
找到app01这个文件夹,也就是项目应用的主文件夹下面有modes.py 文件,这个文件就是我们用来存放类和对象的文件,这里需要用到ORM(对象关系映射),这里我们先记住他的使用方法就好了,过几天带大家手写一个ORM。
注意:其他文件不要动,其他文件不要动,其他文件不要动
from django.db import models# Create your models here.# 出版社类
class Publisher(models.Model):id = models.AutoField(primary_key=True)name = models.CharField(max_length=64)# 书籍的类
class Book(models.Model):id = models.AutoField(primary_key=True)name = models.CharField(max_length=64)publisher = models.ForeignKey(to=Publisher) # Django中创建外键联表操作# 作者的类
class Author(models.Model):id = models.AutoField(primary_key=True)name = models.CharField(max_length=64)# 一个作者可以对应多本书,一本书也可以有多个作者,多对多,在数据库中创建第三张表book = models.ManyToManyField(to=Book)
写核心逻辑函数
同样是app01文件夹下的views.py这个文件,上面的urls.py文件中的函数都是从这个文件中引入的,这个文件是最主要的文件
from django.shortcuts import render, redirect# Create your views here.
from app01 import models# 出版社列表
def publisher_list(request):# 查询publisher = models.Publisher.objects.all() # ORM中的查询全部# 渲染return render(request, 'publisher_list.html', {'publisher_list': publisher})# 添加出版社
def add_publisher(request):# POST请求表示用户已提交数据if request.method == 'POST':new_publisher_name = request.POST.get('name')models.Publisher.objects.create(name=new_publisher_name)return redirect('/publisher_list/')# 渲染待添加页面给用户return render(request, 'add_publisher.html')# 删除出版社
def drop_publisher(request):# GET请求拿到url中的IDdrop_id = request.GET.get('id')drop_obj = models.Publisher.objects.get(id=drop_id)drop_obj.delete()return redirect('/publisher_list/')# 编辑出版社
def edit_publisher(request):if request.method == 'POST':edit_id = request.GET.get('id')edit_obj = models.Publisher.objects.get(id=edit_id)new_name = request.POST.get('name')edit_obj.name = new_name# 注意保存edit_obj.save()return redirect('/publisher_list/')edit_id = request.GET.get('id')edit_obj = models.Publisher.objects.get(id=edit_id)return render(request, 'edit_publisher.html', {'publisher': edit_obj})# 书籍的列表
def book_list(request):book = models.Book.objects.all()return render(request, 'book_list.html', {'book_list': book})# 添加本书籍
def add_book(request):if request.method == 'POST':new_book_name = request.POST.get('name')publisher_id = request.POST.get('publisher_id')models.Book.objects.create(name=new_book_name, publisher_id=publisher_id)return redirect('/book_list/')res = models.Publisher.objects.all()return render(request, 'add_book.html', {'publisher_list': res})# 删除本书籍
def drop_book(request):drop_id = request.GET.get('id')drop_obj = models.Book.objects.get(id=drop_id)drop_obj.delete()return redirect('/book_list/')# 编辑本书籍
def edit_book(request):if request.method == 'POST':new_book_name = request.POST.get('name')new_publisher_id = request.POST.get('publisher_id')edit_id = request.GET.get('id')edit_obj = models.Book.objects.get(id=edit_id)edit_obj.name = new_book_nameedit_obj.publisher_id = new_publisher_idedit_obj.save()return redirect('/book_list/')edit_id = request.GET.get('id')edit_obj = models.Book.objects.get(id=edit_id)all_publisher = models.Publisher.objects.all()return render(request, 'edit_book.html', {'book': edit_obj, 'publisher_list': all_publisher})# 作者的列表
def author_list(request):author = models.Author.objects.all()return render(request, 'author_list.html', {'author_list': author})# 添加个作者
def add_author(request):if request.method == 'POST':new_author_name = request.POST.get('name')models.Author.objects.create(name=new_author_name)return redirect('/author_list/')return render(request, 'add_author.html')# 删除个作者
def drop_author(request):drop_id = request.GET.get('id')drop_obj = models.Author.objects.get(id=drop_id)drop_obj.delete()return redirect('/author_list/')# 修改下作者
def edit_author(request):if request.method == 'POST':edit_id = request.GET.get('id')edit_obj = models.Author.objects.get(id=edit_id)new_author_name = request.POST.get('name')new_book_id = request.POST.getlist('book_id')edit_obj.name = new_author_nameedit_obj.book.set(new_book_id)edit_obj.save()return redirect('/author_list/')edit_id = request.GET.get('id')edit_obj = models.Author.objects.get(id=edit_id)all_book = models.Book.objects.all()return render(request, 'edit_author.html', {'author': edit_obj,'book_list': all_book})
写前端页面
前端基本上是一直在重复的页面,注意几个与后端建立联系的地方就好了
<tbody>{% for publisher in publisher_list %}<tr><td>{{ forloop.counter }}</td><td>{{ publisher.name }}</td><td class="text-center"><a class="btn btn-info btn-sm" href="/edit_publisher/?id={{ publisher.id }}"><iclass="fa fa-pencil fa-fw"aria-hidden="true"></i>编辑</a><a class="btn btn-danger btn-sm" href="/drop_publisher/?id={{ publisher.id }}"><iclass="fa fa-trash-o fa-fw"aria-hidden="true"></i>删除</a></td></tr>{% endfor %}</tbody>
前端复杂的部分是与数据库多表查询的部分,需要用for循环,注意for循环在Django中的使用方式
<select class="form-control" name="publisher_id">{% for publisher in publisher_list %}{# 如果当前循环到的出版社 和 书关联的出版社 相等 #}{% if publisher == book.publisher %}<option selectedvalue="{{ publisher.id }}">{{ publisher.name }}</option>{% else %}<option value="{{ publisher.id }}">{{ publisher.name }}</option>{% endif %}{% endfor %}</select>
完整代码已上传到GIthub,请点击我的github:https://github.com/mayite/lms访问下载
原创作者:马一特
文章出处:http://www.cnblogs.com/mayite/






![[Python从零到壹] 十五.文本挖掘之数据预处理、Jieba工具和文本聚类万字详解](https://img-blog.csdnimg.cn/20210623125327751.png#pic_center)