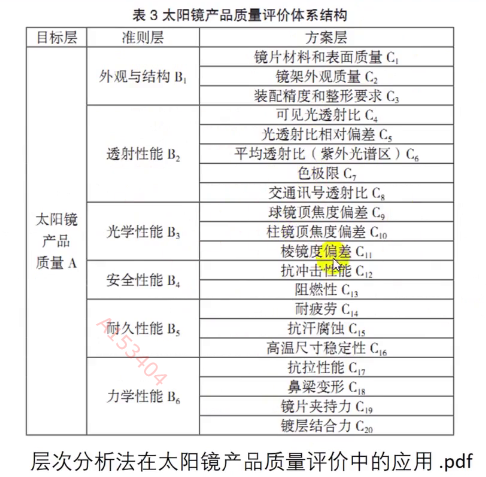
层次分析法
文章目录
- 层次分析法
- 概述
- 层次分析法简介
- 层次分析法典型应用
- 层次分析法基本原理
- 层次分析法的步骤和方法
- 建立层次结构模型
- 构造判断矩(成对比较)阵
- 层次单排序及其一致性检验
- 一致性检验
- 正互反阵最大特征根和特征向量的简化计算
- 层次总排序及其一致性检验
- 层次总排序
- 层次总排序的一致性检验
- 层次分析法的基本步骤归纳如下
- 建模实例
- 问题提出
- 问题的分析与假设
- 模型的建立与求解
- 建立层次结构图
- 确定准则层对目标层的权重向量
- 确定方案层对准则层的权重向量
- 确定方案层P对目标层O的组合权重向量
- 模型的结果分析与推广
- 层次分析法的优缺点
- 层次分析法的优点
- 层次分析法的局限性
- 层次分析法代码
概述
层次分析法简介
- 人们在对社会、经济以及管理领域的问题进行系统分析时,面临的经常是一个由相互关联、相互制约的众多因素构成的复杂系统。层次分析法则为研究这类复杂的系统,提供了一种新的、简洁的、实用的决策方案。
- 层次分析法( AHP \text{AHP} AHP法)是一种解决多目标的复杂问题的定性与定量相结合的决策分析方法。该方法将定量分析与定性分析结合起来,用决策者的经验判断各衡量目标能否实现的标准之间的相对重要程度,并合理的给出每个决策方案的对每个标准的权数,利用权数求出各方案的优劣次序,比较有效的应用于那些难以用定量方法解决的课题。
- 层次分析法是社会、经济系统决策中的有效工具。其特征是合理地将定性与定量的决策结合起来,按照思维,心理的规律把决策过程层次化、数量化。是系统科学中常用的一种系统分析方法。
- 该方法自1982年被介绍到我国以来,以其定性与定量相结合地处理各种决策因素的特点,以及其系统灵活简洁的优点,迅速地在我国社会经济各个领域内,如工程计划、资源分配、方案排序、政策指定、冲突问题、性能评价、能源系统分析、城市规划、经济管理、科研评价等,得到了广泛的重视和认可。
层次分析法典型应用
- 用于最佳方案的选取(选择运动员、选择地址)
- 用于评价类问题(评价水质状况、评价环境)
- 用于指标体系的优选(兼顾科学和效率)
层次分析法基本原理
层次分析法根据问题的性质和要达到的总目标,将问题分解为不同的组成因素,并按照因素间的相互影响以及隶属关系将因素按不同层次聚集组合,形成一个多层次的分析结构模型,从而最终使问题归结为最低层(供决策的方案、措施等)相对于最高层(总目标)的相对重要权值的确定或相对优劣次序的排定。
层次分析法的步骤和方法
运用层次分析法构造系统模型时,大体可以分为以下四个步骤:
- 建立层次结构模型
- 构造判断(成对)比较矩阵
- 层次单排序及其一致性检验
- 层次总排序及其一致性检验
建立层次结构模型
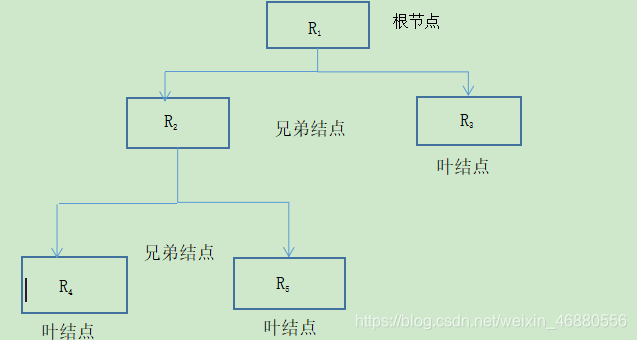
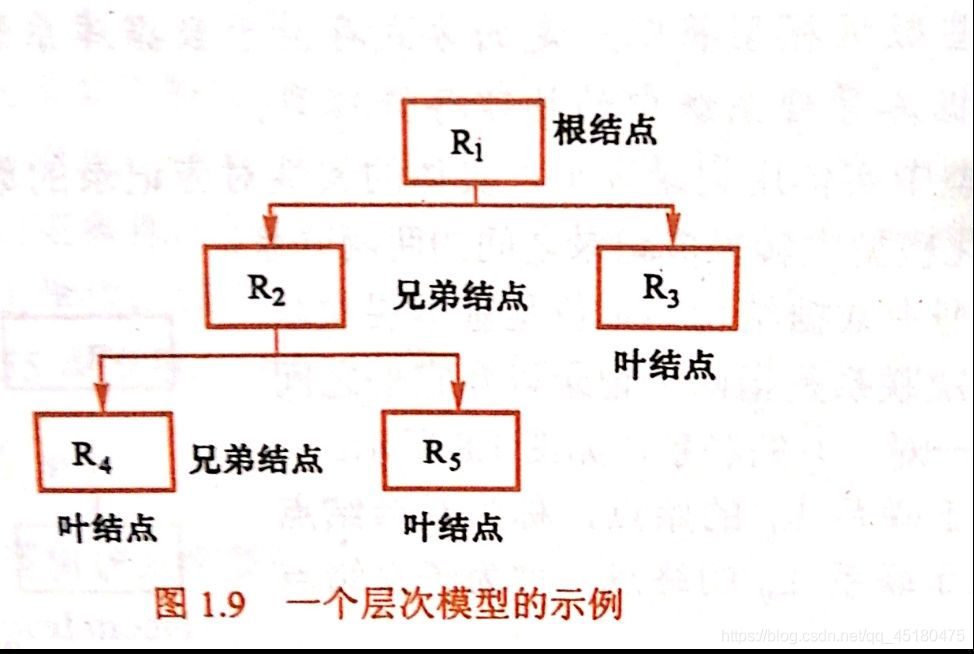
将决策的目标、考虑的因素(决策准则)和决策对象按它们之间的相互关系分为最高层,中间层和对低层,绘出层次结构图。
- 最高层:决策的目的、要解决的问题。
- 中间层:考虑的因素、决策的准则。
- 最低层:决策时的备选方案。
对于相邻的两层,称最高层为目标层,低层为因素层。比如我们只考虑中间层和最低层时,此时中间层就是最高层,即目标层;最低层就是因素层。
例1 建立层次结构模型
选择旅游目的地:如何在3个目的地中按照景色、费用、居住条件等因素选择。
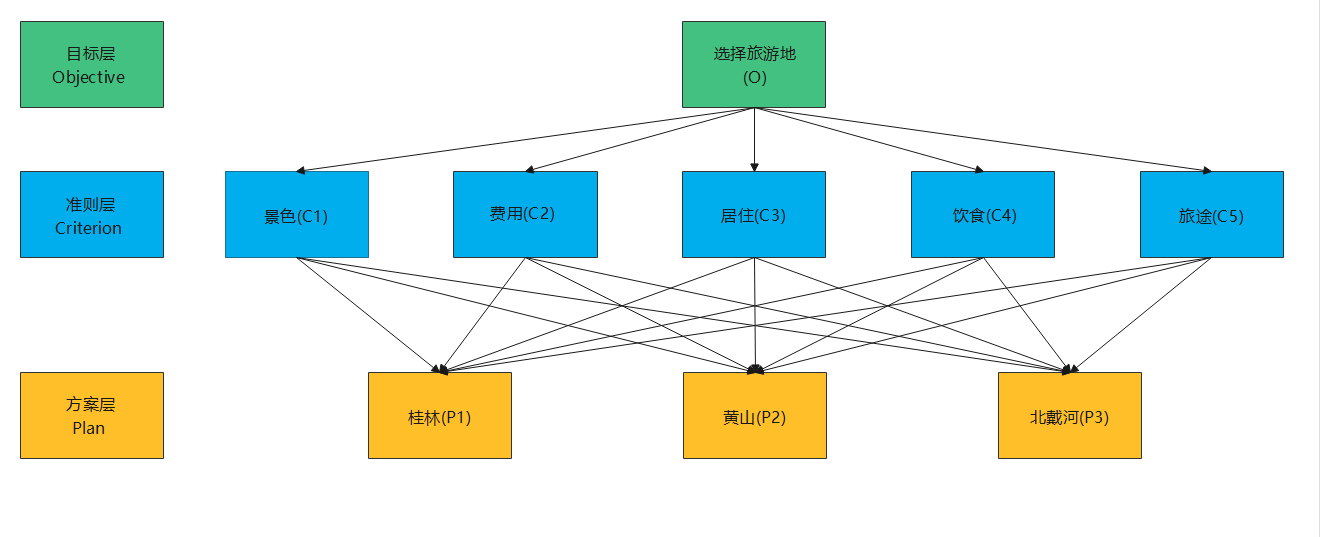 层次结构图 |
层次分析法的思维过程的归纳:
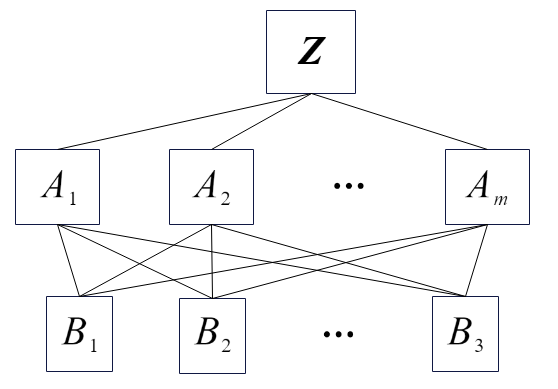
将决策问题分为3个或多个层次:
- 最高层:表示解决问题的目的,即层次分析要达到的总目标。通常只有一个总目标。也称为目标层。
- 中间层:表示采取某种措施、政策、方案等实现预定总目标所涉及的中间环节。也称为准则层、指标层、策略层、约束层等。
- 最低层:表示将选用的解决问题的各种措施、政策、方案等。通常有几个方案可选。
每层有若干元素,层间元素的关系用相连直线表示。
层次分析法所要解决的问题是关于最低层对最高层的相对权重问题,按此相对权重可以对最低层中的各种方案、措施进行排序从而在不同的方案中作出选择或形成选择方案的原则。
构造判断矩(成对比较)阵
在确定各层次各因素之间的权重时,如果只是定性的结果,则常常不容易被别人接受,因而提出一致矩阵法:
- 不把所有因素放在一起比较,而是两两相互比较。
- 对比时采用相对尺度,以尽可能减少性质不同的诸因素相互比较的困难,以提高准确度。
判断矩阵是表示本层所有因素针对上一层某一个因素的相对重要性的比较。判断矩阵的元素 a ij a_\text{ij} aij用1-9标度方法给出。此外心理学家认为成对比较的因素不宜超过9个,即每层不要超过9个元素。
| 标度 | 含义 |
|---|---|
| 1 | 表示两个因素相比,具有同样重要性 |
| 3 | 表示两个因素相比,一个因素比另一个因素稍微重要 |
| 5 | 表示两个因素相比,一个因素比另一个因素明显重要 |
| 7 | 表示两个因素相比,一个因素比另一个因素强烈重要 |
| 9 | 表示两个因素相比,一个因素比另一个因素极端重要 |
| 2,4,6,8 | 上述两相邻判断的中值 |
| 倒数 | 因素 i \text i i与 j \text j j比较的判断 a ij a_\text{ij} aij,则因素 j \text j j与 i \text i i比较的判断 a ji = 1 a ij a_\text{ji}=\frac{1}{\Large {a_\text{ij}}} aji=aij1 |
例2 构造成对比较矩阵
构建景色、费用等诸因素对目标层“选择旅游目的地”的成对比较矩阵。
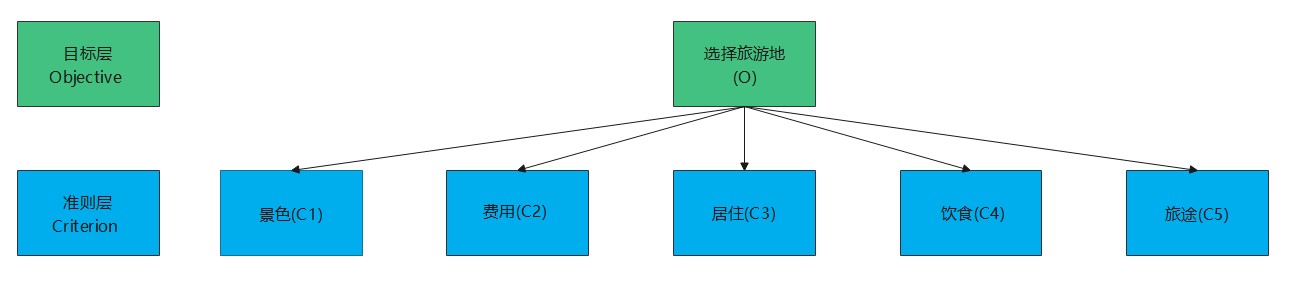 目标层-准则层 |
设各准则 C 1 , C 2 , ⋯ , C n \text C_1,\text C_2,\cdots,\text C_\text n C1,C2,⋯,Cn对于目标层 O \bf O O的两两成对比较的标度如下:
C i : C j ⟹ a ij \text C_\text i:\text C_\text j\Longrightarrow a_\text{ij} Ci:Cj⟹aij
我们把这些标度构成的矩阵称为判断矩阵(成对比较矩阵) A = ( a ij ) n × n {\bf A}=(a_\text{ij})_{\text n\times\text n} A=(aij)n×n,显然 A \bf A A矩阵是正互反矩阵:
a ij > 0 , a ij = 1 a ji a_\text{ij}>0,a_{\text {ij}}=\frac{1}{a_\text{ji}} aij>0,aij=aji1
然后通过查阅资料、阅读相关文献、询问专家和老师以及自己的琢磨,我们给出判断矩阵:
A = [ 1 1 2 4 3 3 2 1 7 5 5 1 4 1 7 1 1 2 1 3 1 3 1 5 2 1 1 1 3 1 5 3 1 1 ] {\bf A}= \begin{bmatrix} 1&\frac{1}{2}&4&3&3\\ 2&1&7&5&5\\ \frac{1}{4}&\frac{1}{7}&1&\frac{1}{2}&\frac{1}{3}\\ \frac{1}{3}&\frac{1}{5}&2&1&1\\ \frac{1}{3}&\frac{1}{5}&3&1&1\\ \end{bmatrix} A=⎣ ⎡1241313121171515147123352111353111⎦ ⎤
但是上述 A \bf A A矩阵存在不一致情况:
a 21 ( C 2 : C 1 ) = 2 , a 13 ( C 1 : C 3 ) = 4 ⇓ a 23 ( C 2 : C 3 ) = 8 a_{21}(\text C_2:\text C_1)=2,a_{13}(\text C_1:\text C_3)=4\\ \Downarrow\\ a_{23}(\text C_2:\text C_3)=8 a21(C2:C1)=2,a13(C1:C3)=4⇓a23(C2:C3)=8
我们说的一致就是线性关系,比如 C 2 \text C_2 C2的满意度或者重要性是 C 1 \text C_1 C1的满意度的2倍,而 C 1 \text C_1 C1的满意度又是 C 3 \text C_3 C3满意度的4倍,那么 C 2 \text C_2 C2的满意度就是 C 3 \text C_3 C3满意度的8倍。而所给判断矩阵 C 2 \text C_2 C2的满意度是 C 7 \text C_7 C7满意度的7倍,这就是不一致的情况。
但是这种逻辑仅仅是数学上的逻辑,在实际生活中两个稍微重要(标度为3)一定是极端重要(标度为9)吗?答案肯定是否定的。所以我们允许出现不一致的情况,但是需要有一定的界限,因为不一致程度过大时会出现逻辑上的矛盾。比如 a 12 = 2 , a 31 = 2 , a 23 = 2 a_{12}=2,a_{31}=2,a_{23}=2 a12=2,a31=2,a23=2:
a 12 = 2 , a 31 = 2 (1) a_{12}=2,a_{31}=2\tag1 a12=2,a31=2(1)
从 ( 1 ) (1) (1)式中我们可以得到 C 1 \text C_1 C1比 C 2 \text C_2 C2重要, C 3 \text C_3 C3比 C 1 \text C_1 C1重要,从而 C 3 \text C_3 C3比 C 2 \text C_2 C2重要.
a 23 = 2 (2) a_{23}=2\tag2 a23=2(2)
但是我们从 ( 2 ) (2) (2)式中却得到 C 2 \text C_2 C2比 C 3 \text C_3 C3重要的结论,这显然出现了逻辑错误,这就是由于不一致程度太大所导致的,所以我们所允许的不一致程度是有一定范围的,或者说我们需要对判断矩阵进行一致性检验。
考查完全一致的情况
设: W = w 1 , w 2 , ⋯ , w n {\bf W}=\text w_1,\text w_2,\cdots,\text w_\text n W=w1,w2,⋯,wn,令 a ij = w i w j a_\text{ij}=\dfrac{\text w_\text i}{\text w_\text j} aij=wjwi,一致矩阵 A \bf A A如下:
A = [ w 1 w 1 w 1 w 2 ⋯ w 1 w n w 2 w 1 w 2 w 2 ⋯ w 2 w n ⋮ ⋮ ⋱ ⋮ w n w 1 w n w 2 ⋯ w n w n ] {\bf A}= \begin{bmatrix} \dfrac{\text w_1}{\text w_1}&\dfrac{\text w_1}{\text w_2}&\cdots&\dfrac{\text w_1}{\text w_\text n}\\ \dfrac{\text w_2}{\text w_1}&\dfrac{\text w_2}{\text w_2}&\cdots&\dfrac{\text w_2}{\text w_\text n}\\ \vdots&\vdots&\ddots&\vdots\\ \dfrac{\text w_\text n}{\text w_1}&\dfrac{\text w_\text n}{\text w_2}&\cdots&\dfrac{\text w_\text n}{\text w_\text n}\\ \end{bmatrix} A=⎣ ⎡w1w1w1w2⋮w1wnw2w1w2w2⋮w2wn⋯⋯⋱⋯wnw1wnw2⋮wnwn⎦ ⎤
一致矩阵 A \bf A A的性质:
- A \bf A A的秩为1, A \bf A A的唯一非零特征根为 n \text n n。
- 特征根 n \text n n对应的特征向量归一化后可作为权向量。
层次单排序及其一致性检验
对应于判断矩阵最大特征根 λ max \lambda_{\max} λmax的特征向量,经归一化(使向量中各种元素之和等于1)后记为 W \bf W W。 W \bf W W的元素为同一层次因素对于上一层次某个因素相对重要性的排序权值,这一过程成为层次单排序。能否确认(使用)层次单排序,需要进行一致性检验,所谓一致性检验是指对判断矩阵 A \bf A A确定不一致的允许范围。
一致性检验
在检验的过程中,我们需要用到两个定理:
- n \text n n阶一致阵的唯一非零特征根为 n \text n n。
- n \text n n阶正互反矩阵 A \bf A A的最大特征根 λ ≥ n \lambda\ge\text n λ≥n,当且仅当 λ = n \lambda=\text n λ=n时, A \bf A A为一致矩阵。
λ \lambda λ比 n \text n n大的越多, A \bf A A的不一致性越严重。用最大特征值对应的特征向量作为被比较因素对上层某因素影响程度的权向量,其不一致程度越大,引起的判断误差越大。因而可以用 λ − n \lambda-\text n λ−n数值的大小来衡量 A \bf A A的不一致程度。
定义一致性指标:
CI = λ − n n − 1 \text{CI}=\frac{\lambda-\text n}{\text n-1} CI=n−1λ−n
- CI = 0 \text{CI}=0 CI=0,有完全的一致性
- CI \text{CI} CI接近与0,有满意的一致性
- CI \text{CI} CI越大,不一致越严重
为衡量 CI \text{CI} CI的大小,引入随机一致性指标 RI \text{RI} RI。方法为随机构造500个成对比较矩阵 A 1 , A 2 , ⋯ , A 500 \bf A_1,A_2,\cdots,A_{500} A1,A2,⋯,A500,则可得一致性指标 C I 1 , C I 2 , ⋯ , C I 500 \rm CI_1,CI_2,\cdots,CI_{500} CI1,CI2,⋯,CI500。
R I = C I 1 + C I 2 + ⋯ + C I 500 500 = λ 1 + λ 1 + ⋯ + λ 500 500 − n n − 1 \rm RI=\frac{CI_1+CI_2+\cdots+CI_{500}}{500}=\frac{\dfrac{\lambda_1+\lambda_1+\cdots+\lambda_{500}}{500}-\text n}{\text n-1} RI=500CI1+CI2+⋯+CI500=n−1500λ1+λ1+⋯+λ500−n
对于不同的 n \text n n结果如下表:
| n \text n n | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| RI \text{RI} RI | 0 | 0 | 0.58 | 0.90 | 1.12 | 1.24 | 1.32 | 1.41 | 1.45 | 1.49 | 1.51 |
定义一致性比率:
C R = C I R I \rm CR=\frac{CI}{RI} CR=RICI
一般,当一致性比率 C R < 0.1 \rm CR<0.1 CR<0.1时,认为 A \bf A A的不一致程度在允许范围之内,有满意的一致性,通过一致性检验。可用其归一化特征向量作为权向量,否则要重新构造成对比较矩阵 A \bf A A,对 a i j a_{\rm ij} aij加以调整。
一致性检验:利用一致性指标和一致性比率及一致性指标的数值表,对 A \bf A A进行检验的过程。
例3 对例2的成对比较矩阵 A \bf A A进行一致性检验
准则层对目标层的成对比较矩阵:
A = [ 1 1 2 4 3 3 2 1 7 5 5 1 4 1 7 1 1 2 1 3 1 3 1 5 2 1 1 1 3 1 5 3 1 1 ] {\bf A}= \begin{bmatrix} 1&\frac{1}{2}&4&3&3\\ 2&1&7&5&5\\ \frac{1}{4}&\frac{1}{7}&1&\frac{1}{2}&\frac{1}{3}\\ \frac{1}{3}&\frac{1}{5}&2&1&1\\ \frac{1}{3}&\frac{1}{5}&3&1&1\\ \end{bmatrix} A=⎣ ⎡1241313121171515147123352111353111⎦ ⎤
最大特征根 λ = 5.073 \lambda=5.073 λ=5.073,权向量(特征向量) w = ( 0.263 , 0.475 , 0.055 , 0.090 , 0.110 ) T {\bf w}=(0.263,0.475,0.055,0.090,0.110)^\text T w=(0.263,0.475,0.055,0.090,0.110)T。
一致性指标 CI = 5.073 − 5 5 − 1 = 0.018 \text{CI}=\dfrac{5.073-5}{5-1}=0.018 CI=5−15.073−5=0.018,随机一致性指标 RI = 1.12 \text{RI}=1.12 RI=1.12。
一致性比率 CR = 0.018 1.12 = 0.016 < 0.1 \text{CR}=\dfrac{0.018}{1.12}=0.016<0.1 CR=1.120.018=0.016<0.1。通过一致性检验。
正互反阵最大特征根和特征向量的简化计算
简化计算的思路:一致矩阵的任一一列向量都是特征向量,一致性尚好的正互反矩阵的列向量都应近似特征向量,可取其某种意义下的平均。以下面的 A \bf A A矩阵为例求近似特征向量。
A = [ 1 2 6 1 2 1 4 1 6 1 4 1 ] {\bf A}= \begin{bmatrix} 1&2&6\\ \dfrac{1}{2}&1&4\\ \dfrac{1}{6}&\dfrac{1}{4}&1 \end{bmatrix} A=⎣ ⎡121612141641⎦ ⎤
- 列向量归一化:
A = [ 1 2 6 1 2 1 4 1 6 1 4 1 ] ⟹ [ 0.6 0.615 0.545 0.3 0.308 0.364 0.1 0.077 0.091 ] {\bf A}= \begin{bmatrix} 1&2&6\\ \dfrac{1}{2}&1&4\\ \dfrac{1}{6}&\dfrac{1}{4}&1 \end{bmatrix} \Longrightarrow \begin{bmatrix} 0.6&0.615&0.545\\ 0.3&0.308&0.364\\ 0.1&0.077&0.091 \end{bmatrix} A=⎣ ⎡121612141641⎦ ⎤⟹⎣ ⎡0.60.30.10.6150.3080.0770.5450.3640.091⎦ ⎤
- 按行求和并归一化得到近似权向量:
w = [ 0.6 0.615 0.545 0.3 0.308 0.364 0.1 0.077 0.091 ] ⟹ [ 0.587 0.324 0.089 ] {\bf w}= \begin{bmatrix} 0.6&0.615&0.545\\ 0.3&0.308&0.364\\ 0.1&0.077&0.091 \end{bmatrix} \Longrightarrow \begin{bmatrix} 0.587\\ 0.324\\ 0.089 \end{bmatrix} w=⎣ ⎡0.60.30.10.6150.3080.0770.5450.3640.091⎦ ⎤⟹⎣ ⎡0.5870.3240.089⎦ ⎤
- 计算近似的特征值:
λ = 1 3 ( 1.796 0.587 + 0.974 0.324 + 0.268 0.089 ) = 3.009 \lambda=\frac{1}{3}(\frac{1.796}{0.587}+\frac{0.974}{0.324}+\frac{0.268}{0.089})=3.009 λ=31(0.5871.796+0.3240.974+0.0890.268)=3.009
现在列出精确结果:
w = 1. / w T A w × 1 3 = [ 0.588 , 0.322 , 0.090 ] T , λ = 3.010 {\bf w}=1./{\bf w}^\text T{\bf A}{\bf w}\times\frac{1}{3}=[0.588,0.322,0.090]^\text T,\lambda=3.010 w=1./wTAw×31=[0.588,0.322,0.090]T,λ=3.010
我们可以看到近似结果和精确结果相差不大,可以采用。
一些细节:
计算近似值的过程是这样的,先对列向量进行归一化,然后按行求和再进行归一化得到近似的权重向量,在这里我产生了一个疑问,可不可以先对行求和然后再进行归一化呢,这样就减少了步骤。所以我对我的猜想用计算机进行了测试,结果就是这两个流程得到的结果是不同的,而且直接求和再进行归一化这个步骤得到的近似权重向量误差更大一点,结果如下:
w = [ 0.5654 , 0.3455 , 0.0890 ] T , λ = 3.0393 {\bf w}=[0.5654,0.3455,0.0890]^\text T,\lambda=3.0393 w=[0.5654,0.3455,0.0890]T,λ=3.0393
层次总排序及其一致性检验
层次总排序
计算某一层次所有因素对于最高层(总目标)相对重要性的权值,称为层次总排序。这一过程是从最高层到最低层次依次进行的。
 层次结构图 |
A \bf A A层 m \text m m个因素 A 1 , A 2 , ⋯ , A m \bf A_1,A_2,\cdots,A_m A1,A2,⋯,Am,对总目标 Z \text Z Z的排序为:
w ( 2 ) = [ a 1 , a 2 , ⋯ , a m ] {\bf w}^{(2)}=[a_1,a_2,\cdots,a_\text m] w(2)=[a1,a2,⋯,am]
B \bf B B层 n \text n n个因素对上层 A \bf A A中因素为 A j {\bf A}_\text j Aj的层次单排序为:
w j ( 3 ) = [ b 1 j , b 2 j , ⋯ , b nj ] , j = 1 , 2 , ⋯ , m {\bf w}^{(3)}_\text j=[\text b_{1\text j},\text b_{2\text j},\cdots,\text b_{\text n\text j}],\quad \text j=1,2,\cdots,\text m wj(3)=[b1j,b2j,⋯,bnj],j=1,2,⋯,m
B \bf B B层次总排序(对于目标层)为:
B 1 : a 1 b 11 + a 2 b 12 + ⋯ + a m b 1 m B 2 : a 1 b 21 + a 2 b 22 + ⋯ + a m b 2 m ⋮ B n : a 1 b n 1 + a 2 b n 2 + ⋯ + a m b nm {\bf B}_1:a_1\text b_{11}+a_2\text b_{12}+\cdots+a_\text m\text b_{1\text m}\\ {\bf B}_2:a_1\text b_{21}+a_2\text b_{22}+\cdots+a_\text m\text b_{2\text m}\\ \vdots\\ {\bf B}_\text n:a_1\text b_{\text n1}+a_2\text b_{\text n2}+\cdots+a_\text m\text b_{\text n\text m}\\ B1:a1b11+a2b12+⋯+amb1mB2:a1b21+a2b22+⋯+amb2m⋮Bn:a1bn1+a2bn2+⋯+ambnm
即 B \bf B B层第 i \text i i个因素对总目标的权值为:
w i = ∑ j = 1 m a j b i j {\bf w}_\text i=\sum_{\rm j=1}^\text ma_\text j\rm b_{ij} wi=j=1∑majbij
| a 1 a_1 a1 | a 2 a_2 a2 | ⋯ \cdots ⋯ | a m a_\text m am | B \bf B B层的层次总排序 | |
|---|---|---|---|---|---|
| B 1 {\bf B}_1 B1 | b 11 \rm b_{11} b11 | b 12 \rm b_{12} b12 | ⋯ \cdots ⋯ | b 1 m \rm b_{1\rm m} b1m | b 1 = ∑ j = 1 m a j b 1 j \rm b_1=\sum\limits_{\rm j=1}^\text ma_\text j\rm b_{1j} b1=j=1∑majb1j |
| B 2 {\bf B}_2 B2 | b 21 \rm b_{21} b21 | b 22 \rm b_{22} b22 | ⋯ \cdots ⋯ | b 2 m \rm b_{2\rm m} b2m | b 2 = ∑ j = 1 m a j b 2 j \rm b_2=\sum\limits_{\rm j=1}^\text ma_\text j\rm b_{2j} b2=j=1∑majb2j |
| ⋮ \vdots ⋮ | ⋮ \vdots ⋮ | ⋮ \vdots ⋮ | ⋱ \ddots ⋱ | ⋮ \vdots ⋮ | ⋮ \vdots ⋮ |
| B n {\bf B}_\text n Bn | b n 1 \rm b_{\rm n1} bn1 | b n 2 \rm b_{\rm n2} bn2 | ⋯ \cdots ⋯ | b n m \rm b_{\rm nm} bnm | b n = ∑ j = 1 m a j b n j \rm b_n=\sum\limits_{\rm j=1}^\text ma_\text j\rm b_{nj} bn=j=1∑majbnj |
层次总排序的一致性检验
设 B \bf B B层 B 1 , B 2 , , ⋯ , B n {\bf B}_1,{\bf B}_2,,\cdots,{\bf B}_{\rm n} B1,B2,,⋯,Bn对上层 A \bf A A中因素 A j {\bf A}_{\rm j} Aj的层次单排序一致性指标为 C I j \rm CI_j CIj,随机一致性指标 R I j \rm RI_j RIj,则层次总排序的一致性比率为:
C R = a 1 C I 1 + a 2 C I 2 + ⋯ + a m C I m a 1 R I 1 + a 2 R I 2 + ⋯ + a m R I m \rm CR=\frac{a_1CI_1+a_2CI_2+\cdots+a_mCI_m}{a_1RI_1+a_2RI_2+\cdots+a_mRI_m} CR=a1RI1+a2RI2+⋯+amRIma1CI1+a2CI2+⋯+amCIm
当 C R < 0.1 \rm CR<0.1 CR<0.1时,认为层次总排序通过一致性检验。层次总排序具有满意的一致性,否则需要重新调整那些一致性比率高的判断矩阵的元素取值。
到此,根据最下层(决策层)的层次总排序作出最后决策。
例4 选择旅游地的层次总排序
记第2层(准则)对第1层(目标)的权向量为:
w ( 2 ) = [ 0.263 , 0.475 , 0.055 , 0.090 , 0.110 ] T {\bf w}^{(2)}=[0.263,0.475,0.055,0.090,0.110]^{\rm T} w(2)=[0.263,0.475,0.055,0.090,0.110]T
同样求第3层(方案)对第2层每一元素(准则)的权向量:
- 方案层对 C 1 \rm C_1 C1(景色)的成对比较矩阵:
B 1 = [ 1 2 5 1 2 1 2 1 5 1 2 1 ] {\bf B}_1= \begin{bmatrix} 1&2&5\\ \dfrac{1}{2}&1&2\\ \dfrac{1}{5}&\dfrac{1}{2}&1 \end{bmatrix} B1=⎣ ⎡121512121521⎦ ⎤
- 方案层对 C 2 \rm C_2 C2(费用)的成对比较矩阵:
B 2 = [ 1 1 3 1 8 3 1 1 3 8 3 1 ] {\bf B}_2= \begin{bmatrix} 1&\dfrac{1}{3}&\dfrac{1}{8}\\ 3&1&\dfrac{1}{3}\\ 8&3&1 \end{bmatrix} B2=⎣ ⎡138311381311⎦ ⎤
- 方案层对 C n \rm C_n Cn的成对比较矩阵为 B n {\bf B}_{\rm n} Bn。
最大特征根:
λ 1 = 3.005 , λ 2 = 3.002 , ⋯ , λ 5 = 3.0 \lambda_1=3.005,\lambda_2=3.002,\cdots,\lambda_5=3.0 λ1=3.005,λ2=3.002,⋯,λ5=3.0
对应的特征向量:
w 1 ( 3 ) = [ 0.595 , 0.277 , 0.129 ] T w 2 ( 3 ) = [ 0.082 , 0.236 , 0.682 ] T ⋮ {\bf w}^{(3)}_1=[0.595,0.277,0.129]^{\rm T}\\ {\bf w}^{(3)}_2=[0.082,0.236,0.682]^{\rm T}\\ \vdots w1(3)=[0.595,0.277,0.129]Tw2(3)=[0.082,0.236,0.682]T⋮
组合权向量
| w ( 2 ) {\bf w}^{(2)} w(2) | 0.263 | 0.475 | 0.055 | 0.090 | 0.110 |
|---|---|---|---|---|---|
| 0.595 | 0.082 | 0.429 | 0.633 | 0.166 | |
| w k ( 3 ) {\bf w}^{(3)}_{\rm k} wk(3) | 0.277 | 0.236 | 0.429 | 0.193 | 0.166 |
| 0.129 | 0.682 | 0.142 | 0.175 | 0.668 | |
| λ k \lambda_{\rm k} λk | 3.005 | 3.002 | 3 | 3.009 | 3 |
| C I k \rm CI_k CIk | 0.003 | 0.001 | 0 | 0.005 | 0 |
R I = 0.58 ( n = 3 ) \rm RI=0.58(n=3) RI=0.58(n=3), C I k \rm CI_k CIk均可通过一致性检验。
方案P1对目标的组合权重为 0.595 × 0.263 + ⋯ = 0.300 0.595\times0.263+\cdots=0.300 0.595×0.263+⋯=0.300。
方案层对目标层的组合权向量为 [ 0.300 , 0.246 , 0.456 ] T [0.300,0.246,0.456]^{\rm T} [0.300,0.246,0.456]T。
层次分析法的基本步骤归纳如下
-
建立层次结构模型
该结构图包括目标层,准则层,方案层。
-
构建成对比较矩阵
从第二层开始用成对比较矩阵和1-9尺度。
-
计算单排序权向量并做一致性检验
对每个成对比较矩阵计算最大特征值及其对应的特征向量,利用一致性指标、随机一致性指标和一致性比率做一致性检验。若检验通过,特征向量(归一化后)即为权向量;若不通过,需要重新构造成对比较矩阵。
-
计算总排序权向量并做一致性检验
- 计算最下层对最上层总排序的权向量。
- 利用一致性比率进行检验,若通过,则可按照总排序权向量表示的结果进行决策,否则需要重新考虑模型或重新构造那些一致性比率 C R \rm CR CR较大的成对比较矩阵。
例5 旅游问题
- 建立层次结构模型
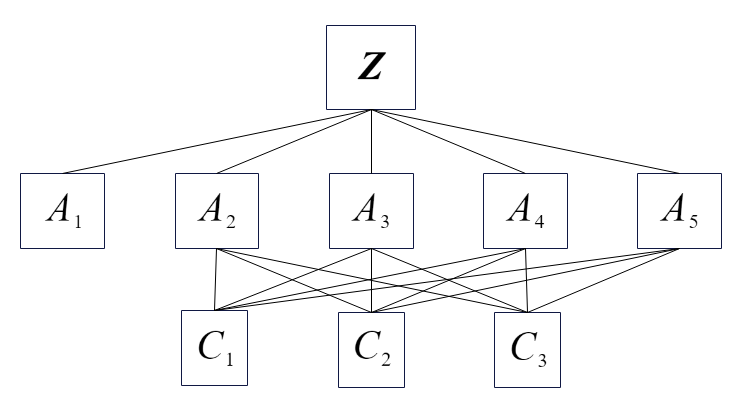 层次结构图 |
A 1 , A 2 , A 3 , A 4 , A 5 {\bf A}_1,{\bf A}_2,{\bf A}_3,{\bf A}_4,{\bf A}_5 A1,A2,A3,A4,A5分别表示景色、费用、居住、饮食、旅途。
C 1 , C 2 , C 3 {\bf C}_1,{\bf C}_2,{\bf C}_3 C1,C2,C3分别表示苏杭、北戴河、桂林。
- 构造成对比较矩阵
A = [ 1 1 2 4 3 3 2 1 7 5 5 1 4 1 7 1 1 2 1 3 1 3 1 5 2 1 1 1 3 1 5 3 1 1 ] {\bf A}= \begin{bmatrix} 1&\frac{1}{2}&4&3&3\\ 2&1&7&5&5\\ \frac{1}{4}&\frac{1}{7}&1&\frac{1}{2}&\frac{1}{3}\\ \frac{1}{3}&\frac{1}{5}&2&1&1\\ \frac{1}{3}&\frac{1}{5}&3&1&1\\ \end{bmatrix} A=⎣ ⎡1241313121171515147123352111353111⎦ ⎤
B 1 = [ 1 2 5 1 2 1 2 1 5 1 2 1 ] B 2 = [ 1 1 3 1 8 3 1 1 3 8 3 1 ] B 3 = [ 1 1 1 4 1 1 1 4 4 4 1 ] B 4 = [ 1 3 4 1 3 1 1 1 4 1 1 ] B 5 = [ 1 1 1 4 1 1 1 4 4 4 1 ] {\bf B}_1= \begin{bmatrix} 1&2&5\\ \dfrac{1}{2}&1&2\\ \dfrac{1}{5}&\dfrac{1}{2}&1\\ \end{bmatrix} \quad {\bf B}_2= \begin{bmatrix} 1&\dfrac{1}{3}&\dfrac{1}{8}\\ 3&1&\dfrac{1}{3}\\ 8&3&1\\ \end{bmatrix} \quad {\bf B}_3= \begin{bmatrix} 1&1&\dfrac{1}{4}\\ 1&1&\dfrac{1}{4}\\ 4&4&1\\ \end{bmatrix}\\ \\ {\bf B}_4= \begin{bmatrix} 1&3&4\\ \dfrac{1}{3}&1&1\\ \dfrac{1}{4}&1&1\\ \end{bmatrix} \quad {\bf B}_5= \begin{bmatrix} 1&1&\dfrac{1}{4}\\ 1&1&\dfrac{1}{4}\\ 4&4&1\\ \end{bmatrix} B1=⎣ ⎡121512121521⎦ ⎤B2=⎣ ⎡138311381311⎦ ⎤B3=⎣ ⎡11411441411⎦ ⎤B4=⎣ ⎡13141311411⎦ ⎤B5=⎣ ⎡11411441411⎦ ⎤
- 计算层次单排序的权向量和一致性检验
- 对矩阵 A \bf A A计算层次单排序和一致性检验
成对比较矩阵 A \bf A A的最大特征值 λ = 5.037 \lambda =5.037 λ=5.037,该特征值对应的归一化特征向量:
w = [ 0.263 , 0.475 , 0.055 , 0.099 , 0.110 ] T {\bf w}=[0.263,0.475,0.055,0.099,0.110]^\text T w=[0.263,0.475,0.055,0.099,0.110]T
则一致性指标和随机一致性指标如下:
C I = 5.073 − 5 5 − 1 ≈ 0.018 R I = 1.12 \rm CI=\frac{5.073-5}{5-1}\approx0.018\quad RI=1.12 CI=5−15.073−5≈0.018RI=1.12
故一致性比率如下:
C R = 0.018 1.12 = 0.016 < 0.1 \rm CR=\frac{0.018}{1.12}=0.016<0.1 CR=1.120.018=0.016<0.1
表明 A \bf A A通过了一致性验证。
- 对成对比较矩阵 B 1 , B 2 , B 3 , B 4 , B 5 {\bf B}_1,{\bf B}_2,{\bf B}_3,{\bf B}_4,{\bf B}_5 B1,B2,B3,B4,B5计算层次单排序和一致性检验,结果如下:
| k \text k k | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| w k 1 {\bf w}_{\rm k1} wk1 | 0.595 | 0.082 | 0.429 | 0.633 | 0.166 |
| w k 2 {\bf w}_{\rm k2} wk2 | 0.277 | 0.236 | 0.429 | 0.193 | 0.166 |
| w k 3 {\bf w}_{\rm k3} wk3 | 0.129 | 0.682 | 0.142 | 0.175 | 0.668 |
| λ k \lambda_{\rm k} λk | 3.005 | 3.002 | 3 | 3.009 | 3 |
| C I k \rm CI_k CIk | 0.003 | 0.001 | 0 | 0.005 | 0 |
| R I k \rm RI_k RIk | 0.58 | 0.58 | 0.58 | 0.58 | 0.58 |
计算 C R k \rm CR_k CRk可知 B 1 , B 2 , B 3 , B 4 , B 5 {\bf B}_1,{\bf B}_2,{\bf B}_3,{\bf B}_4,{\bf B}_5 B1,B2,B3,B4,B5通过一致性检验。
- 计算层次总排序权值和一致性检验
C 1 {\bf C}_1 C1对总目标的权值为:
0.595 × 0.263 + 0.082 × 0.475 + 0.429 × 0.055 + 0.633 × 0.099 + 0.166 × 0.110 = 0.3 0.595\times0.263+0.082\times0.475+0.429\times0.055+0.633\times0.099+0.166\times0.110=0.3 0.595×0.263+0.082×0.475+0.429×0.055+0.633×0.099+0.166×0.110=0.3
同理得, C 2 , C 3 {\bf C}_2,{\bf C}_3 C2,C3对总目标的权向量为:0.246,0.456。
决策层对目标层的权向量为:
w = [ 0.3 , 0.246 , 0.456 ] T {\bf w}=[0.3,0.246,0.456]^{\rm T} w=[0.3,0.246,0.456]T
层次总排序一致性检验如下:
C R = 0.263 × 0.003 + 0.475 × 0.001 + 0.055 × 0 + 0.099 × 0.005 + 0.110 × 0 0.58 = 0.015 < 0.1 \rm CR=\frac{0.263\times0.003+0.475\times0.001+0.055\times0+0.099\times0.005+0.110\times0}{0.58}=0.015<0.1 CR=0.580.263×0.003+0.475×0.001+0.055×0+0.099×0.005+0.110×0=0.015<0.1
故层次总排序通过一致性检验。 w = [ 0.3 , 0.246 , 0.456 ] T {\bf w}=[0.3,0.246,0.456]^{\rm T} w=[0.3,0.246,0.456]T可作为最后的决策依据。
即各方案的权重排序为 C 3 > C 1 > C 2 {\bf C}_3>{\bf C}_1>{\bf C}_2 C3>C1>C2,又 C 1 , C 2 , C 3 {\bf C}_1,{\bf C}_2,{\bf C}_3 C1,C2,C3分别表示苏杭、北戴河、桂林,所以最后的决策应为去桂林。
建模实例
问题提出
设某学校数学建模教练组根据实际需要,拟从报名参赛的20名队员中选出15名优秀队员代表学校参赛。表1给出了20名队员的基本条件的量化情况。
请根据这些条件对20名队员进行综合评价,从中选出15名综合素质较高的优秀队员。
| 学科知识竞赛成绩 r i ( 1 ) \rm r_i^{(1)} ri(1) | 思维敏捷度 r i ( 2 ) \rm r_i^{(2)} ri(2) | 知识面宽广度 r i ( 3 ) \rm r_i^{(3)} ri(3) | 写作能力 r i ( 4 ) \rm r_i^{(4)} ri(4) | 计算机应用能力 r i ( 5 ) \rm r_i^{(5)} ri(5) | 团结协作能力 r i ( 6 ) \rm r_i^{(6)} ri(6) | |
|---|---|---|---|---|---|---|
| S 1 \rm S_1 S1 | 86 | 9.0 | 8.2 | 8.0 | 7.9 | 9.5 |
| S 2 \rm S_2 S2 | 82 | 8.8 | 8.1 | 6.5 | 7.7 | 9.1 |
| S 3 \rm S_3 S3 | 80 | 8.6 | 8.5 | 8.5 | 9.2 | 9.6 |
| S 4 \rm S_4 S4 | 85 | 8.9 | 8.3 | 9.6 | 9.7 | 9.7 |
| S 5 \rm S_5 S5 | 88 | 8.4 | 8.5 | 7.7 | 8.6 | 9.2 |
| S 6 \rm S_6 S6 | 92 | 9.2 | 8.2 | 7.9 | 9.0 | 9.0 |
| S 7 \rm S_7 S7 | 92 | 9.6 | 9.0 | 7.2 | 9.1 | 9.2 |
| S 8 \rm S_8 S8 | 92 | 8.0 | 9.8 | 6.2 | 8.7 | 9.7 |
| S 9 \rm S_9 S9 | 70 | 8.2 | 8.4 | 6.5 | 9.6 | 9.3 |
| S 10 \rm S_{10} S10 | 77 | 8.1 | 8.6 | 6.9 | 8.5 | 9.4 |
| S 11 \rm S_{11} S11 | 83 | 8.2 | 8.0 | 7.8 | 9.0 | 9.2 |
| S 12 \rm S_{12} S12 | 90 | 9.1 | 8.1 | 9.9 | 8.7 | 9.5 |
| S 13 \rm S_{13} S13 | 96 | 9.6 | 8.3 | 8.1 | 9.0 | 9.7 |
| S 14 \rm S_{14} S14 | 95 | 8.3 | 8.2 | 8.1 | 8.8 | 9.3 |
| S 15 \rm S_{15} S15 | 86 | 8.2 | 8.8 | 8.4 | 8.6 | 9.0 |
| S 16 \rm S_{16} S16 | 91 | 8.0 | 8.6 | 8.8 | 8.4 | 9.4 |
| S 17 \rm S_{17} S17 | 93 | 8.7 | 9.4 | 9.2 | 8.7 | 9.5 |
| S 18 \rm S_{18} S18 | 84 | 8.4 | 9.2 | 9.1 | 7.8 | 9.1 |
| S 19 \rm S_{19} S19 | 87 | 8.3 | 9.5 | 7.9 | 9.0 | 9.6 |
| S 20 \rm S_{20} S20 | 78 | 8.1 | 9.6 | 7.6 | 9.0 | 9.2 |
问题的分析与假设
这是一个半定性与半定量、多因素的综合选优排序问题。鉴于数学建模竞赛不仅要考查学生的学科知识、还要考查学生的写作能力、计算机应用能力、团结协作能力等多方面的因素,要从20名队员中选拔出优秀参赛队员,就要对表1中所列的6个因素进行比较分析,综合排序选优。
模型假设:
- 题目中所确定的考评条件是合理的,能够反映出参选队员的建模能力
- 各参选队员的量化得分是按统一的量化标准得出的
- 对参选队员的量化打分是公平的,所有参选队员对打分结果无异议
- 选拔队员所考虑的6个因素在选拔优秀队员中所起的作用依次为学科知识竞赛、思维敏捷度、知识面宽广度、写作能力、计算机应用能力、团结协作能力,并且相邻两个因素的影响程度之差基本相同
模型的建立与求解
建立层次结构图
建立如下图所示的层次结构图:
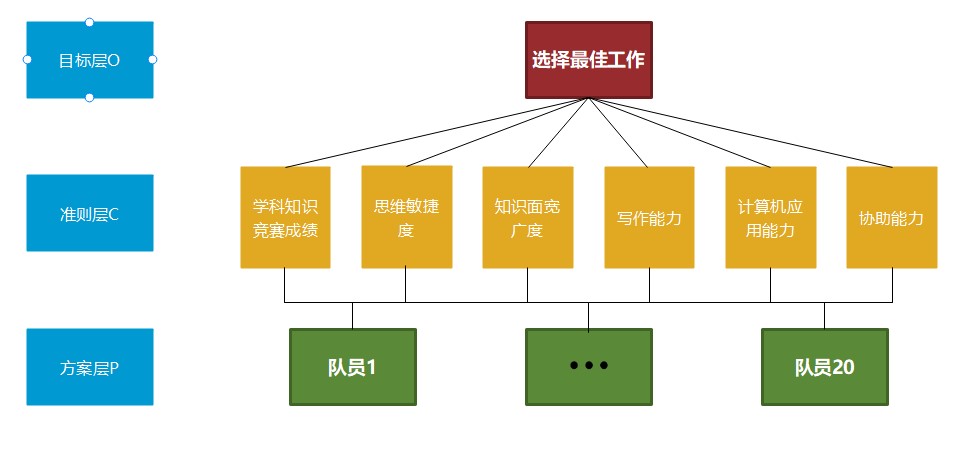 层次结构图 |
- 第一层为目标层:选拔优秀参赛队员
- 第二次为准则层:选拔优秀队员时所考虑的6个因素,依次为学科知识竞赛成绩,思维敏捷度、写作能力、计算机应用能力、协作能力
- 第三层为方案层:参选的20名队员
确定准则层对目标层的权重向量
根据假设,构造准则层C对目标层O的两两比较矩阵:
A = [ 1 2 3 4 5 6 1 2 1 2 3 4 5 1 3 1 2 1 2 3 4 1 4 1 3 1 2 1 2 3 1 5 1 4 1 3 1 2 1 2 1 6 1 5 1 4 1 4 1 2 1 ] {\bf A}= \begin{bmatrix} 1&2&3&4&5&6\\ \dfrac{1}{2}&1&2&3&4&5\\ \dfrac{1}{3}&\dfrac{1}{2}&1&2&3&4\\ \dfrac{1}{4}&\dfrac{1}{3}&\dfrac{1}{2}&1&2&3\\ \dfrac{1}{5}&\dfrac{1}{4}&\dfrac{1}{3}&\dfrac{1}{2}&1&2\\ \dfrac{1}{6}&\dfrac{1}{5}&\dfrac{1}{4}&\dfrac{1}{4}&\dfrac{1}{2}&1\\ \end{bmatrix} A=⎣ ⎡121314151612121314151321213141432121415432121654321⎦ ⎤
这是一个6阶的正反矩阵,用和法计算A的最大特征根为 λ max = 6..1232 \lambda_{\max}=6..1232 λmax=6..1232,相应归一化特征向量为:
w ( 2 ) = [ 0.3794 , 0.2488 , 0.1604 , 0.1024 , 0.0655 , 0.0434 ] T {\bf w}^{(2)}=[0.3794,0.2488,0.1604,0.1024,0.0655,0.0434]^\text T w(2)=[0.3794,0.2488,0.1604,0.1024,0.0655,0.0434]T
一致性指标: C I ( 2 ) = 0.0246 \rm CI^{(2)}=0.0246 CI(2)=0.0246,随机一致性指标 R I ( 2 ) = 1.24 \rm RI^{(2)}=1.24 RI(2)=1.24,一致性比率 C R ( 2 ) = 0.0198 < 0.1 \rm CR^{(2)}=0.0198<0.1 CR(2)=0.0198<0.1通过一致性检验, w ( 2 ) {\bf w}^{(2)} w(2)为准则层对目标层的权重向量(在一致性检验之前,我们称 w ( 2 ) {\bf w}^{(2)} w(2)为归一化特征向量,只有一致性检验之后,我们才能称 w ( 2 ) {\bf w}^{(2)} w(2)为权重向量)。
确定方案层对准则层的权重向量
根据表1和模型假设,构造方案层P中20个队员对准则层C中各因素 C k \rm C_k Ck的两两比较矩阵:
B = ( b i j ( k ) ) 20 × 20 b i j ( k ) = r i ( k ) r j ( k ) i , j = 1 , 2 , ⋯ , 20 , k = 1 , 2 , ⋯ , 6 {\bf B}=(\rm b_{ij}^{(k)})_{20\times20}\quad b_{ij}^{(k)}=\frac{r_i^{(k)}}{r_j^{(k)}}\quad i,j=1,2,\cdots,20,k=1,2,\cdots,6 B=(bij(k))20×20bij(k)=rj(k)ri(k)i,j=1,2,⋯,20,k=1,2,⋯,6
显然,所有 B k {\bf B}_{\rm k} Bk均为一致阵,于是 B k {\bf B}_{\rm k} Bk的最大特征根为:
λ max ( k ) = 20 , C I k = 0 , C R k = 0 \lambda_{\max}^{(\rm k)}=20,\rm CI_k=0,CR_k=0 λmax(k)=20,CIk=0,CRk=0
B k {\bf B}_{\rm k} Bk的任一列向量都是 λ max ( k ) \lambda_{\max}^{(\rm k)} λmax(k)的特征向量,将其归一化得到方案层P对 C k \rm C_k Ck的权重向量 w k ( 3 ) {\bf w}^{(3)}_{\rm k} wk(3)。于是方案层对准则层的权重向量矩阵为:
W ( 3 ) = [ w 1 ( 3 ) , w 2 ( 3 ) , ⋯ , w 6 ( 3 ) , ] 20 × 6 {\bf W}^{(3)}=[{\bf w}_1^{(3)},{\bf w}_2^{(3)},\cdots,{\bf w}_6^{(3)},]_{20\times6} W(3)=[w1(3),w2(3),⋯,w6(3),]20×6
一致性比率为 C R k = 0 ( k = 1 , 2 , ⋯ , 6 ) \rm CR_k=0(k=1,2,\cdots,6) CRk=0(k=1,2,⋯,6)通过一致性检验。
确定方案层P对目标层O的组合权重向量
方案层对目标层的组合权重向量为:
w ( 3 ) = W ( 3 ) w ( 2 ) = [ 0.0498 , 0.0474 , 0.0490 , 0.0513 , 0.0497 , 0.0517 , 0.0526 , 0.0504 , 0.0450 , 0.0464 , 0.0480 , 0.0523 , 0.0535 , 0.0511 , 0.0496 , 0.0505 , 0.0531 , 0.0500 , 0.0506 , 0.0481 , ] T {\bf w}^{(3)}={\bf W}^{(3)}{\bf w}^{(2)}=[ \begin{aligned} 0.0498,0.0474,0.0490,0.0513,\\ 0.0497,0.0517,0.0526,0.0504,\\ 0.0450,0.0464,0.0480,0.0523,\\ 0.0535,0.0511,0.0496,0.0505,\\ 0.0531,0.0500,0.0506,0.0481, \end{aligned} ]^{\rm T} w(3)=W(3)w(2)=[0.0498,0.0474,0.0490,0.0513,0.0497,0.0517,0.0526,0.0504,0.0450,0.0464,0.0480,0.0523,0.0535,0.0511,0.0496,0.0505,0.0531,0.0500,0.0506,0.0481,]T
组合一致性指标 C I ( 3 ) = 0 \rm CI^{(3)}=0 CI(3)=0,组合一致性比率为:
C R ( 3 ) = C R ( 2 ) + C I ( 3 ) R I ( 3 ) = 0.0198 < 0.1 \rm CR^{(3)}=CR^{(2)}+\frac{CI^{(3)}}{RI^{(3)}}=0.0198<0.1 CR(3)=CR(2)+RI(3)CI(3)=0.0198<0.1
通过一致性检验,组合权重 w ( 3 ) {\bf w}^{(3)} w(3)可作为决策依据。
将权重向量 w ( 3 ) {\bf w}^{(3)} w(3)的20个分量分别作为20名队员的综合实力,从大到小依次为:
S 13 , S 17 , S 7 , S 12 , S 6 , S 4 , S 14 , S 19 , S 16 , S 8 , S 18 , S 1 , S 5 , S 15 , S 3 , S 20 , S 11 , S 2 , S 10 , S 9 {\bf S}_{13},{\bf S}_{17},{\bf S}_{7},{\bf S}_{12},{\bf S}_{6},{\bf S}_{4},{\bf S}_{14},{\bf S}_{19},{\bf S}_{16},{\bf S}_{8},{\bf S}_{18},{\bf S}_{1},{\bf S}_{5},{\bf S}_{15},{\bf S}_{3},{\bf S}_{20},{\bf S}_{11},{\bf S}_{2},{\bf S}_{10},{\bf S}_{9} S13,S17,S7,S12,S6,S4,S14,S19,S16,S8,S18,S1,S5,S15,S3,S20,S11,S2,S10,S9
根据排名结果,淘汰最后5名队员 S 20 , S 11 , S 2 , S 10 , S 9 {\bf S}_{20},{\bf S}_{11},{\bf S}_{2},{\bf S}_{10},{\bf S}_{9} S20,S11,S2,S10,S9。
模型的结果分析与推广
- 由表1,20名队员6项条件互有强弱,利用层次分析法得到了一种合理的综合排序方案,结果选出了综合实力较强的15名队员。
- 第13号队员各项条件总体较强,排在了第一位;
- 第9号和第10号队员各项条件总体较弱,排在后两位。
- 该模型还可以应用到三好学生的评选问题、旅游景点的选择问题、综合实力的评选分析问题等。
层次分析法的优缺点
层次分析法的优点
- 系统性:把所研究的问题看成了一个系统,按照分解、比较判断、综合分析的思维方式进行决策分析,也是实际中继机理分析方法、统计分析方法之后发展起来的又一个重要的系统分析工具。
- 实用性:把定性与定量方法结合起来,能处理许多传统的优化方法无法处理的实际问题,应用范围广。而且将决策者和决策分析者联系起来,体现了决策者的主观意见,决策者可以直接应用它进行决策分析,增加了决策的有效性和实用性。
- 简洁性:具有中等文化程度的人都可以学习掌握层次分析法的基本原理和步骤,计算也比较简便,所得结果简单明确,容易被决策者了解和掌握。
层次分析法的局限性
局限性是粗略、主观。首先是它的比较、判断及结果都是粗糙的,不适于精度要求很高的问题;其次是从建立层次结构图到给出两两判断比较矩阵,人的主观因素作用很大,使决策结果较大程度地依赖于决策人的主管意志(换一个决策者结果很有可能就不一样了),可能难以为众人接受。
层次分析法代码
disp('请输入准则层判断矩阵A(n阶)');
A=input('A=');
[n,n]=size(A);
[V,D]=eig(A);%求得特征向量和特征值%求出最大特征值和它所对应的特征向量
tempNum=D(1,1);
pos=1;
for h=1:nif D(h,h)>tempNumtempNum=D(h,h);pos=h;end
end
w=abs(V(:,pos));
w=w/sum(w);
t=D(pos,pos);
disp('准则层特征向量w=');disp(w);disp('准则层最大特征根t=');disp(t);%以下是一致性检验
CI=(t-n)/(n-1);RI=[0 0 0.52 0.89 1.12 1.26 1.36 1.41 1.46 1.49 1.52 1.54 1.56 1.58 1.59 1.60 1.61 1.615 1.62 1.63];
CR=CI/RI(n);
if CR<0.10disp('此矩阵的一致性可以接受!');disp('CI=');disp(CI);disp('CR=');disp(CR);
else disp('此矩阵的一致性验证失败,请重新进行评分!');
end