CHatGPT
ChatGPT 能以不同样式、不同目的生成文本,并且在准确度、叙述细节和上下文连贯性上具有更优的表现。GPT是Generative Pre-trained Transformer(生成型预训练变换模型)的缩写
OpenAI 使用监督学习和强化学习的组合来调优 ChatGPT,其中的强化学习组件使 ChatGPT 独一无二。OpenAI 使用了「人类反馈强化学习」(RLHF)的训练方法,该方法在训练中使用人类反馈,以最小化无益、失真或偏见的输出。
ChatGPT更强的性能和海量参数,它包含了更多的主题的数据,能够处理更多小众主题。
ChatGPT现在可以进一步处理回答问题、撰写文章、文本摘要、语言翻译和生成计算机代码等任务。
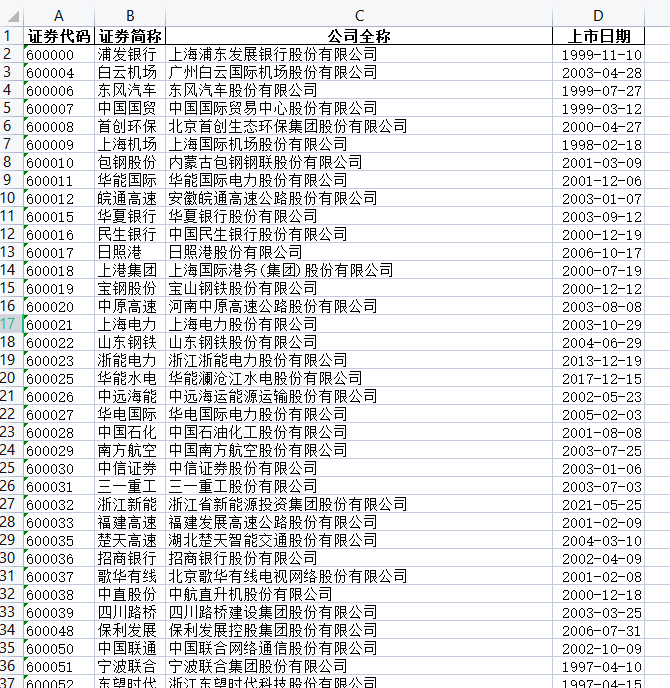
BERT与GPT的技术架构(图中En为输入的每个字,Tn为输出回答的每个字)
简单理解:GPT可以线性下推反馈调整得出结果,新的轮次结果不影响旧的老结果
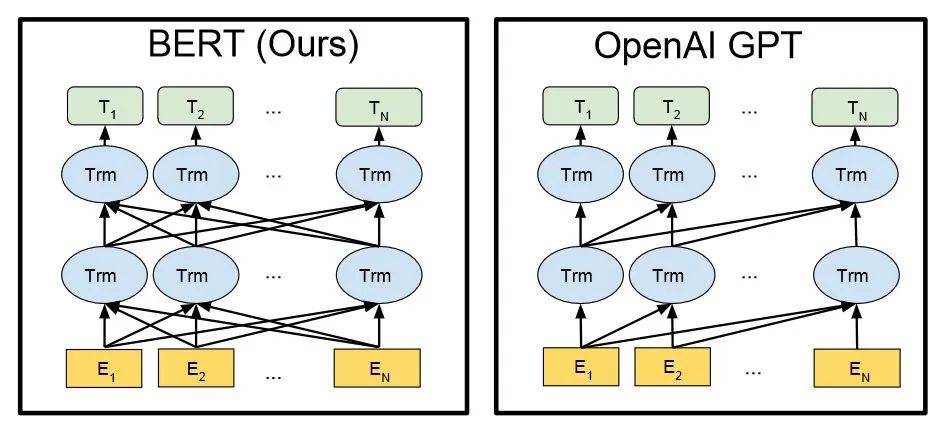
GPT家族的演进
ChatGPT背景理解
chagpt 语言模型 大数据的训练量 -> 一致性问题-> 实际希望做什么,而不是被训练做什么
=> 目标函数是否符合预期 => 人类的期望 => 产生更多的实际价值
GPT-3 非一致性模型 -> 网络文本数据 -> 类人类文本,但不符合人类的预期
-> 预测函数:f(概率分布(词序序列)) ->效率高
-> 问题: 人类文本是 在情景中根据已知的背景知识常识来辅助生成语言->出入
-> 一致性问题表现:内容是 无效,胡编乱造,缺乏可解释性,可能偏见有害
训练语言模型的核心技术
作为ChatGPT基础的GPT-3或GPT-3.5 是一个超大的统计语言模型或顺序文本预测模型
Next-token-prediction
模型被给定一个词序列作为输入,并被要求预测序列中的下一个词
可能性|概率
The cat sat on the [ mat|chair|floor]
masked-language-modeling
Next-token-prediction 的变体:替换词语为特殊token->目标函数 ->生成自然流畅文本
The [MASK] on the []
问题:模型无法区分重要错误和不重要错误
预测高概率词汇的模型可能不一定会学习其含义的某些更高级表征
难以承担:深入理解语言的任务
The Roman Empire [MASK] with the reign of Augustus
[MASK]-> began | ended 高概率词汇 -> 不一致
人类反馈 => RLHF
增加了使用了人类反馈来指导学习过程, 对模型进一步训练
chatgpt将RLHF技术应用于实际场景模型
[人类反馈强化学习RLHF]原理
RLHF(Reinforcement Learning from Human Feedbac,人类反馈强化学习) 技术。
总体是三个不同步骤:
有监督的调优:预训练的语言模型在少量已标注的数据上进行调优,以学习从给定的 prompt 列表生成输出的有监督的策略(即 SFT 模型);
数据收集:[人工标注,openAI(GPT-3)api请求]->相对较小、高质量的数据集
模型选择: GPT-3.5 系列中的预训练模型
使用的基线模型是最新版的 text-davinci-003(通过对程序代码调优的 GPT-3 模型)
在「代码模型」而不是纯文本模型之上进行调优
问题:SFT模型输出 不一致性文本 ->人工排序SFT的不同输出以创建RM模型
模拟人类偏好:标注者们对相对大量的 SFT 模型输出进行投票,这就创建了一个由比较数据组成的新数据集。在此数据集上训练新模型,被称为训练回报模型(Reward Model,RM);
目标:从SFT输出数据中学习目标函数, 根据人类可取程序降序,以反应人类的偏好
f()=sort()
工作原理:
选择prompt数据,通过SFT模型输出N个结果,由标注者排序并添加标签,输出新的标签数据集->训练RM模型
重新将SFT的输出 做为输入,通过RM模型生成新的结果,并排序
TAMER框架
Training an Agent Manually via Evaluative Reinforcement,评估式强化人工训练代理
将人类标记者的知识,以奖励信反馈的形式训练Agent,加快其快速收敛。
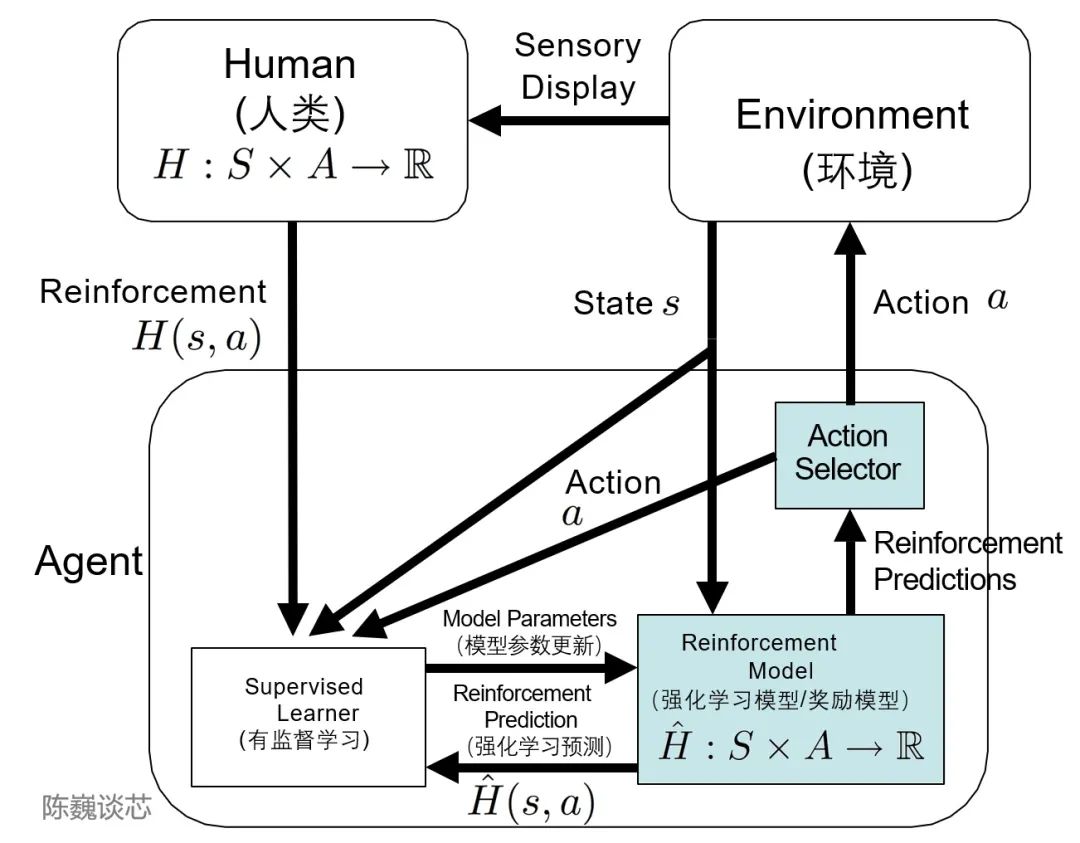
通过TAMER+RL(强化学习),借助人类标记者的反馈,能够增强从马尔可夫决策过程 (MDP) 奖励进行强化学习 (RL) 的过程。
近端策略优化(PPO):RM 模型用于进一步调优和改进 SFT 模型,PPO 输出结果是的策略模式。
目标:使用 PPO 模型优化RM模型以微调 SFT 模型
算法:近端策略优化(PPO)算法
强化学习中训练agent的on-policy算法, 它直接学习和根据agent所获得的回报不断更新当前策略
使用「信任区域优化」方法来训练策略,它将策略的更改范围限制在与先前策略的一定程度内以保证稳定性
使用[价值函数]来估计[给定状态]或[动作的预期回报],通过优势函数来比较前后两次策略,以此来更新更明智的策略
模型:PPO 模型由 SFT 模型初始化,价值函数由 RM 模型初始化
PPO初始化环境:「bandit environment」with SFT RM
ppo从数据集抽样prompt并给出对应的期望响应
RM对 给定的prompt 和响应计算,产生相应的回报
PPO再用回报更新模型,并输出结果
注:SFT模型对每个token添加KL惩罚因子,避免RM过度优化
思路:
Importance Sampling:将Policy Gradient中On-policy的训练过程转化为Off-policy,即将在线学习转化为离线学习
训练高质量的ChatGPT模型
使用多个模型,利用RM阶段训练好的回报模型,靠奖励打分来更新预训练模型SFT参数。在数据集中随机抽取问题,使用PPO模型生成回答,并用训练好的RM模型给出质量分数。
把回报分数依次传递,由此产生策略梯度,通过强化学习的方式以更新PPO模型参数。
通过迭代不断重复第二和第三阶段,训练高质量模型
# 伪代码
# 有监督的调优
def ppoModel
begin with: <prompt,demostration> -> SFTModel3.5 -> fineTune while(times>0):# 模拟人类偏好# 采样label_sorts = makeLabelsAndSort(sample(fineTune)) rmModel=initModel(label_sorts)# 近端策略优化模型ppoModel=(ppoModel==null)?init():update(rmModel))res = ppoModel(prompt)return res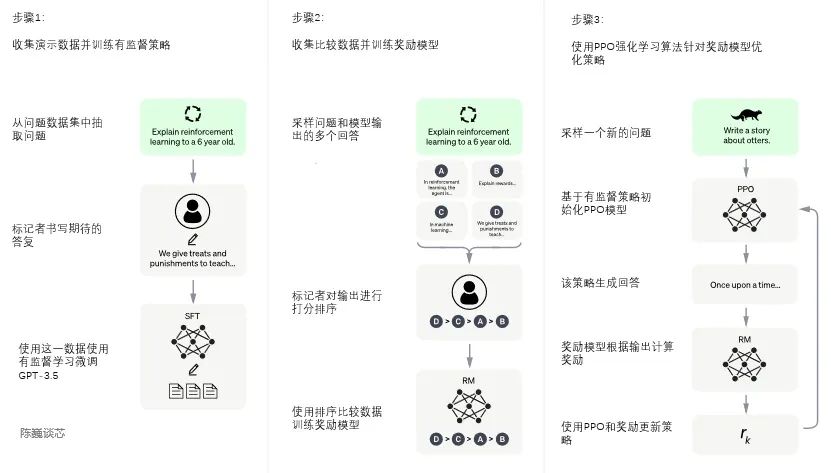
局限性
在将语言模型与人类意图保持一致的过程中,用于 fine-tuning 模型的数据会受到各种错综复杂的主观因素的影响
生成 demo 数据的人工标注者的偏好;
设计研究和编写标签说明的研究人员;
选择由开发人员制作或由 OpenAI 客户提供的 prompt;
标注者偏差既包含在 RM 模型训练中,也包含在模型评估中。
参与训练过程的标注人员和研究人员可能并不能完全代表语言模型的所有潜在最终用户
ChatGPT的使用
简单介绍,具体看官方文档
申请账号(得想点办法),测试使用均需要国外的ip
openai
一般应用都是通过调用openai完成,具体可以参考地址:
https://platform.openai.com/docs/api-reference/images/create
样例demo:
# 测试能否正常ping通接口
curl https://api.openai.com/v1/completions \-H "Content-Type: application/json" \-H "Authorization: Bearer $OPENAI_API_KEY" \-d '{"model": "text-davinci-003","prompt": "Say this is a test","max_tokens": 7,"temperature": 0}'# 测试生成对话
curl https://api.openai.com/v1/chat/completions \-H "Content-Type: application/json" \-H "Authorization: Bearer $OPENAI_API_KEY" \-d '{"model": "gpt-3.5-turbo","messages": [{"role": "user", "content": "Hello!"}]}'# 测试生成图片
curl https://api.openai.com/v1/images/generations \-H "Content-Type: application/json" \-H "Authorization: Bearer $OPENAI_API_KEY" \-d '{"prompt": "A cute baby sea otter","n": 2,"size": "1024x1024"}'SDK
sdk一般就是通过参数封装简化使用接口的第三方代码
javaSDk网上获取了一个样例,以供参考, github地址:
https://github.com/Grt1228/chatgpt-java
样例code
public class OpenAiStreamClientTest {private OpenAiStreamClient client;@Beforepublic void before() {// 执行成功的重点:在此处设置本地笔记本能够访问其他地区的代理端口Proxy proxy = new Proxy(Proxy.Type.HTTP, new InetSocketAddress("127.0.0.1", 8118));client = OpenAiStreamClient.builder().connectTimeout(50).readTimeout(50).writeTimeout(50).apiKey("sk-************************************").proxy(proxy).apiHost("https://api.openai.com/").build();}@Testpublic void chatCompletions() {ConsoleEventSourceListener eventSourceListener = new ConsoleEventSourceListener();Message message = Message.builder().role(Message.Role.USER).content("你好!").build();ChatCompletion chatCompletion = ChatCompletion.builder().messages(Arrays.asList(message)).build();client.streamChatCompletion(chatCompletion, eventSourceListener);CountDownLatch countDownLatch = new CountDownLatch(1);try {countDownLatch.await();} catch (InterruptedException e) {e.printStackTrace();}}
}openapi接口列表
/*** 描述: open ai官方api接口** @author https:www.unfbx.com* 2023-02-15*/
public interface OpenAiApi {/*** 模型列表** @return Single ModelResponse*/@GET("v1/models")Single<ModelResponse> models();/*** models 返回的数据id* @param id* @return Single Model*/@GET("v1/models/{id}")Single<Model> model(@Path("id") String id);/*** 文本问答* Given a prompt, the model will return one or more predicted completions, and can also return the probabilities of alternative tokens at each position.** @param completion* @return Single CompletionResponse*/@POST("v1/completions")Single<CompletionResponse> completions(@Body Completion completion);/*** Creates a new edit for the provided input, instruction, and parameters.* 文本修复** @param edit* @return Single EditResponse*/@POST("v1/edits")Single<EditResponse> edits(@Body Edit edit);/*** Creates an image given a prompt.* 根据描述生成图片** @param image* @return Single ImageResponse*/@POST("v1/images/generations")Single<ImageResponse> genImages(@Body Image image);/*** Creates an edited or extended image given an original image and a prompt.* 根据描述修改图片** @param image* @param mask* @param requestBodyMap* @return Single ImageResponse*/@Multipart@POST("v1/images/edits")Single<ImageResponse> editImages(@Part() MultipartBody.Part image,@Part() MultipartBody.Part mask,@PartMap() Map<String, RequestBody> requestBodyMap);/*** Creates a variation of a given image.* 创建给定图像的变体。** @param image* @param requestBodyMap* @return Single ImageResponse*/@Multipart@POST("v1/images/variations")Single<ImageResponse> variationsImages(@Part() MultipartBody.Part image,@PartMap() Map<String, RequestBody> requestBodyMap);/*** Creates an embedding vector representing the input text.* 创建表示输入文本的嵌入向量。* @param embedding* @return Single EmbeddingResponse*/@POST("v1/embeddings")Single<EmbeddingResponse> embeddings(@Body Embedding embedding);/*** Returns a list of files that belong to the user's organization.* 返回属于用户组织的文件列表。* @return Single OpenAiResponse File*/@GET("/v1/files")Single<OpenAiResponse<File>> files();/*** 删除文件** @param fileId* @return Single DeleteResponse*/@DELETE("v1/files/{file_id}")Single<DeleteResponse> deleteFile(@Path("file_id") String fileId);/*** 上传文件** @param purpose* @param file* @return Single UploadFileResponse*/@Multipart@POST("v1/files")Single<UploadFileResponse> uploadFile(@Part MultipartBody.Part file,@Part("purpose") RequestBody purpose);/*** 检索文件** @param fileId* @return Single File*/@GET("v1/files/{file_id}")Single<File> retrieveFile(@Path("file_id") String fileId);/*** 检索文件内容* ###不对免费用户开放###* ###不对免费用户开放###* ###不对免费用户开放###** @param fileId* @return Single ResponseBody*/@Streaming@GET("v1/files/{file_id}/content")Single<ResponseBody> retrieveFileContent(@Path("file_id") String fileId);/*** 文本审核** @param moderation* @return Single ModerationResponse*/@POST("v1/moderations")Single<ModerationResponse> moderations(@Body Moderation moderation);/*** 创建微调作业** @param fineTune* @return Single FineTuneResponse*/@POST("v1/fine-tunes")Single<FineTuneResponse> fineTune(@Body FineTune fineTune);/*** 微调作业集合** @return Single OpenAiResponse FineTuneResponse*/@GET("v1/fine-tunes")Single<OpenAiResponse<FineTuneResponse>> fineTunes();/*** 检索微调作业** @return Single FineTuneResponse*/@GET("v1/fine-tunes/{fine_tune_id}")Single<FineTuneResponse> retrieveFineTune(@Path("fine_tune_id") String fineTuneId);/*** 取消微调作业** @return Single FineTuneResponse*/@POST("v1/fine-tunes/{fine_tune_id}/cancel")Single<FineTuneResponse> cancelFineTune(@Path("fine_tune_id") String fineTuneId);/*** 微调作业事件列表** @return Single OpenAiResponse Event*/@GET("v1/fine-tunes/{fine_tune_id}/events")Single<OpenAiResponse<Event>> fineTuneEvents(@Path("fine_tune_id") String fineTuneId);/*** 删除微调作业模型* Delete a fine-tuned model. You must have the Owner role in your organization.** @return Single DeleteResponse*/@GET("v1/models/{model}")Single<DeleteResponse> deleteFineTuneModel(@Path("model") String model);/*** 引擎列表* 官方已废弃此接口** @return Single OpenAiResponse Engine*/@Deprecated@GET("v1/engines")Single<OpenAiResponse<Engine>> engines();/*** 检索引擎* 官方已废弃此接口* @param engineId* @return Engine*/@Deprecated@GET("v1/engines/{engine_id}")Single<Engine> engine(@Path("engine_id") String engineId);/*** 最新版的GPT-3.5 chat completion 更加贴近官方网站的问答模型* @param chatCompletion chat completion* @return 返回答案*/@POST("v1/chat/completions")Single<ChatCompletionResponse> chatCompletion(@Body ChatCompletion chatCompletion);/*** 语音转文字** @param model 模型* @param file 语音文件* @return 文本*/@Multipart@POST("v1/audio/transcriptions")Single<WhisperResponse> speechToTextTranscriptions(@Part MultipartBody.Part file,@Part("model") RequestBody model);/*** 语音翻译:目前仅支持翻译为英文** @param model 模型* @param file 语音文件* @return 文本*/@Multipart@POST("v1/audio/translations")Single<WhisperResponse> speechToTextTranslations(@Part MultipartBody.Part file,@Part("model") RequestBody model);
}重点使用openapi的completion文本问答接口
SSE
OpenAI官网在接受Completions接口的时候,使用了sse技术。 Completion对象本身有一个stream属性,当stream为true时候Api的Response返回就会变成Http长链接。
介绍使用server-sent events
Server-Sent Events (SSE) 是一种用于实现服务器向客户端发送实时数据的 Web 技术。与传统的 HTTP 请求不同,SSE 允许服务器持续地向客户端发送数据流,而不需要客户端发起请求。
下面是一个简单的使用 SSE 的示例:
在 HTML 文件中,创建一个 <div> 元素,用于显示从服务器发送的数据:
<div id="messages"></div>使用 JavaScript 创建一个 SSE 连接:
javascriptCopy code
const eventSource = new EventSource('/stream');其中 /stream 是服务器端发送 SSE 数据的端点。
添加事件处理程序来处理来自服务器的数据:
javascriptCopy code
eventSource.onmessage = function(event) {const messagesDiv = document.querySelector('#messages');messagesDiv.innerHTML += event.data;
};在服务器端发送 SSE 数据:
javascriptCopy code
res.write('data: Hello, world!\n\n');其中 data: 是 SSE 数据的前缀,Hello, world! 是实际的数据,\n\n 表示数据的结束。
使用 SSE 可以实现很多实时应用程序,例如聊天应用程序、股票市场数据更新、实时游戏等等。由于 SSE 是基于 HTTP 协议的,因此可以与现有的 Web 技术(如 Ajax 和 WebSockets)很好地集成。