Relate is an Environment for Learning And TEaching
Relate是在 Django上面构建的,可以快速搭建LMS系统,该系统可以方便学习管理和在线课程的发放;
由于最近弄了一个python的课程,所以自己动手测试了以下这个框架
Relate本身包含了后台管理系统,按照官方文档的配置安装就可以启动这个后台管理系统
relate本身是基于YAML和MARKDOWN来进行书写和组织课程相关的材料和测试的。
这些语言可以通过pandoc转换成 其它格式
relate可以渲染 jupyter notebook同时可以嵌入视频
relate本身作为一个服务器和课程开发是分开的,课程开发是一个git的repo,然后只要告诉relate从哪里寻找就好了
这里说一下应用relate创建的课程示例的步骤:
1. 按照指示安装启动服务:
https://documen.tician.de/relate/misc.html
这里不要忘了执行 npm install 这个命令哦
2. 在启动服务器的时候会让输入邮箱和密码
3. 在浏览器打开本地8000端口,就可以访问到web应用,登录的时候采用用户名和密码;其中用户名是计算机的用户名,密码是2中设置的密码
4. 尝试修该local_settings.py,其中重要的部分说明如下:
# {{{ database and site SECRET_KEY = 'xxx'ALLOWED_HOSTS = ["relate.example.com","127.0.0.1",]
EMAIL_HOST = 'smtp.whu.edu.cn' EMAIL_HOST_USER = 'xxx@whu.edu.cn' EMAIL_HOST_PASSWORD = 'xxxxx' EMAIL_PORT = 25 EMAIL_USE_TLS = True # definitely true here ROBOT_EMAIL_FROM = "xxxx@whu.edu.cn" RELATE_ADMIN_EMAIL_LOCALE = "en_US"SERVER_EMAIL = ROBOT_EMAIL_FROM# ADMINS = ( # ("Example Admin", "admin@example.com"), # ) ADMINS = (("xxxx@qq.com", ),)
要注意自己的邮箱服务要开启smtp服务~
relate会通过登录这个邮箱,然后发一个链接给想要登录的用户(如果这个用户想用邮箱登录的话,这个用户主可以是学生或者管理员),用户打开自己的邮箱,看到链接并点击进入,这个用户就可以访问这个系统了。
# {{{ sign-in methods RELATE_SIGN_IN_BY_EMAIL_ENABLED = True RELATE_SIGN_IN_BY_USERNAME_ENABLED = True RELATE_REGISTRATION_ENABLED = True RELATE_SIGN_IN_BY_EXAM_TICKETS_ENABLED = True
LANGUAGE_CODE = 'zh-Hans'
这里配置中文显示,注意的是,这里要首先安装,再配置哦,安装的方法在文档里有详细的说明的
。
5. 使用管理系统创建课程
这里的课程样例在这里
https://github.com/inducer/relate-sample
可以看到这里面所有的文件基本都是YAML格式的
要创建课程并不需要在本地上下载这个repo,需要置顶git的地址就可以,relate会将其存储到某个位置(该位置在配置文件里面进行配置)

,点击设置新课程

按照说明进行设置就可以了。
设置完之后,再访问页面就可以看到课程的连接了,可以点进去看一看,这个时候在另一个浏览器里可以用新的邮箱申请登录哦。
6. 访问和参加课程
访问的话需要登录,登录可以使用邮件,然后relate会给邮件发一个链接,点击链接就可以登录的
要参加课程需要一定的权限。需要在后台进行操作
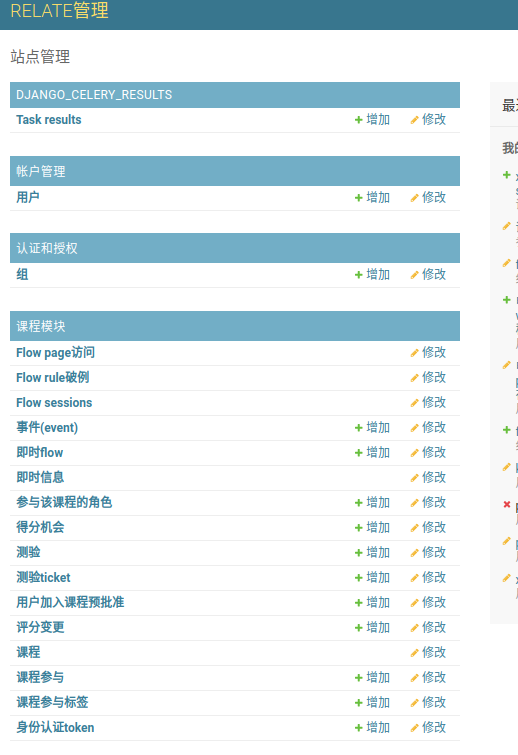
在站点管理里面找到课程模块下面的课程参与点进去
,然后在这里增加可以参加该课程的用户就可以了:
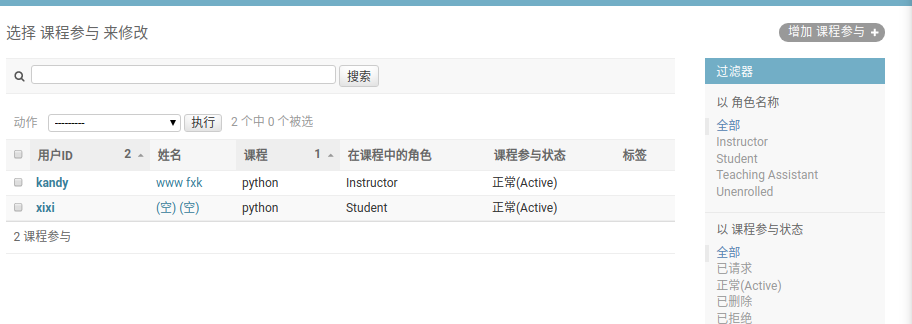
到这里,基本就可以实现了用户登录,参与课程的审核,以及添加课程和访问课程,还有课程管理等功能
最后就安心的根绝 relate制定的规则开发自己的课程就好了
,这里的课程和莫烦的博客其实有很大的差别,首先它不是公开的,其次里面增加了很多管理上的东西。
在开放课程的时候可以使用博客,这样可以专注课程核心内容的开发。
在运营和管理课程的时候才需要lms系统,总的来说,这个系统有以下功能值得尝试使用:
1. 在特定的时间制定相应的课程和课件
2. 可以实现访问控制
3. 可以对学生的作业进行统一管理和评估
4. 包含课程日历,比如课表信息
5. 可以包含pdf课件以及相应的链接


![[Python从零到壹] 十五.文本挖掘之数据预处理、Jieba工具和文本聚类万字详解](https://img-blog.csdnimg.cn/20210623125327751.png#pic_center)