Distant Supervision for Relation Extraction via Piecewise Convolutional Neural Networks
- 0 前言
- 1 多示例学习
- 2 数据集
- 3 模型架构
- 3.1 向量表示
- 3.2 卷积、分段最大池化与分类
- 3.3 样本选择与损失
- 5 结语
- 6 参考资料
0 前言
远程监督(distant supervision)利用知识图谱的实体以及对应的关系对未标注文本进行回标,如果未标注文本中包含了一个知识图谱中具有某种关系的实体对,那么就假定这个文本也描述了相同的关系。通过这种标注策略虽然可以获得大量数据,但同时也会因为假设性太强而一如很多噪声数据(因为包含一个实体对的文本不一定描述了对应的关系)。
文章通过将PCNN模型与 多示例学习 Multi-instanceLearning 结合,有效降低了标注带来的噪声,是远程监督领域一篇非常经典的论文。这篇博客将结合论文与pytorch源码(非官方实现),对PCNN模型以及采用的多示例学习方法进行解读。
1 多示例学习
在解读模型之前,我们先来了解一下什么是多实例学习;
多示例学习可以被描述为:假设训练数据集中的每个数据是一个包(Bag),每个包都是一个示例(instance)的集合,每个包都有一个训练标记,而包中的示例是没有标记的;如果包中至少存在一个正标记的示例,则包被赋予正标记;而对于一个有负标记的包,其中所有的示例均为负标记。(这里说包中的示例没有标记,而后面又说包中至少存在一个正标记的示例时包为正标记包,是相对训练而言的,也就是说训练的时候是没有给示例标记的,只是给了包的标记,但是示例的标记是确实存在的,存在正负示例来判断正负类别)。通过定义可以看出,与监督学习相比,多示例学习数据集中的样本示例的标记是未知的,而监督学习的训练样本集中,每个示例都有一个一已知的标记;与非监督学习相比,多示例学习仅仅只有包的标记是已知的,而非监督学习样本所有示例均没有标记。但是多示例学习有个特点就是它广泛存在真实的世界中,潜在的应用前景非常大。
文章使用的多实例学习给予一个假设:在一个bag中,至少有一个句子是被标注正确的。因此,每个bag都有至少有一个标注正确的句子,这样就可以从每个bag中找一个得分最高的句子来表示整个bag。
2 数据集
作者将 NYT+FreeBase 数据集进行过滤以及打包,形成如下数据集:
27类关系,对数据集做了一些过滤,如删除了两个实体之间距离大于40个词的句子,以及去掉了实例少的关系,详细数据如下所示:
训练数据集:
实体对: 65726; 句子数: 112941;
测试数据集:
实体对: 93574; 句子数: 152416;
具体的,在数据集中,第一行是两个实体ID: ent1id ent2id;第二行: bag标签和bag内句子个数,其中由于少数bag有多个label(不会超过4个),因此句子label用4个整数表示,-1表示为空,如: 2 4 -1 -1 3 表示该bag的标签为2和4,然后包含3个句子;后续几行表示该bag内的句子。
3 模型架构
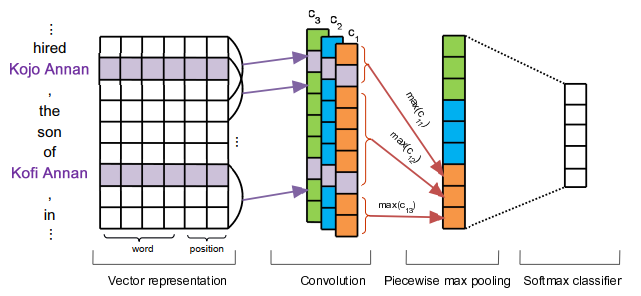
PCNN模型在功能上与其他非远程监督的普通模型并没有太大区别,通过向量表示,卷积,最大池化,分类四个部分获得关系的向量表示,模型结构如下所示:

3.1 向量表示
对于文本的向量表示,文章采用了词向量加位置嵌入的形式。对于位置嵌入,模型通过文本中每一个词与两个实体 e 1 e 2 e_1 e_2 e1e2 的相对位置来获取。示例如下:

首先要注意的是,与一般的模型不同,PCNN每次计算一个包的数据,而不是一个batch,一般模型中第一维度的大小是batch_size,而在这里几乎都是bag_size。实现时获得形状为(bag_size, sequence_len, d w d_w dw)的词向量以及(bag_size, sequence_len, d p d_p dp)的位置嵌入,并在hidden_size维度也就是第二维度连接,即可获得 d = d w + d p ∗ 2 d=d_w+d_p * 2 d=dw+dp∗2 的文本向量表示,源码如下:
self.word_embs = nn.Embedding(self.opt.vocab_size, self.opt.word_dim)self.pos1_embs = nn.Embedding(self.opt.pos_size, self.opt.pos_dim)self.pos2_embs = nn.Embedding(self.opt.pos_size, self.opt.pos_dim)word_emb = self.word_embs(insX)pf1_emb = self.pos1_embs(insPF1)pf2_emb = self.pos2_embs(insPF2)x = torch.cat([word_emb, pf1_emb, pf2_emb], 2)3.2 卷积、分段最大池化与分类
在卷积的过程中,文章选择了大小为(3, kernel_size = d d d)的卷积核,并设置了 n n n 个输出通道。在上图中,输出通道为3,而在具体实现的时候为230。对于每个输出通道的输出的卷积向量 c i c_i ci ,模型根据两个实体的位置将其分为3个 piece ,在最大池化时分别对其进行池化,因此 n n n 个卷积向量进行池化后即可得到长度为 3 ∗ n 3*n 3∗n 最终向量表示,经过一个全连接后即可得到分类结果。主体部分源码如下:
feature_dim = self.opt.word_dim + self.opt.pos_dim * 2self.convs = nn.ModuleList([nn.Conv2d(1, self.opt.filters_num, (k, feature_dim), padding=(int(k / 2), 0)) for k in self.opt.filters])all_filter_num = self.opt.filters_num * len(self.opt.filters)if self.opt.use_pcnn:all_filter_num = all_filter_num * 3masks = torch.FloatTensor(([[0, 0, 0], [1, 0, 0], [0, 1, 0], [0, 0, 1]]))if self.opt.use_gpu:masks = masks.cuda()self.mask_embedding = nn.Embedding(4, 3)self.mask_embedding.weight.data.copy_(masks)self.mask_embedding.weight.requires_grad = Falseself.linear = nn.Linear(all_filter_num, self.opt.rel_num)self.dropout = nn.Dropout(self.opt.drop_out)///////////////////////////////////////////////////////////////////////////////x = x.unsqueeze(1)x = self.dropout(x)x = [conv(x).squeeze(3) for conv in self.convs]if self.opt.use_pcnn:x = [self.mask_piece_pooling(i, insMasks) for i in x]else:x = [F.max_pool1d(i, i.size(2)).squeeze(2) for i in x]x = torch.cat(x, 1).tanh()x = self.dropout(x)x = self.linear(x)return x在PCNN主体部分的代码中,模型首先将 3.1 小节中获得的向量表示增加一个维度,再经dropout后过了一个卷积,得到了一个shape为(bag_size, out_channel=230, sequence_len)的卷积向量。之后对得到的卷积向量进行分段最大池化,激活后过全连接即可。
下面我们将着重看一下用 mask 实现分段最大池化(Piecewise Max Pooling)的策略。如果对于实现细节不是很感兴趣,可直接跳转到第 3.3 小节。
在获得一个包中一个instance的mask时,模型根据两个实体 e 1 e 2 e_1 e_2 e1e2 将文本进行分割,源码如下:
mask = [1] * (epos[0] + 1)mask += [2] * (epos[1] - epos[0])mask += [3] * (len(sent[2:-1]) - epos[1])通过两个实体,一个句子的mask被分成1,2,3三个 piece 。为了保证每个包中句子长度的一致性,还会适当补0,后来补充的这部分mask为0。有了mask后,我们来看一下最大池化部分的代码,其实现使用了很巧妙的技巧,源码如下:
def mask_piece_pooling(self, x, mask):'''refer: https://github.com/thunlp/OpenNREA fast piecewise pooling using mask'''x = x.unsqueeze(-1).permute(0, 2, 1, -1)masks = self.mask_embedding(mask).unsqueeze(-2) * 100x = masks.float() + xx = torch.max(x, 1)[0] - torch.FloatTensor([100]).cuda()x = x.view(-1, x.size(1) * x.size(2))return x其中mask的shape为(bag_size, sequnce_len)经过 x = x.unsqueeze(-1).permute(0, 2, 1, -1) 后,x的shape为(bag_size, sequence_len, out_channel, 1)。通过mask_embedding,mask中文本的位置0,1,2,3分别被映射成[0, 0, 0], [1, 0, 0], [0, 1, 0], [0, 0, 1],因此masks的shape为(bag_size, sequence_len, 1, 3)。
当masks与x相加时,效果如下:
>>> a=torch.tensor(range(3)).reshape(1,3)
>>> b=torch.tensor(range(3)).reshape(3,1)
>>> print(a)
tensor([[0, 1, 2]])
>>> print(b)
tensor([[0],[1],[2]])
>>> print(a+b)
tensor([[0, 1, 2],[1, 2, 3],[2, 3, 4]])也就是说,一个元素如果在第一个实体 e 1 e_1 e1 之前,那么其对应的mask是1,对应的masks是 [100, 0, 0] ,其余两个位置亦然,如果是0填充,对应的masks是 [0, 0, 0] ,不会被计算。在masks与x相加时,卷积向量中的每个元素都被复制了三份,并且如果这个元素处于第 i 个piece,那么这个元素会在最后一个维度的第 i 个位置上被加上100,这样在求最大值时,一个句子会被重复求三次,第一个 piece 上的最大元素会被保留在最后一个维度第一个位置上,第二个 piece 最大元素在第二个位置上,第三个亦然。最后改变一下矩阵的形状,我们就可以得到最大池化的结果。确实是个很有意思的加速计算技巧。
3.3 样本选择与损失
在本文开头我们提到,PCNN模型基于一个假设,在一个bag中,至少有一个句子是被标注正确的。bag 中每个实例经过全连接后,都会得到关于每个关系类别的概率。假设训练集中某个 bag 标签为 label,我们选择每个包中预测关系为 label 概率最高的那个值作为 bag 描述关系为 label 的概率。源码如下:
model.eval()for idx, bag in enumerate(batch_data):insNum = bag[1]label = labels[idx]max_ins_id = 0if insNum > 1:model.batch_size = insNumif opt.use_gpu:data = map(lambda x: torch.LongTensor(x).cuda(), bag)else:data = map(lambda x: torch.LongTensor(x), bag)out = model(data)# max_ins_id = torch.max(torch.max(out, 1)[0], 0)[1]max_ins_id = torch.max(out[:, label], 0)[1]比较特别的地方在于,这里首先要将模型调为eval模式,然后预测bag中所有实力表示目标关系的概率,再选取最高者作为包的表示。在选出所有batch中所有bag的表示后,把模型调成train模式,再进行预测与计算损失。
ps:这样确实带来了很多重复运算,其实选择出一个 bag 的表示之后无需再用model预测,直接使用即可,可以在后续需要的时候加以改进。
out = model(data, train=True)loss = criterion(out, label)data就是刚刚获得的所有bag都用所选示例表示的一个batch的数据。损失函数采用了交叉熵,这里就不过多赘述,更多实现细节可以阅读源码实现。
5 结语
PCNN模型通过分段最大池化和多示例学习,降低了错误标签带来的噪声,提高了模型的准确率,是远程监督领域一个非常经典的模型。
6 参考资料
论文地址:
https://www.aclweb.org/anthology/D15-1203.pdf
pytorch源码:
https://github.com/ShomyLiu/pytorch-relation-extraction
mask策略参考:
https://github.com/thunlp/OpenNRE
参考博客:
http://shomy.top/2018/02/28/relation-extraction/
http://shomy.top/2018/07/05/pytorch-relation-extraction/
https://www.jianshu.com/p/c8d08e92744c


![【MATLAB图像融合】[14]PCNN脉冲耦合神经网络代码分享](https://img-blog.csdnimg.cn/2020091111014875.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3N1ZGE1Mzk1,size_16,color_FFFFFF,t_70#pic_center)


![【MATLAB图像融合】[18]双通道PCNN模型实现图像融合](https://img-blog.csdnimg.cn/20210701180529996.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3N1ZGE1Mzk1,size_16,color_FFFFFF,t_70)





![【MATLAB图像融合】[13]PCNN脉冲耦合神经网络基本原理](https://img-blog.csdnimg.cn/20200910212004267.png#pic_center)