pytorch关系抽取框架OpenNRE源码解读与实践:PCNN ATT
- 0 前言
- 1 OpenNRE整体架构
- 2 PCNN+ATT 模型架构
- 2.1 PCNN Encoder
- 2.2 Bag Attention
- 结语
- 参考资料
0 前言
OpenNRE是清华大学推出的开源关系抽取框架,针对命名实体识别,句子级别的关系抽取,远程监督(包级别的关系抽取),文档级别的关系抽取以及 few-shot 任务均有实现。其模块化的设计可以大幅度减少不必要的代码重写。
本文将对OpenNRE整体架构进行介绍,并重点解读OpenNRE中针对远程监督任务的模型 PCNN + ATT :《Neural Relation Extraction with Selective Attention over Instances》。
ps:OpenNRE不支持 Windows ,在 Windows 环境下需要改很多路径,非常不方便,建议在 linux 环境下使用。
1 OpenNRE整体架构
OpenNRE在实现时,将关系抽取的框架划分成不同的模块,这使得在实现新的模型时,通常秩序修改Model和Encoder部分即可,其他部分不需要太大的改动即可使用,大大的提升了实现模型的效率。

在DataLoader模块中,针对不同的任务,实现了不同的读取策略和DataSet类;
在Encoder模块中,实现了各个模型获得关系向量表示的步骤。如用 PCNN+最大池化 得到关系向量表示,BERT模型的特殊标记 [CLS] 作为关系向量表示,将两个实体前面插入特殊标记 [ E 1 s t a r t ] , [ E 2 s t a r t ] [E_{1start}], [E_{2start}] [E1start],[E2start] ,并将这两个特殊标记的隐藏向量拼接作为关系向量表示(BERTem模型)等。这里对于BERTem模型具体细节不是很清楚的话可以看一下我之前解读BERTem论文与源码的博客。
BERTem:https://blog.csdn.net/xiaowopiaoling/article/details/105931134
我后续也会出解读OpenNRE中使用BERT进行关系抽取的源码。
在Model模块中,实现了在获取关系向量表示后的分类策略。如普通的全连接加softmax,远程监督的将一个包中所有的关系向量平均作为包的关系向量表示再过全连接和softmax,以及本文将要讲解的对于包中的实例应用attention策略后得到向量表示再进行分类等。
再Train Method 和 Eval Method 中是一些比较套路化的训练步骤,在实现模型时将其稍加改动即可拿来使用,非常方便。
Module 模块中实现了一些基础模块,如cnn,rnn,lstm,以及处理策略如平均池化,最大池化等,也是可以直接拿来用的。
FrameWork模块对上述所有模块进行集成,包括普通句子级别的关系抽取流程 sentence_re ,以及远程监督包级别的关系抽取 bag_re 等。
2 PCNN+ATT 模型架构
下面,我们将针对远程监督的 PCNN+ATT 模型,来解读一下模型实现的细节。
2.1 PCNN Encoder
对于模型中 PCNN 部分,主要流程就是先将文本转化成词嵌入与位置嵌入后,再过卷积神经网路,对于得到的结果,按照实体位置分成第一个实体之前,两个实体之间,第二个实体之后三个部分并分别最大池化。模型图如下:

这里对于模型细节感兴趣的可以看一下我之前的博客。
PCNN:https://blog.csdn.net/xiaowopiaoling/article/details/106120543
下面我们来看一下 PCNN encoder 的代码:
self.drop = nn.Dropout(dropout)self.kernel_size = kernel_sizeself.padding_size = padding_sizeself.act = activation_functionself.conv = nn.Conv1d(self.input_size, self.hidden_size, self.kernel_size, padding=self.padding_size)self.pool = nn.MaxPool1d(self.max_length)self.mask_embedding = nn.Embedding(4, 3)self.mask_embedding.weight.data.copy_(torch.FloatTensor([[0, 0, 0], [1, 0, 0], [0, 1, 0], [0, 0, 1]]))self.mask_embedding.weight.requires_grad = Falseself._minus = -100self.hidden_size *= 3def forward(self, token, pos1, pos2, mask):"""Args:token: (B, L), index of tokenspos1: (B, L), relative position to head entitypos2: (B, L), relative position to tail entityReturn:(B, EMBED), representations for sentences"""# Check size of tensorsif len(token.size()) != 2 or token.size() != pos1.size() or token.size() != pos2.size():raise Exception("Size of token, pos1 ans pos2 should be (B, L)")x = torch.cat([self.word_embedding(token), self.pos1_embedding(pos1), self.pos2_embedding(pos2)], 2) # (B, L, EMBED)x = x.transpose(1, 2) # (B, EMBED, L)x = self.conv(x) # (B, H, L)mask = 1 - self.mask_embedding(mask).transpose(1, 2) # (B, L) -> (B, L, 3) -> (B, 3, L)pool1 = self.pool(self.act(x + self._minus * mask[:, 0:1, :])) # (B, H, 1)pool2 = self.pool(self.act(x + self._minus * mask[:, 1:2, :]))pool3 = self.pool(self.act(x + self._minus * mask[:, 2:3, :]))x = torch.cat([pool1, pool2, pool3], 1) # (B, 3H, 1)x = x.squeeze(2) # (B, 3H)x = self.drop(x)return x这里的注释其实也非常清楚了,其中 B 是batch_size,L 是 sequence_len ,H 是输出通道数,即有多少个卷积核(这里为230)。首先将文本的词嵌入和位置嵌入连接,这里位置嵌入是根据一个词与两个实体之间的相对位置获得的,所以有两个,示例如下:

连接后,我们再过一个卷积层,得到 shape 为 (B, H, L) 的矩阵。
之后我们采取利用mask进行分段最大池化的策略,这里也是模型非常巧妙地地方。对于一个句子地某个词,如果这个词的位置在第一个实体之前,那么mask相应位置上被置为1,如果在两个实体之间被置为2,第二个实体之后被置为3,用与补齐句子的0填充被置为0。
通过mask_embedding,mask中文本的位置0,1,2,3分别被映射成[0, 0, 0], [1, 0, 0], [0, 1, 0], [0, 0, 1]。当执行 mask = 1 - self.mask_embedding(mask).transpose(1, 2) 时,四种mask变为 [1, 1, 1], [0, 1, 1], [1, 0, 1], [1, 1, 0]。对于根据实体位置分成的三个段,在每个段的池化过程中,shape 为 (B, H, L) 的 x 将会与 shape 为(B, 1, L) 的 self._minus * mask[:, 0:1, :] 相加,即当前段中元素值不受影响,而其它两个段所有元素都会因被减掉100而不被计算,这样就使得最大池化的过程在一个段上进行。重复三次操作,我们便可以得到对三个段分别进行最大池化的结果。将其拼接后我们即可得到关系的向量表示。
2.2 Bag Attention
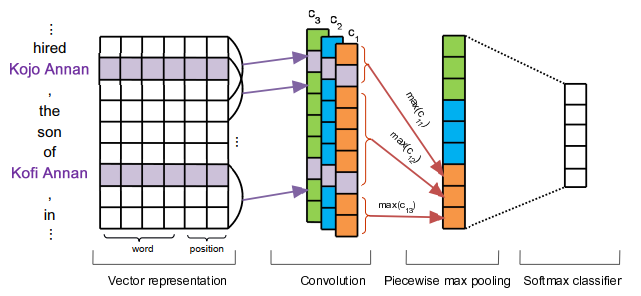
对于模型中 Attention 的部分,我们先来看一下模型图:

远程监督(distant supervision)利用知识图谱的实体以及对应的关系对未标注文本进行回标,如果未标注文本中包含了一个知识图谱中具有某种关系的实体对,那么就假定这个文本也描述了相同的关系。通过这种标注策略虽然可以获得大量数据,但同时也会因为假设性太强而一如很多噪声数据(因为包含一个实体对的文本不一定描述了对应的关系)。
解决远程监督错误标注所带来的噪声问题,我们通常使用多示例学习(Multi-instance Learning)的方法,即将多个数据打包成一个 bag ,bag 中所有句子都含有相同的实体对。对于模型图中,一个 bag 中有 i i i 个实例,句子 m 1 , m 2 , . . . , m i m_1,m_2,...,m_i m1,m2,...,mi 经过上面 PCNN Encoder 后获得了其对应的关系向量表示 x 1 , x 2 , . . . , x i \mathbf x_1,\mathbf x_2,...,\mathbf x_i x1,x2,...,xi (这里为了防止混淆,将模型图中的 r 1 , r 2 , . . . r i r_1,r_2,...r_i r1,r2,...ri 替换为了 x 1 , x 2 , . . . , x i \mathbf x_1,\mathbf x_2,...,\mathbf x_i x1,x2,...,xi ),对于 bag 的关系向量表示,我们通过加权平均获得,即:
s = ∑ i α i x i \mathbf s=\sum_i {\alpha_i} \mathbf x_i s=i∑αixi
得到 bag 的向量表示 s \mathbf s s 后,再过全连接加softmax分类即可。
那么这个权重 α \alpha α 应该如何获得呢?有如下三种比较思路:
1.At Least One。这种思路基于一个假设:对于一个 bag 中的示例,至少有一个示例是标注正确的。假设一个 bag 的标签为 i,即这个包的实体描述了第 i 个关系,我们就选择包中示例预测关系为 i 概率最高的那个示例作为 bag 的关系向量表示。在这种情况下,被选择的示例权重 α \alpha α 为1,而其余都为0 。这种思路缓解了数据中含有噪声的问题,但同时也造成了大量的数据浪费。
2.平均。对于一个包中的关系向量表示 x 1 , x 2 , . . . , x i \mathbf x_1,\mathbf x_2,...,\mathbf x_i x1,x2,...,xi ,我们将其以一种非常简单的方式加权,即 bag 种每一个示例的权重都是 1 n 1\over n n1 。这样虽然可以尽可能地利用包中的信息,但没有解决远程监督错误标注带来的噪声问题。
3.Attention机制。设 bag 标签的关系向量表示为 r \mathbf r r(注意,这里非常容易混淆,前面的提到的 bag 中示例的关系表示为 x i \mathbf x_i xi ,bag 的关系向量表示为 r \mathbf r r,这两个向量都是每次计算得到的,而这里 bag 标签关系的向量表示 r r r 暂时可以看作从 embedding 中获得的,在后面我们会详细讲述),对于 bag 中的示例 i i i ,我们计算其关系向量表示 x i \mathbf x_i xi 与 bag 标签的关系向量表示 r r r 的匹配度 e i e_i ei 。在PCNN+ATT 的原文种, e i e_i ei 的计算公式如下:
e i = x i A r e_i=\mathbf x_i\mathbf A \mathbf r ei=xiAr
其中 A \mathbf A A 是加权对角矩阵。而 OpenNRE 修改了计算公式,改为了计算两个向量之间的点积,具体如下:
e i = x i ⋅ r e_i=\mathbf x_i \cdot \mathbf r ei=xi⋅r
通过当前关系的匹配度 e i e_i ei 占全部的比重,我们就可以得到权重 α i \alpha_i αi(也就是softmax) :
α i = exp ( e i ) ∑ k exp ( e k ) \alpha_i= {\exp(e_i)\over\sum_k \exp(e_k)} αi=∑kexp(ek)exp(ei)
看到这里我们可能会有两个问题,一个是 bag 标签关系的向量表示 r r r 如何得到,另一个是为什么 OpenNRE 要如此修改计算公式。
首先,对于 bag 标签关系的向量表示 r r r ,在得到 bag 的向量表示 s \mathbf s s 后,我们使用全连接加softmax进行分类分类。而 bag 标签关系的向量表示 r r r 就是通过这个全连接层中的权重矩阵按照类似于 embedding 层以下标索引的方式得到的。为什么全连接层的权重矩阵可以作为关系向量表示呢?我们来看一下我们使用全连接层分类时矩阵乘法的运算过程,其中 S \mathbf S S 是一个 shape 为(batch_size=2, hidden_state=3)的 bag 的关系向量表示, R \mathbf R R 是 shape 为(hidden_state=3, num_relation=2)的全连接层的权重, O \mathbf O O 为分类结果(实际中还需要加上 bias,这里为了解释原理暂时不考虑)。
S = [ a 1 , 1 a 1 , 2 a 1 , 3 a 2 , 1 a 2 , 2 a 2 , 3 ] \mathbf S = \begin{bmatrix} a_{1,1} & a_{1,2} &a_{1,3} \\ a_{2,1} &a_{2,2} &a_{2,3} \end{bmatrix} S=[a1,1a2,1a1,2a2,2a1,3a2,3]
R = [ b 1 , 1 b 1 , 2 b 2 , 1 b 2 , 2 b 3 , 1 b 3 , 2 ] \mathbf R=\begin{bmatrix} b_{1,1}&b_{1,2}\\b_{2,1}&b_{2,2}\\b_{3,1}&b_{3,2} \end{bmatrix} R=⎣⎡b1,1b2,1b3,1b1,2b2,2b3,2⎦⎤
O = S ⋅ R = [ a 1 , 1 b 1 , 1 + a 1 , 2 b 2 , 1 + a 1 , 3 b 3 , 1 a 1 , 1 b 1 , 2 + a 1 , 2 b 2 , 2 + a 1 , 3 b 3 , 2 a 2 , 1 b 1 , 1 + a 2 , 2 b 2 , 1 + a 2 , 3 b 3 , 1 a 2 , 1 b 1 , 2 + a 2 , 2 b 2 , 2 + a 2 , 3 b 3 , 2 ] \mathbf O=\mathbf S\cdot \mathbf R=\begin{bmatrix} a_{1,1}b_{1,1}+a_{1,2}b_{2,1}+a_{1,3}b_{3,1}&a_{1,1}b_{1,2}+a_{1,2}b_{2,2}+a_{1,3}b_{3,2}\\a_{2,1}b_{1,1}+a_{2,2}b_{2,1}+a_{2,3}b_{3,1}&a_{2,1}b_{1,2}+a_{2,2}b_{2,2}+a_{2,3}b_{3,2} \end{bmatrix} O=S⋅R=[a1,1b1,1+a1,2b2,1+a1,3b3,1a2,1b1,1+a2,2b2,1+a2,3b3,1a1,1b1,2+a1,2b2,2+a1,3b3,2a2,1b1,2+a2,2b2,2+a2,3b3,2]
我们可以看到,在分类的过程中,对于一个 bag 的向量表示 s \mathbf s s ,即 S \mathbf S S 中的一行,我们相当于用其与全连接层权重 R \mathbf R R 的每一列都求了一个点积,将点积得到的值作为当前 bag 与相应关系的匹配度,经过softmax后作为这个 bag 描述相应关系的概率。这就解释了 OpenNRE 采用点积的形式来计算匹配度 e i e_i ei 的依据。也正因如此,我们可以把全连接层权重 R \mathbf R R 的每一列看作相应关系的向量表示 r \mathbf r r 。在计算 e i e_i ei 时,我们只需使用类似于 embedding 的形式,将对应的关系向量 r \mathbf r r 取出即可与计算得到的 x i \mathbf x_i xi 计算点积,从而得到匹配度 e i e_i ei 。
至此,模型的 attention 机制已经非常清晰了,下面我们来看一下这部分的源码:
if mask is not None:rep = self.sentence_encoder(token, pos1, pos2, mask) # (nsum, H) if train:if bag_size > 0:batch_size = label.size(0)query = label.unsqueeze(1) # (B, 1)att_mat = self.fc.weight.data[query] # (B, 1, H)rep = rep.view(batch_size, bag_size, -1)att_score = (rep * att_mat).sum(-1) # (B, bag)softmax_att_score = self.softmax(att_score) # (B, bag)bag_rep = (softmax_att_score.unsqueeze(-1) * rep).sum(1) # (B, bag, 1) * (B, bag, H) -> (B, bag, H) -> (B, H)bag_rep = self.drop(bag_rep)bag_logits = self.fc(bag_rep) # (B, N)这里的 sentence_encoder 就是 PCNN ,rep 即获得的 bag 中所有示例的向量表示,shape 为(batch_size * bag_size, hidden_state)。接下来我们从全连接层中取出 label 对应的关系向量 r \mathbf r r ,也就是 att_mat ,shape 为(batch_size, 1, hidden_state),同时将 rep 的 shape 变为(batch_size, bag_size, hidden_state),再将 rep 与 att_mat 中的元素一一对应相乘,这时会进行广播运算,对于得到的结果在最后一个维度求和,就相当于求得点积。之后再通过 e i e_i ei 也就是 softmax 得到对应权重的 α i \alpha_i αi ,将其与关系向量表示 rep 按元素意义对应相乘并求和,即进行了加权平均运算。最后过一个 dropout 和全连接即可得到分类结果。
PCNN+ATT 模型的损失采用了交叉熵,其训练也是比较套路化的,在此就不过多赘述了,对于更多实现细节有兴趣的话可以阅读 OpenNRE 的源码。
结语
OpenNRE 是一个优秀的关系抽取框架,通过将关系抽取的框架划分成不同的模块,大大的提升了实现模型的效率。同时由于集成了许多关系抽取模型,使得不同模块之间可以自由组合,极大方便了日后基于 OpenNRE 的拓展与研究。
参考资料
OpenNRE 论文:
https://www.aclweb.org/anthology/D19-3029.pdf
OpenNRE 源码:
https://github.com/thunlp/OpenNRE
PCNN 论文:
https://www.aclweb.org/anthology/D15-1203.pdf
PCNN 参考博客:
https://blog.csdn.net/xiaowopiaoling/article/details/106120543
PCNN+ATT 论文:
https://www.researchgate.net/publication/306093646_Neural_Relation_Extraction_with_Selective_Attention_over_Instances
![【MATLAB图像融合】[14]PCNN脉冲耦合神经网络代码分享](https://img-blog.csdnimg.cn/2020091111014875.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3N1ZGE1Mzk1,size_16,color_FFFFFF,t_70#pic_center)


![【MATLAB图像融合】[18]双通道PCNN模型实现图像融合](https://img-blog.csdnimg.cn/20210701180529996.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3N1ZGE1Mzk1,size_16,color_FFFFFF,t_70)





![【MATLAB图像融合】[13]PCNN脉冲耦合神经网络基本原理](https://img-blog.csdnimg.cn/20200910212004267.png#pic_center)